一种基于大数据的风电场发电功率预测方法
本发明属于风力发电,具体涉及一种基于大数据的风电场发电功率预测方法。
背景技术:
1、随着全球对可再生能源的需求不断增加,风电作为清洁能源的重要代表之一,正在迅速发展。然而,由于风速等自然因素的不确定性和变化性,风电场的发电功率预测一直是一个具有挑战性的问题。传统的基于物理模型的预测方法往往受限于模型的复杂度和参数的准确性,难以充分考虑到复杂的气象环境和风电场运行状态。同时,随着大数据和深度学习技术的快速发展,人们意识到利用海量数据和深度学习模型可能会为风电场发电功率预测带来新的突破。
2、大数据技术的出现为风电场发电功率预测提供了强大的支持。风电场运行过程中产生了大量的数据,包括风速、温度、湿度等气象数据,以及风机状态、发电功率等运行数据。这些数据量庞大、多样化,具有很高的时空分辨率,为发电功率预测提供了丰富的信息。利用大数据技术,可以对这些数据进行有效的采集、存储、处理和分析,挖掘其中的潜在规律和特征,为发电功率预测提供更可靠的依据。
3、另一方面,深度学习技术的快速发展也为风电场发电功率预测带来了新的机遇。深度学习模型具有强大的非线性拟合能力和表征学习能力,能够从大数据中自动学习到数据的特征表示,捕捉数据之间的复杂关系。相较于传统的基于物理模型的预测方法,深度学习模型不需要过多的先验知识,可以更好地适应复杂多变的气象环境和风电场运行状态,具有更高的预测精度和泛化能力。
4、因此,基于大数据和深度学习技术的风电场发电功率预测方法具有重要的研究价值和广阔的应用前景。通过充分利用大数据和深度学习技术,可以实现对风电场发电功率的准确预测,为风电场的运行调度提供科学依据,推动风电产业的智能化、高效化发展。
技术实现思路
1、针对现有技术存在的不足,本发明提出了一种基于大数据的风电场发电功率预测方法,该方法包括:
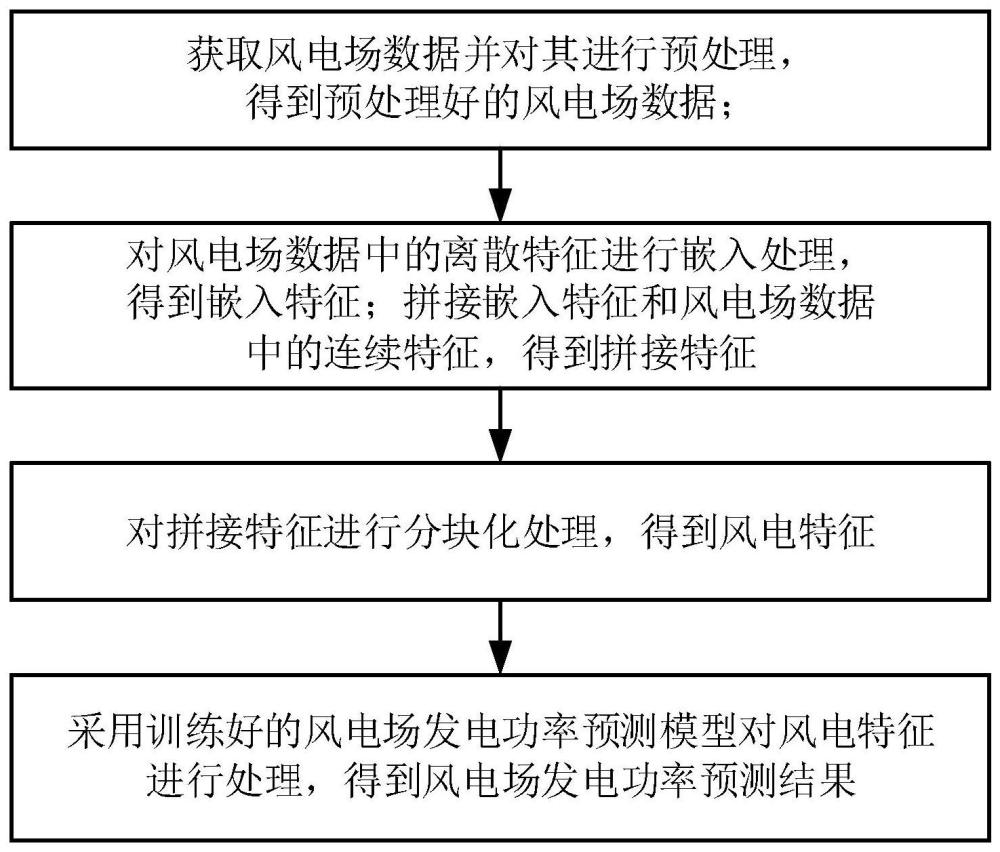
2、s1:获取风电场数据并对其进行预处理,得到预处理好的风电场数据;其中,风电场数据包括历史气象数据、未来气象数据和发电出力时序数据;
3、s2:对风电场数据中的离散特征进行嵌入处理,得到嵌入特征;拼接嵌入特征和风电场数据中的连续特征,得到拼接特征;
4、s3:对拼接特征进行分块化处理,得到风电特征;
5、s4:采用训练好的风电场发电功率预测模型对风电特征进行处理,得到风电场发电功率预测结果。
6、优选的,步骤s1中,历史气象数据包括历史风速、历史风向、历史温度、历史气压、历史湿度、历史降水量、历史云量和历史太阳辐射;未来气象数据包括预报风速、预报风向、预报温度、预报气压、预报湿度、预报降水量和预报云量;发电出力时序数据包括发电功率、涡轮机状态、负荷需求、涡轮机效率、故障记录数据、维护记录数据、电网调度指令和涡轮机转速。
7、优选的,步骤s4中,风电场发电功率预测模型对风电特征进行处理的过程包括:
8、s41:采用sctconv模块对风电特征进行处理,得到sctconv模块输出特征图;
9、s42:使用ptransformer模块对sctconv模块输出特征图进行时序特征提取,得到综合特征图;
10、s43:将综合特征图输入到特征解码模块中进行处理,得到解码特征;
11、s44:采用enhance模块对解码特征进行处理,得到增强解码特征;
12、s45:将增强解码特征输入到dnn预测模块中进行处理,得到风电场发电功率预测结果。
13、进一步的,sctconv模块对风电特征进行处理的过程包括:
14、对风电特征进行组归一化和加权处理,得到第一特征图;
15、根据预设置的门控阈值将第一特征图划分为信息部分和非信息部分;
16、对信息部分和非信息部分进行重构,得到两个重构信息部分和两个重构非信息部分;
17、将两个重构信息部分相加后通过线性层,得到新重构信息部分;将两个重构非信息部分相加后通过线性层处理,得到新重构非信息部分;
18、拼接两个新重构信息部分,并与两个新重构非信息部分拼接后的结果相加;将相加后的特征图通过线性层处理,得到第二特征图;
19、对第二特征图进行全局平均池化和卷积操作,得到通道注意力权重向量;根据通道注意力权重向量对第二特征图进行处理,得到sctconv模块输出特征图。
20、进一步的,对信息部分和非信息部分进行重构的公式为:
21、
22、
23、其中,x11和x12分别表示第一和第二重构信息部分,x21和x22表示第一和第二重构非信息部分,x1表示信息部分,x2表示非信息部分,size(x)表示x的通道数量,dim=1表示第1个维度。
24、进一步的,ptransformer模块对sctconv模块输出特征图进行时序特征提取的过程包括:
25、根据sctconv模块输出特征图计算query值、key值和value值;根据query值和key值计算注意力分数矩阵;
26、对注意力分数矩阵进行稀疏处理,得到稀疏注意力分数矩阵;
27、根据sctconv模块输出特征图、value值、query值和稀疏注意力分数矩阵计算得到综合特征图。
28、进一步的,计算注意力分数矩阵的公式为:
29、
30、
31、
32、其中,attscore表示注意力分数矩阵,xc表示sctconv模块输出特征图,wk表示被查询向量权重,wq表示查询向量权重,d表示数据维度,linear()表示线性层,q表示query值,k表示key值。
33、进一步的,计算综合特征图的公式为:
34、
35、其中,xd表示综合特征图,xc表示sctconv模块输出特征图,sparseattscore表示稀疏注意力分数矩阵,v表示value值,attscore表示注意力分数矩阵,q表示query值,relu()表示relu激活函数。
36、进一步的,特征解码模块对综合特征图的处理过程包括:
37、对综合特征图进行一次卷积操作,得到第一空间特征,对综合特征图进行两次卷积操作,得到第二空间特征;
38、对第一空间特征和第二空间特征进行卷积操作后再进行拼接,分别计算拼接结果的平均值和极差值;
39、根据拼接结果的平均值和极差值计算注意力权重;
40、将注意力权重分别与第一空间特征和第二空间特征相乘,将相乘后的结果通过一个卷积操作,得到解码特征。
41、进一步的,enhance模块对解码特征进行处理的公式为:
42、xf=relu(conv(relu(conv(xe))))
43、z1=maxpool(xf,2)
44、z2=maxpool(xf,4)
45、z1′=upsample(relu(conv(z1)))
46、z2′=upsample(relu(conv(z2)))
47、xf′=concat(z1′,z2′,xf)
48、xg=leakyrelu(relu(conv(xf′))+xe)
49、其中,xe表示解码特征,conv()表示卷积操作,maxpool()表示最大池化操作,relu()表示relu激活函数,upsample()表示上采样操作,concat()表示拼接操作;xf、z1、z2、z1′、z2′和xf′分别表示第一、第二、第三、第四、第五和第六中间参数;leakyrelu()表示leakyrelu激活函数,xg表示增强解码特征。
50、本发明的有益效果为:本发明通过sctconv模块进行特征提取,并结合ptransformer模块对时序数据进行特征提取,有效地捕获了数据中的时空信息和时序关系,为后续的预测任务提供了有力支持;本发明采用spatialattentiondecoder模块对数据进行解码,同时通过enhance模块对特征进行进一步的增强,以增强模型对数据的表征能力和理解能力;本发明结合注意力机制和特征增强技术,有效地提高了预测准确性,同时增强了模型的泛化能力和计算效率,解决了现有技术在时空信息捕捉和模型表征能力上的不足,具有良好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!