一种4DPPM检测中符号插入与删节的处理方法与流程
本发明涉及一种属于数字通信编码领域,特别涉及一种4dppm检测中符号插入与删节的处理方法。
背景技术:
目前,脉冲位置调制(ppm)是一种能获得较高的功率利用率的技术,因此被广泛应用于多种类型的通信系统中。例如,红外数据协会(irda)将4-ppm制定为4-mb/s串行数据链路的标准调制技术;美国国家航空航天局(nasa)提出将ppm技术应用在自由空间光通信系统中;ppm类调制方式也可以应用于基于脉冲的超宽带通信系统等。差分脉冲位置调制(dppm)技术是ppm的一种衍生调制方式。与ppm相比,dppm可获得更高的功率和频谱利用率。然而由于dppm中传输信息的符号序列长度可变,由加性高斯白噪声(awgn)引起的码片翻转会导致对应的符号边界的损坏,同时引起后续符号偏离原始位置,这将导致严重的插入、删节和替代错误,造成传输失败。针对该类错误的一个处理策略是使用最大似然序列检测(mlsd)的方法。但是,mlsd的复杂度很高,在实际应用中不具备可行性。随后,研究者提出使用一种低复杂度的符号软判决方法,具有较好的实用性。但是,其输出序列中会存在插入与删节错误,成为制约其应用的关键。
针对传统的插入与删节错误,传统的纠错码无法有效纠正。因此,针对dppm传输,研究者提出了一些用于处理插入与删节错误的纠错方案。研究者提出了标记(marker)码,将其插入到dppm传输码片中,纠正无线红外通信中的插入与删节错误。进一步,可以利用里德-所罗门(rs)码与marker码进行级联,纠正marker码译码器输出中的残余错误。davey和mackay(dm)提出了水印码的概念,设计了水印码与低密度奇偶校验(ldpc)码的级联码,与其它纠正插入与删节错误的纠错方案相比较,可显著提高纠错性能。该方法利用水印借助前后向算法恢复dppm符号的同步,进一步利用非二进制低密度奇偶校验(ldpc)码来纠正残余错误。然而,该方法具有较高的复杂度。更为重要的是,由于dppm符号检测中引入插入、删节和替代错误的特性不同,其相互之间存在依赖性,通常会伴随发生,这与dm方案的插入/删节/替代(ids)信道不同,因此,dm方案难以直接应用于采用dppm的传输方案。
技术实现要素:
本发明为解决公知技术中存在的技术问题而提供一种可解决4dppm逐符号检测中的插入、删节和替代错误的4dppm检测中符号插入与删节的处理方法。
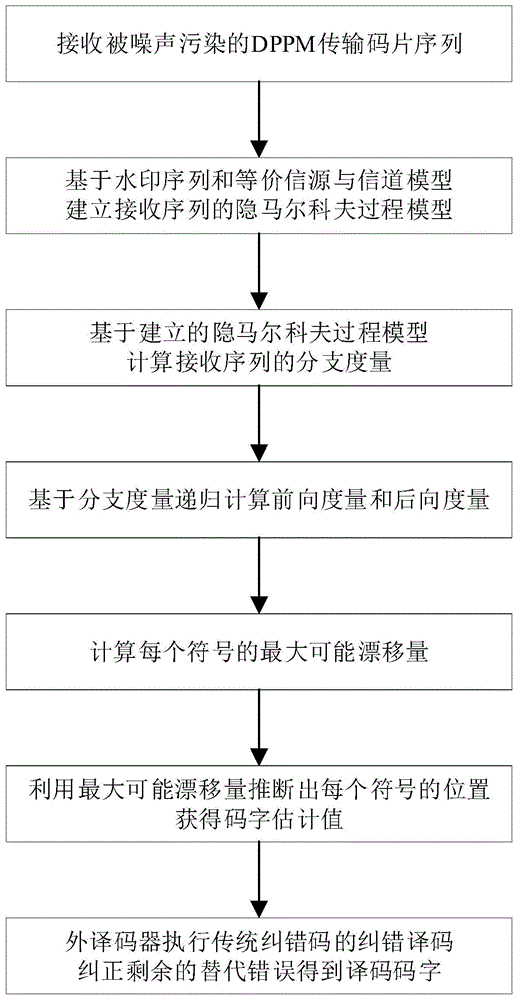
本发明为解决公知技术中存在的技术问题所采取的技术方案是:一种4dppm检测中符号插入与删节的处理方法,在通信信道发送端,将水印序列规则地插入到由信息序列编码的二进制ldpc码中,生成级联码;将级联码转化成4dppm符号序列并调制为4dppm码片序列后发送;在通信信道接收端,将接收码片序列解调为接收符号序列,将接收符号序列依次经由第一级译码器及第二级译码器进行译码处理;其中第一级译码器设有基于已知的水印序列和等价信源与信道模型建立的隐马尔科夫模型,由隐马尔科夫模型的分支度量和转移位置差,递归计算前向度量和后向度量,得到每个符号的最大可能漂移量,由最大可能漂移量确定每个符号的位置并获得码字估计值;第二级译码器采用纠错码算法,利用码字估计值纠正剩余的替代错误,得到最终译码码字。
进一步地,由已知水印序列比特及与其关联的接收符号,推断插入、删节和替代情形,对应等价信源及等价信道模型的所有插入、删节、替代的可能情形,建立状态转移网格图,根据插入/删节/替代信道的不同信噪比下的码片翻转概率及状态转移网格图,建立隐马尔科夫模型。
进一步地,建立隐马尔科夫模型的方法包括如下步骤:
步骤a-1,定义第i时刻的符号漂移量xi为从发送符号t0至待发送符号ti间存在的插入数目减去删节数目,将符号漂移量{xi}作为隐马尔科夫模型的隐状态,设符号最大漂移量为xmax,则xi的取值集合为x={-xmax,...,-1,0,1,...,xmax};
步骤a-2,设经过信道传输后的接收符号序列r为r=r(0)r(1)...r(n-1),其由子序列
步骤a-3,将接收符号序列r解映射为比特对(uivi),得到相应的接收水印序列u和接收码字v;通过比较发送端的水印序列比特和接收符号来推断插入删节和替代情形;
步骤a-4,根据等价信源与信道模型的所有传输情形建立隐马尔科夫模型状态转移网格图,使网格图中的每个节点对应第i个位置的漂移量xi。
进一步地,在隐马尔科夫模型中,设位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态为a;设qi,a,b表示第i个位置的接收符号序列的分支度量,设ji,a,b表示第i个位置的转移位置差;在状态转移过程中,对于位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态a有多种不同情形,对应不同的情形分别计算分支度量qi,a,b,记录转移位置差ji,a,b。
进一步地,设wi代表已知的水印序列w中第i个码字比特;设ri+b代表接收符号序列中第i+b个符号的值;设pf代表码片翻转概率;对于位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态a的多种情形,以及对应的分支度量qi,a,b、转移位置差ji,a,b的计算方法分别如下所示:
(1)若a=b,则对应两种传输情形:正确传输和替代,对于正确传输情形,对应转移路径i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-1)=1,
对于替代情形,对应转移路径为i-2→i,即xi-2=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-2)=2;
(2)若a=b+2,则对应删节情形{(001)→3,(010)→3,(100)→3},转移路径为i-3→i,即xi-3=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
qi,a,b=pf2(1-pf)2,(wi-2wi-1wi)=000,ri+b=(3),
ji,a,b=i-(i-3)=3;
(3)若a=b+1,则对应删节情形{(00)→1,(01)→2,(10)→2,(02)→3,(11)→3,(20)→3},转移路径为i-2→i,即xi-2=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-3)=3;
(4)若a=b-1,则对应插入情形{1→(00),2→(01),2→(10),3→(02),3→(11),3→(20)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-1)=1;
(5)若a=b-2,则对应插入情形{2→(000),3→(001),3→(010),3→(100)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
qi,a,b=pf2(1-pf)2,wi=1,(ri-2+bri-1+bri+b)=(000)or(001)or(010)or(100),
ji,a,b=i-(i-1)=1。
进一步地,通过第一级译码器获得码字估计值的方法包括如下步骤:
步骤b-1,在隐马尔科夫模型中,定义前向度量为位置i处的漂移量为xi=a并且接收到r的前(i-1+a)个符号的概率,用fi(a)表示前向度量,fi(a)计算公式为:
式中
定义后向度量为给定状态xi=b时,输出r的尾部序列(ri+b,...)的概率,用bi(b)表示后向度量,bi(b)计算公式为:
式中
步骤b-2,基于计算得到的前向度量fi(a)和后向度量bi(b),设最大可能漂移量为
步骤b-3,由于每个符号的最大可能漂移量与其码字比特的最大可能漂移量一致,使用漂移量
进一步地,水印序列为二进制伪随机序列。
本发明具有的优点和积极效果是:本发明提出一种针对4dppm检测中的高效算法逐符号地检测造成的符号插入与删节错误的处理方法。与传统的处理方法不同,本发明采用两级译码器,其中第一级译码器基于已知的水印序列和等价信源与信道模型建立隐马尔科夫模型,来估计接收符号的插入与删节错误,采用硬判决前向-后向算法输出码字估计值。第二级译码器采用外译码器,执行现有技术的纠错码算法来纠错译码,纠正剩余的替代错误,得到最终译码码字。本方法可以处理传输过程中的插入删节错误。可有效纠正4dppm传输中的插入、删节和替代错误,与利用动态规划算法和维特比算法作为内译码算法的译码方案相比,本发明提出的译码方案提高了纠正4dppm传输中插入、删节和替代错误的性能。
附图说明
图1是本发明的一种工作流程框图;
图2为本发明的一种隐马尔科夫模型的状态转移网格图;
图3为本发明的一种工作原理示意图;
图4为采用不同内译码算法的4dppm传输性能比较示意图;
图5为编码方案中采用不同码长ldpc码的4dppm传输性能比较示意图;
图6为不同信噪比下码片翻转错误率和符号插入/删节/替代错误率示意图;
图7为采用维特比内译码器及采用本发明的内译码器处理后汉明距离内每帧错误比特个数平均值比较图。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹列举以下实施例,并配合附图详细说明如下:
请参见图1至图7,一种4dppm检测中符号插入与删节的处理方法,在通信信道发送端,将水印序列规则地插入到由信息序列编码的二进制ldpc码中,生成级联码;将级联码转化成4dppm符号序列并调制为4dppm码片序列后发送;在通信信道接收端,将接收码片序列解调为接收符号序列,将接收符号序列依次经由第一级译码器及第二级译码器进行译码处理;其中第一级译码器设有基于已知的水印序列和等价信源与信道模型建立的隐马尔科夫模型,由隐马尔科夫模型的分支度量和转移位置差,递归计算前向度量和后向度量,得到每个符号的最大可能漂移量,由最大可能漂移量确定每个符号的位置并获得码字估计值;第二级译码器采用纠错码算法,利用码字估计值纠正剩余的替代错误,得到最终译码码字。每个位置与其转移对应的前一个位置之间的距离,称为位置差。转移位置差表示状态转移过程中每个位置的转移对应的位置差。
本发明中,第一级译码器又称内译码器;第二级译码器又称外译码器。
ldpc中文释义为低密度奇偶校验。
4dppm中文释义为四进制差分脉冲位置调制。
位置差为每个位置与其转移对应的前一个位置之间的距离。
优选地,可由已知水印序列比特及与其关联的接收符号,推断插入、删节和替代情形,可对应等价信源及等价信道模型的所有插入、删节、替代的可能情形,建立状态转移网格图,可根据插入/删节/替代信道的不同信噪比下的码片翻转概率及状态转移网格图,建立隐马尔科夫模型。
优选地,建立隐马尔科夫模型的方法可包括如下步骤:
步骤a-1,可定义第i时刻的符号漂移量xi为从发送符号t0至待发送符号ti间存在的插入数目减去删节数目,可将符号漂移量{xi}作为隐马尔科夫模型的隐状态,可设符号最大漂移量为xmax,则xi的取值集合为x={-xmax,...,-1,0,1,...,xmax};
步骤a-2,可设经过信道传输后的接收符号序列r为r=r(0)r(1)...r(n-1),其可由子序列
步骤a-3,可将接收符号序列r解映射为比特对(uivi),得到相应的接收水印序列u和接收码字v;可通过比较发送端的水印序列比特和接收符号来推断插入删节和替代情形;
步骤a-4,可根据等价信源与信道模型的所有传输情形建立隐马尔科夫模型状态转移网格图,使网格图中的每个节点对应第i个位置的漂移量xi。
优选地,在隐马尔科夫模型中,可设位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态为a;设qi,a,b表示第i个位置的接收符号序列的分支度量,可设ji,a,b表示第i个位置的转移位置差;在状态转移过程中,对于位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态a有多种不同情形,可对应不同的情形分别计算分支度量qi,a,b,记录转移位置差ji,a,b。
优选地,可设wi代表已知的水印序列w中第i个码字比特;可设ri+b代表接收符号序列中第i+b个符号的值;可设pf代表码片翻转概率;对于位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态a的多种情形,以及对应的分支度量qi,a,b、转移位置差ji,a,b的计算方法可分别如下所示:
(1)若a=b,则对应两种传输情形:正确传输和替代,对于正确传输情形,对应转移路径i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-1)=1,
对于替代情形,对应转移路径为i-2→i,即xi-2=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-2)=2;
(2)若a=b+2,则对应删节情形{(001)→3,(010)→3,(100)→3},转移路径为i-3→i,即xi-3=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
qi,a,b=pf2(1-pf)2,(wi-2wi-1wi)=000,ri+b=(3),
ji,a,b=i-(i-3)=3;
(3)若a=b+1,则对应删节情形{(00)→1,(01)→2,(10)→2,(02)→3,(11)→3,(20)→3},转移路径为i-2→i,即xi-2=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-3)=3;
(4)若a=b-1,则对应插入情形{1→(00),2→(01),2→(10),3→(02),3→(11),3→(20)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
ji,a,b=i-(i-1)=1;
(5)若a=b-2,则对应插入情形{2→(000),3→(001),3→(010),3→(100)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量qi,a,b及转移位置差ji,a,b的计算公式为:
qi,a,b=pf2(1-pf)2,wi=1,(ri-2+bri-1+bri+b)=(000)or(001)or(010)or(100),
ji,a,b=i-(i-1)=1。
优选地,通过第一级译码器获得码字估计值的方法包括如下步骤:
步骤b-1,在隐马尔科夫模型中,可定义前向度量为位置i处的漂移量为xi=a并且接收到r的前(i-1+a)个符号的概率,可用fi(a)表示前向度量,fi(a)计算公式可为:
式中
位置i处的前向度量是根据位置i转移对应的前一个位置的前向度量计算得到的,若位置i的漂移量为a,则位置i转移对应的前一个位置的漂移量c的取值可以为{a-2,a-1,a,a+1,a+2},根据c值与a值的差,对照建立的隐马尔科夫模型可求得对应的转移位置差,用ji,c,a表示,i-ji,c,a即为位置i转移对应的前一个位置的坐标。
可定义后向度量为给定状态xi=b时,输出r的尾部序列(ri+b,...)的概率,可用bi(b)表示后向度量,bi(b)计算公式可为:
式中
位置i处的后向度量是根据位置i转移对应的后一个位置的后向度量计算得到的,若位置i的漂移量为b,则位置i转移对应的后一个位置的漂移量c的取值可以为{b-2,b-1,b,b+1,b+2},根据b值与c值的差对照建立的隐马尔科夫模型可求得对应的转移位置差,用ji,b,c表示,i+ji,b,c即为位置i转移对应的后一个位置的坐标。
步骤b-2,可基于计算得到的前向度量fi(a)和后向度量bi(b),设最大可能漂移量为
步骤b-3,由于每个符号的最大可能漂移量与其码字比特的最大可能漂移量一致,可使用漂移量
水印序列可为二进制伪随机序列。
下面结合本发明的一个具体实施例来进一步说明本发明的工作流程及工作原理,其中下述具体实施例中的各表达式定义同上所述。
一种4dppm检测中符号插入与删节的处理方法,主要以长度为576比特的预定伪随机序列分别与长度为576比特、码率为r=0.67和r=0.5的ldpc码构造的长度为1152比特的级联水印码为例,请参考图3,包括以下步骤:
(1)发送端将信息序列b编码为长度为576比特的二进制ldpc码d,将长度为576比特的水印序列w,即二进制伪随机序列,规则地插入到码字d中,生成级联码[w0d0,w1d1,...,wn-1dn-1],级联码的长度为1152比特,依次将比特对(widi)按照映射规则{(00)→‘0’,(01)→‘1’,(10)→‘2’,(11)→‘3’},转化成4dppm符号xi,生成长度为576比特的符号序列x,将符号序列x按照规则{‘0’→(1),‘1’→(01),‘2’→(001),‘3’→(0001)},调制为4dppm码片序列c,码片序列c经过信道传输引起码片翻转,得到接收码片序列z,使用4dppm逐符号检测方法将接收码片序列恢复为长度为576比特的接收符号序列r;
(2)第一级译码器基于水印序列和等价信源与信道模型建立隐马尔科夫过程模型,确定隐马尔科夫模型的隐状态和可观测向量,根据等价信源与信道模型的所有传输情形建立隐马尔科夫模型状态转移网格图;
(2.1)定义第i时刻的符号漂移量xi为从发送符号t0至待发送符号ti间存在的插入数目减去删节数目,将符号漂移量{xi}作为隐马尔科夫模型的隐状态,为降低提出的内译码算法的计算量,将符号最大漂移量限定为10,所以xi的取值集合为x={-10,...,-1,0,1,...,10};
(2.2)经过信道传输后的接收符号序列r为r=r(0)r(1)...r(n-1),由子序列
(2.3)根据规则{(0)→(00),(1)→(01),(2)→(10),(3)→(11)}将接收符号序列r解映射为比特对(uivi),得到相应的接收水印序列u和接收码字v;
(2.4)根据等价信源与信道模型的所有传输情形建立隐马尔科夫模型状态转移网格图,网格图中的每个节点对应第i个位置的漂移量xi,给定位置i-1的漂移状态为xi-1=a时,位置i的漂移状态xi=b的可能取值为b∈{a,a+1,a+2},给定位置i-2的漂移状态为xi-2=a时,位置i的漂移状态xi=b的可能取值为b∈{a-1,a},给定位置i-3的漂移状态为xi-3=a时,位置i的漂移状态xi=b的可能取值为b∈{a-2},在状态转移过程中,利用变量ji,a,b记录第i个位置的转移对应的位置差,ji,a,b∈{1,2,3}。
(3)基于建立的隐马尔科夫过程模型,利用广义插入/删节/替代(ids)信道不同信噪比下的码片翻转概率,比较已知水印比特和相关联的接收符号,考虑到等价信源及等价信道模型的所有插入、删节、替代的可能情形,对于位置i的漂移状态xi=b,转移对应的前一个位置的漂移状态a有5种不同情形,初始化分支度量qi,a,b,记录转移位置差ji,a,b;可设wi代表已知的水印序列w中第i个码字比特;可设ri+b代表接收符号序列中第i+b个符号的值;可设pf代表码片翻转概率;5种不同情形下,分支度量qi,a,b和转移位置差ji,a,b计算方法可如下所示:
(3.1)若a=b,则对应两种传输情形:正确传输和替代,对于正确传输情形,对应转移路径i-1→i,即xi-1=a,xi=b,分支度量计算公式为:
ji,a,b=i-(i-1)=1,
对于替代情形,对应转移路径为i-2→i,即xi-2=a,xi=b,分支度量计算公式为:
ji,a,b=i-(i-2)=2;
(3.2)若a=b+2,则对应删节情形{(001)→3,(010)→3,(100)→3},转移路径为i-3→i,即xi-3=a,xi=b,分支度量计算公式为:
qi,a,b=pf2(1-pf)2,(wi-2wi-1wi)=000,ri+b=(3),
ji,a,b=i-(i-3)=3;
(3.3)若a=b+1,则对应删节情形{(00)→1,(01)→2,(10)→2,(02)→3,(11)→3,(20)→3},转移路径为i-2→i,即xi-2=a,xi=b,分支度量计算公式为:
ji,a,b=i-(i-3)=3;
(3.4)若a=b-1,则对应插入情形{1→(00),2→(01),2→(10),3→(02),3→(11),3→(20)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量计算公式为:
ji,a,b=i-(i-1)=1;
(3.5)若a=b-2,则对应插入情形{2→(000),3→(001),3→(010),3→(100)},转移路径为i-1→i,即xi-1=a,xi=b,分支度量计算公式为:
qi,a,b=pf2(1-pf)2,wi=1,(ri-2+bri-1+bri+b)=(000)or(001)or(010)or(100),ji,a,b=i-(i-1)=1。
(4)使用隐马尔科夫模型的分支度量qi,a,b和转移位置差ji,a,b,递归计算前向度量fi(a)和后向度量bi(b),然后计算每个符号的最大可能漂移量
(4.1)使用隐马尔科夫模型中计算的接收符号序列分支度量qi,a,b以及记录的转移位置差ji,a,b,递归计算前向度量fi(a)和后向度量bi(b)。
前向度量
后向度量
(4.2)基于计算得到的前向度量fi(a)和后向度量bi(b),计算每个符号的最大可能漂移量
(4.3)由于每个符号的最大可能漂移量与其码字比特的最大可能漂移量一致,使用漂移量
(5)外译码器利用码字估计值
在加性高斯白噪声(additivewhitegaussiannoise,awgn)信道下,对本发明提出的4dppm检测中符号插入与删节的处理方法进行性能仿真,对内译码算法分别采用动态规划算法、维特比算法和提出的基于隐马尔科夫模型的硬判决前后向算法在不同信噪比下的误帧率性能进行了对比。参见图4,仿真结果显示本发明提出的译码算法可以显著提高4dppm传输中插入、删节和替代错误的纠错性能。
进一步,为了说明本发明提出的译码方案对插入与删节错误更多的长码的适用性,使用码长为24576比特,码率为0.67的ldpc码与长度为24576比特的预定伪随机序列构造长度为24576×2比特的级联水印码。对内译码算法分别采用维特比算法和基于隐马尔科夫模型的硬判决前后向算法的两种不同长度的级联水印码在不同信噪比下的误帧率性能进行了对比。参见图5,仿真结果显示在相同码率下,采用分组译码的方式,长码对于4dppm传输中插入、删节和替代错误具有更优越的纠错性能。硬判决前后向算法是指利用隐马尔科夫模型中的分支度量和转移位置差递归计算前向度量和后向度量,由前向度量和后向度量计算每个符号的最大可能漂移量,进而得到码字估计值。
使用码长为576比特,码率为0.67的ldpc码来分析广义ids信道的错误特性,并比较了提出的硬判决前后向算法和维特比算法的残余替代错误的数量。参见图6,为了计算基于隐马尔科夫模型的硬判决前后向算法,使用不同信噪比下的码片翻转错误率来估计码片翻转概率pf,广义ids信道的码片翻转是由awgn信道和4dppm符号软解调方法引起的,从而导致的符号插入、删节和替代错误可以通过编辑距离进行测量,图6给出了通过广义ids信道发生码片翻转和符号插入/删节/替代的错误率。参见图7,给出了两种内译码后汉明距离内每帧错误比特个数的平均值,可以观察到,插入和删节错误已通过内译码器进行了纠正或转换为少量的残余替代错误。另外,与维特比算法相比,本发明提出的基于隐马尔科夫模型的硬判决前后向算法具有更好的同步性能,在snr=5db时可以将残余误码率降低到2.25%,为外译码器提供了可靠的保证。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅为了描述,不代表实施例的优劣。
以上所述仅为本发明较佳的实施例,并不用于限制本发明,凡在本发明的精神原则内,所做的任何修改、等同替换以及改进等,均应包含在本发明的保护范围内。以上所述的实施例仅用于说明本发明的技术思想及特点,其目的在于使本领域内的技术人员能够理解本发明的内容并据以实施,不能仅以本实施例来限定本发明的专利范围,即凡本发明所揭示的精神所作的同等变化或修饰,仍落在本发明的专利范围内。
- 还没有人留言评论。精彩留言会获得点赞!