基于抽样猜测的数据压缩方法与流程
本发明涉及一种压缩方法,特别是有关于一种基于抽样猜测的数据压缩方法。
背景技术:
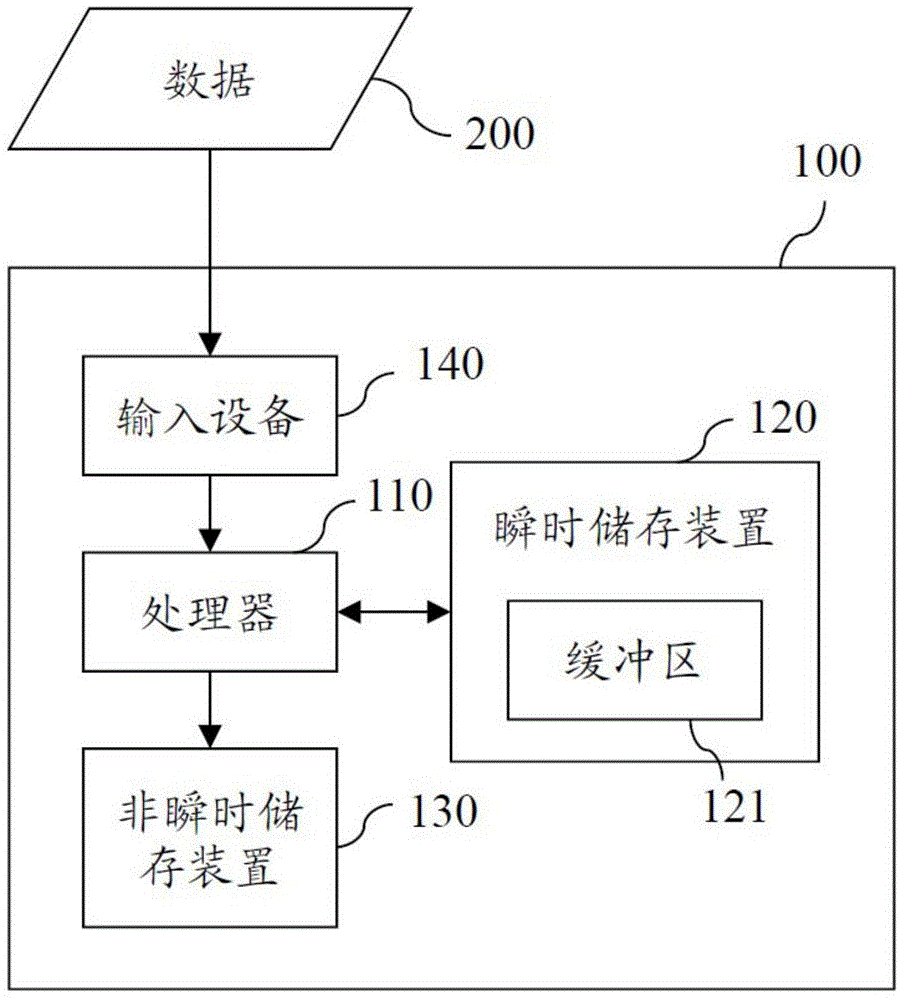
:实时数据压缩有快速压缩的需求,通常采用压缩能力较差但具有较快压缩速度的算法。然而,为了达到快速的需求,常常无法判断是否有足够的数据累赘,导致造成压缩后的数据比压缩前的数据还大的现象,此为无意义的压缩。技术实现要素:有鉴于此,本发明一实施例提出一种基于抽样猜测的数据压缩方法,包含:接收一笔数据,该笔数据包含m个数据区域;于该笔数据的m个数据区域中,抽取n个数据区域,其中n<m,且n与m为正整数;检查n个数据区域中的数据累赘占比;及根据数据累赘占比多寡决定是否压缩该笔数据。本发明另一实施例还提出一种基于抽样猜测的数据压缩方法,依序对多笔数据的每一笔数据执行下列步骤:于该第i笔数据的mi个数据区域中,抽取ni个数据区域,其中n<m,且n、m与i为正整数;检查ni个数据区域中的数据累赘;于所抽取的各数据区域中均为数据累赘的占比至少为阈值时,将该第i笔数据存放于缓冲区中;及当满足压缩条件时,压缩缓冲区中的第x笔至第i笔的数据,该压缩条件为且其中x、k为正整数。综上所述,根据本发明实施例所述的基于抽样猜测的数据压缩方法,可对欲储存的数据进行抽样,检查数据累赘的比例,据以推估数据值不值得压缩,据此可兼顾压缩速度及压缩率。附图说明图1为本发明一实施例的系统架构图。图2为本发明一实施例的基于抽样猜测的数据压缩方法流程图。图3为本发明另一实施例的基于抽样猜测的数据压缩方法流程图。符号说明:100计算机系统110处理器120瞬时储存装置121缓冲区130非瞬时储存装置140输入设备200数据具体实施方式参照图1,为本发明一实施例的系统架构图。本发明实施例由计算机系统100实现。计算机系统100包含处理器110、瞬时储存装置120(如挥发式内存)、非瞬时储存装置130(如硬盘、固态硬盘等)及输入设备140(如网络接口、外接储存装置(如随身碟、外接硬盘等))。计算机系统100可例如为个人计算机、服务器、服务器群集等。瞬时储存装置120包含缓冲区121。在一些实施例中,缓冲区121是位于非瞬时储存装置130中的挥发式内存上。在一些实施例中,缓冲区121是位于非瞬时储存装置130中的非挥发式储存介质上。参照图2,为本发明一实施例的基于抽样猜测的数据压缩方法流程图,由处理器110加载程序后执行。所述程序可储存于非瞬时储存装置130中。首先,自输入设备140接收一笔数据200,数据200包含m个数据区域(步骤s210)。在此,m为正整数。参照表1,为m个数据区域(r1~r16)的示例,于此m为16。在步骤s220中,于此笔数据200的m个数据区域中,抽取n个数据区域。在此,n为4,但本发明实施例非以此为限,只要n为小于m的正整数即可。于步骤s230中,检查此些n个数据区域中的数据累赘占比。如表1所示,以符号“z”表示对应的数据区域全部为数据累赘。所述数据累赘可例如为零或其他可视为冗余的字符。在此例中,所抽取的四个数据区域全部为数据累赘,因此数据累赘占比为100%。在步骤s240中,根据数据累赘占比多寡决定是否压缩该笔数据200。于此,可根据所抽取的各数据区域中均为数据累赘的占比是否至少为阈值来判断是否压缩该笔数据200。在本例中,可设定阈值为100%。而因为所抽取的四个数据区域的数据累赘占比为100%,因此将对该笔数据200进行压缩。所述压缩并非限定只能对单笔数据200进行,也可累积多笔数据200一起进行压缩,于后将再详细说明。[表1]r1r2r3r4r5r6r7r8r9r10r11r12r13r14r15r16zzzz于此,将再以表2来示例数据累赘的占比非为100%的情形。在此,以符号“a”表示对应的数据区域中不完全为数据累赘,也就是至少部分非为数据累赘。在此例中,所抽取的四数据区域中有三个数据区域为数据累赘,另一个数据区域不完全为数据累赘,因此数据累赘占比为75%。若阈值设定为100%,则不对此笔数据200进行压缩。[表2]r1r2r3r4r5r6r7r8r9r10r11r12r13r14r15r16zzaz参照图3,为本发明另一实施例的基于抽样猜测的数据压缩方法流程图,由处理器110加载程序后执行。于此,假设是依序对n笔数据200进行处理,n为正整数。在此,以n为8为例,如表3所示,共有八笔数据200。于步骤s310,判断i是否小于或等于n,意即确认n笔数据200是否已处理完毕。于此,i代表现在处理的数据200次序,为正整数。若已处理完毕,则结束此流程,若未处理完毕,则进入步骤s320。在此例中,第i笔数据200包含mi个数据区域。mi为正整数。于此,mi为16,但本发明实施例非以此为限。[表3]在步骤s320中,于第i笔数据200的mi个数据区域中,抽取ni个数据区域。ni小于mi。于此例中,ni均为相同数值。于此,ni均为4,但本发明实施例非以此为限。接着,进入步骤s330。在步骤s330中,检查此些抽取出的ni个数据区域中的数据累赘。以第一笔数据d1来说,如表3所示,所抽取出的数据区域r2、r5、r10、r14中均为数据累赘。接着,在步骤s340中,判断所抽取的各数据区域中均为数据累赘的占比是否至少为阈值。若是,则进入步骤s350,将第i笔数据200存放在缓冲区121中,以利后续进行压缩。若否,表示该第i笔数据200不适合压缩的机率很高,则进入步骤s380,以原值储存该第i笔数据200。在此,阈值仍以100%为例说明。由于第一笔数据d1所抽取出的四个数据区域均为数据累赘,因此会将第一笔数据d1存放于缓冲区121中,接着进入步骤s360。在步骤s360中,计算缓冲区121中的第x笔至第i笔的数据200对应的ni/mi的总和。在此,缓冲区121中仅有第一笔数据d1,其ni/mi总和为1/4。于此步骤中,会判断ni/mi的总和是否小于且接近k,作为压缩条件。k为正整数,于此以k为1为例。所述接近k的意思是指小于或等于k的最大值,若再将下一笔数据200的ni/mi(即ni+1/mi+1)计入总和则会大于k。在此,由于ni+1/mi+1也是1/4,因此其总和为1/2,并不符合压缩条件,将回到步骤310,检查第二笔数据d2。重复前述的步骤,发现第一笔至第四笔的数据d1~d4的数据累赘占比均超过阈值,而均存入缓冲区121中。并且,第一笔至第四笔数据d1~d4的ni/mi均为1/4,其总和为k,符合压缩条件。因此,将进入步骤s370,压缩缓冲区121中的第一笔至第四笔数据d1~d4。之后,返回步骤s310,检查处理第五笔数据d5。参照表3,第五笔数据d5所抽取的四个数据区域r2、r4、r8、r13中的数据区域r4、r8所存放的不完全为数据累赘。因此,在步骤s340中判断数据累赘占比仅有50%,低于阈值,表示该第五笔数据d5有较高的机率具有较低的压缩效率,因而接续步骤s380。在步骤s380中,以原值储存该第五笔数据d5,而不对第五笔数据d5进行压缩。在步骤s380之后,进入步骤s370,以将缓冲区121中的数据200进行压缩。换言之,压缩条件还包含该第i笔数据累赘占比小于阈值。若该第i笔数据累赘占比小于阈值,则不压缩第i笔数据200,并压缩缓冲区121中的数据200。于步骤s370执行后再返回步骤s310,继续检查后续的数据200直至所有数据200都处理完毕后结束流程。[表4]参照表4,在此示例变化各数据200抽取的数据区域数量的情形。也就是说,各笔数据200的ni/mi不完全相同。第一笔数据d1的ni/mi是1/4;第二笔数据d2的ni/mi是1/2;第三笔数据d3的ni/mi是1/8。此三笔数据d1~d3的数据累赘占比均为100%,且ni/mi总和接近k(在此仍设定为1),因此将于步骤s370将此三笔数据d1~d3压缩成不超过一笔数据200的大小。接着,对于第四笔数据d4,数据区域r3、r4、r7、r9、r11、r14不完全为数据累赘,因此将进入步骤s380,原值储存第四笔数据d4。而后,由于此时缓冲区121尚无数据200,因此再返回步骤s310,继续处理后续数据200。第五笔数据d5的ni/mi是3/8;第六笔数据d6的ni/mi是1/8;第七笔数据d7的ni/mi是1/4;第八笔数据d8的ni/mi是1/8。此四笔数据d5~d8的数据累赘占比均为100%,且ni/mi总和接近k(在此仍设定为1),因此将于步骤s370将此四笔数据d5~d8压缩成不超过一笔数据200的大小。在一些实施例中,前笔数据200或已检查过的多笔数据200的数据累赘占比会影响之后的取样。举例而言,若当前的数据200的数据累赘占比偏高,则可降低对下一笔数据200抽取数据区域的数量;反之,则提升对下一笔数据200抽取数据区域的数量。[表5]参见表5,在此示例其他阈值设定的情形。在一些实施例中,阈值可不设定为100%,可设定在50%~100%的范围内。于此以阈值为70%为例说明。第一笔数据d1的数据区域r2、r4、r5、r7、r10、r14为数据累赘,数据区域r13、r15不完全为数据累赘,因此数据累赘占比为75%,系超过阈值,因此第一笔数据d1将存放于缓冲区121中。在此,假设k为2,也就是希望压缩后的数据能不超过两倍的数据200大小。第一笔数据d1的ni/mi是1/2。第二笔数据d2的数据区域r1、r2、r3、r9、r12为数据累赘,数据区域r13不完全为数据累赘,因此数据累赘占比为83%,系超过阈值,因此第二笔数据d2将存放于缓冲区121中。第二笔数据d2的ni/mi是3/8。第三笔数据d3的数据累赘占比为75%,其ni/mi是1/2。第四笔数据d4的数据累赘占比为100%,其ni/mi是1/8。第五笔数据d5的数据累赘占比为75%,其ni/mi是1/4。第一笔数据至第五笔数据d1~d5的ni/mi总和接近k,于是将于步骤s370压缩第一笔数据至第五笔数据d1~d5。而第六笔数据d6的数据累赘占比为33%,低于阈值。因此,将于步骤s380中原值储存第六笔数据d6。接着返回步骤s310,接续处理后续数据200。在一些实施例中,一笔数据200的大小可设定为4k位,因此多笔数据200经压缩后可存入k个页面。综上所述,根据本发明实施例所述的基于抽样猜测的数据压缩方法,可对欲储存的数据进行抽样,检查数据累赘的比例,据以推估数据值不值得压缩,据此可兼顾压缩速度及压缩率。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1