一种水声通信信源信道联合译码方法与流程
本申请涉及水声通信的
技术领域:
,具体而言,涉及一种水声通信信源信道联合译码方法。
背景技术:
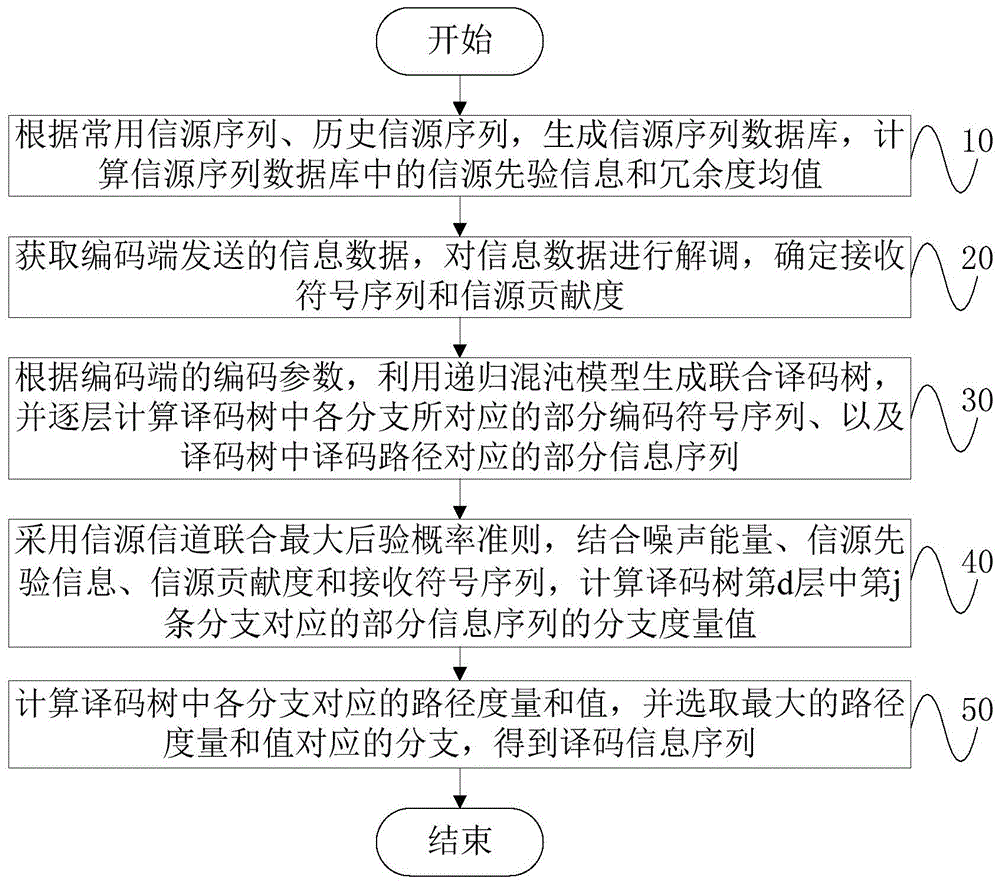
:在传统水声通信系统中,发送端先后将发送信源序列进行信源编码和信道编码,并发送至接收端,接收端根据接收符号序列,先后经过信道译码和信源译码,得到发送信源序列对应的估计。并且,由于水声通信系统的特性,实际的水声通信中,发送信源序列中的各信源符号间,通常存在一定的相关性,当一个信源符号a确定时,信源符号集合中各信源符号作为信源符号a后续符号出现的概率呈现为一定规律的分布,该分布取决于信源符号a的取值,即信源符号间的相关性。由于信源间相关性导致信源序列中存在冗余,而这种冗余难以被传统信源编码方法去除。现有技术中,为了能够充分利用信源序列间的相关性,通常使用的译码方法包括:基于网格的联合译码方法和迭代形式的联合译码方法。而这两种译码方法,一方面,在处理较大的信源符号集合时,由于算法复杂度较高,难以实际应用。另一方面,由于实际发送信源序列所包含相关冗余大小存在差异,而上述两种方法无法调节信源先验信息在译码过程中所占比例,难以在所有可能信源序列发送情况下保证联合译码方法的性能。技术实现要素:本申请的目的在于:通过对历史发送信息和常用信息等统计信源符号间的相关性,在水声通信的译码过程中充分利用信源符号间相关性,对信道译码进行修正,并利用接收信噪比和发送信源序列冗余度,调节信道转移概率与信源转移概率在译码度量中所占比重,从而提高水声通信的译码性能。为实现上述目的,本发明提出了一种水声通信信源信道联合译码方法,所述译码方法适用于信源编码采用定长信源编码,且其信道编码采用递归混沌码的通信系统的译码,所述方法包括:获取编码端发送的信息数据,对所述信息数据进行解调,确定接收符号序列和信源贡献度,其中,所述信源贡献度为发送信源序列的冗余度与冗余度均值的比值;根据所述编码端的编码参数,利用所述递归混沌模型生成联合译码树,并逐层计算所述译码树中各分支所对应的部分编码符号序列、以及所述译码树中译码路径对应的部分信息序列;采用信源信道联合最大后验概率准则,结合噪声能量、信源先验信息、信源贡献度和接收符号序列,计算译码树的信息序列的分支度量值;计算译码树中各分支对应的路径度量和值,并选取最大的路径度量和值对应的分支,得到译码信息序列。作为上述方法的一种改进,所述方法还包括:计算冗余度均值;具体包括:建立包括若干个训练信源序列的信源序列数据库,所述训练信源序列包括:常用信源序列和历史信源序列;所述信源序列数据库中设置有信源符号集合,所述信源符号集合中包括多个信源符号,所述训练信源序列由多个所述信源符号组合而成,所述信源序列数据库中每条训练信源序列均对应一个发送概率;计算信源序列数据库中的信源先验信息;计算所述信源序列数据库中的冗余度均值;将所述信源先验信息和冗余度均值保存至通信系统的编码端和译码端。作为上述方法的一种改进,所述计算信源序列数据库中的信源先验信息,具体包括:统计所述信源符号集合中任一个信源符号作为样本信源序列的首符号s′1时,所述首符号s′1在所述信源符号集合中的初始概率p″(s′1),其中,所述样本信源序列为任一条所述训练信源序列;统计所述样本信源序列中前一个符号s′k-1为条件符号,且当前符号s′k为发送符号时,所述发送符号在所述信源符号集合中的初始条件概率p″(s′k|s′k-1),其中,k为所述样本信源序列中符号的标号,k=2,3,...,所述条件符号和所述发送符号为所述信源符号集合中的任一个信源符号;根据所述初始概率p″(s′1)、所述初始条件概率p″(s′k|s′k-1)和所述定长信源编码的码长,计算所述信源先验信息p(s′1)和p(s′k|s′k-1):式中,β为经验估计选定参数,ls为所述定长信源编码的码长。作为上述方法的一种改进,计算所述信源序列数据库中的冗余度均值,具体包括:指定所述信源序列数据库中第f条训练信源序列的发送概率计算所述第f条训练信源序列的冗余度rf:式中,kf为第f条信源序列的长度,为第f条训练信源序列中的首符号,为第f条训练信源序列中第k个信源符号,k=2,3,...,kf,和为第f条训练信源序列中信源符号的信源先验信息;根据冗余度rf和发送概率计算所述冗余度均值式中,f为所述信源序列数据库中训练信源序列的总数。作为上述方法的一种改进,所述采用信源信道联合最大后验概率准则,结合噪声能量、信源先验信息、信源贡献度和接收符号序列,计算译码树的信息序列的分支度量值,具体包括:根据所述接收符号序列,计算所述接收符号序列的能量均值接收噪声信号,计算所述噪声信号的估计噪声能量e′n,则估计噪声能量e′n的归一化噪声能量en为:根据所述接收符号序列中对应所述译码树中第d层分支的部分接收符号序列y′d、所述译码树中第d层中第j条分支所对应部分编码符号序列x′d,j和所述归一化噪声能量en,计算所述分支路径信道转移度量l′channel,d,j:式中,l′channel,d,j为所述译码树中第d层中第j条分支路径信道转移度量,x′d,j,i为所述部分编码符号序列x′d,j中的第i个元素,y′d,i为所述部分接收符号序列y′d中、与x′d,j,i相对应的元素;nd为译码树中第d层分支所对应的部分接收序列y′d的长度;根据所述译码树中第d层中第j条分支所对应的部分信息序列m′d,j,计算所述译码树中第d层中第j条分支路径信源转移度量l′source,d,j,并利用所述信源贡献度进行加权,计算加权结果与所述分支路径信道转移度量的和值,将所述和值,记作所述译码树中第d层中第j条分支的分支度量值ld,j,所述分支度量值ld,j的计算公式为:ld,j=l′channel,d,j+αl′source,d,j式中,α为所述信源贡献度,r为发送信源序列的冗余度,为所述冗余度均值。作为上述方法的一种改进,所述发送信源序列的冗余度的计算步骤,具体包括:所述发送信源序列发送信源序列s=(s1,…,sk),sk为信源符合;1≤k≤k;则其冗余度r为:式中,k为发送信源序列的长度。作为上述方法的一种改进,所述计算所述译码树中第d层中第j条分支的分支路径信源转移度量l′source,d,j,具体包括:判断所述译码树中第d层中第j条分支所对应部分信息序列m′d,j的长度id是否为所述定长信源编码的码长ls的整数倍,若为否,设定所述译码树中第d层中第j条分支路径信源转移度量l′source,d,j=0,否则,对部分信息序列m′d,j进行信源译码,得到对应所述译码树中第d层中第j条分支的部分信源序列其中,td=id/ls为所述部分信息序列m′d,j对应部分信源序列s′d,j的长度,计算所述译码树中第d层中第j条分支路径信源转移度量l′source,d,j;其中,所述译码树中第d层中第j条分支路径信源转移度量l′source,d,j的计算公式为:式中,s′d,j,1为所述部分信源序列s′d,j中的首符号,和为部分信源序列s′d,j中最后两个信源符号。本发明的有益效果是:1、本发明的方法首先根据常用信源序列和历史发送序列等构建信源序列数据库,并利用训练序列库统计信源先验信息,同时计算信源序列数据库中信源序列冗余度平均值,保存至水声通信系统。在通信系统的发送端,根据发送信源序列冗余度和信源序列数据库中信源序列冗余度平均值,计算信源贡献度并将其发送至译码端;随后将发送信源序列先后经过定长信源编码和递归混沌编码发送至水声信道;译码端采用信源信道联合最大后验概率准则进行译码;译码过程中,随着译码树的扩展,对各路径对应的信息序列进行信源译码;同时综合信道转移概率和信源转移概率,即信源先验信息,计算各路径译码度量;将信源译码和信道译码相结合,充分利用信源冗余抵抗信道差错,进一步提高水声通信系统的译码性能;2、本发明的方法可以在信源间存在相关性的情况下,获得比传统分离译码更好的误码率性能,也解决了现有方法算法复杂度高的问题,本申请还利用接收信噪比和发送信源序列冗余度,在实际应用中调节信道转移概率与信源转移概率在译码度量中所占比重的方法,具有较高的实用价值。附图说明图1是根据本发明的一个实施例的水声通信信源信道联合译码方法的示意流程图;图2是根据本发明的一个实施例的水声通信信源信道联合译码过程的示意图;图3是根据本发明的一个实施例的译码树的示意图;图4是根据本发明的一个实施例的水声通信系统的示意框图;图5是根据本发明的一个实施例的译码测试仿真图。具体实施方式为了能够更清楚地理解本申请的上述目的、特征和优点,下面结合附图和具体实施方式对本申请进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互结合。在下面的描述中,阐述了很多具体细节以便于充分理解本申请,但是,本申请还可以采用其他不同于在此描述的其他方式来实施,因此,本申请的保护范围并不受下面公开的具体实施例的限制。本发明的方法应用于水声通信系统,该系统包括编码端(即发送端)和译码端(即接收端)。如图1所示,本发明提供了一种水声通信信源信道联合译码方法,译码方法适用于信源编码采用定长信源编码,且其信道编码采用递归混沌码的水声通信系统的译码,译码方法包括:步骤10,根据常用信源序列、历史信源序列,生成信源序列数据库,计算信源序列数据库中的信源先验信息和冗余度均值;具体的,利用常用信源序列、历史发送信源序列等构建信源序列数据库,同时按照实际发送的经验,设定各训练序列所对应发送概率其中,常用信源序列、历史信源序列作为信源序列数据库中的已知信源序列,记作训练信源序列。因此,对于生成的信源序列数据库,每一条训练信源序列的长度、信源符号构成等参数,均为已知值。在本实施例中,设定发送信源序列s=(s1,s2,s3,s4)包含4个信源符号,经unicode编码,定长编码码长ls=16,对应的发送信息序列m=[1001011101011110010111100011100001100010101100010110101101001001]。进一步的,将常用信源序列和历史信源序列,记作训练信源序列,构成信源序列数据库,信源序列数据库中设置有信源符号集合,信源符号集合中包括多个信源符号,训练信源序列由多个信源符号组合而成,信源序列数据库中每条训练信源序列均对应一个发送概率,步骤10中,计算信源序列数据库中的信源先验信息,具体包括:步骤11,统计信源符号集合中任一个信源符号作为样本信源序列的首符号s′1时,首符号s′1在信源符号集合中的初始概率p″(s′1),其中,样本信源序列为任一条训练信源序列;步骤12,统计样本信源序列中前一个符号s′k-1为条件符号,且当前符号s′k为发送符号时,发送符号在信源符号集合中的初始条件概率p″(s′k|s′k-1),其中,k为样本信源序列中符号的标号,k=2,3,...,条件符号和发送符号为信源符号集合中的任一个信源符号;具体的,按照各样本信源序列的发送概率,每次从信源序列数据库中随机的抽取一个样本信源序列,统计每个信源符号作为第一个信源符号s′1的初始概率p″(s′1)和确定前一个符号s′k-1时信源序列中第k个符号s′k的初始条件概率p″(s′k|s′k-1)。假设信源序列数据库中包括三条训练信源序列,依次为:aa、abcd和bad,信源符号集合为{a,b,c,d},则信源符号a的初始概率p″(a)=2/3,初始条件概率p″(a|b)=1/2,即序列中,前一个字母为b,后一个字母为a的概率。重复上述过程,直到对信源序列数据库中的每一条训练信源序列均得到有效的统计。步骤13,根据初始概率p″(s′1)、初始条件概率p″(s′k|s′k-1)和定长信源编码的码长,计算信源先验信息,其中,信源先验信息的计算公式为:其中,β为经验估计选定参数,ls为定长信源编码的码长。本实施例中,设定经验估计选定参数β=0.001,定长编码码长ls=16,因此,可以计算出信源序列数据库的信源先验信息。本实施例中,发送信源序列s=(s1,s2,s3,s4)中各信源符号的信源先验信息p,如表1所示:表1p(s1)p(s2|s1)p(s3|s2)p(s4|s3)2.03×10-58.35×10-47.51×10-49.04×10-4进一步的,步骤10中,计算信源序列数据库中的冗余度均值,具体包括:在生成信源序列数据库时,根据实际应用经验指定信源序列数据库中第f条训练信源序列的发送概率psf;计算第f条训练信源序列的冗余度,冗余度计算公式为:式中,kf为第f条信源序列的长度,为第f条训练信源序列中的首符号,为第f条训练信源序列中第k个信源符号,k=2,3,...,kf,和为第f条训练信源序列中信源符号的信源先验信息;根据冗余度和发送概率计算冗余度均值,冗余度均值的计算公式为:式中,f为信源序列数据库中训练信源序列的总数,f=1,2,...。具体的,通过上述计算过程,逐条计算信源序列数据库中训练信源序列的冗余度,再结合发送概率可以计算出冗余度均值信源先验信息和冗余度均值一起保存至通信系统的发送端和接收端。本实施例中,冗余度均值步骤20,获取编码端发送的信息数据,对信息数据进行解调,确定接收符号序列和信源贡献度α,其中,信源贡献度α为发送信源序列的冗余度与冗余度均值的比值;具体的,本实施例中对发送信源序列s=(s1,s2,s3,s4)首先经过定长信源编码,得到待发送信源序列m,随后将待发送信源序列m经递归混沌编码器进行递归混沌编码,设定递归混沌编码过程中信息片段长度g=1。在编码完成后,可得到编码符号序列x=(x1,x2,...,xn),其中,n为编码端发送编码符号总数。同时,编码端对发送信源序列进行冗余度计算,对应的计算公式为:本实施例中,发送信源序列的冗余度r=4.42,因此,信源贡献度待编码端计算出信源贡献度α后,将信源贡献度α作为边信息,连同编码符号序列x作为信息数据,一同发送至译码端,由译码端进行解调,获取信源贡献度α和接收符号序列y。步骤30,根据编码端的编码参数,利用递归混沌模型生成联合译码树,并逐层计算译码树中各分支所对应的部分编码符号序列x′d,j、以及译码树中各译码路径对应的部分信息序列m′d,j,其中,部分编码符号序列为译码树中第d层中第j条分支所对应部分编码符号序列,译码树中编码符号序列x中的部分序列,n'd为译码树中第d层分支对应的部分接收符号序列y′d的长度,为接收符号序列y的部分序列;具体的,如图2所示,本实施例中采用定长信源编码和常规的递归混沌编码。首先由编码端进行编码,待编码端的信息数据发送至译码端后,译码端采用相同的编码方法,根据约定好的编码端的编码参数,生成译码树。如图3所示,由于信息片段长度g=1,因此,译码树中每一个叶子节点对应下一层分支中,包括0和1两条分支。利用递归混沌编码中的译码树,逐层进行译码,译码树的生成过程、译码树第d层中第j条分支所对应部分编码符号序列x′d,j以及部分信息序列m′d,j的计算过程,此处不再赘述,其中,实线箭头所指示的路径为译码树中的一条译码路径。步骤40,采用信源信道联合最大后验概率准则,结合所述归一化噪声能量en、信源先验信息、信源贡献度α和接收符号序列,计算译码树第d层中第j条分支对应的部分信息序列m′d,j的分支度量值ld,j,其中,d=1,2,...,d,j=1,2,...,min{2d,b},b为译码树宽度;进一步的,步骤40中,由于译码树每一层包含信息序列中的1比特,因此译码树总共包含d层子节点集合,每一层子节点集合中包含j条分支,将第d(d=1,2,...,d)层子节点集合中第j(j=1,2,...,j)条分支记作当前分支,计算当前分支对应部分信息序列m′d,j的分支度量值ld,j,具体包括:步骤41,根据接收符号序列,计算接收符号序列的能量均值接收噪声信号,计算噪声信号的估计噪声能量e′n、以及估计噪声能量e′n的归一化噪声能量en,归一化噪声能量en的计算公式为:其中,估计噪声能量e′n可以由译码端在空闲时进行计算,能量均值由译码端在接收到接收符号序列后进行计算,两者采用常规计算方法即可。步骤42,根据接收符号序列中对应译码树中第d层分支的部分接收符号序列y′d、译码树中第d层中第j条分支所对应部分编码符号序列x′d,j和归一化噪声能量en,计算分支路径信道转移度量,分支路径信道转移度量的计算公式为:式中,l'channel,d,j为译码树中第d层中第j条分支路径信道转移度量,x′d,j,i为部分编码符号序列x′d,j中的第i个元素,y′d,i为部分接收符号序列y′d中、与x′d,j,i相对应的元素;nd为译码树中第d层分支所对应的部分接收序列y′d的长度;步骤43,根据译码树中第d层中第j条分支所对应的部分信息序列m′d,j,计算译码树中第d层中第j条分支路径信源转移度量l′source,d,j,并利用信源贡献度进行加权,计算加权结果与分支路径信道转移度量的和值,将和值,记作译码树中第d层中第j条分支的分支度量值ld,j,分支度量值ld,j的计算公式为:ld,j=l′channel,d,j+αl′source,d,j式中,α为由发送端计算并发送至接收端的信源贡献度。进一步的,计算分支路径信源转移度量l′source,d,j,具体包括:判断译码树中第d层中第j条分支所对应部分信息序列m′d,j的长度id是否为定长信源编码的码长ls的整数倍,若否,设定译码树中第d层中第j条分支路径信源转移度量l′source,d,j=0,若是,对部分信息序列m′d,j进行信源译码,得到对应译码树中第d层中第j条分支的部分信源序列计算分支路径信源转移度量l′source,d,j。其中,td为当前分支所对应部分信源序列s′d,j所包含信源符号数(序列长度)。由于译码树每一层对应信息序列中的一个比特,因此部分信息序列m′d,j的长度id,j等于当前译码树层数d,因此有td=d/ls。其中,所述当前分支路径信源转移度量l′source,d,j的计算公式为:式中,s′d,j,1为部分信息序列md,j中的首符号,和为部分信息序列md,j′中最后两个信源符号具体的,当部分信息序列m′d,j的长度不是定长信源编码的码长ls的整数倍时,即d≠tdls,td=1,2,...,本实施例中码长ls=16,此时,无法通过信源译码得到新的信源符号,即部分信息序列m′d,j中不包含完整的、新的信源符号。此时,不进行信源译码,令当前分支对应的分支路径信源转移度量l′source,d,j=0,并计算当前分支度量值ld,j(仅包括分支路径信道转移度量l'channel,d,j)。如果部分信息序列m′d,j的长度id,j=d为码长ls的整数倍,则进行信源译码。当部分信息序列m′d,j的长度id,j=d=ls=16时,即译码树扩展到第16层,部分信息序列的长度为16bit,正好可以通过信源译码得到一个完整信源符号s′d,j,1,对各路径所对应部分信息序列进行信源译码,得到各路径所对应部分信源序列s′d,j=(s′d,j,1),通过上式计算分支路径信道转移度量l'channel,d,j和信源转移度量l′source,d,j,并计算当前分支度量值ld,j。当部分信息序列m′d,j的长度id,j=d=2ls=32时,即译码树扩展到第32层,经过信源译码得到的部分信源序列中包含两个信源符号,即s′d,j=(s′d,j,1,s′d,j,2)。通过上式,计算当前分支的分支路径信源转移度量l′source,d,j和分支路径信道转移度量l′channel,d,j,将信源贡献度α作为分支路径信源转移度量l′source,d,j的权值,并计算当前分支度量值ld,j。步骤50,计算所述译码树中各分支对应的路径度量和值,并选取最大的路径度量和值对应的分支,得到译码信息序列。具体的,计算译码树中各分支对应的路径度量和值,并根据路径度量和值进行排序,保留路径度量和值最大的b条路径,并判断译码树层数是否等于发送信源序列长度,若否,对留存译码路径继续进行译码树扩展并执行步骤40;若是,则选择路径度量和值最大的路径,以该路径所对应信息序列作为译码结果输出。在进行译码树扩展时,为了提高译码效率,减少不必要的运算,同时考虑到译码过程中的容错率,设定每一次译码树扩展时,保留路径度量和值最大的b(b=512)条分支,将路径度量和值较小的分支删除。进一步的,步骤50中,具体包括:步骤51,将当前分支的分支度量值ld,j,采用累加算法,累加至上一层分支的路径度量和值,并对累加后的路径度量和值进行排序,选取并保留路径度量和值中取值较大的b条分支,形成最大分支集合,将最大分支集合中每一条分支对应的部分信息序列md,j′,记作译码片段,判断当前分支是否为译码树中最后一层分支,若是,执行步骤52,若否,对保留的最大分支集合进行译码树扩展,重复步骤40;步骤52,选取最大分支集合中最大路径度量和值对应的分支,作为译码路径,将译码路径对应的译码片段作为译码结果输出。具体的,通过上述过程,逐层对译码树中的分支进行扩展,直到译码树扩展至最后一层后,选择最后一层分支中路径度量和值中的最大值,将该路径度量和值对应的路径作为译码路径,将该译码路径对应的译码片段,作为译码结果输出。如图4所示,为了验证本实施例中译码器的译码性能,搭建水声通信系统,编码器和译码器,编码端采用定长信源编码和递归混沌编码方法进行编码,译码端采用信源信道联合译码,并与现有的采用传统分离译码方法的水声通信系统进行误码率比较,如图5所示,在信噪比相同的情况下,本实施例所对应的误码率(曲线501)明显优于现有方法所对应的误码率(曲线502)。以上结合附图详细说明了本申请的技术方案,在进行信息传输之前,利用常用信源序列、历史发送信源序列等构建信源序列数据库。将信源建模为一阶马尔科夫模型利用信源序列数据库统计信源先验信息。利用信源序列冗余度估计公式计算信源序列数据库中各信源序列冗余度,并计算训练序列冗余度均值。将信源先验信息的统计结果和训练序列冗余度均值保存至水声通信系统,待信息传输时使用。本申请所涉及的信源编码技术可以采用当前已有的任意定长编码技术,同时计算信源贡献度。信源编码后得到的信息序列,经递归混沌码编码,得到编码符号序列,编码符号序列经发送顺序规划和信号调制后,与信源贡献度一同发送至水声信道。译码端首先解码得到信源贡献度,随后采用基于译码树的信源信道联合最大后验概率译码。逐比特(层)地遍历所有可能信息序列,并重现编码过程,得到其对应编码符号序列,并与接收符号序列对比,选择最可能的信息序列作为译码结果。本申请中的步骤可根据实际需求进行顺序调整、合并和删减。本申请装置中的单元可根据实际需求进行合并、划分和删减。最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种广播网络复用协议的转换方法及系统与制造工艺
- 一种基于EM算法的LDPC码译码噪声方差的估计方法与制造工艺
- 一种校验码穿孔和解穿孔方法及装置与制造工艺
- 一种针对Turbo乘积码的修正的软入软出译码方法与制造工艺
- 一种低复杂度的(47,24,11)平方剩余码译码方法与制造工艺
- 一种基于串行抵消列表极化码译码的动态分布排序算法的制造方法与工艺
- 基于k段分解的低复杂度极化码折叠硬件构架的实现方法与制造工艺
- 基于极化码的自适应连续消除译码方法及架构与制造工艺
- 一种基于Hoey序列的非规则Type‑II QC‑LDPC码构造方法与制造工艺
- 一种基于完备循环差集的可快速编码的Type‑II QC‑LDPC码构造方法与制造工艺