一种面向高速硬件电路实现的GII码译码算法的制作方法
本发明涉及通信技术领域,特别涉及一种面向高速硬件电路实现的gii码译码算法。
背景技术:
前向纠错码被广泛采用于各种数字通信和存储系统中,其中译码算法及其硬件电路的实现是主要关心的问题。大数据和云计算时代的到来,极大地推动了分布式存储技术的研究,而该技术对前向纠错码的编码灵活性提出了更高的要求。integratedinterleaved码正是在这种背景下被提出,随后该码被扩展为generalizedintegratedinterleaved(gii)码,使得这种码每层冗余位的选择可以更加地灵活,相应的译码算法也随之提出。纠正删除的gii码被证明非常适用于磁盘阵列(raid)。
400g以太网标准在2017年底通过批准,为满足编码增益等各项指标,rs码被选作400g以太网的纠错码方案。更高的速度也带来了更高的功耗,不仅是以太网的纠错码方案的选取,任何数字通信或者存储系统都致力于更低的功耗。对于下一代更高速的以太网的纠错码方案,功耗将会是焦点问题。级联码是公认的拥有低译码复杂度的纠错码方案,作为级联码的一种,gii码有望成为下一代以太网的纠错码方案。但是已有的gii译码算法并不利于硬件实现,并且其对应硬件有着较长的关键路径。因此,需要修改已有的gii译码算法使之更加硬件高效,并且缩短其最长路径使之对应硬件电路可以有更高的速度。
技术实现要素:
本发明为使gii译码算法更利于高速硬件电路实现,将现有的译码算法进行改进,提出了新的译码结构。译码算法的改进包括:
●顶层结构上进行改进,每次迭代采用固定纠错能力。纠错能力记为t0,t1,…,tl-1,每个译码阶段采用的rs码的纠错能力与未纠正的interleave的数目没有关系,按照迭代的进行,依次采用tl-1,tl-2,…,t0。
●kes模块的算法采用拥有更短关键路径的ribm算法,相较于已有gii码译码算法中的ibm算法,ribm拥有低至一个加法器和一个乘法器的关键路径。
●利用ribm算法中
●利用ribm算法中存在的恒等关系,对正确译码的interleave的高阶校正子进行计算。对于译码正确的interleave,利用关键方程寄存器中的系数可以求得高阶校正子。例如对于正确译码的interleave,有δ2t=s2t+1λ0+s2tλ1+…+s1λ2t=0,而高阶校正子s2t+1被初始化为0,所以寄存器中的值实际为s2tλ1+…+s1λ2t,高阶校正子可以通过s2t+1=λ0-1(s2tλ1+…+s1λ2t)求得。
●高阶嵌套校正子的计算只在相应的译码阶段进行,而不是在第一阶段完成后将所有高阶嵌套校正子全部求出并存储。假设某一译码阶段对应的纠错能力是ti,若译码在这一阶段没有完成,则需要求出对应的高阶嵌套校正子
附图说明
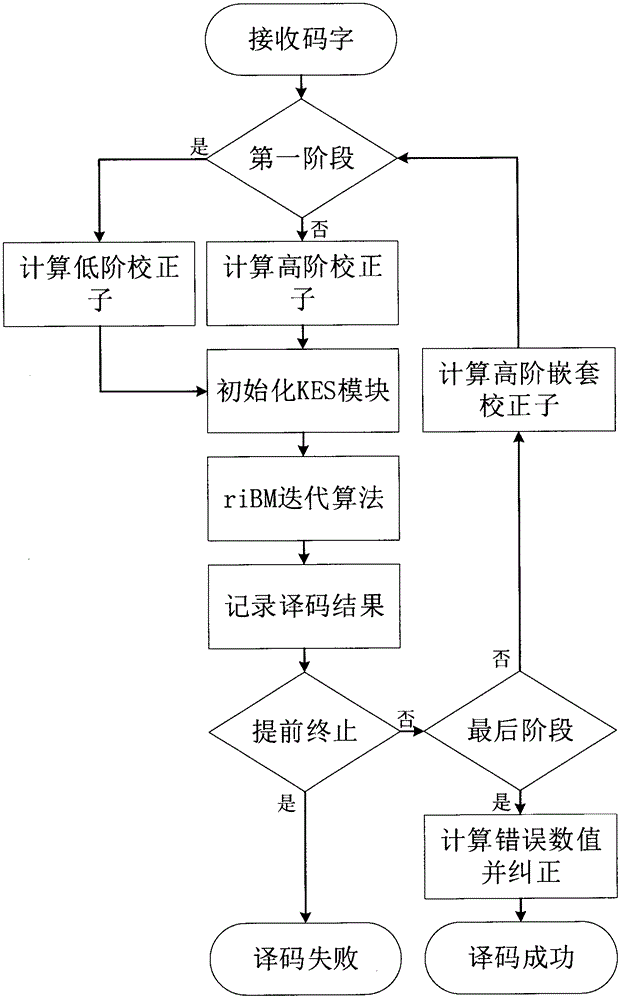
图1为本发明提出的gii码译码算法总流程图;
图2为本发明提出的算法和传统算法的顶层结构对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清晰,下面将结合附图对本发明的具体实施作更进一步的说明。下面通过参考附图描述的实施是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
在第一个译码阶段,对应的低阶校正子s1,s2,…,
考虑纠错能力为ti的译码阶段,在这一阶段完成后,得到对应的多项式和高阶校正子,利用这些结果,可以重新初始化kes单元中
在校正子s1,s2,…,
而kes模块中的多项式为
这2ti个系数满足
在进入下一阶段前,更高阶的校正子
而kes模块中的多项式为
其中2ti-1个系数满足
可见,相比于(3)中的系数,(6)中的系数多出一些项,而这些项是由高阶校正子构成。因此,当一个interleave在纠错能力为ti的译码阶段被判断为不可解时,会进行下一个译码阶段,而在下一个译码阶段开始时,通过高阶校正子
对于可解码的interleave,在后续的译码阶段中多项式不会再进行更新。但是可解码的interleave的λ(x)将被用来计算该interleave对应的高阶校正子,进一步求出高阶嵌套校正子。根据牛顿恒等式有
sjλ0+sj-1λ1+…+sj-υλυ=0,υ<j。(7)
在纠错能力为ti的译码阶段结束后,可解码的interleave的
于是高阶校正子可以表示为
将不可解的interleave的集合记为i,嵌套码j的高阶嵌套校正子
注意到
于是有
得到了高阶嵌套校正子,不可解的interleave的高阶校正子由高阶嵌套校正子与转换矩阵的子矩阵的逆矩阵相乘得到。综上,改译码算法的总流程图如图1.
考虑一个t=(12,13,16,20,28)的gii码,假设5个interleave的错误数目分别是(1,10,13,15,18),图2给出了传统算法和本发明提出的算法的顶层结构对比图。在第一个译码阶段结束后,有3个interleave不可解,在传统算法中,下一阶段使用的纠错能力是t2=16,而本发明提出的算法使用t3=13,后面的译码阶段类似。从总的迭代次数来看,传统算法需要168,而本发明提出的算法只需要146。
- 还没有人留言评论。精彩留言会获得点赞!