数据压缩方法及装置与流程
1.本技术涉及数据存储领域,尤其涉及一种数据压缩方法及装置。
背景技术:
2.随着信息时代的到来,产生了大量的数据。在许多领域,需要通过压缩算法对数据进行压缩。压缩算法可以分为重复内容查找和熵编码等不同机制的算法。基于重复内容查找机制的压缩算法包括蓝波-立夫(lempel-ziv,lz)编码算法、游程编码(run length encoding, rle)算法等。基于熵编码机制的压缩算法包括哈夫曼编码算法、算数编码算法等。
3.目前,在进行数据压缩时,一般都是采用一种压缩算法对待压缩的全部数据进行压缩,压缩后的数据的长度在压缩前不可知,但是有很多应用如邮件应用、数据库应用对所处理的数据的长度有限制,对于不满足其长度限制的数据,则无法处理,例如对于邮件应用来说,超过限制长度的数据则会出现传输错误。
技术实现要素:
4.本技术提供了一种数据压缩方法。该方法对压缩后的长度大于长度限制值的待压缩数据,在压缩过程中根据长度限制值对压缩后数据进行分割,使得压缩后数据包括多个子压缩数据,且子压缩数据的长度小于限制值,如此能够被应用处理,满足了应用需求。本技术还提供了上述方法对应的装置、设备、计算机可读存储介质以及计算机程序产品。
5.第一方面,本技术提供了一种数据压缩方法。该方法可以由计算机设备执行,其中,计算机设备可以是终端,或者是服务器。为了便于描述,以计算机设备为终端进行示例说明。
6.具体地,终端获取待压缩数据及压缩数据的长度限制值,当所述待压缩数据压缩后的数据的长度大于所述长度限制值时,终端在对所述待压缩数据压缩过程中,依据所述长度限制值对所述待压缩数据进行分割,使所述待压缩数据被压缩后包括至少两个压缩文件,且每个压缩文件的长度小于所述长度限制值。
7.即使待压缩数据压缩后的数据长度大于限制值,通过本方法可以将压缩数据分割为多个长度小于等于长度限制值的压缩文件,从而可以被应用成功处理,满足了应用需求。
8.在一些可能的实现方式中,终端可以逐块预测每个数据块压缩后的长度,并对当前预测的数据块以及当前预测块之前的数据块的长度累加得到第一预测压缩长度,当所述第一预测压缩长度大于所述长度限制值时,则终端可以根据所述当前预测的数据块之前的数据块进行压缩,压缩后的数据形成第一压缩文件,所述第一压缩文件属于所述至少两个压缩文件。
9.由于预测数据块压缩后的长度所耗费的时间远小于对数据块进行压缩,然后确定压缩后的长度所耗费的时间,因此,通过先预测压缩后的长度,然后根据预测结果对待压缩数据进行分割,基于分割后的数据进行压缩可以有效提高压缩效率。
10.在一些可能的实现方式中,所述当前预测的数据块之前的数据块为n个,因此,当前预测的数据块以及当前预测块之前的数据块的长度累加得到的第一预测压缩长度大于长度限制值时,终端可以回退数据块,对当前预测的数据块之前的n个数据块中的部分或全部数据块(例如为第1至第n-k个数据块,n为大于等于2的自然数,k为小于n的自然数)进行合并压缩。当压缩后的数据长度小于等于所述长度限制值,则将所述压缩后的数据作为第一压缩文件。
11.通过在第一预测压缩长度大于长度限制值时进行数据块回退,可以有效减少压缩次数,进而提高压缩效率。
12.在一些可能的实现方式中,第1至第n-k个数据块合并压缩后的数据长度小于等于所述长度限制值时,终端可以继续预测第n-k个数据块之后的数据块的压缩后的长度,以对所述待压缩数据的剩余的数据继续分割。如此可以避免重复压缩,减少计算量,降低计算资源开销。
13.在一些可能的实现方式中,当前预测的数据块之前的数据块为n个,终端根据当前预测的数据块之前的数据块进行压缩,具体可以是先对第1至第n-k个数据块进行合并压缩, n为大于等于2的自然数,k为小于n的自然数,当压缩后的数据长度大于所述长度限制值,则可以回退数据块,对回退后的数据块进行合并压缩,例如终端可以对第1至第n-k-1 个数据块进行合并压缩。
14.通过逐步回退可以减少压缩次数,提高压缩效率,减少压缩开销。
15.在一些可能的实现方式中,待压缩数据可以是未经过分块的数据流。终端可以对数据流进行分块,得到多个数据块。当数据的分割位置对数据不产生影响时,终端还可以基于如下分块方法进行分块,以保障对数据块进行合并压缩形成的压缩文件都在限定长度内的前提下提升缩减率。
16.具体地,终端先对待压缩数据进行第一次分块,例如是按照平均分块法分块,获得多个初始数据块。终端可以记录多个初始数据块的边界值,该边界值可以通过初始数据块的最后一个字节的序号表征。
17.终端还可以对多个初始数据块进行匹配,例如终端可以通过lz编码算法进行匹配,得到各个初始数据块的四元组。该四元组包括块间四元组,具体是不同数据块匹配成功所产生的四元组。当一个数据块与多个数据块匹配成功时,终端记录数据块与距离该数据块最近的数据块匹配所产生的四元组。其中,四元组包括无匹配字符序列、无匹配字符长度、匹配长度和匹配偏移。其中,被匹配的字符序列和匹配的字符序列可以形成一个匹配。
18.终端可以基于初始数据块的边界以及初始数据块的四元组(例如是四元组中的匹配偏移)确定边界与匹配是否交叉。其中,表征边界的字符在被匹配的字符序列和匹配的字符序列之间,则边界与匹配交叉。基于此,终端可以统计出初始数据块的边界与匹配交叉的次数。终端可以基于该交叉的次数,选择最佳分块位置,例如可以选择与匹配交叉的次数最小,或者是小于预设值的边界作为最佳分块位置。终端基于该最佳分块位置合并最佳分块位置之间的数据块,得到最终的数据块。
19.当压缩算法需要进行分块回退时,按照最优分块位置进行回退,那么最优分块位置两侧的数据会分两次参与到压缩中,由于输入数据本身的匹配需要跨越该位置的数量和长度较少,则按照此种分块方式进行压缩,总体上的压缩率相较于分块前的损失最小。
20.第二方面,本技术提供了一种数据压缩装置。所述装置包括:
21.通信单元,用于获取待压缩数据及压缩数据的长度限制值;
22.压缩单元,用于当所述待压缩数据压缩后的数据的长度大于所述长度限制值时,在对所述待压缩数据压缩过程中,依据所述长度限制值对所述待压缩数据进行分割,使所述待压缩数据被压缩后包括至少两个压缩文件,且每个压缩文件的长度小于所述长度限制值。
23.在一些可能的实现方式中,所述压缩单元具体用于:
24.逐块预测每个数据块压缩后的长度,并对当前预测的数据块以及当前预测块之前的数据块的长度累加得到第一预测压缩长度;
25.当所述第一预测压缩长度大于所述长度限制值时,则根据所述当前预测的数据块之前的数据块进行压缩,压缩后的数据形成第一压缩文件,所述第一压缩文件属于所述至少两个压缩文件。
26.在一些可能的实现方式中,所述当前预测的数据块之前的数据块为n个,所述压缩单元具体用于:
27.对第1至第n-k个数据块进行合并压缩,n为大于等于2的自然数,k为小于n的自然数;
28.当压缩后的数据长度小于等于所述长度限制值,则将所述压缩后的数据作为第一压缩文件。
29.在一些可能的实现方式中,所述压缩单元还用于:
30.继续预测第n-k个数据块之后的数据块的压缩后的长度,以对所述待压缩数据的剩余的数据继续分割。
31.在一些可能的实现方式中,所述当前预测的数据块之前的数据块为n个,所述压缩单元具体用于:
32.对第1至第n-k个数据块进行合并压缩,n为大于等于2的自然数,k为小于n的自然数;
33.当压缩后的数据长度大于所述长度限制值,则对第1至第n-k-1个数据块进行合并压缩。
34.第三方面,本技术提供一种设备,所述设备包括处理器和存储器。所述处理器、所述存储器进行相互的通信。所述处理器用于执行所述存储器中存储的指令,以使得设备执行如第一方面或第一方面的任一种实现方式中的数据压缩方法。
35.第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,所述指令指示设备执行上述第一方面或第一方面的任一种实现方式所述的数据压缩方法。
36.第五方面,本技术提供了一种包含指令的计算机程序产品,当其在设备上运行时,使得设备执行上述第一方面或第一方面的任一种实现方式所述的数据压缩方法。
37.本技术在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
附图说明
38.为了更清楚地说明本技术实施例的技术方法,下面将对实施例中所需使用的附图作以简单地介绍。
39.图1为本技术实施例提供的一种终端的结构示意图;
40.图2为本技术实施例提供的一种数据压缩方法的流程图;
41.图3为本技术实施例提供的一种图形用户界面的示意图图;
42.图4为本技术实施例提供的一种数据分块的示意图;
43.图5为本技术实施例提供的一种数据压缩方法的流程示意图;
44.图6为本技术实施例提供的一种数据压缩方法的流程示意图;
45.图7为本技术实施例提供的一种数据压缩装置的结构示意图。
具体实施方式
46.本技术实施例中的术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。
47.首先对本技术实施例中所涉及到的一些技术术语进行介绍。
48.数据压缩:数据压缩是按照特定的编码机制用比未经编码少的数据比特(或者其它信息相关的单位)表示信息的过程。数据压缩具体是通过数据压缩算法实现。根据编码机制不同,数据压缩算法可以分为基于重复内容查找机制的压缩算法、基于熵编码机制的压缩算法等不同类型。基于重复内容查找机制的压缩算法包括lz编码算法、rle算法等。以 lz编码算法为例,其压缩原理为遍历输入数据生成一个历史字典,将重复出现的一段数据使用占据空间更少的字典索引的形式进行存储。基于熵编码机制的压缩算法包括哈夫曼编码算法、算数编码算法等。以哈夫曼编码算法为例,其压缩原理为根据不同字符在输入数据中出现的频率不同对字符进行重新编码来实现压缩。
49.目前,在进行数据压缩时,一般都是采用一种压缩算法对全部数据进行压缩,压缩后的数据的长度在压缩前不可知。而很多应用如邮件应用、数据库应用对所处理的数据的长度有限制,对于不满足长度限制的数据,则无法处理,例如对于邮件应用而言,超过限制长度的数据可以导致传输错误。基于此,业界亟需提供一种数据压缩方法,对压缩后的数据的长度进行限制,以满足应用的需求。
50.本技术实施例提供了一种数据压缩方法。在数据压缩之前,首先获取处理该数据的应用对数据的长度限制值,当待压缩数据压缩后的数据的长度大于所述长度限制值时,在数据压缩过程中,依据所述长度限制值对压缩后数据进行分割,使所述压缩后数据包括至少两个子压缩数据,且所述子压缩数据的长度小于所述限制值。这样,即使待压缩数据压缩后的数据长度大于限制值,也可以被应用成功处理。
51.本技术实施例可以应用于不同应用场景。例如,可以用于邮件应用,邮件应用对邮件的附件大小有限制,假定邮件应用允许上传的附件的大小为20兆字节(megabyte,mb) 以内,则可以对大于20mb的附件进行压缩,获得多个大小在20mb以内的压缩文件。又例如,可以用于信息管理系统,信息管理系统对用户上传的附件大小有限制,则可以对该附件进行压缩,将附件压缩为多个大小在长度限制值以内的压缩文件。
52.邮件应用、信息管理系统仅仅是对应用场景的示例说明,该数据压缩方法还可以用于其他对压缩后长度有限制的场景。例如可以应用于传输带宽、传输可靠性出现瓶颈的场景,或者是应用于视频压缩等因存储粒度、网络传输要求限制压缩后长度的场景。
53.本技术实施例提供的数据压缩方法可以由计算机设备执行。该计算机设备可以是终端,或者是服务器。其中,终端包括但不限于台式机、笔记本电脑、平板电脑或者是智能手机等设备。服务器可以是本地服务器(例如是自有数据中心中的服务器)或者是云服务器(例如是云服务提供商的数据中心中的服务器)。进一步地,该方法可以由单台计算机设备执行,也可以由多台计算机设备形成的集群执行,其中,通过集群执行可以提高数据压缩服务的稳定性和可靠性。
54.为了便于理解,下文以终端执行数据压缩方法进行示例说明。
55.首先,对终端的硬件结构进行介绍。图1为本技术实施例提供的一种终端的结构示意图,如图1所示,终端100包括总线101、处理器102、通信接口103和存储器104。处理器102、存储器104和通信接口103之间通过总线101通信。
56.总线101可以是外设部件互连标准(peripheral component interconnect,pci)总线或扩展工业标准结构(extended industry standard architecture,eisa)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图1中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
57.处理器102可以为中央处理器(central processing unit,cpu)、图形处理器(graphicsprocessing unit,gpu)、微处理器(micro processor,mp)或者数字信号处理器(digital signalprocessor,dsp)等处理器中的任意一种或多种。
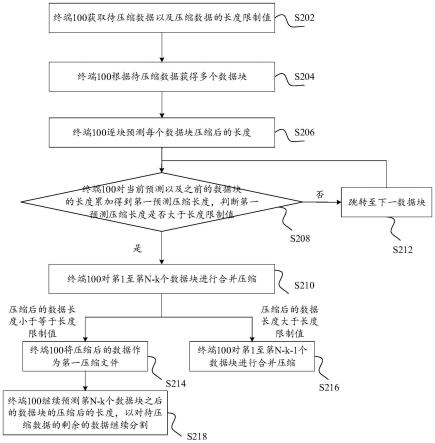
58.通信接口103用于与外部通信。例如,通信接口103用于获取待压缩数据,获取压缩数据的长度限制值,或者是输出至少两个长度小于上述长度限制值的压缩文件等等。
59.存储器104可以包括易失性存储器(volatile memory),例如随机存取存储器(randomaccess memory,ram)。存储器104还可以包括非易失性存储器(non-volatile memory),例如只读存储器(read-only memory,rom),快闪存储器,硬盘驱动器(hard disk drive,hdd) 或固态驱动器(solid state drive,ssd)。
60.存储器104中存储有可执行代码,处理器102执行该可执行代码以执行前述数据压缩方法。
61.图1对用于执行数据压缩方法的终端100的硬件结构进行了详细介绍,接下来,从终端100的角度,结合附图对本技术实施例提供的数据压缩方法进行详细说明。
62.参见图2所示的数据压缩方法的流程图,该方法包括:
63.s202:终端100获取待压缩数据以及压缩数据的长度限制值。
64.具体地,终端100可以提供用户界面。该用户界面可以是图形用户界面(graphical userinterface,gui),或者是命令用户界面(command user interface,cui)。终端100可以接收用户通过上述gui或者cui输入的数据以及压缩数据的长度限制值。其中,压缩数据的长度限制值是指处理所述待压缩数据的应用对所述待压缩数据压缩后长度的限制值。终端100可以直接接收用户输入的数据,也可以接收用户输入的数据的存储路径,然后根据该存储路径获取数据。
65.下面以gui为例,对终端获取待压缩数据以及压缩数据的长度限制值进行说明。
66.参见图3所示的gui的界面示意图,如图3所示,gui承载有存储地址输入控件302 和长度限制值输入控件304,其中,存储地址输入控件302用于输入数据的存储地址,该存储地址输入控件302支持下拉输入方式,长度限制值输入控件304用于输入长度限制值度。gui还承载有提交控件306和取消控件308。用户通过存储地址输入控件302输入数据的存储地址,以及通过长度限制值输入控件304输入长度限制值后,可以点击提交控件 306触发提交操作,终端100可以响应于用户的提交操作,获取数据以及长度限制值。
67.需要说明的是,在一些实施例中,应用也可以默认设置有长度限制值,如此,gui也可以不承载上述长度限制值输入控件304,用户无需配置长度限制值,通过gui输入待压缩数据的存储地址,终端100根据该存储地址获取待压缩数据,以及根据默认设置获得长度限制值。
68.s204:终端100根据待压缩数据,获得多个数据块。
69.数据中可以包括多个数据块。数据中包括的多个数据块可以是原生的,也可以是终端 100对数据进行分块得到。例如,终端100可以根据数据块数量或者数据块的长度,对数据进行平均分块,获得多个数据块。需要说明的是,当数据总长度不能被数据块数量或者数据块的长度整除时,个别数据块的长度可以不等于其他数据块的长度。例如,数据长度为130kb时,单个数据块长度为8kb,则可以分块为15个8kb的数据块以及1个10kb 的数据块。
70.针对数据没有明确分块的场景,比如输入的数据为长度较长的连续输入,并且数据的分割位置对数据不产生影响,本技术实施例还可以提供一种分块方法,在保证对数据块进行合并压缩形成的压缩文件都在限定长度内的前提下提升缩减率。
71.参见图4所示的数据分块的流程示意图,原始数据为连续的数据流,终端100可以按照平均分块方式,将数据分为大小相等的多个初始数据块。终端100可以记录多个初始数据块的边界值,该边界值可以通过初始数据块的最后一个字节的序号表征。接着,终端100 还可以对多个初始数据块进行匹配,例如终端100可以通过lz编码算法进行匹配,得到各个初始数据块的四元组。该四元组包括块间四元组,具体是不同数据块匹配成功所产生的四元组。当一个数据块与多个数据块匹配成功时,本技术实施例中记录数据块与距离该数据块最近的数据块匹配所产生的四元组。其中,四元组包括无匹配字符序列、无匹配字符长度、匹配长度和匹配偏移。
72.为了便于理解,本技术提供了一具体示例。该示例中假定数据流的长度为500字节(byte, b),终端100基于平均分块方法进行分块,获得多个初始数据块,该初始数据块的边界为 100b、200b、
……
400b等位置。数据流以及初始数据块的边界具体如下所示:
73.(
……
qwer
……
xyz
……
tyui
……
,(100b),
……
qwer
……
tyui
……
xyz
……
, (200b),
……
lmn
……
tyui
……
opq
……
sdf
……
,(300b),
……
lmn
……
,(400b),
……ꢀ
sdf
……
opq
……
)
74.其中,省略号表示未匹配成功的字符,“qwer”等表示匹配成功的字符,(100b)、(200b) 等表示初始数据块的边界。第一个数据块中的“qwer”与第二个数据块中的“qwer”匹配成功,第一个数据块中的“xyz”与第二个数据块中的“xyz”匹配成功,第一个数据块中“tyui”的与第二个数据块中的“tyui”匹配成功,第二个数据块中“tyui”的与第三个数据块中的“tyui”匹配成功,第三个数据块中的“lmn”与第四个数据块中的“lmn”匹配成功,第三个数据块中的“opq”和第五个数据块中的“opq”匹配成功,第三个数据块中的“sdf”和第五
个数据块中的“sdf”匹配成功。
75.终端100可以基于上述匹配结果,记录边界和匹配交叉的次数。其中,边界和匹配交叉是指边界字符在匹配字符之间。基于此,在上述示例中,终端100可以确定边界100b 与匹配交叉的次数为3,边界200b与匹配交叉的次数为1,边界300b与匹配交叉的次数为3,边界400b与匹配交叉的次数为2。终端100可以根据边界与匹配交叉的次数,选择最佳分块位置,根据该最佳分块位置合并初始数据块,得到最终的数据块。其中,终端100 可以选择与匹配交叉的次数最小,或者是小于预设值的边界作为最佳分块位置。例如,终端100可以选择200b作为最佳分块位置,进一步地,终端100还可以选择400b作为最佳分块位置。
76.当压缩算法需要进行分块回退时,按照最优分块位置进行回退,那么最优分块位置两侧的数据会分两次参与到压缩中,由于输入数据本身的匹配需要跨越该位置的数量和长度最少,则按照此种分块方式进行压缩,总体上的压缩率相较于分块前的损失最小。
77.s206:终端100逐块预测每个数据块压缩后的长度。
78.在一些可能的实现方式中,当数据块采用基于熵编码机制的压缩算法时,终端100可以根据香农范诺熵极限,逐块预测每个数据块的压缩后长度的预测值。具体地,香农范诺熵极限通过如下公式计算:
79.h(x)=-σ
x
p(x)log
2 p(x)
ꢀꢀꢀꢀ
(1)
80.其中,x表示熵编码输入的字符,p(x)表示字符x的出现概率,h(x)表征香农范诺熵极限,具体是平均每输入一个字节进行熵编码后的最小比特(bit)位数。基于此,数据块的压缩后长度的预测值可以根据熵编码输入长度(例如是字节数)和香农范诺熵极限确定,具体如下所示:
81.len
out
x=len
in
*h(x)=len
in
*(-σ
x
p(x)log
2 p(x))
ꢀꢀꢀꢀ
(2)
82.其中,len
in
表示输入长度,例如是熵编码输入的字节数,len
out
x表示输出长度,例如是对输入进行熵编码后的长度的预测值。需要说明的是,当终端100直接对数据块进行熵编码时,输入长度可以是数据块的长度。
83.在一些可能的实现方式中,终端100也可以先对数据块进行匹配,例如通过lz编码算法对数据块进行逐块匹配,得到每个数据块的四元组,该四元组包括块间四元组和块内四元组。其中,块间四元组可以参见上文相关内容描述,块内四元组是指该数据块内匹配成功所产生的四元组。与块间四元组类似,块内四元组也包括无匹配字符序列、无匹配字符长度、匹配长度和匹配偏移。终端100可以将四元组作为熵编码输入进行熵编码,从而实现对数据块的压缩。相应地,输入长度可以为四元组的长度。终端100可以根据四元组的长度以及香农范诺熵极限确定对输入进行熵编码后的长度的预测值。
84.其中,终端100可以根据四元组的每一种元素(如无匹配字符序列、无匹配字符长度、匹配长度和匹配偏移)单独进行字频统计,即统计每一种元素中每种字符出现次数,并由字频除以字符总数获得字符x的出现概率p(x)。如此,终端100可以根据p(x),通过上述公式(1)确定香农范诺熵极限h(x)。
85.在一些可能的实现方式中,终端100还可以对预测过程中产生的过程数据进行管理。其中,该过程数据可以包括对数据块进行匹配产生的四元组,以及各数据块的四元组对应的边界信息。终端100可以存储数据块的四元组以及四元组的边界信息。该边界信息包括所述数据块的四元组的数量。例如,终端100对一个数据块进行匹配,获得10个四元组,终端
100可以存储与该数据块对应的10个四元组,以及存储该数据块对应的四元组的数量(例如为10)。如此,终端100可以根据该边界信息,区分不同数据块的四元组,进而可以快速获取相应的四元组,实现数据块的快速回退。
86.在另一些可能的实现方式中,终端100也可以获取历史压缩率,该历史压缩率包括终端100在本次压缩之前对数据进行压缩的压缩率。其中,对数据进行压缩的压缩率包括整体压缩率,该整体压缩率可以为数据块的压缩率提供参考。基于此,终端100可以根据数据块的长度以及历史压缩率,预测所述数据块的压缩后长度。例如终端100可以将数据块的长度和历史压缩率的乘积,确定为数据块的压缩后长度的预测值。在一些实施例中,终端100可以确定历史压缩率的平均值,例如确定最近5次整体压缩率的平均值,然后根据数据块的长度以及历史压缩率的平均值,确定数据块的压缩后长度的预测值。
87.进一步地,终端100还可以对历史压缩率进行更新,以使得历史压缩率能够接近真实压缩率,进而实现对压缩后长度的准确预测。具体地,终端100可以在根据所述数据的长度和所述数据的压缩数据的长度确定当前压缩率,然后根据所述当前压缩率更新所述历史压缩率。更新后的历史压缩率可以用于下一轮预测。其中,终端100在对历史压缩率进行管理时,可以采用先进先出(first in first output,fifo)策略等进行管理。
88.s208:终端100对当前预测的数据块以及当前预测的数据块之前的数据块的长度累加得到第一预测压缩长度,判断所述第一预测压缩长度是否大于所述长度限制值。当所述第一预测压缩长度大于所述长度限制值时,执行s210;当所述第一预测压缩长度小于等于所述长度限制值时,执行s212。
89.假定当前预测的数据块之前的数据块为n个,终端100对这n个数据块的预测压缩长度和当前数据块的预测压缩长度进行累计,得到第一预测压缩长度。当该第一预测长度大于长度限制值时,表明这n+1个数据块被压缩后长度有较高概率大于长度限制值,终端 100可以进行数据块回退,例如回退一个数据块,则有较高概率获得压缩后长度小于等于长度限制值的压缩文件,基于此,终端可以执行s210。当第一预测长度小于等于长度限制值时,表明这n+1个数据块被压缩后长度有较高概率小于长度限制值,终端100仍可以增加新的数据块,以进行合并压缩,从而实现尽可能提高输入粒度,基于此,终端100可以执行s212。
90.s210:终端100对第1至第n-k个数据块进行合并压缩。当压缩后的数据长度小于等于长度限制值时,执行s214;当压缩后的数据长度大于长度限制值时,执行s216。
91.其中,n为大于等于2的自然数,k为小于n的自然数,例如k可以取值为0或1等等。终端100可以对当前预测的数据块之前的n个数据块中的部分或全部数据块进行合并,例如终端100可以对n个数据块合并,然后对合并后的数据块进行压缩。其中,终端100 可以根据实际需求选择相应的压缩算法,实现对合并后的数据块的压缩。例如,终端100 可以选择基于熵编码的压缩算法,例如哈夫曼编码算法、算数编码算法等,或者是选择基于重复内容查找的压缩算法,例如lz编码算法、rle算法等,实现对合并后的数据块的压缩。
92.其中,终端100通过lz编码算法确定数据块的四元组,并基于数据块的四元组预测压缩后的长度时,终端100可以利用上述四元组等,通过lz编码算法进行熵编码,从而实现对合并后的数据块的压缩。终端100通过历史压缩率预测数据块压缩后的长度时,终端100可以选择基于熵编码的压缩算法或者是基于重复内容查找的压缩算法(如lz编码算法)进
行编码,从而实现对合并后的数据块的压缩。
93.s212:终端100跳转至下一数据块,以下一数据块作为当前预测的数据块,执行s208。
94.具体地,终端100逐步累计新的数据块的预测压缩长度,在数据块的预测压缩长度之和小于等于长度限制值时,跳转至下一数据块,继续累加,直至长度之和大于长度限制值时,终端100可以停止累加。如此,终端100可以从这些数据块中确定合适的分割点,以便对多个数据块进行分割,进而对分割后的数据块合并压缩。
95.s214:终端100将压缩后的数据作为第一压缩文件,然后执行s218。
96.压缩后的数据长度小于等于长度限制值,而且是在预测压缩长度大于长度限制值的情况下回退少量数据块进行压缩,因而该压缩后的数据长度比较接近长度限制值,终端100 可以将压缩后的数据作为第一压缩文件。一方面,满足了应用对于长度限制值的要求,另一方面,避免了压缩文件粒度过小。
97.s216:终端100对第1至第n-k-1个数据块进行合并压缩。
98.压缩后的数据长度大于长度限制值,终端100可以回退数据块,然后对回退后的数据块进行合并压缩。其中,图2所示实施例是以回退一个数据块之后,对第1至第n-k-1个数据块进行合并压缩示例说明。在本技术实施例其他可能的实现方式中,终端100也可以每次回退多个数据块,例如可以回退2个数据块。
99.s218:终端100继续预测第n-k个数据块之后的数据块的压缩后的长度,以对待压缩数据的剩余的数据继续分割。
100.由于第1个数据块和第n-k个数据块已进行合并压缩,获得第一压缩文件,终端100 可以继续预测n-k个数据块之后的数据块的压缩后的长度,并按照相同的方式对待压缩数据的剩余的数据继续分割。
101.需要说明的是,本技术实施例提供的数据压缩方法,用于待压缩数据压缩后的数据的长度大于长度限制值时,在对所述待压缩数据压缩过程中,依据所述长度限制值对所述待压缩数据进行分割,使待压缩数据压缩被压缩后包括至少两个压缩文件,且每个压缩文件的长度小于所述长度限制值。当待压缩数据压缩后的数据的长度小于等于长度限制值时,则可以直接对待压缩数据整体进行压缩,无需执行上述分块、预测过程。还需要说明的是,当待压缩数据被压缩为至少两个长度小于等于长度限制值的压缩文件时,终端100还可以获得完整的压缩文件,根据完整的压缩文件进行解压,从而恢复待压缩数据。
102.基于上述内容描述,本技术实施例提供了一种数据压缩方法。该方法通过预测数据块的压缩后长度,并基于预测结果对数据块进行合并压缩,实现了对压缩后数据的长度进行限制,例如限制为目标压缩长度以内,满足了业务需求。而且,该方法可以使得数据块合并压缩后长度接近目标压缩长度,保障了最大粒度的输入,从而保障了压缩率。进一步地,该方法无需对相同数据进行反复压缩确认,保证了压缩性能。该方法支持自动地对压缩后长度进行限制,无需用户手动试验,简化了用户操作,提高了用户体验。
103.接下来,将以基于熵编码的压缩算法进行数据压缩以及基于重复内容查找的压缩算法进行数据压缩示例说明。
104.参见图5所示的数据压缩方法的流程示意图,该方法包括如下步骤:
105.s502:终端100接收用户输入的数据。
106.s504:终端100对用户输入的数据进行分块,得到多个数据块。
107.具体地,终端100可以采用平均分块法对输入的数据进行分块,得到多个数据块。进一步地,终端100还可以基于对数据块进行匹配获得的匹配偏移,确定数据块的边界与匹配交叉的次数,基于交叉的次数确定最佳分块位置,根据该分块位置对数据块合并,得到最终的数据块。
108.s506:终端100对多个数据块通过lz编码算法进行逐块匹配,获得多个数据块的四元组。
109.四元组包括无匹配字符、无匹配字符长度、匹配长度和匹配偏移。其中,无匹配字符是指开始匹配之前的字符序列,无匹配字符长度是指开始匹配之前的字符序列的长度,匹配长度是指匹配的字符序列的长度。匹配偏移是指匹配的字符序列相对于无匹配字符中被匹配的字符序列的偏移。
110.为了便于理解,下面结合一具体示例进行说明。假设数据块包括字符序列“asdfgsdfkhj”,则终端100可以确定无匹配字符为“asdfg”,无匹配字符长度为5,匹配的字符序列为“sdf”,基于此,匹配长度为3,“asdfg”之后的“sdf”到“asdfg”中“sdf”的偏移为4,基于此,匹配偏移为4。如此,第一个四元组可以记作(“asdfg”, 5,3,4)。接着终端100对剩下的字符继续进行匹配,具体是对每个字符从右往左匹配,如此,可以确定第二个四元组(“khj”,3,0,0)。
111.需要说明,上述示例主要是对块内四元组进行说明。终端100还可以跨数据块匹配,获得块间四元组。例如,上述数据块之前还包括其他数据块时,则可以继续和前面的数据块进行匹配,得到块间四元组。
112.s508:终端100存储每个数据块的四元组以及每个数据块的四元组的边界信息。
113.终端100可以对匹配过程产生的四元组进行存储,由此实现对包括四元组在内的过程数据的管理。进一步地,终端100还可以对四元组的边界信息,例如是对数据块进行匹配产生的四元组的个数进行存储,以便于后续回退数据块时可以根据该边界信息快速回退。
114.s510:终端100根据四元组,逐块预测每个数据块压缩后的长度。
115.终端100可以对数据块的四元组中的每一种元素单独进行字频统计,并由字频除以字符总数得到字符的出现概率。然后基于香农范诺熵极限以及熵编码输入预估压缩后长度。由于熵值预测过程主要分为字频统计和熵值计算过程,而熵值计算过程耗时较短,可以忽略不计,相较于熵编码过程中,建表以及编码等操作占据90%以上的耗时,统计字频仅占据较少的时间,也即预估压缩后长度时间远小于实际压缩时间。通过先预测再压缩,可以有效提高压缩效率。
116.需要说明的是,对四元组的每一种元素单独进行字频统计可以实现对每种元素单独进行熵编码,对于字符总数较少的元素可以有效提高字符的出现概率,如此可以提升对应元素的编码效果。
117.s512:终端100对当前预测的数据块以及当前预测的数据块之前的数据块的长度累加得到第一预测压缩长度,判断第一预测压缩长度是否大于长度限制值。若是,则执行s514,若否,则执行s522。
118.s514:终端100对第1至第n-k个数据块进行合并压缩。当压缩后的数据长度小于等
于长度限制值时,执行s516;当压缩后的数据长度大于长度限制值时,执行s518。
119.其中,终端100可以基于第1至第n-k个数据块的四元组,对数据块进行熵编码,由此实现对数据块的合并压缩。
120.s516:终端100将压缩后的数据作为第一压缩文件。
121.s518:终端100根据四元组的边界回退一个数据块,对第1至第n-k-1个数据块进行合并压缩。
122.s520:终端100继续预测第n-k个数据块之后的数据块的压缩后的长度,以对待压缩数据的剩余的数据继续进行分割。
123.s522:终端100跳转至下一数据块,然后再执行s512。
124.其中,s512至s522的具体实现可以参见图2所示实施例相关内容描述,在此不再赘述。
125.图5以基于熵编码的压缩算法进行数据压缩进行示例说明,接下来以基于重复内容查找的压缩算法进行数据压缩进行示例说明。
126.参见图6所示的数据压缩方法的流程示意图,该方法包括:
127.s602:终端100接收用户输入的数据。
128.s604:终端100对用户输入的数据进行分块,得到多个数据块。
129.s602至s604的具体实现参见上文相关内容描述,在此不再赘述。
130.s606:终端100根据数据块的长度以及历史压缩率,逐块预测每个数据块压缩后的长度。
131.终端100维护有每次压缩过程对应的整体压缩率,本次压缩之前的整体压缩率可以统称为历史压缩率。终端100可以基于最近n次压缩率的平均值以及数据块的长度,预测数据块压缩后的长度。
132.s608:终端100对当前预测的数据块以及当前预测的数据块之前的数据块的长度累加得到第一预测压缩长度,判断第一预测压缩长度是否大于长度限制值。若是,则执行s610,若否,则执行s618。
133.s610:终端100对第1至第n-k个数据块进行合并压缩。当压缩后的数据长度小于等于长度限制值时,执行s612;当压缩后的数据长度大于长度限制值时,执行s614。
134.s612:终端100将压缩后的数据作为第一压缩文件,然后执行s616。
135.s614:终端100回退一个数据块,对第1至第n-k-1个数据块进行合并压缩。
136.具体地,终端100可以通过基于重复内容查找的压缩算法,对第1至第n-k-1个数据块进行合并压缩。
137.s616:终端100继续预测第n-k个数据块之后的数据块的压缩后的长度,以对待压缩数据的剩余的数据继续进行分割。
138.s618:终端100跳转至下一数据块,然后再执行s608。
139.s620:当待压缩数据的所有数据块被压缩形成至少两个压缩文件时,终端100确定当前压缩率,根据该当前压缩率更新历史压缩率。
140.具体地,终端100可以根据待压缩数据的长度和压缩文件的总长度确定当前压缩率,然后将当前压缩率维护至数据库或数据表中,从而更新历史压缩率。
141.上文结合图1至图6对本技术实施例提供的数据压缩方法进行了详细介绍,下面将
结合附图对本技术实施例提供的装置进行介绍。
142.参见图7所示的数据压缩装置的结构示意图,该数据压缩装置700可以是软件装置,包括具有数据压缩功能的软件单元模块,该数据压缩装置700也可以是硬件装置,包括具有相应功能的硬件单元模块,该装置700包括:
143.通信单元702,用于获取待压缩数据及压缩数据的长度限制值。
144.其中,通信单元702获取待压缩数据及压缩数据的长度限制值的具体实现可以参见图 2所示实施例中s202相关内容描述,在此不再赘述。
145.压缩单元704,用于当所述待压缩数据压缩后的数据的长度大于所述长度限制值时,在对所述待压缩数据压缩过程中,依据所述长度限制值对所述待压缩数据进行分割,使所述待压缩数据被压缩后包括至少两个压缩文件,且每个压缩文件的长度小于所述长度限制值。
146.压缩单元704在对所述待压缩数据压缩过程中,依据所述长度限制值对所述待压缩数据进行分割,使所述待压缩数据被压缩后包括至少两个压缩文件的具体实现可以参见图2 所示实施例中s204至s218相关内容描述,在此不再赘述。
147.在一些可能的实现方式中,所述压缩单元704具体用于:
148.逐块预测每个数据块压缩后的长度,并对当前预测的数据块以及当前预测块之前的数据块的长度累加得到第一预测压缩长度;
149.当所述第一预测压缩长度大于所述长度限制值时,则根据所述当前预测的数据块之前的数据块进行压缩,压缩后的数据形成第一压缩文件,所述第一压缩文件属于所述至少两个压缩文件。
150.其中,压缩单元704逐块预测每个数据块压缩后的长度,并对当前预测的数据块以及当前预测块之前的数据块的长度累加得到第一预测压缩长度的具体实现可以参见s206至 s208相关内容描述,在此不再赘述。
151.压缩单元704根据所述当前预测的数据块之前的数据块进行压缩,压缩后的数据形成第一压缩文件的具体实现可以参见s210、s214相关内容描述,在此不再赘述。
152.在一些可能的实现方式中,所述当前预测的数据块之前的数据块为n个,所述压缩单元704具体用于:
153.对第1至第n-k个数据块进行合并压缩,n为大于等于2的自然数,k为小于n的自然数;
154.当压缩后的数据长度小于等于所述长度限制值,则将所述压缩后的数据作为第一压缩文件。
155.压缩单元704对第1至第n-k个数据块进行合并压缩,当压缩后的数据长度小于等于所述长度限制值,则将所述压缩后的数据作为第一压缩文件的具体实现可以参见s210、 s214相关内容描述,在此不再赘述。
156.在一些可能的实现方式中,所述压缩单元704还用于:
157.继续预测第n-k个数据块之后的数据块的压缩后的长度,以对所述待压缩数据的剩余的数据继续分割。
158.压缩单元704继续预测第n-k个数据块之后的数据块的压缩后的长度,以对所述待压缩数据的剩余的数据继续分割的具体实现可以参见s218相关内容描述,在此不再赘述。
159.在一些可能的实现方式中,所述当前预测的数据块之前的数据块为n个,所述压缩单元具体用于:
160.对第1至第n-k个数据块进行合并压缩,n为大于等于2的自然数,k为小于n的自然数;
161.当压缩后的数据长度大于所述长度限制值,则对第1至第n-k-1个数据块进行合并压缩。
162.压缩单元704对第1至第n-k个数据块进行合并压缩,当压缩后的数据长度大于所述长度限制值,则对第1至第n-k-1个数据块进行合并压缩的具体实现可以参见s210、s216 相关内容描述,在此不再赘述。
163.根据本技术实施例的数据压缩装置700可对应于执行本技术实施例中描述的方法,并且数据压缩装置700的各个模块/单元的上述和其它操作和/或功能分别为了实现图2所示实施例中的各个方法的相应流程,为了简洁,在此不再赘述。
164.本技术实施例还提供了一种设备。该设备用于实现如图7所示实施例中数据处理装置 700的功能。该设备可以是笔记本电脑、台式机等终端,也可以是本地服务器或者云服务器。为了便于理解,以设备为终端进行示例说明。
165.参见图1所示的终端100的结构示意图,该终端100包括总线101、处理器102、通信接口103和存储器104。处理器102、存储器104和通信接口103之间通过总线101通信。
166.通信接口103用于与外部通信。例如,通信接口103用于获取待压缩数据,获取压缩数据的长度限制值,或者是输出至少两个长度小于上述长度限制值的压缩文件等等。存储器104中存储有可执行代码,处理器102执行该可执行代码以执行前述数据压缩方法。
167.本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质包括指令,所述指令指示计算机执行上述应用于数据压缩装置700的数据压缩方法。
168.本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质包括指令,所述指令指示计算机执行上述应用于数据压缩装置700的数据压缩方法。
169.本技术实施例还提供了一种计算机程序产品,所述计算机程序产品被计算机执行时,所述计算机执行前述数据压缩方法的任一方法。该计算机程序产品可以为一个软件安装包,在需要使用前述数据压缩方法的任一方法的情况下,可以下载该计算机程序产品并在计算机上执行该计算机程序产品。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1