用于进行重组解码的低密度奇偶校验解码装置及相关方法与流程
本申请是申请日为2017年03月21日、申请号为201710171352.7、发明创造名称为“用于进行重组解码的低密度奇偶校验解码装置及相关方法”的中国发明申请的分案申请。
本发明涉及低密度奇偶校验(low-densityparitycheck,ldpc)的重组解码器(shuffledecoder),尤其涉及一种额外包括序集合(orderedset)的低密度奇偶校验重组解码器。
背景技术:
低密度奇偶校验解码器是使用具有奇偶位(paritybit)的线性错误校正码来进行解码,其中奇偶位会提供用以验证接收到的码字(码字)的奇偶方程式给解码器。举例来说,低密度奇偶校验可为一具有固定长度的二进制代码,其中所有的符元(symbol)相加会等于零。
在编码过程中,所有的数据位会被重复执行并且被传送至对应的编码器,其中每个编码器会产生一奇偶符元(paritysymbol)。码字是由k个信息位(informationdigit)以及r个校验位(checkdigit)所组成。如果码字总共有n位,则k=n-r。上述码字可用一奇偶校验矩阵来表示,其中所述奇偶校验矩阵具有r列(表示方程式的数量)以及n行(表示位数),如图1所示。这些码之所以被称为「低密度」是因为相较于奇偶校验矩阵中位0的数量而言,位1的数量相对的少。在解码过程中,每次的奇偶校验皆可视为一奇偶校验码,并随后与其他奇偶校验码一起进行交互校验(cross-check),其中解码会在校验节点(checknode)进行,而交互校验会在变量节点(variablenode)进行。
其中,校验节点(checknode)代表奇偶位(paritybit)的数量,且变量节点(variablenode)代表一码字中位的数量。如果一特定方程式与码符元(codesymbol)有关,则对应的校验节点与变量节点之间会以联机来表示。被估测的消息会沿着这些联机来传递,并且于节点上以不同的方式组合。一开始时,变量节点将发送一估测至所有联机上的校验节点,其中这些联机包括被认为是正确的位。接着,每个校验节点会依据对所有其他的连接的估测(connectedestimate)来针对每一变数节点进行新的估测,并且将新的估测传回至变量节点。新的估测是基于:奇偶校验方程式迫使所有的变量节点连接至一特定校验节点,以使总和为零。
重组解码(shuffledecoding,或称混洗解码)是以上述技术为基础,但使用分层可靠度传递(layeredbeliefpropagation)算法来实现。奇偶矩阵(又称为h矩阵)被分为多层,且每一层被分为多个子矩阵(sub-matrix)。在解码过程中,所述多个子矩阵会被同时更新,使得多个解码算法被有效率地重组(混洗)。每一码字长度会被分为g个群组,若一码字具有n个位,则所述g个群组中每一群组会具有n/g个位。对于群组的更新是以平行的方式进行,也就是说,校验节点会被平行地更新。
一开始,数据会通过一输入封套(inputwrapper)来传递并且储存于一通道值存储器。在一完整的码字通过此方式传递后,通道值存储器可将估测储存为v个向量,其中所述v个向量会在每次迭代中更新。由于算法被重组(shuffled,或称混洗),多个桶型移位器(barrelshifter)会对调整后的多个通道值安排不同的顺序,使得这些通道值能传递在正确的数据路径,以传递于有序集合存储器。
重组解码的特征在于,在当前迭代中,并不使用来自前一次迭代尾端的信息,反而是:在当前迭代中得到的信息会立即地用于同一迭代中,进而达到平行更新(parallel)的目的。然而在第一次迭代中,数据会输入至通道值存储器,但有序集合存储器中没有信息。因此,第一次迭代仅能用来储存数据以及参数的初始值(initializationofparameters),无法用来进行任何错误校正。
技术实现要素:
基于以上缘由,本发明的一目的在于公开一种系统以及相关方法来进行重组解码,以得到更好的效能。
本发明的一实施例公开了一种用于进行重组解码的低密度奇偶校验解码装置,包括一输入封套、一低密度奇偶校验解码器以及一初始化电路。所述输入封套,用以接收包括多个码字的输入数据以及错误校正信息,以及对所述输入数据进行填码。所述低密度奇偶校验解码器耦接于所述输入封套,且所述低密度奇偶校验解码器用以接收填码后的所述输入数据、依据所述错误校正信息来对填码后的所述输入数据进行具有多次迭代的低密度奇偶校验解码以产生多个通道值,以及在最后一次迭代中输出一硬决策通道值。所述初始化电路耦接于所述低密度奇偶校验解码器,且所述初始化电路用以于所述多次迭代的第一次迭代中接收所述输入数据、将所述输入数据储存至一有序集合数据,以及立即地将所述有序集合数据传送至所述低密度奇偶校验解码器,使得所述错误校正信息可在所述第一次迭代中对填码后的所述输入数据进行低密度奇偶校验解码。
本发明的另一实施例公开了一种低密度奇偶校验解码装置进行重组解码的方法,包括:接收包括多个码字的输入数据以及错误校正信息;对所述输入数据进行填码;以及依据所述错误校正信息来对填码后的所述输入数据进行具有多次迭代的低密度奇偶校验解码以产生多个通道值。所述方法于第一次迭代中包括以下步骤:利用一初始化电路来将所述输入数据储存至一有序集合数据;立即地将所述有序集合数据传送至所述低密度奇偶校验解码装置的一低密度奇偶校验解码器;以及在最后一次迭代中输出一硬决策通道值。
附图说明
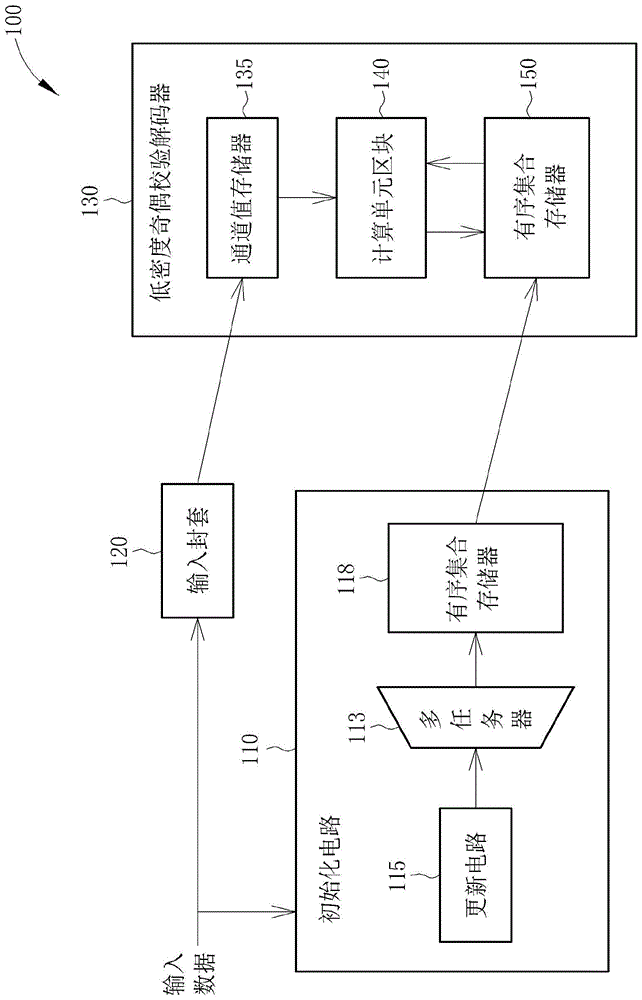
图1是根据本发明的一实施例的重组解码器的方块图。
其中,附图标记说明如下:
100重组解码器
110初始化电路
115更新电路
118有序集合存储器
113多任务器
120输入封套
130低密度奇偶校验解码器
135通道值存储器
140计算单元区块
150有序集合存储器
具体实施方式
请参考图1,图1是根据本发明的一实施例的重组解码器(shuffledecoder)100的方块图。重组解码器100包括一初始化电路110,初始化电路110包括一更新电路115、一有序集合存储器(orderedsetmemory)118以及一多任务器113。重组解码器100另包括一输入封套(inputwrapper)120以及一低密度奇偶校验(low-densityparitycheck,ldpc)解码器130。低密度奇偶校验解码器130包括一通道值存储器135、一计算单元区块140以及一有序集合存储器150。
输入封套120是用于对码字填入足够的位组(bytes),也就是填码(padding),以供低密度奇偶校验解码器130之用。举例来说,当输入数据只具有8个位组,而低密度奇偶校验解码器130需要具有48个位组的数据来进行操作时,则有需要使用输入封套。
在解码过程的第一次迭代中,输入数据是被输入至输入封套120,并且进行填码的动作,被填码后的数据接着会被分为g个群组并且储存于通道值存储器135,以上是现有技术中第一次迭代中的所有步骤。然而,在本实施例的系统中,输入数据也会输入至初始化电路110,其中输入数据会先储存于更新电路115,接着经多任务器113进行处理后再输入至有序集合存储器118。当输入数据的总线宽度(buswidth)是远小于低密度奇偶校验解码器130内的总线宽度时,输入数据可快速地储存于有序集合存储器118,这使得当通道值存储器135已经储存有码字时,有序集合存储器118内的数据会传给低密度奇偶校验解码器130内的有序集合存储器150。
由于重组解码(shuffledecoding)是使用第一次迭代所得到的数据,储存于通道值存储器135中的数据可于第一次迭代就被更新。
因此,有用的迭代的数量会增加1(相较于现有技术中的第一次迭代无法进行校正),且低密度奇偶校验解码器可操作在近乎100%的效率,而非80%。
初始化电路110中的多任务器113是用以将数据编组为一有序集合,以存入有序集合存储器118。在第一次迭代中,数据的正负号(sign)会直接地输入至低密度奇偶校验解码器130,这是因为对存储器电路进行一次性的(one-shot)更新会有更高的难度。在后续的迭代中,正负号将会被低密度奇偶校验解码器135计算。
以上实施例的电路架构并不复杂,且本领域通常知识者可在参阅以上实施例后轻易地实作。除了初始化电路110,低密度奇偶校验解码器130中的计算单元区块140只需要增设额外的加法器即可接收第一次迭代中数据的正负号,因此计算单元区块140可利用正负号与接收到的码字来计算出通道值。
本发明只需通过增设初始化电路就可减少低密度奇偶校验解码器的延迟时间,并且确保在第一次迭代就可进行解码操作。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!