本发明涉及新能源发电机组参数辨识领域,具体涉及一种基于rf-nsga-ii算法的双馈风机控制参数多目标分步辨识方法。
背景技术:
1、随着双碳目标提出,新能源在电力系统中占比大幅度提升。一方面,以光伏和风电为代表的新能源发电出力具有随机性、波动性和间歇性,多样化的恶劣自然天气进一步扩大了这种不确定性,是导致电网运行不稳定的因素之一。另一方面,以电力电子并网技术为基础的新能源变流器替换了大量的传统同步机组,电力电子变流器宽频振荡现象严重、谐波分量大,导致电网呈现强不确定性、低惯性、弱抗扰性以及强非线性,造成了电力系统的运行特性发生了根本性变化,为新型电网的安全稳定运行带来巨大挑战。
2、因此,在风电场并网前,有必要对并网可行性及其对电网产生的影响进行多角度、深层次的分析,准确的分析依赖于建立准确的双馈风机单机模型。考虑到针对风电机组工作原理的研究已足够完备,可以认定其模型方程的正确性,那么模型的精度主要取决于其参数的准确性。然而,由于技术厂家的保密,电压控制参数难以直接从铭牌或手册中获取。此外,设备受到工作状态以及故障情况等因素的影响,在运行一段时间后最初设定的并网变流器控制参数会与实际变流器运行特性不符,与实际情况出现较大偏差。鉴于此,通过参数辨识准确获得双馈风机的低电压穿越控制参数并建立仿真模型是一种较为高效的建模方式,具有重要的实用意义。
技术实现思路
1、针对现有双馈风机变流器参数辨识研究中所存在的问题,本发明提供一种基于rf-nsga-ii算法的双馈风机控制参数多目标分步辨识方法,该方法采用rf-nsga-ii算法对影响双馈风机低穿特性的控制参数进行高精度分步辨识,所述辨识方法在低电压穿越工况下具有良好的适应性,并能有效提高参数辨识精度。
2、本发明采取的技术方案为:
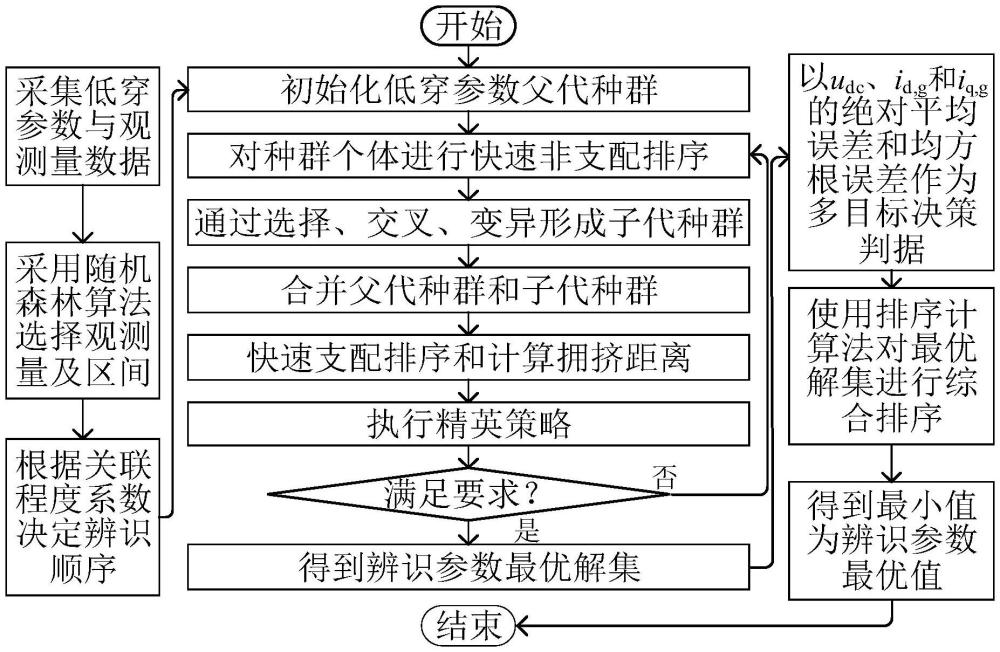
3、基于rf-nsga-ii算法的双馈风机控制参数多目标分步辨识方法,包括以下步骤:
4、步骤1:搭建双馈风机辨识模型,包括网侧变流器,网侧变流器采用电网电压定向矢量控制;当低电压穿越时,网侧变流器提供动态无功支撑,q轴电流内环切换到低电压穿越lvrt控制模式;
5、步骤2:基于随机森林(random forest,rf)算法对双馈风机网侧变流器的特征进行选择,计算udc、id,g、iq,g、p和q等特征的重要性,选择重要性大的udc、id,g和iq,g特征作为观测量;
6、步骤3:采用随机森林袋外数据(out of bag,oob)误差方法来衡量观测量与待辨识参数之间的关联程度;
7、步骤4:利用待辨识参数与观测量的关联程度,筛选出高关联度观测量,计算观测量的各区间关联系数,并据此确定低电压穿越控制参数分步辨识顺序。
8、步骤5:利用nsga-ii算法求出最优参数解,,得到双馈风机待辨识控制参数的辨识结果。所述步骤1中,搭建双馈风机辨识模型,如图11所示,展示了双馈风机的物理结构以及网侧变流器的控制模型。物理结构包括异步电机、rsc机侧变流器、gsc网侧变流器、滤波器以及等效电网的电压源。其滤波器、异步电机、变压器及其他元件电气参数与硬件在环模型相同,参数辨识是对实际风机控制器的参数进行辨识。硬件在环模型是利用rtlab仿真机对实际控制器进行测试的一个模型,得到的数据为实际控制器测试数据。搭建的辨识模型目的是为了将辨识得到的参数填到辨识模型中去,得到数据为仿真数据,将仿真数据与实际控制器测试得到的数据进行对比,进而来验证辨识出参数的准确性。其滤波器、异步电机、变压器及其他元件电气参数与硬件在环模型相同是为了减小与硬件在环模型的差异,降低其他量对两种数据对比误差的影响,进而来说明本发明辨识参数的准确性。
9、网侧变流器采用电网电压定向矢量控制,其中,定子侧电压d轴分量ud,s,定子侧电压us,定子侧电压q轴分量uq,s,ud,s=us,uq,s=0,为使功率因数接近1,通常将q轴参考电流iq,g设置为0;则d轴电流参考值id,g,ref、并网点电压d轴分量ud,c和并网点电压d轴分量uq,c分别可表示为:
10、a=kpa1+∫kia1dt+a2 (1);
11、kp=diag{kp1 kp2 kp3} (2);
12、式(2)中,kpn表示控制参数中的比例系数,n=1,2,3;
13、ki=diag{ki1 ki2 ki3} (3);
14、式(3)中,kin表示控制参数中的积分系数,n=1,2,3;
15、a=[id,g,ref ud,c uq,c]t (4);
16、式(4)中,t表示矩阵的转置。
17、a1=[udc,ref-udc id,g,ref-id,g iq,g,ref-iq,g]t (5);
18、式(5)中,udc、udc,ref分别为变流器之间直流电压值及其电压参考值;id,g为网侧电流d轴分量;iq,g,ref网侧电流q轴分量的参考值;iq,g为网侧电流q轴分量。
19、a2=[0 ud,s+xriq,g uq,s+xrid,g]t (6);
20、式(6)中,ud,s为网侧电压d轴分量,uq,s为网侧电压q轴分量。
21、a3=[us+xriq,g xrid,g] (7);
22、式(7)中,us为网侧电压;xr为滤波电抗;xg为线路电抗,在图11上有表示出来。
23、当低电压穿越时,网侧变流器提供动态无功支撑,q轴电流内环切换到lvrt控制模式,q轴电流参考值iq,g,ref,可由公式(8)得到:
24、
25、式(7)中,k为无功电流支撑系数,为并网点电压标幺值;iq,g,ref(t)为网侧电流q轴分量参考值。为故障时并网点电压标幺值。
26、所述步骤2中,基于随机森林(random forest,rf)算法对双馈风机网侧变流器的特征进行选择,计算udc、id,g、iq,g、p和q等特征的重要性;
27、随即森林特征选择包括了步骤3和步骤4的内容,决策树训练完成后采用步骤3方法分析低电压控制参数与udc、id,g、iq,g、p和q等特征的关联程度。
28、随机森林(random forest,rf)算法中,首先,采用有放回抽样为每棵决策树生成训练集,使用训练集对每棵树进行训练,待所有决策树独立训练完成后,通过计算所有树的预测结果的平均值作为最终预测。
29、
30、式中,y(x)为随机森林对样本x的预测,tk(x)为第k棵树的预测。
31、所述步骤3中,eoob1为每颗决策树对应的袋外数据误差,随机生成噪声干扰xi,noise,将其加入到随机森林袋外数据(out of bag,oob)所有的样本特征xi中,得到新的特征x2i,计算其oob误差为eoob2;
32、xi,noise=rand(min(xi),max(xi)/2) (12);
33、式(12)中,min(xi)为特征xi中最小值;max(xi)为特征xi中最大值;
34、rand(min(xi),max(xi)/2)表示在最小值和1/2最大值之前随机取一个数。
35、x2i=xi+xi,noise (13);
36、将加入噪声干扰的袋外数据放到已经训练好的随机森林模型中进行预测,得到的预测结果就是eoob2。
37、所述步骤3中,关联程度指数indexj,r为:
38、
39、式(14)中,n为随机森林中随机树的数量;为j区间和r参数对应的袋外数据误差;udc,a、udc,b分别为观测量直流电压的a区间和b区间;id,e为有功电流的e区间;kpn和kin分别为控制参数中的比例和积分系数,n=1,2,3;k为无功电流支撑系数。
40、对indexj,r进行归一化处理:
41、
42、式(14)中,indexj,r表示j区间与r参数对应的关联系数;j表示udc,a,udc,b,…,id,e各区间;min(indexr)表示r参数所对应区间中最小的关联系数。
43、依据得到的关联程度系数值大小,确定辨识顺序,具体是:
44、从图3、4、5中可以看出,图3存在5个数值为1的关联系数,图5存在2个数值为1的关联系数,而图4中不存在数值为1的关联系数。图3与图5中关联系数等于1的个数为7,形成了7个参数辨识的充分条件。udc,d与kp1、udc,c与kp2、udc,b与ki1、udc,a与ki1和kp3的关联系数均为1,因此,udc的d区间数据为kp1辨识必选数据,udc的c区间数据为kp2辨识必选数据,udc的b区间数据为ki1辨识必选数据,udc的a区间数据为ki2和kp3辨识必选数据。如图4所示,id,g,a与ki3的关联系数为0.621,为id,g各区间与lvrt参数最大关联系数,于是id,g的a区间数据为ki3辨识必选数据。如图5所示,iq,g,d与k、iq,g,c与ki3的关联系数均为1,iq,g,d与k的关联系数为0.97,因此,可提取iq,g的c和d区间数据为k辨识区间,iq,g的c区间数据为ki3辨识必选数据。
45、由图3、4、5进一步可知,k值仅对iq,g的c和d区间具有较大的影响,而对其他观测量的a、b、c、d、e和f区间关联系数值基本可忽略,因此将k的观测量辨识区间选为iq,g,c和iq,g,d;kp1和ki1仅对udc的a、b、c、d和f区间影响较大,其关联系数均大于0.4,于是将udc的观测量辨识区间选为启动时暂态区间udc,a、故障暂态区间udc,c以及稳态区间udc,b、udc,d和udc,f;kp2、kp3、ki2和ki3对udc,a、udc,b、udc,c、id,g,a、iq,g,a、iq,g,b和iq,g,c区间呈现高相关性,因此选择以上区间作为观测量辨识区间。
46、首先,辨识无功支撑系数k;
47、其次,辨识kp1和ki1;最后,对kp2、kp3、ki2和ki3进行辨识,具体如下:
48、设置待求解目标函数,分别选取与辨识参数高关联程度的udc、id,g和iq,g区间作为观测量;因为k值仅与iq,g的c和d区间呈现高相关性,所以辨识k值时目标函数由iq,g的c和d区间构成。
49、
50、式中,fk1和fk2均为辨识k值的目标函数;
51、fk1,min表示为第一个目标函数值最小,fk2,min为第二个目标函数值最小。iq,g,ci表示c区间q轴无功电流,iq,g,di为d区间q轴无功电流。ncend为c区间末项数据序号。ndend为d区间末项数据序号。ncstart为c区间首项数据序号。ndend为d区间首项数据序号。i为该区间第i个数据点。
52、kp1和ki1对udc,a、udc,b、udc,c、udc,d和udc,f区间呈现高相关性,因此,设置辨识kp1和ki1的目标函数为式(17)所示,并划分为启动时暂态、故障暂态和稳态目标函数。
53、
54、式中,fk1、fk2和fk3均为辨识kp1和ki1值的目标函数;udc,ai、udc,bi、udc,ci、udc,di和udc,fi分别为a、b、c、d和f区间的直流电压值。
55、fk1,min、fk2,min和fk3,min分别为第一、二、三个目标函数值最小;nfstart为f区间首项数据序号。
56、kp2、kp3、ki2和ki3对udc,a、udc,b、udc,c、id,g,a、iq,g,a、iq,g,b和iq,g,c区间呈现高相关性,所以辨识kp2、kp3、ki2和ki3时,可将目标函数设置为式(18):
57、
58、式中,fk1、fk2和fk3均为辨识kp2、kp3、ki2和ki3值的目标函数。
59、naend为a区间末项数据序号;nbend为b区间末项数据序号;id,g,ai为a区间有功电流,iq,g,ai、iq,g,bi和iq,g,ci分别表示a、b、c区间的无功电流。
60、所述步骤5中,采用快速非支配排序遗传算法(non-dominated sorting geneticalgorithm,nsga-ⅱ)对建立的多目标误差函数寻优求解,寻优结果即为辨识模型关键控制参数辨识结果,得到双馈风机待辨识控制参数的辨识结果。具体步骤如下:
61、步骤5.1:首先,对种群进行初始化,以式(19)所示的随机方式生成初始种群。
62、xi=xmin+(xmax-xmin)×rand(0,1) (19);
63、式中,xi为个体初始值,xmin和xmax分别为个体范围下界和上界,rand(0,1)为生成0~1的随机值。
64、其次,采用快速非支配排序将解集分解为不同次序的pareto前沿,以降低计算复杂度;快速非支配排序定义为下式:
65、
66、式中,n表示n个目标函数,表示对于任意的第1至n个目标函数。fj(xk)为xk的第j个目标函数值,xk为解集中任一个解。fj(xr)为xr的第j个目标函数值,xr为解集中任一个解。∧为逻辑运算符,表示“与”运算,表示需要两边同时满足。
67、为保持种群的多样性和判断同一前沿中每个解的优劣,引入拥挤距离策略,计算每个解的拥挤距离,使pareto最优解在目标空间中尽可能分散,拥挤距离计算如式(21)所示。
68、
69、式中,d为拥挤距离;fj(xi+1)表示第i+1个解的目标函数值,fj(xi-1)表示第i-1个解的目标函数值。n表示n个目标函数值。
70、步骤5.2:首先,初始化算法参数,设置种群规模和最大迭代次数分别为10和20,交叉率和变异率分别为0.9和0.3,二进制位串长为15,用以生成种群初始编码;然后,跟据目标函数计算种群个体适应度,适应度大小为目标函数值;最后,求解pareto前沿解,迭代过程中判断是否满足误差要求,若不满足,则返回进行种群选择、交叉和变异步骤,实现种群进化,以满足收误差要求。
71、对pareto前沿解集构建多目标决策选择方法,如式(22)所示,分别以udc、id,g和iq,g的绝对平均误差eu,mae、eid,mae、eiq,mae和均方根误差eu,rmse、eid,rmse和eiq,rmse作为评价指标,利用多目标决策中的排序计算得到各pareto前沿解的综合排序,并选择排序结果最小值作为pareto前沿解集中的最优值。
72、
73、式中,sortr表示每个解计算udc、id,g和iq,g区间绝对平均误差和均方根误差排序后得到的结果。表示解集中每个解的直流电压绝对平均误差的排序结果,按照误差从小到大顺序进行1、2、3…打分。表示解集中每个解的有功电流绝对平均误差的排序结果。表示解集中每个解的无功电流绝对平均误差的排序结果。表示解集中每个解的直流电压均方根误差的排序结果。表示解集中每个解的有功电流均方根误差的排序结果。表示解集中每个解的无功电流均方根误差的排序结果;对所有解udc、id,g和iq,g的绝对平均误差和均方根误差打分进行相加,就得到sort每个解的打分结果。
74、以有功电流id为例,采用式(23)计算以上电压跌落工况时辨识结果与测试结果在a、b、c、d和e区间的平均偏差,评估辨识结果的准确性。
75、
76、式中,fid,i为区间id,i的平均偏差;id,m为有功电流实测数据;id,i为有功电流仿真数据,
77、kstart和kend分别为该区间内首项和末项数据序号。
78、本发明一种基于rf-nsga-ii算法的双馈风机控制参数多目标分步辨识方法,技术效果如下:
79、1)本发明基于rf-nsga-ii算法的双馈风机控制参数多目标分步辨识方法,与以往辨识方法相比,采用了分步辨识方法,有效的避免了同时辨识低灵敏pi参数和高灵敏度k参数导致的低灵敏度pi参数辨识不准确的问题。
80、2)本发明方法还构建了多目标优化函数,对待辨识待参数只选择与其高关联度区间作为待辨识区间,避免了低关联度区间对参数辨识过程的影响,降低了辨识工作量,提高了辨识速度。
81、3)本发明方法对pareto前沿解集构建多目标决策选择方法,综合考虑了各区间的绝对平均误差和均方跟误差,准确的从辨识解集中筛选出辨识最优解。