新能源送出受阻场景下的关键输电断面识别方法及系统与流程
本发明属于电力系统自动化,具体涉及一种新能源送出受阻场景下的关键输电断面识别方法及系统。
背景技术:
1、新型电力系统呈现出高比例新能源并网快速发展和分布式电源、储能、电力电子设备等柔性负荷比例快速增加的趋势,系统运行的不确定性显著增强,容易发生电源侧、负荷侧重构现象,运行数据的复杂程度大大增加。为了保障全网供电能力、电力现货市场运行和绿电交易等需求,大规模新能源消纳送出涉及的调度策略较为复杂。
2、在现有技术中,区域性储能电站的出现并不能完全解决和平抑区域局部新能源波动给电网带来的调控风险。新能源场站外送受阻通常由于市场消纳能力、电网送电通道传输容量、调峰容量不够以及电网故障导致的电力损失等因素造成。
3、为了实现新能源大规模消纳送出,判断外送通道传输能力十分必要,目前自动控制软件通常由固定策略进行功率分配,无法实现最优控制。
4、随着电网数智化的演进,社会环境数据接入电网,调度对象类型和数量呈指数级增长,电网内外部不确定性影响因素增多,当前广泛采用的确定性、模型驱动优化方法的决策可行性及计算效率等方面均不能完全满足促进新能源消纳送出的优化调度要求。
技术实现思路
1、本发明的目的在于针对上述现有技术中的问题,提供一种新能源送出受阻场景下的关键输电断面识别方法及系统,在新能源受阻的条件下对外送通道资源进行分析,判断关键断面的输送能力,优化后续的调度控制计算过程,辅助生成最优的场站日内调度策略。
2、为了实现上述目的,本发明有如下的技术方案:
3、第一方面,提供一种新能源送出受阻场景下的关键输电断面识别方法,包括:
4、获取区域电网输电线路和断面的历史、实时或未来潮流运行值及限额信息,计算得出断面负载率;
5、将断面负载率进行分类,找出目标区间的断面负载率,并抽取对应时刻的电网运行断面作为关联分析样本;
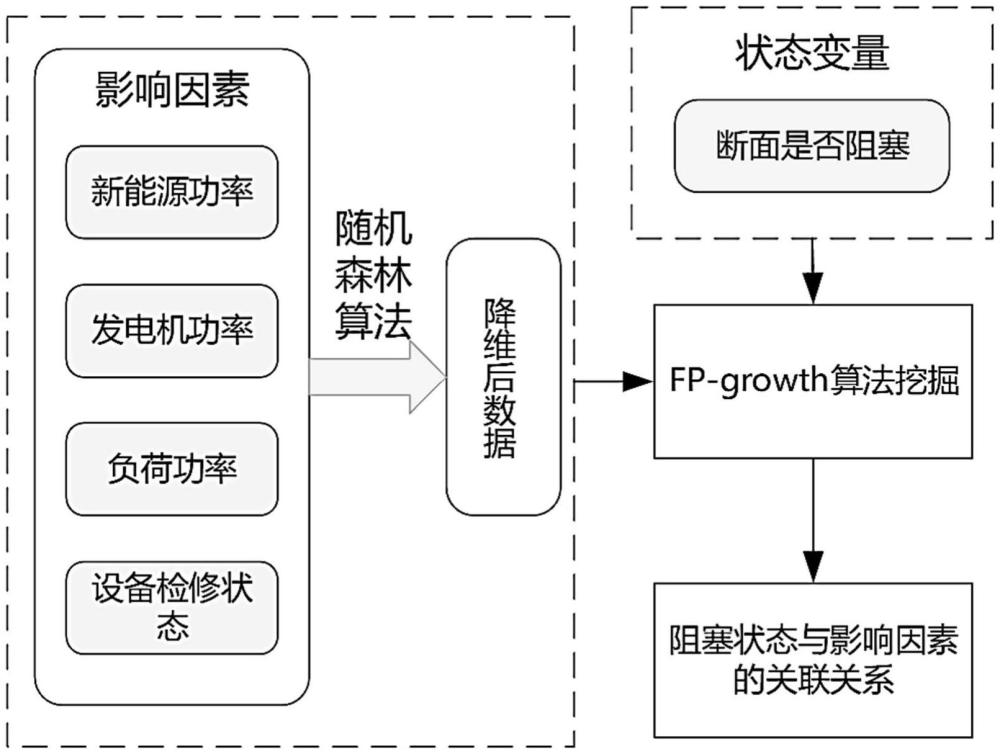
6、基于关联分析样本中的电网运行断面,对预先获取的电网运行状态数据进行影响因素降维分析,得到关键影响因素数据;
7、将电网运行断面是否重、满、过载作为状态量,挖掘状态量与关键影响因素数据之间的关联关系,根据关联关系找出阻碍新能源送出的关键输电断面。
8、作为一种优选的方案,所述断面负载率按照如下表达式进行计算:
9、
10、式中,nline表示线路数,ii表示第i条线路的电流运行值,ti表示第i条线路的热稳定极限,j表示输电断面编号。
11、作为一种优选的方案,所述将断面负载率进行分类,找出目标区间的断面负载率的步骤采用k-means聚类分析法进行分类,包括:
12、设定聚类个数k,并从n个场景中随机选择k个场景作为初始聚类中心zk;
13、计算每个场景xm到各个聚类中心的距离di,k,根据最小距离原则划分类别;
14、按下式计算新的聚类中心:
15、
16、式中,ck为第k类所有对象;nk为第k类包含的对象数;
17、重复上述步骤直到分类不再变化,得到分类结果。
18、作为一种优选的方案,所述预先获取的电网运行状态数据包括新能源功率上下限、发电机功率上下限、负荷功率上下限、联络线功率上下限以及设备检修状态所对应的数据。
19、作为一种优选的方案,所述基于关联分析样本中的电网运行断面,对预先获取的电网运行状态数据进行影响因素降维分析,得到关键影响因素数据的步骤采用随机森林算法进行影响因素降维分析,包括:
20、从原始数据集中每次随机有放回的抽样选取与原始数据集相同数量的样本数据,构造数据子集;
21、每个数据子集从所有待选择的特征中随机选取设定数量个最优特征作为决策树的输入特征,即影响因素;
22、根据每个数据子集分别得到每棵决策树,由多棵决策树共同组成随机森林。
23、作为一种优选的方案,在所述将电网运行断面是否重、满、过载作为状态量,挖掘状态量与关键影响因素数据之间的关联关系,根据关联关系找出阻碍新能源送出的关键输电断面的步骤中,采用fp-growth算法挖掘状态量与关键影响因素数据之间的关联关系,包括:
24、获取电网运行数据、目标区间断面负载率所对应的电网运行断面以及关键影响因素数据,生成关联关系数据库;
25、第一次对关联关系数据库进行扫描,记录每个影响因素特征量和新能源送出受阻条件下目标区间断面负载率所对应的电网运行断面的支持度,并选出满足支持度条件的项,依据支持度大小降序列出每个事务中的项,构造对应的条件投影数据库和投影fp-tree;
26、第二次对关联关系数据库进行扫描,构建新的fp-tree,遍历每个事务中经过筛选以及重新排序后的波动特征值和风险指标状态项,将每项所代表的信息压缩至fp-tree结构中,保留数据之间的关联性;重复上述过程直到新构造的fp-tree为空,或者只包含一条路径;
27、通过构建的fp-tree查找频繁项集,依据频繁项集找出阻碍新能源送出的关键输电断面。
28、作为一种优选的方案,在所述第二次对关联关系数据库进行扫描,构建新的fp-tree,遍历每个事务中经过筛选以及重新排序后的波动特征值和风险指标状态项,将每项所代表的信息压缩至fp-tree结构中,保留数据之间的关联性的步骤中,确定关联关系数据库出现状态变化的项,以及对应路径上状态变化的项出现的次数,某一项在所有路径上出现的次数之和等于这一项在数据库中出现的频率。
29、作为一种优选的方案,在所述通过构建的fp-tree查找频繁项集的步骤中,找到每个项的条件模式基,通过递归调用树结构,删除不满足最小支持度的项,如果最后的树结构只剩一条路径,则穷举出所有组合即可,如果树结构不是单一路径,则继续递归调用树结构,直到只剩单一路径为止;当构建的fp-tree为空时,则对应fp-tree的前缀即为频繁模式;当构建的fp-tree只包含一条路径时,则通过枚举所有可能组合并与对应fp-tree的前缀连接,即得到频繁模式。
30、作为一种优选的方案,在所述通过构建的fp-tree查找频繁项集的步骤中,当完成fp-tree的构建后,以树的尾项为基准按照自下而上的顺序挖掘fp-tree,依次得到不同路径的频繁项集,通过对不同路径的频繁项集取并集,即得到关联关系数据库中所有的频繁项集。
31、第二方面,提供一种新能源送出受阻场景下的关键输电断面识别系统,包括:
32、断面负载率计算模块,用于获取区域电网输电线路和断面的历史、实时或未来潮流运行值及限额信息,计算得出断面负载率;
33、关联分析样本抽取模块,用于将断面负载率进行分类,找出目标区间的断面负载率,并抽取对应时刻的电网运行断面作为关联分析样本;
34、关键影响因素数据分析模块,用于基于关联分析样本中的电网运行断面,对预先获取的电网运行状态数据进行影响因素降维分析,得到关键影响因素数据;
35、关键输电断面确定模块,用于将电网运行断面是否重、满、过载作为状态量,挖掘状态量与关键影响因素数据之间的关联关系,根据关联关系找出阻碍新能源送出的关键输电断面。
36、作为一种优选的方案,所述断面负载率计算模块按照如下表达式计算断面负载率:
37、
38、式中,nline表示线路数,ii表示第i条线路的电流运行值,ti表示第i条线路的热稳定极限,j表示输电断面编号。
39、作为一种优选的方案,所述关联分析样本抽取模块采用k-means聚类分析法进行分类,包括:
40、设定聚类个数k,并从n个场景中随机选择k个场景作为初始聚类中心zk;
41、计算每个场景xm到各个聚类中心的距离di,k,根据最小距离原则划分类别;
42、按下式计算新的聚类中心:
43、
44、式中,ck为第k类所有对象;nk为第k类包含的对象数;
45、重复上述步骤直到分类不再变化,得到分类结果。
46、作为一种优选的方案,所述预先获取的电网运行状态数据包括新能源功率上下限、发电机功率上下限、负荷功率上下限、联络线功率上下限以及设备检修状态所对应的数据;
47、所述关键影响因素数据分析模块采用随机森林算法进行影响因素降维分析,包括:
48、从原始数据集中每次随机有放回的抽样选取与原始数据集相同数量的样本数据,构造数据子集;
49、每个数据子集从所有待选择的特征中随机选取设定数量个最优特征作为决策树的输入特征,即影响因素;
50、根据每个数据子集分别得到每棵决策树,由多棵决策树共同组成随机森林。
51、作为一种优选的方案,所述关键输电断面确定模块采用fp-growth算法挖掘状态量与关键影响因素数据之间的关联关系,包括:
52、获取电网运行数据、目标区间断面负载率所对应的电网运行断面以及关键影响因素数据,生成关联关系数据库;
53、第一次对关联关系数据库进行扫描,记录每个影响因素特征量和新能源送出受阻条件下目标区间断面负载率所对应的电网运行断面的支持度,并选出满足支持度条件的项,依据支持度大小降序列出每个事务中的项,构造对应的条件投影数据库和投影fp-tree;
54、第二次对关联关系数据库进行扫描,构建新的fp-tree,遍历每个事务中经过筛选以及重新排序后的波动特征值和风险指标状态项,将每项所代表的信息压缩至fp-tree结构中,保留数据之间的关联性;重复上述过程直到新构造的fp-tree为空,或者只包含一条路径;
55、通过构建的fp-tree查找频繁项集,依据频繁项集找出阻碍新能源送出的关键输电断面。
56、作为一种优选的方案,所述关键输电断面确定模块在第二次对关联关系数据库进行扫描,构建新的fp-tree时,确定关联关系数据库中出现状态变化的项,以及对应路径上状态变化的项出现的次数,某一项在所有路径上出现的次数之和等于这一项在数据库中出现的频率。
57、作为一种优选的方案,所述关键输电断面确定模块在通过构建的fp-tree查找频繁项集时,找到每个项的条件模式基,通过递归调用树结构,删除不满足最小支持度的项,如果最后的树结构只剩一条路径,则穷举出所有组合即可,如果树结构不是单一路径,则继续递归调用树结构,直到只剩单一路径为止;当构建的fp-tree为空时,则对应fp-tree的前缀即为频繁模式;当构建的fp-tree只包含一条路径时,则通过枚举所有可能组合并与对应fp-tree的前缀连接,即得到频繁模式。
58、作为一种优选的方案,所述关键输电断面确定模块在通过构建的fp-tree查找频繁项集时,当完成fp-tree的构建后,以树的尾项为基准按照自下而上的顺序挖掘fp-tree,依次得到不同路径的频繁项集,通过对不同路径的频繁项集取并集,即得到关联关系数据库中所有的频繁项集。
59、第三方面,提供一种电子设备,包括处理器和存储器,所述处理器用于执行存储器中存储的计算机程序以实现如第一方面所述新能源送出受阻场景下的关键输电断面识别方法。
60、第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有至少一个指令,所述至少一个指令被处理器执行时实现如第一方面所述新能源送出受阻场景下的关键输电断面识别方法。
61、相较于现有技术,本发明的第一方面至少具有如下的有益效果:
62、基于区域电网输电线路和断面的历史、实时或未来潮流运行值及限额信息,计算得出断面负载率,将断面负载率分为“高中低”三档,分析统计阻塞高发的电网运行断面,为提取阻塞电网运行断面的典型特征提供数据基础。针对电网运行断面阻塞与预先获取的电网运行状态数据进行影响因素降维分析,得到关键影响因素数据。通过关联程度分析方法,实现影响阻塞发生对应的电网运行关键输电断面识别。本发明新能源送出受阻场景下的关键输电断面识别方法在新能源受阻条件下,实现针对外送通道资源进行分析,判断关键输电断面的输送能力,能够用于基于优化算法的“储能+新能源”场站日内调度策略的生成,为后续优化计算调度控制服务,能够为日内调控辅助决策优化求解中缩减网络约束规模提供技术支撑。
63、更进一步的,本发明采用随机森林算法基于关联分析样本中的电网运行断面,对预先获取的电网运行状态数据进行影响因素降维分析,得到关键影响因素数据,可以对新能源受阻的影响因素进行特征压缩,实现对运行数据提取影响新能源关键外送断面消纳能力的原因降维分析,为新能源关键外送断面消纳能力关联分析提供支撑。
64、更进一步的,本发明利用频繁项集搜索fp-growth算法挖掘状态量与关键影响因素数据之间的关联关系,分析影响关键输电断面受阻的主要因素,为新能源受阻条件下开展优化调度和功率调节提供支撑,可避免数据量增加时大量候选项集的产生,并且只需要扫描关联关系数据库两次,即可快速找出频繁项集,实现高效计算。
65、可以理解的是,上述第二方面至第四方面的有益效果可以参见上述第一方面中的相关描述,在此不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!