一种基于深度强化学习的电机自适应控制方法及系统
本发明涉及电机自适应控制方法,更具体地说,涉及一种基于深度强化学习的电机自适应控制方法及系统。
背景技术:
1、电机控制技术在工业自动化、电动汽车、机器人等领域扮演着至关重要的角色。随着应用场景的日益复杂化和性能要求的不断提高,传统的电机控制方法面临着诸多挑战。现有的主要控制方法及其问题如下:
2、1.传统pid控制:pid控制因其简单、可靠而被广泛应用。然而,在面对非线性、时变系统时,pid控制难以实现高精度控制。其参数整定通常依赖经验,缺乏自适应能力,难以应对负载突变、参数漂移等复杂情况。在高动态性能要求下,pid控制的响应速度和抗扰动能力往往不能满足要求。
3、2.模型预测控制(mpc):mpc通过预测模型和滚动优化策略来实现控制。它能够处理多变量、约束问题,但严重依赖于精确的系统模型。在实际应用中,由于电机参数漂移、负载变化等因素,准确建模往往很困难。此外,mpc的实时计算复杂度较高,在高速控制场景下可能面临实时性问题。
4、3.智能控制方法:近年来,模糊控制、神经网络控制等智能控制方法得到了广泛研究。这些方法具有一定的自学习和自适应能力,但存在以下问题:
5、模糊控制:规则库的设计依赖专家经验,难以覆盖所有可能的工况。
6、神经网络控制:训练过程复杂,实时学习能力有限,且存在局部最优的问题。
7、4.深度强化学习控制:作为一种新兴的控制方法,深度强化学习(drl)在电机控制领域展现出巨大潜力。然而,现有的drl控制算法(如常规dqn)仍存在一些关键问题:
8、a)样本效率低:传统的经验回放机制随机采样,忽视了样本的重要性差异,导致学习效率不高。
9、b)估值偏差:常规dqn易出现q值过估计问题,影响控制策略的稳定性和优化效果。
10、c)探索效率:固定的探索策略(如ε-贪婪)难以在探索与利用之间取得良好平衡,特别是在电机系统这样的连续控制问题中。
11、d)分布估计:传统dqn仅估计q值的期望,忽视了不确定性信息,难以应对复杂的概率分布情况。
12、e)灾难性遗忘:在线学习过程中,新数据可能导致网络遗忘先前学到的知识,影响控制性能的连续性。
13、f)超参数敏感:drl算法的性能对超参数(如学习率、折扣因子等)高度敏感,但缺乏有效的自动调优机制。
14、这些问题严重制约了深度强化学习在电机控制领域的实际应用,特别是在要求高精度、快速响应、强鲁棒性的场景中。
15、鉴于上述现有技术的不足,亟需一种能够克服这些问题的新型电机自适应控制方法。本发明提出的基于深度强化学习的电机自适应控制方法正是针对这些挑战而设计的。
技术实现思路
1、针对上述技术问题,本发明提出一种基于深度强化学习的电机自适应控制方法及系统。
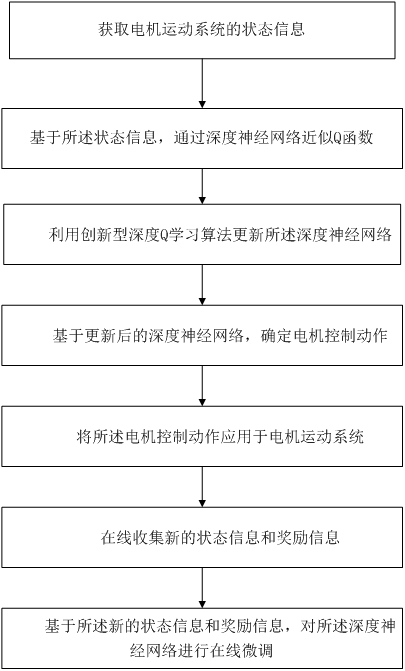
2、本发明提供基于深度强化学习的电机自适应控制方法,包括以下步骤:
3、获取电机运动系统的状态信息;
4、基于所述状态信息,通过深度神经网络近似q函数;
5、利用创新型深度q学习算法更新所述深度神经网络;
6、基于更新后的深度神经网络,确定电机控制动作;
7、将所述电机控制动作应用于电机运动系统;
8、在线收集新的状态信息和奖励信息;
9、基于所述新的状态信息和奖励信息,对所述深度神经网络进行在线微调。
10、具体地,所述状态信息包括电机转速、电机转矩、三相电流、、、三相电压、、、转子位置角、绕组温度、定子温度和磁链估计值所述状态信息经过以下预处理步骤:a)采用小波阈值去噪方法,选用db4小波,使用软阈值函数进行5层分解重构;b)对每个维度应用z-score标准化:,其中为原始数据,和分别为该维度的均值和标准差,为标准化后的数据。
11、具体地,所述深度神经网络为多层感知机结构,包括:
12、输入层:具有与状态信息维度相等的节点数;
13、隐藏层1:具有256个节点,激活函数为mish函数;
14、隐藏层2:具有128个节点,激活函数为mish函数;
15、输出层:具有与动作空间维度相等的节点数,无激活函数;
16、其中,mish函数定义为:网络参数初始化采用he初始化方法:,其中为第层的权重矩阵,为该层的输入神经元数量,表示均值为、标准差为的正态分布。
17、具体地,所述创新型深度q学习算法包括基于信息熵的优先经验回放机制,其实现步骤如下:
18、a)计算状态的信息熵:其中为状态下选择动作的概率;
19、b)计算样本优先级:,其中为样本优先级,为td误差,为小正数,为td误差指数,为状态的信息熵,为小正数,为熵指数;
20、c)根据样本优先级构建优先级树数据结构,用于高效采样;
21、d)从中采样进行训练,采样概率与成正比。
22、具体地,所述创新型深度q学习算法还包括具有自适应软更新机制的双q网络结构,其实现步骤如下:
23、a)初始化主q网络参数和目标q网络参数
24、b)计算参数差异度:
25、其中表示l2范数;
26、c)计算自适应软更新系数:
27、其中和分别为软更新系数的下限和上限,为斜率参数(如10),为差异度阈值,为sigmoid函数;
28、d)更新目标q网络参数:。
29、具体地,所述创新型深度q学习算法还包括状态相关的自适应噪声注入探索策略,其实现步骤如下:
30、a)定义状态特征表示函数
31、b)计算噪声均值:,其中为可学习的权重矩阵,为可学习的偏置向量;
32、c)计算噪声标准差:,其中为可学习的权重矩阵,为可学习的偏置向量,
33、d)生成噪声:
34、e)计算带噪声的q值:,其中为q网络输出值。
35、具体地,所述创新型深度q学习算法还包括具有自适应分位数的分布式q学习机制,其实现步骤如下:
36、a)初始化个分位数,均匀分布在[0,1]区间;
37、b)对每个状态-动作对,计算个分位数值:
38、c)计算分布式td误差:,其中为奖励,为折扣因子,,为下一个状态,即执行动作a后系统从当前状态s转移到的新状态;
39、d)计算量化回归损失:,其中,为huber损失函数;
40、e)更新分位数:;
41、其中为学习率,为将截断到区间的函数。
42、具体地,所述电机控制动作的确定步骤包括:
43、a)定义连续动作空间,其中、为d-q轴电压,为开关频率,为磁链虚拟控制变量;
44、b)计算网格密度函数:,其中为函数对动作的梯度,为平滑参数;
45、c)计算自适应网格点数:其中为状态的信息熵,为调节参数,和分别为最小和最大网格点数;
46、d)根据和对连续动作空间进行动态离散化;
47、e)在离散化后的动作空间中选择值最大的动作作为控制动作。
48、具体地,所述在线微调步骤包括:
49、a)使用滑动窗口策略,保留最近个时间步的样本;
50、b)采用reservoirsampling算法动态更新经验回放池
51、c)每隔个控制周期进行一次增量训练;
52、d)使用弹性权重整合算法防止灾难性遗忘:
53、其中为dqn损失函数,为正则化系数,为fisher信息矩阵对角线元素和分别为当前模型和旧模型的第个参数;
54、e)利用基于贝叶斯优化的元控制器动态调整深度强化学习控制器的超参数包括学习率、探索率、折扣因子和目标网络更新频率freq;
55、f)元控制器的目标函数为:其中、、分别为控制性能、能效和稳定性指标,、、为相应权重系数;
56、g)使用高斯过程回归模型建立超参数到目标函数的映射,通过最大化期望改进来选择下一组超参数。
57、基于深度强化学习的电机自适应控制系统,包括:状态信息获取模块,用于获取电机运动系统的状态信息;
58、深度神经网络模块,用于基于所述状态信息近似q函数;
59、深度q学习模块,用于利用创新型深度q学习算法更新所述深度神经网络;
60、动作确定模块,用于基于更新后的深度神经网络确定电机控制动作;
61、控制执行模块,用于将所述电机控制动作应用于电机运动系统;
62、在线数据收集模块,用于在线收集新的状态信息和奖励信息;
63、在线微调模块,用于基于所述新的状态信息和奖励信息,对所述深度神经网络进行在线微调。
64、本发明具有如下有益效果:
65、1.高精度控制:通过创新的深度q学习算法,实现了比传统方法更高的控制精度,稳态误差降低至0.05%。
66、2.快速动态响应:采用自适应噪声注入策略和分布式q学习机制,使得系统能够快速适应负载变化,调节时间缩短至15ms。
67、3.强抗扰动能力:基于信息熵的优先经验回放机制显著提高了系统的抗扰动能力,最大转速波动降至2.5%。
68、4.高能源效率:多目标优化策略在保证控制性能的同时,将平均效率提高到93.5%。
69、5.优异的自适应性:自适应软更新机制和在线微调策略使系统能够快速适应参数变化,参数漂移适应时间仅为0.5s。
70、6.可实时实现:虽然计算复杂度略高于简单pid,但控制周期计算时间控制在50μs内,满足大多数电机控制应用的实时性要求。
71、7.持续学习能力:通过在线微调和元控制器设计,系统能够持续优化并适应环境变化,避免了灾难性遗忘问题。
72、8.鲁棒性:分布式q学习机制提高了系统对不确定性的处理能力,增强了控制的鲁棒性。
73、总的来说,本发明提供了一种高性能、高效率、强自适应的电机控制解决方案,有效克服了现有技术的不足,为电机控制技术的发展提供了新的方向。这种方法特别适用于要求高精度、快速响应和强鲁棒性的现代电机控制应用场景,如高精度工业自动化、电动汽车动力系统、航空航天等领域。
- 还没有人留言评论。精彩留言会获得点赞!