面向配电网边缘计算装置的PMU数据压缩及重构方法与流程
面向配电网边缘计算装置的pmu数据压缩及重构方法
技术领域
1.本发明涉及一种pmu数据压缩与重构方法。特别是涉及一种面向配电网边缘计算装置的pmu数据压缩及重构方法。
背景技术:
2.各种先进的信息化与数字化技术在电网中的应用极大地加速了电网的数字化转型,云-边协同架构成为数字电网建设与运行中的一种新模式。其中,在配电层面,利用边缘计算技术实现海量数据的就地采集、分析、处理以及在此基础上的智能分析与决策,是充分释放数据资源价值、突破数据大规模通信传输瓶颈、提高快速多变环境下决策快速性的重要手段。但与此同时,配电网边缘计算装置的计算与存储资源有限,并需要同时承载保护、控制、监测等多类型电网业务,对单一业务占用资源的约束更加严格和关键,这对边缘计算环境下的电网业务逻辑和算法设计提出了更高要求。
3.近年来,以同步相量测量(phasor measurement unit,pmu)为代表的新型量测技术应用愈发广泛,并已开始应用于配电网。pmu利用全球定位系统给每帧数据打上精确时标,保证了配电网电压相量、电流相量等数据获取的同步性;数据采集速率可达到100帧/s,保证了数据获取的实时性。上述优势使pmu可为运行人员提供更丰富的配电网运行信息,有效提升了配电网的运行状态感知水平,为故障定位、状态估计等应用提供重要的数据支撑。因此,pmu功能被作为配电网边缘计算的核心业务功能之一。然而,由于其多类型、高频次量测特征,pmu采集到的数据量急剧增长,给其在边缘侧的就地处理和存储带来了巨大挑战。包含20种量测信息、数据上送速率为60hz的pmu,一天产生的数据量可达100gb。这极大地增加了pmu业务在配电网边缘计算环境下的部署和应用难度。
4.数据压缩是指在保留有价值信息的前提下,通过对数据的处理或重新组织缩减数据规模,以提高其传输、存储和处理效率,是解决边缘计算环境下pmu数据规模过大问题的一种重要方案。国内外已经开展了基于小波压缩算法、傅里叶压缩算法、主成分分析算法等的pmu数据有损压缩方法和基于霍夫曼编码、算术编码等的pmu数据无损压缩方法。但在压缩比、重构精度以及边缘计算环境下的使用能力仍然存在挑战。本发明考虑了边缘侧有限的计算和存储资源,并结合pmu数据特点,基于改进的过滤旋转门压缩算法和指数哥伦布编码实现了配电网边缘计算环境下各类型pmu数据的高效压缩。
技术实现要素:
5.本发明所要解决的技术问题是,为了克服现有的技术的不足,提供一种能够实现电压相量、电流相量、频率等多类型pmu数据高效压缩的面向配电网边缘计算装置的pmu数据压缩及重构方法。
6.本发明所采用的技术方案是:一种面向配电网边缘计算装置的两阶段pmu数据压缩方法,包括有损压缩阶段和无损压缩阶段,其中,有损压缩阶段包括过滤压缩阶段和旋转门压缩阶段;两阶段pmu数据压缩方法包括如下步骤:
7.1)输入两阶段pmu数据压缩方法所需的控制参数,包括:在过滤压缩阶段的最大传输间隔t
max
和最大允许误差δ
excdev
、在旋转门压缩阶段的最大允许误差δ
compdev
、pmu浮点型数据小数位数α、pmu数据上送速率f、压缩数据读入控制变量nc、压缩周期序数变量βc;
8.2)读入从边缘计算装置获取的多通道pmu数据,包括五类数据:三相节点电压有效值数据、三相节点电压相位数据、三相支路电流有效值数据、三相支路电流相位数据、频率数据,对于首个压缩周期βc=1,读入的pmu数据个数其中pmu数据上送时间间隔δt=1/f;当βc》1时,若nc=0,读入的pmu数据个数若nc=1,读入的pmu数据个数
9.3)对步骤2)获取的多通道pmu数据分别进行有损压缩,即基于过滤压缩阶段的最大允许误差δ
excdev
,执行过滤压缩判据;再基于旋转门压缩阶段最大允许误差δ
compdev
,对过滤压缩判据结果执行改进的旋转门压缩判据,得到有损压缩阶段保留的pmu数据及时标索引数据;
10.4)对步骤3)得到的pmu数据及时标索引数据,进行数据预处理,包括对pmu数据及时标索引数据进行差分编码,对pmu数据差分编码得到的差分序列进行归一化处理两个步骤;
11.5)对步骤4)得到的结果,进行基于0阶指数哥伦布编码的无损压缩,得到最终保留的数据;跳转到步骤2),执行下一个压缩周期。
12.本发明的面向配电网边缘计算装置的pmu数据压缩及重构方法,将改进的过滤旋转门压缩方法和0阶指数哥伦布编码方法进行结合,与单独使用过滤旋转门压缩方法相比,在保证相同重构数据精度的同时,进一步提高了压缩比,实现了电压相量、电流相量、频率等多类型pmu数据的高效压缩,且计算资源和内存资源占用较小,满足边缘计算环境下的数据压缩应用需求。
附图说明
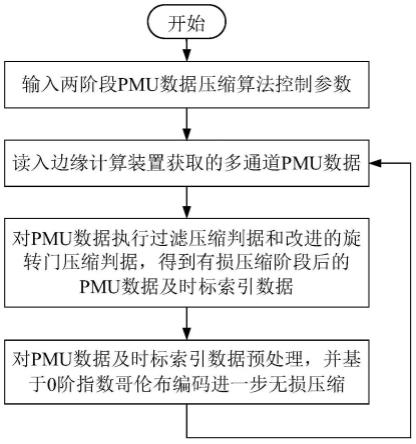
13.图1是本发明面向配电网边缘计算装置的两阶段pmu数据压缩方法的流程图;
14.图2是本发明中过滤压缩算法示意图;
15.图3是改进的旋转门压缩算法流程图;
16.图4是改进的旋转门压缩算法示意图;
17.图5是a相电压有效值重构数据曲线图;
18.图6是a相电压有效值数据重构误差曲线图。
具体实施方式
19.下面结合实施例和附图对本发明的面向配电网边缘计算装置的pmu数据压缩及重构方法做出详细说明。
20.如图1所示,本发明的面向配电网边缘计算装置的两阶段pmu数据压缩方法,包括有损压缩阶段和无损压缩阶段,其中,有损压缩阶段包括过滤压缩阶段和旋转门压缩阶段;两阶段pmu数据压缩方法包括如下步骤:
21.1)输入两阶段pmu数据压缩方法所需的控制参数,包括:在过滤压缩阶段的最大传输间隔t
max
和最大允许误差δ
excdev
、在旋转门压缩阶段的最大允许误差δ
compdev
、pmu浮点型数据小数位数α、pmu数据上送速率f、压缩数据读入控制变量nc、压缩周期序数变量βc;
22.2)读入从边缘计算装置获取的多通道pmu数据,包括五类数据:三相节点电压有效值数据、三相节点电压相位数据、三相支路电流有效值数据、三相支路电流相位数据、频率数据,对于首个压缩周期βc=1,读入的pmu数据个数其中pmu数据上送时间间隔δt=1/f;当βc》1时,若nc=0,读入的pmu数据个数若nc=1,读入的pmu数据个数
23.3)对步骤2)获取的多通道pmu数据分别进行有损压缩,即基于过滤压缩阶段的最大允许误差δ
excdev
,执行过滤压缩判据;再基于旋转门压缩阶段最大允许误差δ
compdev
,对过滤压缩判据结果执行改进的旋转门压缩判据,得到有损压缩阶段保留的pmu数据及时标索引数据;
24.所述的过滤压缩判据,是对步骤2)得到的每一类数据,按照时标顺序定义:将过滤压缩阶段前最后一个被保存的数据点设为ξ
save
、将过滤压缩阶段被保存的数据点集合设为ξ
temp
、将过滤压缩阶段当前新数据点设为ξ
curr
、将当前新数据点的前一个数据点设为ξ
prev
,则当前新数据点ξ
curr
是否被压缩的判断依据如下:
25.δt《t
max
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0026][0027]
式中,δt为ξ
curr
与ξ
save
的时间差,s为ξ
temp
集合中元素个数,即:ξ
temp
(s-1)为ξ
temp
集合中最后一个元素;若连续2个数据点均满足式(1)和式(2),则前一个数据点被舍弃,后一个数据点与相连的下一个数据点再进行判断;否则将这2个连续的数据点归入被保存的数据点集合ξ
temp
中,在压缩过程中第一个数据点不参与压缩,这一机制决定了过滤压缩阶段的最大误差不超过2δ
excdev
;如图2所示,以点a为起点建立过滤压缩框,从点b开始进行过滤压缩判断;对点b,由于点b、c均在当前过滤压缩框内,故点b被舍弃;对点c,由于点d不在当前过滤压缩框内,故点c、d均被保留;下一步,以点d为起点建立新的过滤压缩框,重复上述判断过程,直至该压缩周期所有数据点均执行完过滤压缩判据,此时点f为ξ
curr
,点e为ξ
prev
;
[0028]
对过滤压缩判据得到的ξ
temp
数据集合执行改进的旋转门压缩判据,计算公式如下:
[0029][0030][0031]kup
≤k
down
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0032]
i≤s+1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0033]
式中,ξ
sdt
集合为s+2维向量,是由ξ
save
、ξ
temp
、ξ
prev
按照时标顺序组合得到;i、j为ξ
sdt
集合的索引变量,ξ
sdt
(j)为ξ
sdt
集合中第j+1个元素;与是与ξ
sdt
(j)具有
相同时标、距离为δ
compdev
的上下两个支点;ξ
sdt
(i)为ξ
sdt
集合中第i+1个元素,k
up
为ξ
sdt
(i)与上支点构成的斜率的最大值,k
down
为ξ
sdt
(i)与下支点构成的斜率的最小值;进行如下判断:
[0034]
(1)对j=0且i∈{j+1,
…
,s+1}的ξ
sdt
集合中的数据点依次执行旋转门压缩判据,若式(3)至式(6)均成立,则ξ
temp
集合中的数据点全部被舍弃,有损压缩阶段结束,并保存ξ
prev
,作为下一个过滤压缩阶段前最后一个被保存的数据点ξ
save
,置nc=0,并传递ξ
save
、ξ
curr
及时标和k
up
、k
down
到下一个压缩周期;
[0035]
(2)设t、q为ξ
sdt
集合的索引变量,对j=t,t∈{0,
…
,s}且i∈{j+1,
…
,s+1}的ξ
sdt
集合数据点依次执行旋转门压缩判据,若执行到i∈q,q∈{j+1,
…
,s+1}中的一点,式(5)不成立,式(6)成立,则保留ξ
sdt
(q-1),并令j=q-1,对i∈{j+1,
…
,s+1}中的所有点继续执行第(2)步,若式(6)不成立,跳转到第(3)步;
[0036]
(3)有损压缩阶段结束,置nc=1,传递ξ
save
、ξ
prev
、ξ
curr
及对应的时标和k
up
、k
down
到下一个压缩周期。
[0037]
第(1)步至第(3)步可总结为图3所示的计算流程。进一步地,如图4所示,已知点b在过滤压缩中被舍弃,点a为ξ
save
,点c、d为过滤压缩阶段保留的ξ
temp
集合中的元素,点e为ξ
prev
,点f为ξ
curr
;点a至f组成ξ
sdt
集合。初始时,点a作为旋转门压缩起始点;点c完全满足改进的旋转门压缩判据,点d仅不满足式(5),故点c被保存并作为新的旋转门起始点;点d、e完全满足改进的旋转门压缩判据,点f不满足式(6),故点d被舍弃,点e、f的取舍由下一个压缩周期决定。
[0038]
4)对步骤3)得到的pmu数据及时标索引数据,进行数据预处理,包括对pmu数据及时标索引数据进行差分编码,对pmu数据差分编码得到的差分序列进行归一化处理两个步骤;
[0039]
所述的差分编码和归一化处理方法如下:
[0040]
所述的差分编码是对步骤3)得到的pmu数据和时标索引数据分别进行差分编码,具体是对pmu数据中第一个数据点保持真值不变,从第二个数据点开始,依次将当前数据点与前一个数据点作差,得到差分序列δξc;相邻两个数据点的差分值计算公式如下:
[0041]
δξc(l)=ξc(l)-ξc(l-1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0042]
式中,l∈n为索引变量,δξc(l)为差分序列δξc第l+1个数据点,ξc(l)为步骤3)得到的pmu数据和时标索引数据第l+1个数据点,ξc(l-1)为步骤3)得到的pmu数据和时标索引数据第l个数据点;
[0043]
所述的归一化处理,是对得到的pmu数据差分序列进行归一化处理,归一化处理公式如下:
[0044]
δξ
int
(m)=δξc(m)
×
10
α
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0045][0046]
式中,m为索引变量,δξ
int
为pmu数据整数序列,δξ
int
(m)为δξ
int
的第m+1个元素,ξ
nd
为pmu数据非负整数序列,ξ
nd
(m)为ξ
nd
的第i+1个元素。
[0047]
5)对步骤4)得到的结果,进行基于0阶指数哥伦布编码的无损压缩,得到最终保留的数据;跳转到步骤2),执行下一个压缩周期;所述的0阶指数哥伦布编码的具体步骤如下:
[0048]
(5.1)设pmu数据非负整数序列和时标索引数据差分序列中元素为ξ
eg
,分别计算ξ
eg
的分组编号g和组内偏移量offset;
[0049][0050]
offset=ξ
eg
+1-2gꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0051]
式中,代表对*向下取整;
[0052]
(5.2)向二进制位数据流中依次写入g个0;
[0053]
(5.3)向二进制位数据流中写入1个1;
[0054]
(5.4)向二进制位数据流中写入offset的低g位;
[0055]
通过连续地对ξ
eg
执行(5.1)至(5.4)的无损编码过程,实现两阶段pmu数据压缩。
[0056]
本发明的用于面向配电网边缘计算装置的两阶段pmu数据压缩方法的pmu数据重构方法,包括0阶指数哥伦布解码和线性插值两个阶段;具体包括如下步骤:
[0057]
1)输入pmu压缩数据的重构方法所需的控制参数,包括:pmu浮点型数据小数位数α、pmu数据上送速率f、重构周期序数变量βr;
[0058]
2)读入pmu压缩数据和时标索引数据,共十类,包括压缩的pmu数据中三相节点电压有效值数据和对应的时标索引数据、三相节点电压相位数据和对应的时标索引数据、三相支路电流有效值数据和对应的时标索引数据、三相支路电流相位数据和对应的时标索引数据、频率数据和对应的时标索引数据;对于每个重构周期,读入的压缩数据字节数n
tr
=1024;若执行到一个压缩周期,待重构的数据字节数不足1024,按照实际剩余字节数读取;
[0059]
3)对步骤2)获取的每一类数据,分别进行第一阶段的0阶指数哥伦布解码,得到非负整数序列;所述的0阶指数哥伦布解码步骤如下:
[0060]
(3.1)设pmu压缩数据和时标索引数据二进制位数据流为ξ
byte
,ξ
byte
经过0阶指数哥伦布解码得到非负整数序列,ξ
eg
为非负整数序列中的元素,对于每一类数据,按位读取ξ
byte
,当读取到位1结束,计算读取到的位0的个数,即ξ
eg
在0阶指数哥伦布编码阶段所在的组号g;
[0061]
(3.2)继续读取g位二进制数据,并转换为十进制数据,即为ξ
eg
组内偏移量offset;
[0062]
(3.3)基于式(11)计算得出ξ
eg
;
[0063]
通过连续地对ξ
byte
执行步骤(3.1)至(3.4),对pmu压缩数据和时标索引数据实现0阶指数哥伦布解码,得到pmu压缩数据非负整数序列和时标索引数据非负整数序列。
[0064]
4)对步骤3)得到的每一类pmu压缩数据非负整数序列和时标索引数据非负整数序列,分别进行数据预处理,包括对pmu压缩数据非负整数序列进行归一化处理的逆变换和差分编码的逆变换,对时标索引数据非负整数序列进行差分编码的逆变换;所述的归一化处理的逆变换和差分编码的逆变换的方法如下:
[0065]
所述的归一化处理的逆变换,是对步骤3)得到的pmu数据非负整数序列ξ
nd
进行归一化处理的逆变换,公式如下:
[0066][0067]
δξ
p
(u)=δξ
int
(u)
×
10-α
ꢀꢀꢀꢀꢀꢀ
(13)
[0068]
式中,u为索引变量,ξ
nd
(u)为pmu数据非负整数序列ξ
nd
中第u+1个元素,δξ
int
为
pmu压缩数据整数序列,δξ
int
(u)为δξ
int
的第u+1个元素,δξ
p
为pmu压缩数据差分序列,δξ
p
(u)为δξ
p
的第u+1个元素;
[0069]
由于压缩时标索引数据时未做归一化处理,故时标索引数据非负整数序列也是时标索引数据差分序列,设pmu压缩数据差分序列和时标索引数据差分序列为δξr,所述的差分编码的逆变换,是对δξr从第二个数据点开始进行差分编码的逆变换,公式如下:
[0070]
ξr(v)=δξr(v)+ξr(v-1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0071]
式中,v为索引变量,δξr(v)为δξr序列中第v+1个元素,ξr(v-1)为有损压缩后的pmu数据序列或时标索引数据序列的第v个元素,ξr(v)为有损压缩后的pmu数据序列或时标索引数据序列的第v+1个元素。
[0072]
5)对步骤4)得到的结果进行线性插值,得到最终重构的数据;跳转到步骤2),执行下一个重构周期;所述的线性插值,具体步骤如下:
[0073]
设pmu数据的上送时间间隔δt=1/f;参与线性插值的运算数据为步骤4)得到的有损压缩后的pmu数据序列的相邻两个数据以及这两个数据在有损压缩后的时标索引数据序列中的时标,分别记为ξ
head
、ξ
end
和t
head
、t
end
;当t
end
与t
head
的差为δt时,说明两个数据是相邻的,无需进行线性插值;设p为指示变量,当t
end
与t
head
的差为pδt时,说明两个数据间存在p-1个数据被舍弃,要通过线性插值的方法进行重构;
[0074]
设w为索引变量,待重构的数据点为ξ
recon
(w),对应的时标为(t
head
+wδt),w∈{1,
···
,p-1},ξ
recon
(w)的计算公式为:
[0075][0076]
通过连续地对有损压缩后的pmu数据序列中的相邻数据间的缺失数据进行重构,得到重构后的pmu数据序列。
[0077]
下面给出具体实例:
[0078]
为了验证本发明提出的面向配电网边缘计算装置的pmu数据压缩及重构方法的有效性和可行性,采用实际的配电网pmu量测数据对压缩算法性能进行测试。
[0079]
现场pmu的上送速率为50hz,即pmu数据上送时间间隔δt=0.02s,电压等级为10kv。本发明实例选取需要在边缘侧存储的pmu量测数据类型包括三相节点电压有效值数据、三相节点电压相位数据、三相支路电流有效值数据、三相支路电流相位数据、频率数据。选取连续1小时的数据进行压缩算法性能测试,每种量测类型数据包括180000个数据点。假定每个量测类型的pmu数据分别存储在一个文件中,编码方式为utf-8,每个文件内仅包含1小时该类型的量测数据,该量测类型数据的id标识符及初始数据点对应的时刻标识在文件名中,其余数据点对应的时刻可根据δt计算得到。
[0080]
指数哥伦布编码得到的压缩数据文件为两个二进制文件,分别存储被压缩算法保留的pmu数据及时标索引数据。算例中的重构数据文件,格式与原始数据文件相同,编码方式为utf-8。重构数据精度的计算方式为原始pmu数据与重构pmu数据的对应数据间的绝对和相对误差。
[0081]
对于压缩算法控制参数t
max
、δ
excdev
和δ
compdev
的设定,考虑配电网的实际运行特征和pmu电压、电流、频率量测数据的特点,兼顾存储空间和数据时效性,设定t
max
=1s,即每轮参与过滤旋转门的压缩数据为50个;每种数据类型的单点最大误差要求δ决定了控制参数
δ
excdev
、δ
compdev
的最大取值。依据经验设定δ
excdev
与δ
compdev
的比值为1:2。表1为压缩算法控制参数的具体取值。
[0082]
本发明实例采用压缩比(compression ratio,cr)和重构数据精度来反映数据压缩算法性能。其中,压缩比为原始pmu数据文件大小与压缩文件总大小的比值:
[0083][0084]
式中,f
orig
为原始pmu数据文件的大小,f
comp
为压缩文件的总大小,即压缩pmu数据文件和时标索引数据文件的大小之和。
[0085]
重构数据精度采用最大绝对误差(maximum absolute error,mae)、平均绝对误差百分比(mean absolute error percentage,maep)和平均相对误差百分比(mean relative error percentage,mrep)3个指标。其中,最大绝对误差用来衡量压缩算法对单个数据点精度造成的影响;平均绝对误差百分比用来衡量压缩算法对相位和频率数据整体精度造成的影响;平均相对误差百分比用来衡量压缩算法对电压和电流有效值数据整体精度造成的影响。具体的计算公式如下:
[0086]
最大绝对误差mae:
[0087][0088]
平均绝对误差百分比maep:
[0089][0090]
平均相对误差百分比mrep:
[0091][0092]
式中,ξn为原始pmu数据,为重构pmu数据,n为原始pmu数据个数。
[0093]
基于实际pmu数据进行压缩算法性能测试,结果如表2所示。其中,γ
cr0
为对原始pmu数据执行改进过滤旋转门压缩判据后,原始pmu数据文件与压缩文件总大小的比值,即有损压缩阶段的压缩比;γ
cr
为进一步完成0阶指数哥伦布编码后,原始pmu数据文件与压缩文件总大小的比值,即整个压缩算法总压缩比;电压或电流相量数据的脚标a、b、c分别代表各相。
[0094]
从表2可以得出,所有类型数据的最大绝对误差均不超过设定的最大单点误差,验证了改进的过滤旋转门压缩算法误差是受控的;所有数据的总压缩比均超过8,三相节点电压相量或三相支路电流相量的压缩效果接近,表明了该算法能较好地适应各类型pmu数据的压缩。
[0095]
其中,对于相电压有效值数据,总压缩比超过30,单点最大误差不超过2.1v,平均相对误差控制在0.01%以内;对于电压相位数据,总压缩比超过30,单点最大误差不超过0.1
°
,平均绝对误差控制在0.025
°
以内;对于频率数据,总压缩比超过30,单点最大误差0.002hz,平均相对误差为0.0006hz。可以得出,对于波动较小的原始数据,如电压相量、频率数据,有损压缩阶段压缩比较高,数据在经过差分预处理后,数据绝对值较小,符合指数哥伦布无损压缩编码特性,因此无损压缩阶段在保证相同重构数据精度的同时,进一步提高了数据压缩比。
[0096]
此外,对于支路电流有效值数据,总压缩比超过8,单点最大误差不超过3.1a,平均相对误差控制在0.1%以内;对于电流相位数据,总压缩比超过14,单点最大误差不超过0.1
°
,平均绝对误差控制在0.025
°
以内。这是由于电流相量数据与负荷密切相关,不确定性较强,波动较大,在有损压缩阶段为了保证数据重构精度,压缩比较低,导致无损压缩后压缩比提升程度相对于电压相量、频率数据较小,总压缩比相对较低。
[0097]
为了直观地反映重构数据精度,以相电压有效值数据为例,绘制出1小时原始a相电压有效值数据、重构数据及误差曲线,如图5和图6所示。其中,原始数据在6050v左右上下波动,重构数据能够很好地跟随原始数据;误差曲线也表明原始数据与重构数据间误差是受控的。
[0098]
综上,本发明提出的面向配电网边缘计算装置的pmu数据压缩及重构方法能够实现电压相量、电流相量、频率等多类型pmu数据的高效压缩,满足边缘计算环境下的数据压缩应用需求。
[0099]
表1压缩算法参数设置
[0100][0101]
注:脚标φ代表相数据,角标rms代表有效值,p代表相位。相电压基准值u0=5.774kv,支路电流基准值i0=1000a。
[0102]
表2 pmu数据压缩结果
[0103][0104]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1