基于布尔矩阵分解的图数据压缩方法
indexes with recursive graph bisection[c]//proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining.2016:1535-1544”扩展了chierichetti等人提出的mloggapa,提出了基于递归二分法的bp节点排序算法,对图和倒排索引的压缩提出了统一的压缩模型。
[0008]
文献“besta m,stanojevic d,zivic t,et al.log(graph)a near-optimal high-performance graph representation[c]//proceedings of the 27th international conference on parallel architectures and compilation techniques.2018:1-13”提出的图压缩算法编码方式相对简单,整体的运行效率较高,将图进行对数化编码,从而加速图算法的运行,将间隙码的固定大小特性融入进来,从而提高压缩率。
[0009]
可以看出,现有的图数据压缩方法都是在编码方向努力,希望借助编码将图数据中的冗余信息剔除,从而达到压缩的目的,它们都没有考虑到图的组成以及图数据的基本结构。
[0010]
基于网络稀疏表征的图数据压缩能够对同质图进行压缩。其将图结构数据进行分解,得到图结构的基本结构原子以及原子如何构建原始图结构数据的组合方式,对图结构数据实现表征以及存储压缩。在网络稀疏表征中,使用到了自我中心网络这样的概念,当不再关注图结构数据的整体,而是侧重于研究单个节点的性质时,就会用到自我中心网络,网络节点由唯一的一个中心节点,以及这个节点的邻居组成,边只包括中心节点与邻居之间,以及邻居与邻居之间的边。自我中心网络能够表示一个节点的结构信息,从而同时,网络稀疏表征技术使用k-svd来进行矩阵分解,将采样矩阵进行浮点数矩阵分解,从而生成字典矩阵与稀疏码矩阵。
[0011]
网络稀疏表征的主要问题在于k-svd这种浮点数矩阵分解。输入的采样矩阵是布尔矩阵,而输出的字典矩阵和稀疏码矩阵都是正负未定的浮点数。首先,对于浮点数,很难去判断其物理意义,例如对于字典矩阵中的0.5,判断其是否有连边都不合适;其次,对于矩阵中出现的负数,例如-1.5,其本不应该存在,只是为了拟合矩阵的误差而被迫出现,实际上我们并不希望见到它。网络稀疏表征会通过字典矩阵来生成原子,负数以及浮点数都无法正确的判断其在真实图结构数据中是否存在。由于上述问题,导致网络稀疏表征并不能准确的进行表征。
技术实现要素:
[0012]
为解决现有技术存在的上述问题,本发明提出了一种基于布尔矩阵分解的图数据压缩方法。
[0013]
本发明的具体技术方案为:一种基于布尔矩阵分解的图数据压缩方法,包括如下步骤:
[0014]
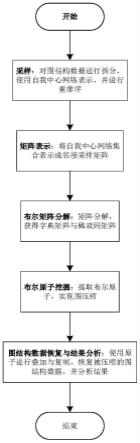
步骤s1.对原始图结构数据进行采样,具体的,对原始图结构数据进行拆分,使用自我中心网络表示,并进行重排序;
[0015]
步骤s2.矩阵表示,使用邻接矩阵对排序后的自我中心网络集合进行表示,生成采样矩阵;
[0016]
步骤s3.布尔矩阵分解,将采样矩阵分解成字典矩阵与稀疏码矩阵的乘积;
[0017]
步骤s4.布尔原子挖掘,对布尔矩阵分解得到的字典矩阵进行处理,将矩阵拆分成多个列向量,对每个列向量,将其还原成邻接矩阵,将所述邻接矩阵分别恢复成图结构数据,同时去除其中同构图,最终得到的就是原子;
[0018]
步骤s5.在稀疏码矩阵的指导下,对原子进行线性组合,即可得到采样恢复矩阵,然后根据采样阶段获得的采样节点集合,将各个节点之间的连边关系按照采样恢复矩阵进行恢复,即可得到恢复的图结构数据。
[0019]
本发明的有益效果:本发明的方法通过使用布尔矩阵分解的方式,对矩阵分解得到的字典矩阵与稀疏码矩阵进行约束,使得字典矩阵和稀疏码矩阵都是布尔型矩阵,可以降低图结构数据表征的误差率,同时提高表征得到的原子的准确率,实现对图数据的压缩。
附图说明
[0020]
图1为本发明实施例的基于布尔矩阵分解的图数据压缩方法的流程示意图。
具体实施方式
[0021]
下面结合附图对本发明的实施例做进一步的说明。
[0022]
针对网络稀疏表征技术存在的问题,本发明提出布尔矩阵的矩阵分解方法,在此基础上,进行图数据压缩,从而给生成的字典矩阵与稀疏码矩阵加上布尔的约束,从而解决上述问题;同时通过降低布尔矩阵分解本身存在的大误差,使得本发明的最终表征效果优于基于网络稀疏表征的图数据压缩方法。具体流程如图1所示,包括如下步骤:
[0023]
步骤s1.对原始图结构数据进行采样,具体的,对原始图结构数据进行拆分,使用自我中心网络表示,并进行重排序;
[0024]
步骤s2.矩阵表示,使用邻接矩阵对排序后的自我中心网络集合进行表示,生成采样矩阵;
[0025]
步骤s3.布尔矩阵分解,将采样矩阵分解成字典矩阵与稀疏码矩阵的乘积;
[0026]
步骤s4.布尔原子挖掘,对布尔矩阵分解得到的字典矩阵进行处理,将矩阵拆分成多个列向量,对每个列向量,将其还原成邻接矩阵,将所述邻接矩阵分别恢复成图结构数据,同时去除其中同构图,最终得到的就是原子;
[0027]
步骤s5.在稀疏码矩阵的指导下,对原子进行线性组合,即可得到采样恢复矩阵,然后根据采样阶段获得的采样节点集合,将各个节点之间的连边关系按照采样恢复矩阵进行恢复,最终即可得到恢复的图结构数据。
[0028]
在步骤s1中,首先对原始图结构数据进行采样。本阶段主要目的是将原始图结构数据分解成自我中心网络集合。由于原始图结构数据规模太大,无法进行处理,从而将图结构数据拆分成多个自我中心网络,分别进行处理。具体分步骤如下:
[0029]
步骤s11.设定采样得到的自我中心网络节点规模大小s;
[0030]
步骤s12.访问某个节点i,创建当前节点i的自我中心网络gi;
[0031]
步骤s13.将节点i加入自我中心网络gi的节点集合,同时将节点i的一阶邻居加入集合;若当前图结构节点数未超过s,则继续添加节点i的二阶邻居;若此时节点数未超过s,则补充虚拟节点到集合;若超过,则剔除多余节点;
[0032]
步骤s14.对节点集合中的节点进行排序,排序规则为:一阶邻居、二阶邻居均按照
自我中心网络gi中的度从大到小排序;
[0033]
步骤s15.将节点集合中所有存在的连边加入自我中心网络gi;
[0034]
步骤s16.遍历图结构数据中的每个节点,重复步骤s12-s15,得到若干自我中心网络。
[0035]
通过步骤s1将原始图结构数据分解成n个小的自我中心网络的集合,从而实现了将图结构数据拆分的目的。
[0036]
步骤s2的目的为将步骤s1得到的自我中心网络集合进行矩阵表示,从而为下一步布尔矩阵分解提供输入。
[0037]
对于一个图结构数据,有多种表示的形式。链表是一种较好的表示及存储范式,以链表的方式来存储多条路径,可以将图结构数据的规模压缩的很低;邻接矩阵也是一种表示方式,它以图结构数据中n个节点来构建n*n的矩阵a,其中,a
ij
代表节点i与节点j具有连边,从而表示整个图结构数据的节点以及连边情况。
[0038]
步骤s2采用邻接矩阵来表示自我中心网络,因为矩阵表示方式更适合数学运算,虽然它的存储效率比较低。具体分步骤如下:
[0039]
步骤s21.构建s*s的矩阵,将自我中心网络的连边情况填入,从而得到多个邻接矩阵。由于步骤s1得到的所有自我中心网络的节点编号范围都是[0,s-1],所以本步骤不需要担心节点序号问题。
[0040]
步骤s22.针对每个邻接矩阵,进行向量化操作,即将邻接矩阵的所有列向量按序首尾拼接,从而将一个s*s的矩阵转换为一个s2*1的列向量。
[0041]
步骤s23.将步骤s22得到的列向量全部按列拼接,从而得到一个全新的矩阵,该矩阵的维度为s2*n,最终得到一个采样矩阵y。
[0042]
对于步骤s2得到的采样矩阵y,步骤s3是将其进行分解,分解成字典矩阵与稀疏码矩阵的乘积,字典矩阵的维度为s2*k,稀疏码矩阵的维度为k*n;其中,k为矩阵分解的轮次,它随着分解误差的收敛不同而不同。
[0043]
布尔矩阵分解是在矩阵分解的过程中施加约束,使得分解得到的字典矩阵和稀疏码矩阵都为布尔型,即矩阵中的元素非0即1。具体分步骤如下:
[0044]
s31.设置终止阈值c,扩展阈值t;
[0045]
s32.将初始采样矩阵拷贝,得到残差矩阵,初始化字典矩阵与稀疏码矩阵;
[0046]
s33.对矩阵中的所有列分别求和,在此基础上对列排序;
[0047]
s34.在排序之后的列集合中选出中位数列,作为基列集合;
[0048]
s35.从基列集合中挨个选取基列,以基列与其它列进行比较,若其它列包含基列中的1的比例达到50%以下,则说明不包含;若其它列包含基列中的1的比例达到50%及以上,则继续将该列在初始矩阵中的对应列与基列进行包含关系的判断,如果比例在扩展阈值t及以上,则说明真实包含,该基列的包含个数加1;
[0049]
s36.统计所有基列的包含个数,选择最大的那个,将该基列选出,加入到字典矩阵中作为新的一列,将每一列是否包含基列用0与1表示,得到一个行向量,将其加入到稀疏码矩阵中作为新的一行;
[0050]
s37.对于残差矩阵中所有包含基列的列,都与基列做减法运算,若出现负数,也置为0;
[0051]
s38.重复上述步骤s33-s37,直到误差无法下降或者误差低于终止阈值c。
[0052]
本步骤主要在于进行矩阵分解,分解的核心思想就是经过多轮迭代,每次都贪心找到最大的矩形,因为矩形就代表着该结构在图结构数据中大量存在。同时,一般而言,中位数列在整个矩阵中能够扩展的矩形会较大,采用这种方式能够更快的找到矩形。
[0053]
由于布尔矩阵分解本身是np难问题,即使使用中位数列作为候选基列能够极大的加快矩阵分解速度,但由于图结构数据规模大,整体的分解效率不高。因此本实施例对图数据采样矩阵的布尔矩阵分解进行优化,对矩阵的列向量进行编码,使用散列集合对向量编码去重,从而在提取中位数列时将重复的基列候选去除,同时在每个基列进行扩展时,忽略冗余的对比列,从而大幅降低矩阵分解的时间开销。结合网络稀疏表征的特点,大规模图数据拆分后得到的自我中心子网相对趋于同构,因此它们的向量也较为相似,
[0054]
步骤s4布尔原子挖掘对布尔矩阵分解得到的字典矩阵进行处理,将矩阵拆分成多个列向量,分别进行处理。由于字典矩阵的维度是s2*k,那么可以拆分成k个列向量。
[0055]
对每个列向量,将其还原成s*s的邻接矩阵,该过程为矩阵表示的逆过程。如此,便可以得到k个邻接矩阵,将它们分别恢复成图结构数据,同时去除其中同构图,最终得到的就是原子。
[0056]
原子是图结构数据表征的结果之一,它们是图结构数据中高频出现的局部结构,是图结构数据的骨架,可以认为,它们就可以代表整个图结构数据的结构特征。
[0057]
对于一个大规模图结构数据,众多的节点与连边使得图结构数据存储的成本增加,而原子是图结构数据的基本机构模式,它可以通过自我复制与线性叠加来构成原始图结构数据,因此,对于图结构数据的存储,经由基于布尔矩阵分解的图压缩方法之后,只需要存储布尔原子及其稀疏编码,这大大了节省了存储空间,实现了图压缩。
[0058]
将原子按照稀疏码矩阵的指导进行线性组合,即可得到采样恢复矩阵,然后根据采样阶段获得的采样节点集合,将各个节点之间的连边关系按照采样恢复矩阵进行恢复,最终即可得到恢复的图结构数据。
[0059]
最终图压缩的误差可以使用恢复的图结构数据与原始图结构数据进行对比,以原始图结构数据的边数为分母,以两个图结构数据共有边数目为分母,即可对表征的准确率进行评价。除此之外,布尔原子的准确性也是需要考虑的一个指标,这也是本发明的方法与网络稀疏表征方法的一个重要不同,根据稀疏编码的指导,找到每个布尔原子在原始图结构数据中对应的点集映射,之后判断两个点集的边集是否一致,即可判断该原子在原始图结构数据中是否真实存在,统计所有原子的存在与否,再与原子总数相除,即可得到原子准确性。
[0060]
稀疏码代表了原子在原始图结构数据中的线性组合的方式,其中,c
ij
就代表了第i个原子在第j个自我中心网络中被使用到,因此统计稀疏码中每一行的行和边可以得知该行对应原子在原始图结构数据中的使用次数。根据此方式,统计所有原子的使用次数,按照次数进行排序,便可以得到高频原子,它们便是整个图结构数据特征中的主要特征,它们更具有代表意义。
[0061]
本发明提出的基于布尔矩阵分解的图压缩方法,解决了基于网络稀疏表征的图压缩方法中浮点数矩阵分解产生的浮点数与负数结果带来的问题,本发明的表征误差更小,图结构数据表征结果更加准确,提取出的原子结构真实存在于原图结构数据中,能更清楚
的挖掘图结构数据中的基本结构模式,便于进行图结构数据结构分析。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1