本发明属于计算机编译码技术领域,更具体地,涉及一种基于CUDA的Raptor Code编码方法、译码方法及系统。
背景技术:
Raptor Code(Rapid tornado Code)作为一种性能优良的无速率码,在通信系统中的应用研究越来越多。Raptor Code是由预编码和LT Code(Luby Transform Code)组成的级联码,其中预编码使用高码率的低密度奇偶校验码(Low Density Parity Check Code,LDPC)。LDPC编码数据根据生成矩阵产生,其译码采用置信传播(Belief Propagation,BP)算法;LT Code编码在LDPC编码数据上进行,其译码同样采用BP算法。LDPC的BP译码在根据校验矩阵产生的Tanner图上进行,在迭代20次后就可以完成译码过程,而LT Code的BP译码则是在由生成矩阵产生的Tanner图上进行的,需要200次迭代才能完成译码过程,并且每一次信息的迭代更新中,都有双曲正切、反双曲正切及累乘运算,因此Raptor Code的译码过程需要大量的运算。
目前主要通过传统编码语言(如matlab脚本语言以及C/C++等)实现Raptor Code编译码算法,但是由于Raptor Code译码过程运算量很大,使用上述编码语言实现Raptor Code编译码算法时,测试周期很长,测试效率低下。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于CUDA的Raptor Code编码方法、译码方法及系统,根据Raptor Code编译码操作的并行特点,设计了并行程序中编译码任务的分解方式和迭代数据存储结构,以及每个线程的具体操作过程,从而提高了Raptor Code编译码的执行速度,由此解决现有技术中实现Raptor Code编译码算法时,测试周期长,测试效率低的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于CUDA的Raptor Code编码方法,包括:
(1)将LDPC的校验矩阵H通过高斯消去及列交换转化成H0=[P|Im],由H0得到LDPC的生成矩阵由生成矩阵GLDPC以及待编码数据向量x得到LDPC目标编码数据向量令向量y’=Px,则y’的计算方式为:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程将矩阵P中第i行与向量x进行乘法运算,得到向量y’中的第i个编码数据值,由所有并行运算的结果及向量x得到LDPC目标编码数据向量y,其中,Im为m阶单位矩阵,Ik-m为k-m阶单位矩阵,P为m×(k-m)的矩阵,x为(k-m)×1的向量,(k-m)为LDPC编码之前的数据长度,k为LDPC编码之后的数据长度;
(2)同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据LT Code编码的度分布函数产生一个[1,k]范围内的正整数值作为待编码数据xi的度值di,由所有并行运算的结果得到度向量d,其中,n为LT Code编码之后的数据长度,j为可能的度值,Ωj为度值取j的概率,k为LT Code编码之前的数据长度,也即为LDPC编码之后的数据长度,d为n×1的向量;
(3)同时开启n个线程,线程编号为i(0≤i≤n-1)的线程获取度向量d中的度值di,并在[0,k-1]范围内按照均匀概率分布随机选取di个互异的整数值作为LT Code的编码矩阵GLT的第i行的非零元素位置,最后由并行运算的结果得到GLT中各行中的非零元素的位置,其中,GLT为n×k的矩阵;
(4)同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行非零元素的位置,得到LDPC目标编码数据向量y中对应位置的元素,由各对应位置的元素生成LT Code的目标编码数据向量z中的第i个编码数据值zi,由所有并行运算结果得到LT Code的目标编码数据向量z,其中,z为n×1的向量。
按照本发明的另一方面,提供了一种基于CUDA的Raptor Code编码系统,包括:LDPC并行编码模块、LT Code度分布并行生成模块、LT Code编码矩阵并行生成模块、LT Code编码数据并行生成模块:
所述LDPC并行编码模块用于将LDPC的校验矩阵H通过高斯消去及列交换转化成H0=[P|Im],由H0得到LDPC的生成矩阵由生成矩阵GLDPC以及待编码数据向量x得到LDPC目标编码数据向量令向量y’=Px,则y’的计算方式为:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程将矩阵P中第i行与向量x进行乘法运算,得到向量y’中的第i个编码数据值,由所有并行运算的结果及向量x得到LDPC目标编码数据向量y,其中,Im为m阶单位矩阵,Ik-m为k-m阶单位矩阵,P为m×(k-m)的矩阵,x为(k-m)×1的向量,(k-m)为LDPC编码之前的数据长度,k为LDPC编码之后的数据长度;
所述LT Code度分布并行生成模块用于同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据LT Code编码的度分布函数产生一个[1,k]范围内的正整数值作为待编码数据xi的度值di,由所有并行运算的结果得到度向量d,其中,n为LT Code编码之后的数据长度,j为可能的度值,Ωj为度值取j的概率,k为LT Code编码之前的数据长度,也即为LDPC编码之后的数据长度,d为n×1的向量;
所述LT Code编码矩阵并行生成模块用于同时开启n个线程,线程编号为i(0≤i≤n-1)的线程获取度向量d中的度值di,并在[0,k-1]范围内按照均匀概率分布随机选取di个互异的整数值作为LT Code的编码矩阵GLT的第i行的非零元素位置,最后由并行运算的结果得到GLT中各行中的非零元素的位置,其中,GLT为n×k的矩阵;
所述LT Code编码数据并行生成模块用于同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行非零元素的位置,得到LDPC目标编码数据向量y中对应位置的元素,由各对应位置的元素生成LT Code的目标编码数据向量z中的第i个编码数据值zi,由所有并行运算结果得到LT Code的目标编码数据向量z,其中,z为n×1的向量。
按照本发明的另一方面,提供了一种基于CUDA的Raptor Code译码方法,包括:
(1)在LT Code的Tanner图上进行LT Code的BP译码,其子步骤为:
(1-1)申请大小为n×dmax的存储空间MLT,其中,dmax为度向量d中的最大值,MLT的第i(0≤i≤n-1)行的前di个存储单元存放与Oi节点相关的信息值,即Oi节点向所有与之相连的I节点传递的信息值或者所有与Oi节点相连的I节点向Oi节点传递的信息值,在LT Code的Tanner图中,I节点对应LDPC目标编码数据向量y,O节点对应LT Code的目标编码数据向量z,Oi到Ij的连线表示GLT中的第i行第j列为非零元素,MLT中初始化值为0;
(1-2)同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行中的di个非零元素的位置,将di个二元值{i,j}(0≤j≤di-1)作为索引值添加到矩阵RLT的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLT,其中RLT表示I节点中的数据在MLT中的索引值,RLT为n×dmax的矩阵;
(1-3)O节点向I节点传递信息:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程取出MLT第i行的前di个存储单元的信息值按照公式:得到di个更新后信息值,并将更新后的di个信息值替换MLT第i行的前di个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值,LLR(zi)为LT Code的目标编码数据向量z中zi的对数似然比;
(1-4)I节点向O节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值,根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值由公式得到cj个更新后的信息值并将更新后的cj个信息值替换MLT中取出信息值的位置处,最后通过并行计算结果得到更新后的MLT,其中cj为与Ij节点相连的O节点的数量,返回步骤(1-3)直到满足预设迭代次数,则执行步骤(1-5);
(1-5)获取I节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值,根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值,将该cj个信息值进行求和得到Ij节点的信息值,由并行运算的结果得到I节点的k个所有信息值{mI0,…,mI(k-1)};
(2)在LDPC的Tanner图上进行LDPC的BP译码,其子步骤为:
(2-1)申请大小为m×dcmax的存储空间MLDPC,其中,dcmax为LDPC校验矩阵H中各行非零元素个数的最大值,MLDPC的第i(0≤i≤m-1)行的前dci个存储单元存放与ci节点相关的信息值,即ci节点向所有与之相连的v节点传递的信息值或者所有与ci节点相连的v节点向ci节点传递的信息值,在LDPC的Tanner图中,v节点对应LDPC校验矩阵H的列,C节点对应LDPC校验矩阵H的行,ci到vj的连线表示H中的第i行第j列为非零元素;
(2-2)同时开启m个线程,线程编号为i(0≤i≤m-1)的线程根据H中第i行中的dci个非零元素的位置,将dci个二元值{i,j}(0≤j≤dci-1)作为索引值添加到矩阵RLDPC的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLDPC,其中RLDPC表示v节点中的数据在MLDPC中的索引值,RLDPC为m×dcmax的矩阵;
(2-3)同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,将步骤(1-5)得到的I节点中的第j个信息值mIj写入MLDPC中与各索引值对应的位置处,由并行运算的结果完成对MLDPC的初始化;
(2-4)c节点向v节点传递信息:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程取出MLDPC第i行的前dci个存储单元的信息值按照公式:得到dci个更新后信息值,并将更新后的dci个信息值替换MLDPC第i行的前dci个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值;
(2-5)v节点向c节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值由公式得到dvj个更新后的信息值并将更新后的dvj个信息值替换MLDPC中取出信息值的位置处,最后通过并行计算结果得到更新后的MLDPC,其中dvj为与vj节点相连的c节点的数量,返回步骤(2-4)直到满足预设迭代次数,则执行步骤(2-6);
(2-6)获取v节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值,将该dvj个信息值的求和值与mIj的和作为vj节点的信息值mvj,由并行运算的结果得到v节点的k个所有信息值{mv0,…,mv(k-1)};
(3)同时开启(k-m)个线程,线程编号为j(0≤j≤k-m-1)的线程按照公式:得到第j个数据由并行运算结果得到目标译码数据向量
按照本发明的另一方面,提供了一种基于CUDA的Raptor Code译码系统,包括:LT-BP并行译码模块、LDPC-BP并行译码模块以及译码结果并行判决模块:
所述LT-BP并行译码模块用于在LT Code的Tanner图上进行LT Code的BP译码,所述LT-BP并行译码模块包括第一内存申请模块、第一索引矩阵生成模块、第一更新模块、第二更新模块以及LT Code的BP译码子模块:
所述第一内存申请模块用于申请大小为n×dmax的存储空间MLT,其中,dmax为度向量d中的最大值,MLT的第i(0≤i≤n-1)行的前di个存储单元存放与Oi节点相关的信息值,即Oi节点向所有与之相连的I节点传递的信息值或者所有与Oi节点相连的I节点向Oi节点传递的信息值,在LT Code的Tanner图中,I节点对应LDPC目标编码数据向量y,O节点对应LT Code的目标编码数据向量z,Oi到Ij的连线表示GLT中的第i行第j列为非零元素,MLT中初始化值为0;
所述第一索引矩阵生成模块用于同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行中的di个非零元素的位置,将di个二元值{i,j}(0≤j≤di-1)作为索引值添加到矩阵RLT的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLT,其中RLT表示I节点中的数据在MLT中的索引值,RLT为n×dmax的矩阵;
所述第一更新模块用于O节点向I节点传递信息:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程取出MLT第i行的前di个存储单元的信息值按照公式:得到di个更新后信息值,并将更新后的di个信息值替换MLT第i行的前di个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值,LLR(zi)为LT Code的目标编码数据向量z中zi的对数似然比;
所述第二更新模块用于I节点向O节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值,根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值由公式得到cj个更新后的信息值并将更新后的cj个信息值替换MLT中取出信息值的位置处,最后通过并行计算结果得到更新后的MLT,其中cj为与Ij节点相连的O节点的数量;
所述LT Code的BP译码子模块用于在所述第一更新模块以及所述第二更新模块执行预设迭代次数之后,获取I节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值,根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值,将该cj个信息值进行求和得到Ij节点的信息值,由并行运算的结果得到I节点的k个所有信息值{mI0,…,mI(k-1)};
所述LDPC-BP并行译码模块用于在LDPC的Tanner图上进行LDPC的BP译码,所述LDPC-BP并行译码模块包括第二内存申请模块、第二索引矩阵生成模块、初始化模块、第三更新模块、第四更新模块以及LDPC的BP译码子模块:
所述第二内存申请模块用于申请大小为m×dcmax的存储空间MLDPC,其中,dcmax为LDPC校验矩阵H中各行非零元素个数的最大值,MLDPC的第i(0≤i≤m-1)行的前dci个存储单元存放与ci节点相关的信息值,即ci节点向所有与之相连的v节点传递的信息值或者所有与ci节点相连的v节点向ci节点传递的信息值,在LDPC的Tanner图中,v节点对应LDPC校验矩阵H的列,C节点对应LDPC校验矩阵H的行,ci到vj的连线表示H中的第i行第j列为非零元素;
所述第二索引矩阵生成模块用于同时开启m个线程,线程编号为i(0≤i≤m-1)的线程根据H中第i行中的dci个非零元素的位置,将dci个二元值{i,j}(0≤j≤dci-1)作为索引值添加到矩阵RLDPC的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLDPC,其中RLDPC表示v节点中的数据在MLDPC中的索引值,RLDPC为m×dcmax的矩阵;
所述初始化模块用于同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,将步骤(1-5)得到的I节点中的第j个信息值mIj写入MLDPC中与各索引值对应的位置处,由并行运算的结果完成对MLDPC的初始化;
所述第三更新模块用于c节点向v节点传递信息:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程取出MLDPC第i行的前dci个存储单元的信息值按照公式:得到dci个更新后信息值,并将更新后的dci个信息值替换MLDPC第i行的前dci个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值;
所述第四更新模块用于v节点向c节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值由公式得到dvj个更新后的信息值并将更新后的dvj个信息值替换MLDPC中取出信息值的位置处,最后通过并行计算结果得到更新后的MLDPC,其中dvj为与vj节点相连的c节点的数量;
所述LDPC的BP译码子模块用于在所述第三更新模块以及所述第四更新模块执行预设迭代次数之后,获取v节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值,将该dvj个信息值的求和值与mIj的和作为vj节点的信息值mvj,由并行运算的结果得到v节点的k个所有信息值{mv0,…,mv(k-1)};
所述译码结果并行判决模块用于同时开启(k-m)个线程,线程编号为j(0≤j≤k-m-1)的线程按照公式:得到第j个数据由并行运算结果得到目标译码数据向量
总体而言,通过本发明所构思的以上技术方案与现有技术相比,主要有以下的技术优点:根据Raptor Code编译码操作的并行特点,设计了并行程序中编译码任务的分解方式和迭代数据存储结构,以及每个线程的具体操作过程。从而提高了Raptor Code编译码的执行速度,由此解决现有技术中实现Raptor Code编译码算法时,测试周期长,测试效率低的技术问题。
附图说明
图1为本发明实施例公开的一种基于CUDA平台的软件与硬件之间的相互协作关系示意图;
图2为本发明实施例公开的一种GPU处理器的模型示意图;
图3为本发明实施例公开的一种基于CUDA的Raptor Code编码方法的流程示意图;
图4为本发明实施例公开的一种基于CUDA的Raptor Code编码系统的结构示意图;
图5为本发明实施例公开的一种基于CUDA的Raptor Code译码方法的流程示意图;
图6为本发明实施例公开的一种LT Code的Tanner图示意图;
图7为本发明实施例公开的一种LDPC的Tanner图示意图;
图8为本发明实施例公开的一种基于CUDA的Raptor Code译码系统的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
为了更好的理解本发明,对本发明中的相关技术背景进行了介绍:采用基于Visual Studio的CUDA并行程序开发环境实现Raptor Code编译码算法,为了实现在GPU运行并行程序的功能,需要软件(如Visual Studio,CUDA)与硬件(如CPU,GPU)之间的相互协作,按照各自的分工共同完成任务。其相互之间的协作关系如图1所示:
Visual Studio:提供程序编写、调试界面;提供串行程序的编译器、链接器,并将并行程序交付CUDA平台处理;
CUDA:提供并行程序的编译器、链接器,并将编译链接后的程序交付GPU执行;
CPU:执行串行程序指令;
GPU:执行并行程序指令。
从功能上看,CUDA平台提供了程序开发环境Visual Studio与执行程序的硬件GPU之间的接口,将在Visual Studio中编写的并行程序解释成GPU能够执行的并行指令。
任一时刻,在一个处理器上只能执行一条指令,也即程序指令的执行是顺序串行的。若要在同一时刻使多条指令并行执行,必须提供多个处理器。在GPU中,有大量的运算能力相对CPU较弱的处理器(如GTX580中有512个处理器),为并行程序设计、执行提供了条件。
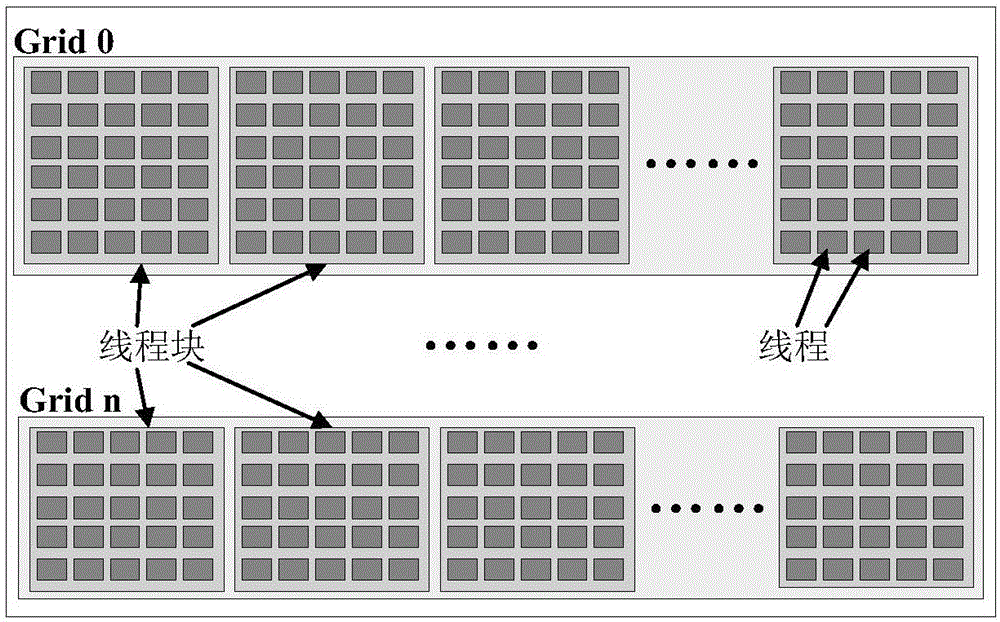
CUDA中执行程序的基本单元是线程,因此,设计并行程序就是把一个任务分配到多个线程中同时执行,由这些线程共同完成这个任务。图2所示为GPU中的处理器资源的抽象模型示意图。
CUDA中的并行程序执行分为两个层面:一是同一程序的副本在不同的线程中同时执行;二是不同程序在不同的线程中同时执行。每一个能够并行执行相同程序的模块称为一个kernel,kernel是操作系统的核心部分,以函数的形式存在。因此,并行程序执行的两个层面可以表述为:一个kernel占用一定线程,各线程同时执行kernel中的程序;GPU中可以同时运行多个kernel。
由于Raptor Code的编译码过程具有很高的并行度,非常适合于使用CUDA并行程序实现,以提高运行速度。在译码程序设计中,最关键的部分是信息值存储方式的设计。根据并行程序的执行特点,可以选择按行存储的方式,以提高各线程对信息值的存取速度。
参阅图3,图3是本发明实施例公开的一种基于CUDA的Raptor Code编码方法的流程示意图,图3所示的方法包括以下步骤:
301:生成LDPC目标编码数据;
其中,步骤301的具体实现方法为:将LDPC的校验矩阵H通过高斯消去及列交换转化成H0=[P|Im],由H0得到LDPC的生成矩阵由生成矩阵GLDPC以及待编码数据向量x得到LDPC目标编码数据向量令向量y’=Px,则y’的计算方式为:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程将矩阵P中第i行与向量x进行乘法运算,得到向量y’中的第i个编码数据值,由所有并行运算的结果及向量x得到LDPC目标编码数据向量y,其中,Im为m阶单位矩阵,Ik-m为k-m阶单位矩阵,P为m×(k-m)的矩阵,x为(k-m)×1的向量,(k-m)为LDPC编码之前的数据长度,k为LDPC编码之后的数据长度;
其中,P是稀疏矩阵,即P中每一行中的非零元素(非零元素全为1)数量为m,所以在存储P时,只存储P中每一行中非零元素的位置。
其中,实现将矩阵P中第i行与向量x进行乘法运算的过程为:根据P中第i行非零元素的位置,得到x中对应位置的元素值,则向量y’中的第i个编码数据值y’i为x中对应位置的各元素值进行异或运算得到的值。
302:生成LT Code度分布向量;
其中,步骤302的具体实现方法为:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据LT Code编码的度分布函数产生一个[1,k]范围内的正整数值作为待编码数据xi的度值di,由所有并行运算的结果得到度向量d,其中,n为LT Code编码之后的数据长度,j为可能的度值,Ωj为度值取j的概率,k为LT Code编码之前的数据长度,也即为LDPC编码之后的数据长度,d为n×1的向量;
其中,参与LT Code编码数据的信息比特数量称为该编码数据的度,度值是按照一定的概率分布产生的。
303:生成LT Code编码矩阵;
其中,步骤303的具体实现方法为:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程获取度向量d中的度值di,并在[0,k-1]范围内按照均匀概率分布随机选取di个互异的整数值作为LT Code的编码矩阵GLT的第i行的非零元素位置,最后由并行运算的结果得到GLT中各行中的非零元素的位置,其中,GLT为n×k的矩阵;
其中,GLT是稀疏矩阵,即GLT中每一行中的非零元素数量为k,因此在生成和存储GLT时,只需要生成和存储GLT中每一行中非零元素的位置。
304:生成LT Code目标编码数据;
其中,步骤304的具体实现方法为:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行非零元素的位置,得到LDPC目标编码数据向量y中对应位置的元素,由各对应位置的元素生成LT Code的目标编码数据向量z中的第i个编码数据值zi,由所有并行运算结果得到LT Code的目标编码数据向量z,其中,z为n×1的向量。
其中,生成编码数据zi的计算方式为:由GLT中第i行非零元素的位置得到的LDPC目标编码数据向量y中对应位置的各元素进行异或运算得到的值作为zi。
参阅图4,图4是本发明实施例公开的一种基于CUDA的Raptor Code编码系统的结构示意图,其中,图4所示的编码系统包括:LDPC并行编码模块、LT Code度分布并行生成模块、LT Code编码矩阵并行生成模块、LT Code编码数据并行生成模块;
上述LDPC并行编码模块用于生成LDPC目标编码数据;
上述LT Code度分布并行生成模块用于生成LT Code度分布向量;
上述LT Code编码矩阵并行生成模块用于生成LT Code编码矩阵;
上述LT Code编码数据并行生成模块用于生成LT Code目标编码数据。
其中,各模块的具体实施方式参照方法实施例3中的描述,本发明实施例将不做赘述。
参阅图5,图5是本发明实施例公开的一种基于CUDA的Raptor Code译码方法的流程示意图,图5所示的译码方法包括以下步骤:
501:在LT Code的Tanner图上进行LT Code的BP译码;
编码数据经过信道传输后,在接收端就可以根据接收值得到编码比特的对数似然比(LLR),定义为:其中zi为发送的第i个目标编码数据,ri对应于zi的接收值,p(x)为事件x成立的概率。
如图6所示为LT Code的Tanner图示意图,其中I节点对应LT Code编码前的数据向量y=[y0,y1,…,yk-1]T,O节点对应LT Code目标编码数据向量z=[z0,z1,…,zn-1]T,Oi到Ij的连线表示GLT的第i行第j列为非零元素。
其中,步骤501的具体实现方式为:
5011:申请大小为n×dmax的存储空间MLT,其中,dmax为度向量d中的最大值,MLT的第i(0≤i≤n-1)行的前di个存储单元存放与Oi节点相关的信息值,即Oi节点向所有与之相连的I节点传递的信息值或者所有与Oi节点相连的I节点向Oi节点传递的信息值,在LT Code的Tanner图中,I节点对应LDPC目标编码数据向量y,O节点对应LT Code的目标编码数据向量z,Oi到Ij的连线表示GLT中的第i行第j列为非零元素,MLT中初始化值为0;
5012:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程根据GLT中第i行中的di个非零元素的位置,将di个二元值{i,j}(0≤j≤di-1)作为索引值添加到矩阵RLT的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLT,其中RLT表示I节点中的数据在MLT中的索引值,RLT为n×dmax的矩阵;
5013:O节点向I节点传递信息:同时开启n个线程,线程编号为i(0≤i≤n-1)的线程取出MLT第i行的前di个存储单元的信息值按照公式:得到di个更新后信息值,并将更新后的di个信息值替换MLT第i行的前di个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值,LLR(zi)为LT Code的目标编码数据向量z中zi的对数似然比;
5014:I节点向O节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值,根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值由公式得到cj个更新后的信息值并将更新后的cj个信息值替换MLT中取出信息值的位置处,最后通过并行计算结果得到更新后的MLT,其中cj为与Ij节点相连的O节点的数量,返回步骤5013直到满足预设迭代次数,则执行步骤5015;
5015:获取I节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLT中第j行的所有索引值根据获取的索引值得到MLT中的与索引值对应的位置处的cj个信息值,将该cj个信息值进行求和得到Ij节点的信息值,由并行运算的结果得到I节点的k个所有信息值{mI0,…,mI(k-1)};
502:在LDPC的Tanner图上进行LDPC的BP译码;
如图7所示为LDPC的Tanner图示意图,其中v节点对应LDPC校验矩阵H的列,c节点对应LDPC校验矩阵H的行,ci到vj的连线表示H中的第i行第j列为非零元素。
其中,步骤502的具体实现过程为:
5021:申请大小为m×dcmax的存储空间MLDPC,其中,dcmax为LDPC校验矩阵H中各行非零元素个数的最大值,MLDPC的第i(0≤i≤m-1)行的前dci个存储单元存放与ci节点相关的信息值,即ci节点向所有与之相连的v节点传递的信息值或者所有与ci节点相连的v节点向ci节点传递的信息值,在LDPC的Tanner图中,v节点对应LDPC校验矩阵H的列,C节点对应LDPC校验矩阵H的行,ci到vj的连线表示H中的第i行第j列为非零元素;
5022:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程根据H中第i行中的dci个非零元素的位置,将dci个二元值{i,j}(0≤j≤dci-1)作为索引值添加到矩阵RLDPC的第i行中的对应位置处,最后根据并行计算结果得到矩阵RLDPC,其中RLDPC表示v节点中的数据在MLDPC中的索引值,RLDPC为m×dcmax的矩阵;
5023:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,将步骤(1-5)得到的I节点中的第j个信息值mIj写入MLDPC中与各索引值对应的位置处,由并行运算的结果完成对MLDPC的初始化;
5024:c节点向v节点传递信息:同时开启m个线程,线程编号为i(0≤i≤m-1)的线程取出MLDPC第i行的前dci个存储单元的信息值按照公式:得到dci个更新后信息值,并将更新后的dci个信息值替换MLDPC第i行的前dci个存储单元中的原始数值,最后通过并行计算结果得到更新后的MLT,其中,为更新后的信息值;
5025:v节点向c节点传递信息:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值,根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值由公式得到dvj个更新后的信息值并将更新后的dvj个信息值替换MLDPC中取出信息值的位置处,最后通过并行计算结果得到更新后的MLDPC,其中dvj为与vj节点相连的c节点的数量,返回步骤5024直到满足预设迭代次数,则执行步骤5026;
5026:获取v节点信息值:同时开启k个线程,线程编号为j(0≤j≤k-1)的线程获取RLDPC中第j行的所有索引值根据获取的索引值得到MLDPC中的与索引值对应的位置处的dvj个信息值,将该dvj个信息值的求和值与mIj的和作为vj节点的信息值mvj,由并行运算的结果得到v节点的k个所有信息值{mv0,…,mv(k-1)};
503:译码判决得到目标译码数据。
根据步骤5016得到的v节点的信息值{mv0,…,mv(k-1)},就可以经判决得到目标译码数据。
其中,步骤503的具体实现过程为:同时开启(k-m)个线程,线程编号为j(0≤j≤k-m-1)的线程按照公式:得到第j个数据由并行运算结果得到目标译码数据向量
参阅图8,图8是本发明实施例公开的一种基于CUDA的Raptor Code译码系统的结构示意图,其中,图8所示的译码系统包括:LT-BP并行译码模块、LDPC-BP并行译码模块以及译码结果并行判决模块;
上述LT-BP并行译码模块用于在LT Code的Tanner图上进行LT Code的BP译码;
上述LDPC-BP并行译码模块用于在LDPC的Tanner图上进行LDPC的BP译码;
上述译码结果并行判决模块用于译码判决得到目标译码数据。
其中,LT-BP并行译码模块包括第一内存申请模块、第一索引矩阵生成模块、第一更新模块、第二更新模块以及LT Code的BP译码子模块。
其中,LDPC-BP并行译码模块包括第二内存申请模块、第二索引矩阵生成模块、初始化模块、第三更新模块、第四更新模块以及LDPC的BP译码子模块。
其中,各模块的具体实施方式参照方法实施例5中的描述,本发明实施例将不做赘述。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。