一种LDPC码的基于排序TEPs的OSD译码方法
本发明属于通信,具体涉及一种ldpc码的基于排序测试错误模式(testerror patterns,teps)的osd译码方法,可用于ldpc码信道编码的通信系统场景。
背景技术:
1、随着通信技术的不断发展,为保证通信系统的可靠性,性能优越的信道编码技术是降低传输误码率的关键技术之一。低密度奇偶校验(low-density parity-check,ldpc)码作为一种在纠错性能与时延上均有一定优势的信道编码,已被广泛应用于各大通信系统中。尽管以置信传播(belief propagation,bp)算法为代表的迭代译码算法在对ldpc长码进行译码时表现优异,但当ldpc码长较短时,bp类译码算法易出现错误平层。针对该问题,1995年由fossorier等人提出分阶统计译码(ordered statistic decoding,osd),随着阶数的增加,osd可达到最大似然译码的性能。但由于osd译码时涉及高斯消元、排序、重编码等,导致算法复杂度较高,限制其大规模实现。尤其随着阶数的增加,osd的复杂度将越来越高,因此一般应用较多的为低阶osd。然而低阶osd译码的误码性能距离实现最大似然译码仍有一定的差距。
技术实现思路
1、在对ldpc码进行译码时,针对低阶osd译码仍有误码性能提升空间的问题,本发明提出一种ldpc码的基于排序teps的osd译码方法,目的在于提升低阶osd译码的误码性能。对于ldpc码,在提出的基于排序teps的osd译码方法中,相比原始osd译码方法,主要有两处不同:(1)提出对teps进行排序的准则,令出现可能性大的tep优先参与osd译码中的重编码等环节。从teps似然度角度分析,提出teps的索引和重量计算方法。在对所有的teps进行排序时,首先计算其汉明重量,令汉明重量小的teps优先参与重编码;若teps的汉明重量相同,则计算其索引和重量,令索引和重量大的teps优先参与重编码。(2)引入crc校验。在接收端利用osd方法进行译码时,对于根据某个tep对应得到的候选码字估计,首先提取出带有crc校验位的信息估计,进行crc校验,并设置一个长度为len的列表(list),仅存储通过crc校验的码字估计,最后,分别计算列表内的len个码字估计与接收序列的欧氏距离,并选取欧氏距离最小的码字估计作为最终译码输出。
2、某个tepe的加权汉明重量主要通过对重编码码字与硬判决接收序列不同的位置上所对应的符号可靠度值进行加和计算得到,如下式所示:
3、
4、显然最大似然译码相当于是在寻找使得加权汉明重量最小的tep。
5、根据osd译码方法中只采用k位的tep,可将加权汉明重量按照式(2)分为两部分,一部分表示tep似然度(这是由于osd中生成矩阵为系统形式,即前k位码字估计即为信息比特估计,而osd中信息比特估计又是在硬判决序列的基础上加上tep得来的),记为另一部分表示冗余比特的加权汉明重量,记为其具体计算分别如式(3)与(4)所示。
6、
7、
8、
9、当确定采用某一tep后,其似然度可以直接计算得出,然而冗余比特的加权汉明重量则必须通过重编码才能得到。这里根据公式(5),利用来实现对的估计。
10、
11、利用该估计,式(2)转变为式(6)。由于系数β>0,且只要接收序列确定,β为一常数,所以有因此,最大似然算法以寻找使得加权汉明重量最小的tep,转变为寻找使似然度最小的tep。
12、
13、由式(3)可得,tep的似然度由取值为1的位置所对应的可靠度值相加得到。为简化实值运算,利用osd在寻找mrb过程中已经按照接收序列的可靠度值进行降序排列,即已知各可靠度值在所有接收符号可靠度值中的排序,用该序号(索引)代替可靠度值运算。如,完成mrb寻找后,所得到的可靠度降序序列为满足取前k个构成对应的索引序列为[1,2,…,k]。定义索引和重量如式(7)所示,表示tep中取值为1索引的加和。由于值越小,其索引i越大,因此当式(3)被简化为(7)时,寻找似然度最小tep的目标,转换为寻找索引和重量最大的tep。因此,在进行重编码时,优先选择索引和重量较大的tep与对应mrb的硬判决接收序列进行模二加得到信息序列估计,并进行重编码等后续译码步骤。
14、
15、由于仅仅当tep取汉明重量(tep中取值为1数量)相同时,才存在似然度越小,索引和重量越大的关系,因此,在基于排序teps的osd译码方法中,对teps进行排序的原则主要分为两步:(1)若两个teps的汉明重量不同,则优先选取汉明重量较小的tep参与重编码;(2)若两个teps的汉明重量相同,则优先选取索引和重量较大的tep参与重编码。
16、本发明的技术方案如下:
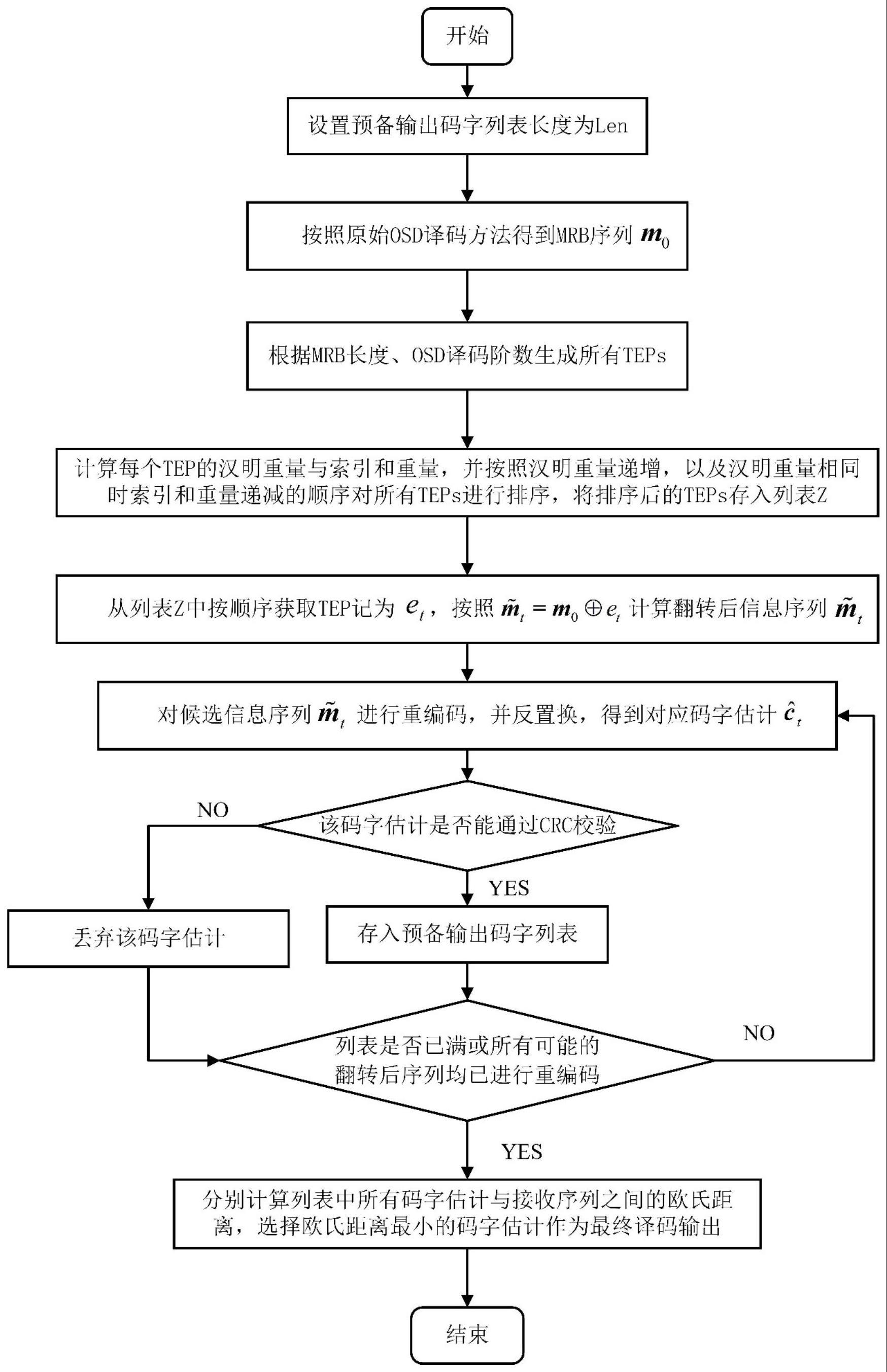
17、设长为k的信息序列m=[m0,m1,...,mk-1]进行经过crc编码,引入r位crc校验位,得到序列mcrc=[m′0,m′1,...,m′k+r-1],对带有crc校验位的信息序列进行码长为n的ldpc编码,得到ldpc码字c=[c0,c1,...,cn-1]。码字c经bpsk调制后获得序列x=[x0,x1,...,xn-1]。序列x经均值为0,方差为σ2的awgn信道传输,接收端接收序列为y=[y0,y1,...,yn-1]。对接收序列y=[y0,y1,...,yn-1]进行硬判决,得到硬判决序列定义为h=[h0,h1,...,hn-1]。假设已按照原始osd译码方法找到最可靠的前k+r个mrb,则执行基于排序teps的osd译码方法需输入:k+r位mrb序列m0、置换关系λ1、λ2、完成置换的生成矩阵g2、原始接收序列y、阶数l、crc生成多项式g_crc、保存通过crc校验码字的列表长度len;译码方法输出为码字估计执行l阶ldpc码的基于排序teps的osd译码方法的具体执行步骤如下,其中使用符号“~”表示与mrb对应的相关序列。
18、具体步骤为:
19、s1、将信息序列在传输前进行crc编码,然后进行ldpc编码;
20、s2、将ldpc编码得到的序列通过awgn信道传输;
21、s3、接收端接收到被传送的信息后进行译码,具体方法为:
22、a.按照osd译码方法得到mrb序列m0;
23、b.根据mrb长度k+r、阶数l生成所有测试错误模式tep,共生成个tep,计算每个tep的汉明重量与索引和重量其中0≤l≤l,e表示tep,k为发送的信息序列长度,r为crc校验位长度;
24、c.按照汉明重量递增,以及汉明重量相同时索引和重量递减的顺序对所有tep进行排序,定义存入排序的tep列表为z={e1,e2,...,et},其中对于所有i,j∈[1,t],i<j,有其中索引和重量表示tep中元素1所在位置的索引之和,即
25、d.从列表z中提取tepet(按照t=1→t的顺序),1≤t≤t,计算翻转后的信息序列
26、e.将信息序列与生成矩阵g2相乘,g2为置换生成矩阵,得到当前tep对应的候选码字即
27、f.对当前码字估计进行反置换作用得到原始传输前码字对应的码字估计即其中λ1、λ2为置换关系;
28、g.从中提取出带crc码字的信息位估计进行crc校验(利用crc生成多项式g_crc),若能够通过crc校验,则将对应的码字估计存入预备输出码字列表p,否则认为信息位估计错误,丢弃对应的码字估计
29、h.判断预备输出码字列表p中的码字序列数量是否已达到设定的列表长度len,若列表p中码字数量已达到len,或已将列表z中所有tep检验完毕,则转至步骤l;若列表p中码字数量小于len,且列表z中尚有tep未检验,则转至步骤d提取tepet+1继续进行重编码;
30、l.计算列表p中所有候选码字与接收序列y的欧氏距离,选取其中欧氏距离最小的码字,作为最终译码输出
31、本发明的有益效果为主要体现为两点:
32、1、在本发明提出的基于排序teps的osd译码方法,通过对teps进行似然度估计并排序,令最有可能出现的tep优先参与重编码。对mrb中的比特进行翻转前,对teps进行排序的原则主要确定为两步:汉明重量不同,优先选择汉明重量小的tep参与重编码;汉明重量相同的情况下优先选择索引和重量较大的tep参与重编码。按照此原则生成排序的teps列表,将最有可能出现的tep排在最前端,随后的tep出现的可能性依次降低,从而可更准确地定位正确的tep与相应的码字估计,提升误码性能。
33、2、在本发明提出的基于排序teps的osd译码方法中,通过crc校验,利用列表保存len个能够通过crc校验的码字估计,并在通过crc校验的码字估计中选择欧氏距离最小的作为译码输出。这样的选择输出码字的方式,既通过了crc校验,又采用欧式距离进行比较判断,因而在定位正确码字输出上比原始osd译码方法更准确,从而提升误码性能。另外,通过设置列表长度len,可决定参与重编码的teps数量,从而影响译码复杂度。因此在本发明提出的方法中,可根据实际需要,设置列表长度len,以平衡译码复杂度与误码性能。
- 还没有人留言评论。精彩留言会获得点赞!