一种FIR滤波器组及滤波方法与流程
本发明涉及数字信号处理技术,尤其涉及一种有限长单位冲激响应(FIR,Finite Impulse Response)滤波器组及滤波方法。
背景技术:
近年来由于软件定义网络(SDN,Software Defined Network)、软件定义存储、软件定义云计算等软件定义概念的提出,使得对硬件产品的功能灵活性、易扩展性、可重构性需求日益增强。
FIR滤波器是数字信号处理系统中最基本的元件,在通信、图像处理、模式识别等领域都有着广泛的应用,例如,在无线通信系统中的数字上变频器(DUC,Digital Up Converter)和数字下变频器(DDC,Digital Down Converter)的链路中,包含有大量的FIR滤波器。
但是,目前在专用集成电路(ASIC,Application Specific Integrated Circuit)设计中,尽管出现了针对单个滤波器结构的可重构改进,但是,对于无法提供对于滤波器组的可重构能力;而且,目前所出现的通过修改滤波器间的连接关系来实现滤波器组的可重构方案,却又缺乏单个滤波器的可重构能力,资源利用率低。无法在多种制式的通信标准长期共存的情况下,实现可重构、可重用且灵活可配置。
技术实现要素:
为解决上述技术问题,本发明实施例期望提供一种FIR滤波器组及滤波方法,实现滤波器组内部硬件资源可重构、可重用且灵活可配置,以及在合理的资源和速度的前提下能够满足不同的滤波组合。
本发明的技术方案是这样实现的:
第一方面,本发明实施例提供了FIR滤波器组,所述FIR滤波器组包括相互耦接的控制电路和数据处理电路;所述数据处理电路包括数据流总线阵列、缓存资源池、算术逻辑单元ALU资源池、累加器资源池;所述控制电路包括:数据流控制器、缓存资源映射器、滤波系数存储器、ALU控制器、累加资源组织器和输出时序控制器;其中,
所述数据流总线阵列,用于从输入端口接收输入数据,从所述累加器资源池接收输出数据;以及,根据所述数据流控制器的控制将所述输入数据及所述输出数据传输至所述缓存资源池,或者根据所述输出时序控制器的控制将所述输出数据传输至输出端口;
所述缓存资源池,包括至少一个缓存资源块,用于根据所述数据流控制器的控制接收所述数据流总线阵列传输的数据,并通过所述数据流控制器根据滤波器阶数、个数和级联关系对所述数据流总线阵列传输的数据进行控制,形成待计算的滤波缓存;
所述ALU资源池包括至少一个ALU,用于根据所述缓存资源映射器、所述滤波系数存储器以及所述ALU控制器对所述待计算的滤波缓存进行乘加计算,并将乘加计算的计算结果通过所述累加资源组织器传输至所述累加器资源池;
所述累加器资源池包括至少一个累加器,每个累加器与所述ALU资源池中的ALU一一对应,用于通过所述累加资源组织器根据滤波资源分配情况对所述ALU进行乘加计算的计算结果进行相加,得到滤波结果;并将所述滤波结果传输至所述数据流总线阵列。
在上述方案中,所述数据流总线阵列中数据流总线的数据结构包括:数据、与数据对应的缓存资源块标识和用于表征数据为新数据的标识位。
在上述方案中,所述缓存资源池中每个缓存资源块均包括至少一个串联的寄存器组,一个缓存级联开关;所述每个缓存资源块的缓存级联开关包括三个输入端和一个输出端,其中,所述缓存级联开关的第一输入端与所述数据流总线阵列相连,所述缓存级联开关的第二输入端与前级缓存资源块的输出相连; 所述缓存级联开关的第三输入端与所述数据流控制器相连;所述缓存级联开关的输出端与所述寄存器组的输入端相连。
在上述方案中,当所述数据流控制器控制所述缓存级联开关的第一输入端开通,第二输入端关闭时,所述缓存资源块的寄存器组的输入数据由所述数据流总线阵列提供;
当所述数据流控制器控制所述缓存级联开关的第一输入端关闭,第二输入端开通时,所述缓存资源块的寄存器组的输入数据由前级的缓存资源块提供。
在上述方案中,所述ALU资源池中的每个ALU均包括两个ALU缓存块,加法器、乘法器以及截位电路;其中,所述两个ALU缓存块分别对应于两个缓存资源块所输出的待运算的滤波缓存,所述每个ALU缓存块的大小与所述缓存资源块中寄存器组的大小相同。
在上述方案中,两个ALU缓存块分别连接在加法器的两个输入端口,通过所述ALU控制器将两个ALU缓存块的缓存数据送入所述加法器;
所述加法器输出端与所述乘法器相连,所述乘法器的另一输入端与所述滤波系数存储器相连,其中,所述滤波系数存储器中的系数通过软件初始化后,以预设的顺序输入所述乘法器进行滤波运算;
所述乘法器运算后的运算结果经过所述截位电路进行截位后送入所述累加资源池。
在上述方案中,所述累加器资源池中的每个累加器均包括一个加法器、截位器和一个缓存器;其中,所述加法器用于两个ALU数据的相加或自累加;所述累加资源组织器根据滤波资源分配情况对ALU进行乘加计算的计算结果通过所述加法器、所述截位器和所述缓存器进行相加,得到滤波结果。
在上述方案中,所述数据流控制器用于根据配置控制所述累加器资源池中的累加器的滤波结果输出到所述数据流总线阵列;或者,
所述数据流控制器用于根据配置控制所述累加器资源池中的累加器的滤波结果输出至所述输出端口。
第二方面,本发明实施例提供了一种滤波方法,所述方法应用于权利要求 1至8任一项所述的FIR滤波器组,所述方法包括:
通过输入端口接收到输入数据后,将所述输入数据传输至数据流总线阵列;
缓存资源池中的缓存资源块根据数据流控制器的控制接收所述数据流总线阵列传输的数据,并通过所述数据流控制器根据滤波器阶数、个数和级联关系进行控制,形成待计算的滤波缓存;
算术逻辑单元ALU资源池中的ALU根据缓存资源映射器、滤波系数存储器以及ALU控制器对所述待计算的滤波缓存进行乘加计算,并将乘加计算的计算结果通过累加资源组织器传输至累加器资源池;
所述累加器资源池中的累加器通过累加资源组织器根据滤波资源分配情况对所述ALU进行乘加计算的计算结果进行相加,得到滤波结果;
根据所述数据流控制器的控制将所述滤波结果传输至所述数据流总线阵列,并将所述数据流总线阵列中的滤波结果传输至输出端口。
在上述方案中,所述方法还包括:所述数据流控制器通过控制所述数据流总线阵列将所述滤波结果回环至缓存资源块。
本发明实施例提供了一种FIR滤波器组及滤波方法,通过将滤波器的所有硬件资源进行统一考量,从而实现滤波器组内部硬件资源可重构、可重用且灵活可配置,以及在合理的资源和速度的前提下能够满足不同的滤波组合。
附图说明
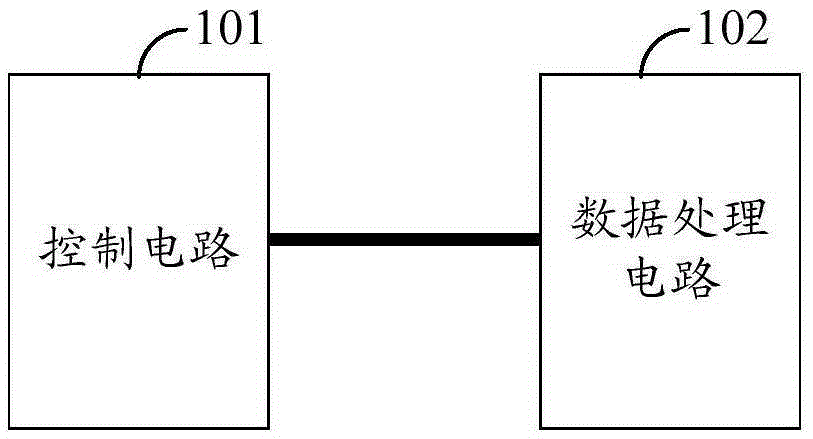
图1为本发明实施例所提出的一种FIR滤波器组的结构示意图;
图2为本发明实施例所提出的另一种FIR滤波器组的结构示意图;
图3为本发明实施例所提出的数据流总线阵列中数据流总线的数据结构示意图;
图4为本发明实施例所提出的缓存资源池中所包括的缓存资源块结构以及缓存资源块之间的连接关系示意图;
图5为本发明实施例所提出的ALU资源池中ALU的结构示意图;
图6为本发明实施例所提出的一种滤波方法的流程示意图;
图7为本发明实施例所提出的一种缓存资源块的数据结构示意图;
图8为本发明实施例所提出的另一种缓存资源块的数据结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
实施例一
由于本发明实施例的技术方案的基本思想是将滤波器的所有硬件资源进行统一考量,使得能够根据不同的应用场景,对滤波资源进行重组,从而形成不同的滤波器组的结构,实现滤波器组的可重构。
参见图1,其示出了本发明实施例所提出的一种FIR滤波器组10的结构。如图1所示,FIR滤波器组10包括:数据处理电路101和控制电路102两个组成部分,这两个组成部分相互之间是耦接的关系。可以理解地,由于本实施例是对于FIR滤波器组10的结构进行实例性的说明,因此,对于FIR滤波器组10相关的外部电路及电器元件,本实施例不作具体赘述,本领域技术人员可以根据实际应用场景的需要对本实施例所述的FIR滤波器组10的相关外部电路进行设计以满足相应的应用需求。
参见图2所示的FIR滤波器组10的具体结构,数据处理电路101可以包括数据流总线阵列1011、缓存资源池1012、ALU资源池1013以及累加器资源池1014;而控制电路102则可以包括:数据流控制器1021、缓存资源映射器1022、滤波系数存储器1023、ALU控制器1024、累加资源组织器1025以及输出时序控制器1026;其中,
数据流总线阵列1011,用于从输入端口接收输入数据,从累加器资源池1014接收输出数据;以及,根据数据流控制器1021的控制将所述输入数据及所述输出数据传输至缓存资源池1012,或者根据输出时序控制器1026的控制将所述输出数据传输至输出端口;
缓存资源池1012,包括至少一个缓存资源块,用于根据数据流控制器1021 的控制接收数据流总线阵列1011传输的数据,并通过数据流控制器1021根据滤波器阶数、个数和级联关系进行控制,形成待计算的滤波缓存;
ALU资源池1013包括至少一个ALU,用于根据缓存资源映射器1022、滤波系数存储器1023以及ALU控制器1024对待计算的滤波缓存进行乘加计算,并将乘加计算的计算结果通过累加资源组织器1025传输至累加器资源池1014;
累加器资源池1014包括至少一个累加器,每个累加器与ALU资源池1013中的一个ALU对应,用于通过累加资源组织器1025根据滤波资源分配情况对ALU进行乘加计算的计算结果进行相加,得到滤波结果;并将滤波结果传输至数据流总线阵列1011。
在图2所示的FIR滤波器组10的具体结构的基础上,示例性地,参见图3,数据流总线阵列1011中数据流总线的数据结构可以包括:数据、与数据对应的缓存资源块标识ID和用于表征数据为新数据的标识位dv。其中,数据的位宽Data Width由从输入端口所接收到的输入数据的位宽决定;数据对应的缓存资源块标识位宽由缓存资源池1012中缓存资源块的数量决定;在用于表征数据为新数据的标识位dv有效的情况下,缓存资源块入口处判断数据流总线中与数据对应的缓存资源块标识ID是否与缓存资源块自身的ID相符,如果相符且该缓存资源块的缓存级联开关指向数据流总线阵列1011的输入数据则该数据往后移位,否则忽略。可以理解的是,在具体设计中需要考虑到流量的需求,可以有至少一组(例如m组)数据流总线组成数据流总线阵列1011。在缓存资源块入口处根据数据流控制器1021进行控制选择即可。
在图2所示的FIR滤波器组10的具体结构的基础上,示例性地,参见图4,其示出了缓存资源池1012中所包括的缓存资源块结构以及缓存资源块之间的连接关系,如图4中点划线框所示,每个缓存资源块都包括至少一个串联的寄存器组,一个缓存级联开关;每个缓存资源块的缓存级联开关包括三个输入端和一个输出端,其中,缓存级联开关的第一输入端与数据流总线阵列1011相连,需要说明的是,第一输入端可以通过数据流总线阵列1011中数据流总线与数据对应的缓存资源块标识ID来确定该缓存资源块所接收的数据流总线阵列1011 中数据流总线的数据;缓存级联开关的第二输入端与前级缓存资源块的输出相连;缓存级联开关的第三输入端与数据流控制器1021相连;缓存级联开关的输出端与寄存器组的输入端相连。
数据流控制器1021可以根据滤波器阶数、个数和级联关系来控制缓存级联开关的第一输入端和第二输入端的通断,从而通过控制所述寄存器组的输入数据的来源对滤波器阶数、个数和级联关系进行控制,还实现了缓存资源的重构。
具体地,当数据流控制器1021控制缓存级联开关的第一输入端开通,第二输入端关闭时,缓存资源块的寄存器组的输入数据由数据流总线阵列1011提供,数据流总线阵列1011中可以提供由输入端口接收的输入数据,也可以提供由累加器资源池1014接收的输出数据,当寄存器组的输入数据是由数据流总线阵列1011提供的由累加器资源池1014接收的输出数据时,也就实现了滤波器之间的级联;而当数据流控制器1021控制缓存级联开关的第一输入端关闭,第二输入端开通时,缓存资源块的寄存器组的输入数据由前级的缓存资源块提供,从而实现了滤波器内部缓存器的级联。
例如,当数据流控制器1021通过控制缓存级联开关来确定缓存资源块的寄存器组的输入数据由数据流总线阵列1011提供,且数据流总线阵列1011中数据流总线的用于表征数据为新数据的标识位dv有效时,缓存资源块中的第一输入端判断数据流总线与数据对应的缓存资源块标识ID与该缓存资源块是否匹配,如果匹配则缓存资源块整体右移。后级缓存资源块如果与前级相连则跟着右移,形成一个待运算的滤波缓存。
需要说明的是,每一个缓存资源块可以通过设置寄存器组中串联的寄存器个数来确定缓存的长度,具体可以将最后几个寄存器旁路掉,从而能够保证系数对称的滤波相的前后缓存资源块数据的对称性,方便后续ALU资源池中,ALU运算单元的复用处理。
在图2所示的FIR滤波器组10的具体结构的基础上,示例性地,参见图5,其示出了ALU资源池1013中ALU的结构,如图5中的点划线框所示,ALU资源池1013中的一个ALU可以包含两个ALU缓存块,加法器、乘法器以及 截位电路。两个ALU缓存块分别与两个缓存资源块的输出的待运算的滤波缓存对应,每个ALU缓存块的大小与缓存资源块中寄存器组的大小相同,从而能够在缓存资源映射器1022的控制下,分时地将缓存资源块输出的待计算的滤波相映射到相应的ALU缓存块上;两个ALU缓存块分别连接在加法器的两个输入端口,比如a端口和b端口,通过ALU控制器1024将两个ALU缓存块的缓存数据送入加法器。加法器输出端与乘法器相连,乘法器的另一输入端与滤波系数存储器1023相连。滤波系数存储器1023中的系数通过软件初始化后,以一定的顺序输入乘法器参加滤波运算。乘法器运算后的运算结果经过截位电路进行截位后送入累加资源池。
具体地,加法器a端口缓存数据在ALU控制器1024的控制下从0地址或者配置地址到高地址依次按步进送入加法器,步进长度默认为1,根据系统需要可以设置不同数字;b端口从高地址或者一个配置地址到0地址依次按步进送入加法器,也可以选择数据0。
示例性地,累加器资源池1014中的一个累加器可以包括一个加法器、截位器和一个缓存器,加法器既可以用于两个ALU数据的相加,也可以作为自累加用。累加资源组织器1025根据滤波资源分配情况对ALU进行乘加计算的计算结果通过加法器、截位器和缓存器进行相加,得到滤波结果。进一步地,还可以根据ALU的复用需求配置累加资源组织器、控制ALU的相加关系和自累加循环次数。
示例性地,数据流控制器1021还可以用于根据配置控制累加器资源池1014中的累加器的滤波结果输出到数据流总线阵列1011,从而通过数据流总线阵列1011将滤波结果回环到相应的缓存资源块进行下一级滤波;或者根据配置控制累加器资源池1014中的累加器的滤波结果输出到output端口。
示例性地,输出时序控制器1026控制输出端口的滤波结果按照预设的时序进行排序后进行输出。
本实施例提供了一种FIR滤波器组,通过将滤波器的所有硬件资源进行统一考量,从而实现滤波器组内部硬件资源可重构、可重用且灵活可配置,以及 在合理的资源和速度的前提下能够满足不同的滤波组合。
实施例二
参见图6,其示出了一种应用于前述实施例所述的FIR滤波器组的滤波方法,FIR滤波器组的具体结构如前述实施例所述,在此不再赘述,滤波方法可以包括:
S601:输入端口接收到输入数据后,将所述输入数据传输至数据流总线阵列;
具体地,将所述输入数据传输至数据流总线阵列,可以包括:
将所述输入数据传输至数据流总线阵列中的数据流总线时对应进行标识ID,并将相应的用于表征数据为新数据的标识位dv设置为有效。
S602:缓存资源池中的缓存资源块根据数据流控制器的控制接收数据流总线阵列传输的数据,并通过数据流控制器根据滤波器阶数、个数和级联关系进行控制,形成待计算的滤波缓存;
其中,每个缓存资源块都包括至少一个串联的寄存器组,一个缓存级联开关;每个缓存资源块的缓存级联开关包括三个输入端和一个输出端,其中,缓存级联开关的第一输入端与数据流总线阵列相连,需要说明的是,第一输入端可以通过数据流总线阵列中数据流总线与数据对应的缓存资源块标识ID来确定该缓存资源块所接收的数据流总线阵列中数据流总线的数据;缓存级联开关的第二输入端与前级缓存资源块的输出相连;缓存级联开关的第三输入端与数据流控制器相连;缓存级联开关的输出端与寄存器组的输入端相连。
S603:ALU资源池中的ALU根据缓存资源映射器、滤波系数存储器以及ALU控制器对所述待计算的滤波缓存进行乘加计算,并将乘加计算的计算结果通过累加资源组织器传输至累加器资源池;
具体地,每个ALU可以包含两个ALU缓存块,加法器、乘法器以及截位电路。两个ALU缓存块分别与两个缓存资源块的输出的待运算的滤波缓存对应,每个ALU缓存块的大小与缓存资源块中寄存器组的大小相同,从而能够在缓存资源映射器的控制下,分时地将缓存资源块输出的待计算的滤波相映射到 相应的ALU缓存块上;两个ALU缓存块分别连接在加法器的两个输入端口,通过ALU控制器将两个ALU缓存块的缓存数据送入加法器。加法器输出端与乘法器相连,乘法器的另一输入端与滤波系数存储器相连。滤波系数存储器中的系数通过软件初始化后,以一定的顺序输入乘法器参加滤波运算。乘法器运算后的运算结果经过截位电路进行截位后送入累加资源池。
S604:累加器资源池中的累加器通过累加资源组织器根据滤波资源分配情况对ALU进行乘加计算的计算结果进行相加,得到滤波结果;
需要说明的是,每个累加器与ALU资源池中的一个ALU对应,每个累加器可以包括一个加法器、截位器和一个缓存器;其中,加法器既可以用于两个ALU数据的相加,也可以作为自累加用。累加资源组织器1025根据滤波资源分配情况对ALU进行乘加计算的计算结果通过加法器、截位器和缓存器进行相加,得到滤波结果。
S605:根据数据流控制器的控制将滤波结果传输至数据流总线阵列,并将数据流总线阵列中的滤波结果传输至输出端口;
可以理解的,输出端口可以在输出时序控制器的控制下,将滤波结果以相应的时序进行输出。
此外,数据流控制器还可以通过控制数据流总线阵列将滤波结果回环到相应的缓存资源块进行下一级滤波,从而实现滤波器的级联。
上述过程是FIR滤波器组对输入数据进行滤波的方法流程,为了说明本实施例技术方案的详细应用,通过实施例三至实施例六共四种具体实施例对FIR滤波器组的应用进行简要说明。
实施例三
以两个串联滤波器为例,设定第一级滤波器为12个系数偶对称,2倍抽取,3倍输入复用比;第二级滤波器为47个系数奇对称,2倍抽取,6倍输入复用比。基于前述实施例所述的FIR滤波器组与滤波方法,具体实施过程如下:
设置第一级滤波器占用标识为ID0、ID1两个缓存资源块,缓存资源块ID0的缓存级联开关设置为与数据流总线阵列相连,缓存资源块ID0的寄存器组的 输入数据由数据流总线阵列提供;缓存资源块ID1的缓存级联开关设置为与前级缓存资源块ID0相连,缓存资源块ID1的寄存器组的输入数据由前级的缓存资源块提供;
设置第二级滤波器占用标识为ID2-ID7共五个缓存资源块,缓存资源块ID2的缓存级联开关设置为与数据流总线阵列相连;缓存资源块ID3-ID7的缓存级联开关均设置为与前级缓存资源块相连。
由于第一级滤波可以在6个周期内完成6次乘加操作,因此,在ALU资源池中仅需要一个ALU0即可实现。如图7所示的第一级滤波器的缓存资源块的数据结构,缓存资源块ID0的最后两个寄存器被旁路,这样使得缓存资源块ID0和缓存资源块ID1能够针对对称系数对应的抽头数据进行相加的操作。缓存资源块ID0与ID1分别通过缓存资源映射器被映射到ALU0的两个ALU缓存块上,在ALU控制器的控制下,6个周期依次完成对称数据(d0,d11)、(d1,d10)、(d2,d9)、(d3,d8)、(d4,d7)和(d5,d6)的相加,然后分别与系数相乘、累加、截位等操作后得到的第一级滤波器的输出数据;
随后,在数据流控制器的控制下将第一级滤波器的输出数据加上缓存资源ID号后,通过数据流总线阵列将第一级滤波器的输出数据路由到缓存资源块ID2上,形成第二级滤波器的缓存存储,如图8所示的第二级滤波器的缓存资源块的数据结构。由于第二级滤波器可以在12个周期以内完成24次乘加运算,因此,需要ALU资源池中的2个ALU进行实现,设置为ALU1和ALU2。前四个周期将ID2和ID7同时映射到ALU1和ALU2的两个ALU缓存块上,其中,ALU1完成(d0,d46)、(d1,d45)、(d2,d44)以及(d3,d43)的对应加乘操作;ALU2完成(d4,d42)、(d5,d41)、(d6,d40)以及(d7,d39)的对应加乘操作。后8个周期分别将缓存资源块ID3和ID6映射到ALU1的两个缓存上,ID4和ID5映射到ALU2的两个缓存上。在8个周期内分别完成剩余的数据运算。随后在累加器资源池中将ALU1和ALU2的输出相加之后再进行累加,最后将累加结果截位后,经过输出端口进行输出排序后输出,实现两个串联滤波器。
实施例四
以两个串联滤波器复用一个ALU单元进行处理为例。设定第一级滤波器12个系数偶对称,2倍抽取,12倍输入复用比;第二级滤波器24个系数偶对称,2倍抽取,24倍输入复用比。基于前述实施例所述的FIR滤波器组与滤波方法,具体实施过程如下:
设置第一级滤波器占用标识为ID0、ID1两个缓存资源块,缓存资源块ID0的缓存级联开关设置为与数据流总线阵列相连,缓存资源块ID0的寄存器组的输入数据由数据流总线阵列提供;缓存资源块ID1的缓存级联开关设置为与前级缓存资源块ID0相连,缓存资源块ID1的寄存器组的输入数据由前级的缓存资源块提供;
设置第二级滤波器占用标识为ID2-ID4共三个缓存资源块,缓存资源块ID2的缓存级联开关设置为与数据流总线阵列相连;缓存资源块ID3、ID4缓存资源块的缓存级联开关均设置为与前级缓存资源块相连。
第一级滤波器的处理过程与实施例一相同,在此不再赘述。第一级滤波器在6个周期内完成运算,剩余18个周期的时间内完成第二级滤波器的运算。具体地,第二级滤波器的24个数的乘加运算可以在12拍以内完。前4个周期将缓存资源块ID3同时映射到ALU0的两个ALU缓存块上,完成中间8个数据的加乘操作。后8个周期分别将缓存资源块ID2和ID4映射到ALU0的两个ALU缓存块上,完成剩余的数据运算。这样实现了两个串联滤波器复用一个ALU单元进行处理的配置。
实施例五
以两组并联的插值滤波器为例。第一组滤波器可以是两个串联滤波器,具体的缓存资源块、ALU资源池中ALU的分配及具体处理实现过程如实施例二所述,在此不再赘述。
设定第二组为一个独立滤波器,32个系数偶对称,8倍输入复用比,2倍插值。由于第二组滤波器是2倍插值,因此只需要存储16个数据,占用标识为ID5和ID6两个缓存资源块。
由于第二组滤波器是一个插值滤波器,在8个周期内完成两个16个数据的乘加操作,因此共需要ALU资源池中的2个ALU分别完成奇、偶相的数据运算。将缓存资源块ID5、ID6分别映射到ALU1、ALU2上。ALU1将相加之后的数据逐个与奇相系数相乘得到奇相滤波结果,经过累加、截位,将滤波结果输出到输出端口。偶相滤波结果由ALU2计算。在输出端口通过整理时序,按要求依次输出奇偶相值,得到第二组滤波器的输出结果。
实施例六
以数据流总线阵列中的多组数据流总线的处理为例,对两组并联滤波器进行说明。设定第一组为两个串联滤波器,输入复用比分别为2和4,与之并联的第二组为一个滤波器,输入复用比为2。其中,每个滤波器各占用一个缓存资源块、一个ALU计算单元。此时,数据流总线阵列中的一组数据流总线显然无法满足流量需求。由于三个滤波器的复用比倒数之和等于5/4,因此,需要数据流总线阵列中的两组数据流总线。
第一组串联的两个滤波器复用比倒数之和等于3/4,可以将第一组滤波器分配到第一组数据流总线上,第二组滤波器单独使用第二组数据流总线。
当有多组数据流总线时,需要在缓存资源块与数据流总线的接口处额外增加一级选择匹配逻辑。在缓存资源块ID0、ID1处将缓存级联开关设置为与第一组数据流总线相连,缓存资源块ID2处将缓存级联开关设置为与第二组数据流总线相连。同样在累加器的输出通过第一组数据流总线路由到缓存资源块ID1,实现第一组串联的两个滤波器中,两级滤波器的串联。
通过上述用于具体的应用场景实施例的说明,可以得知,本发明实施例所提出的滤波方法,由于应用在实施例一所述的FIR滤波器组中,因此,能够将滤波器的所有硬件资源进行统一考量,从而实现滤波器组内部硬件资源可重构、可重用且灵活可配置,以及在合理的资源和速度的前提下能够满足不同的滤波组合。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和 硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!