速率匹配方法和装置与流程
本申请要求于2012年4月23日递交的第61/636,981号美国临时申请的优先权,其公开内容通过引用的方式全部并入于此。
技术领域
本发明涉及通信领域,更具体地,本发明涉及一种速率匹配方法和装置。
背景技术:
LTE(长期演进)技术是设计用来提高无线通信系统的容量和速度的第四代无线通信技术的最后一步。LTE规范规定了50Mbps的上行链路。为了满足这种高速传输,速率匹配的快速处理和低实现成本是非常重要的。
速率匹配将来自信道编码器的比特流进行交织,根据协议对其进行截取和重复,将结果馈送入信道交织器。
技术实现要素:
本发明的目的是提供一种新的速率匹配方案。
根据本发明的第一方面,提出了一种速率匹配方法,包括:在信道编码器还没有完成对整个数据块的信道编码的情况下,直接对信道编码器的输出的比特流进行速率匹配;以及将所述速率匹配后的比特流输入到信道交织器。
根据本发明的第二方面,提出了一种速率匹配装置,包括速率匹配单元,用于在信道编码器还没有完成对整个数据块的信道编码的情况下,直接对信道编码器的输出的比特流进行速率匹配;以及输出单元,用于将所述速率匹配后的比特流输入到信道交织器。
根据本发明,由于在整个数据块被完全信道编码之前就可以进行速率匹配,因此不需要额外的缓冲器来存储信道编码器输出的结果并且能够更快速地进行速率匹配,实现速率匹配的快速处理和低实现成本的技术效果。
附图说明
结合附图并参考以下详细说明,本发明各实施方式的特征、优点及其他方面将变得更加明显。在此以示例性而非限制性的方式示出了本发明的若干实施方式。在附图中:
图1示意性地示出了本发明可以在其中实施的无线通信系统;
图2示出了根据现有的方案的方法的流程图;
图3示出了根据本发明的一个实施方式的方法的流程图;
图4示出了根据本发明的一个实施方式的装置的框图。
在所有的上述附图中,相同的标号表示具有相同、相似或相应的特征或功能。
具体实施方式
以下参照附图详细描述本发明的各实施方式。
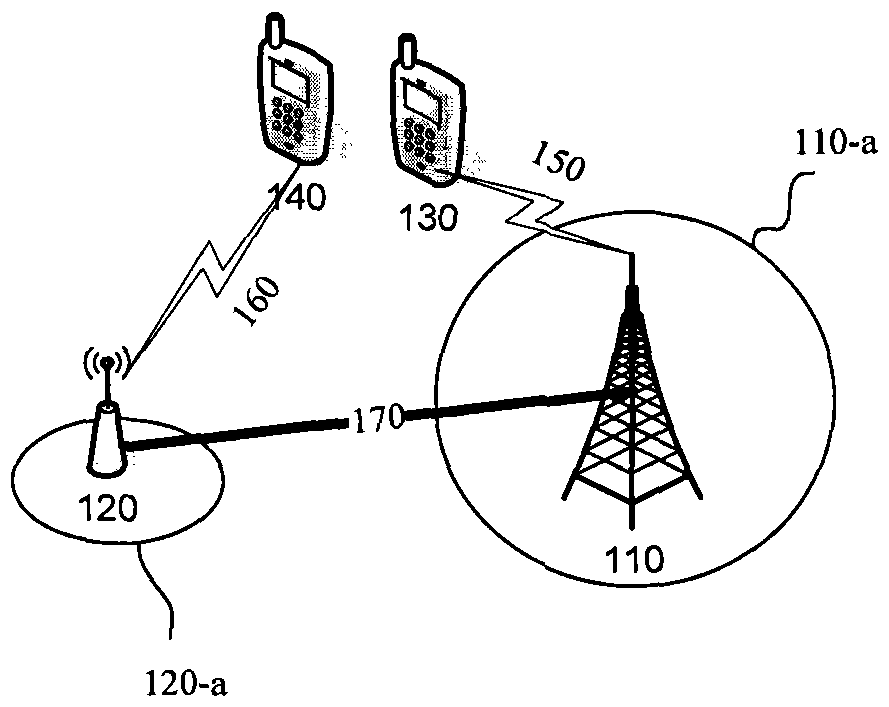
图1示意性地示出了本发明可以在其中实施的无线通信系统100。
如图1所示,该无线通信系统100包括对应于第一小区的第一基站110,对应于第二小区的第二基站120、用户设备130和140。
第一基站110提供第一覆盖范围110-a,第二基站120提供第二覆盖范围120-a。
这里,假定用户设备130在第一覆盖范围110-a内。因此,用户设备130通过无线链路150与第一基站110进行通信。用户设备140在第二覆盖范围120-a内。因此,用户设备140通过无线链路160与第二基站120进行通信。另外,第一基站110和第二基站120之间通过回程链路170进行通信。回程链路170可以是有线的,也可以是无线的。
当然,本领域的技术人员可以理解,无线通信系统100中还可以包括更多或更少的基站、更多或更少的用户设备。
不失一般性,在本发明的描述中,基站与小区是一一对应的关系。即一个小区只有一个基站,以及一个基站只服务于一个小区。另外,不失一般性,在本发明的以下描述中,假定第一基站110和第二基站120是LTE无线通信系统中的基站,用户设备130和140是LTE无线通信系统中的用户设备。当然,本领域的技术人员可以理解,基站也可以是WCDMA、CDMA2000、TD-SCDMA、GPRS、GSM等等无线通信系统中的基站,用户设备130和140也可以是WCDMA、CDMA2000、TD-SCDMA、GPRS、GSM等等无线通信系统中的用户设备。
用户设备130、140可以是移动电话、平板电脑、个人数字助理、照相机、音乐播放器、游戏设备等。
下面作为一个例子描述了一种现有的对Turbo信道编码器的输出的比特流进行速率匹配的方案。更详细的内容可参见3GPP TS36.212,″Evolved Universal Terrestrial Radio Access(E-UTRA);Multiplexing and channel coding′(文献1)。
可以将Turbo信道编码器输出的比特流表示为其中D是比特数,k=0、1、2。当k=0时,表示输出的比特流为系统比特流,当k=1时,表示输出的比特流为奇偶校验1比特流。当k=2时,表示输出的比特流为奇偶校验2比特流。根据Turbo信道编码原理,输入输出之比为1∶3。
将每个输出的比特流排列成矩阵形式,是矩阵的列数,是矩阵的行,通过找到最小的整数使得如果则填充个伪比特。矩阵的前面的ND个元素为填充的伪比特,即对于j=0,1,...,ND-1,接下来,是每个输出的比特流的比特,即m=0,1,...,D-1。
根据该方案,速率匹配的输入与速率匹配的输出之间的关系可以为如下:
对于Turbo信道编码器系统比特流和奇偶校验1比特流,即当k=0和k=1时,π(i)与i之间的关系为:
对于Turbo信道编码器奇偶校验2比特流,即当k=2时,π(i)与i之间的关系为:
在文献1中定义了转置函数P。IΠ为矩阵的大小,即
从等式1可以看出,每个输出的比特流的速率匹配后第i个输出比特,对应于每个输出的比特流的矩阵中的第π(i)个比特。
也就是说,在该方案中,速率匹配的输入是每个输出的比特流的交织顺序,而速率匹配的输出是依次顺序。
尽管上述方案比较直观,但必须等待Turbo信道编码器完全完成对数据块的信道编码才能开始进行速率匹配。因此,需要额外的缓冲器来存储Turbo信道编码器的输出结果。这导致缓冲器的需要并且需要等待额外的时间才可以进行速率匹配。
图2示出了根据现有的上述方案的方法的流程图。
如图2所述,根据该方法200,首先,在步骤S210,Turbo信道编码器之类的信道编码器对数据块进行信道编码。
然后,在步骤S220,将信道编码器输出的每个比特流存储在缓冲器中。
接下来,在步骤S230,对存储在缓冲器中的信道编码器输出的每个比特流进行速率匹配。
最后,在步骤S240,将每个速率匹配后的比特流输入到信道交织器。
作为一个例子,上面所述的3个速率匹配后的比特流如下地输入到信道交织器中的循环缓冲器中:
其中i=0,...,IΠ-1;
其中i=0,...,IΠ-1;
其中i=0,...,IΠ-1。
也就是说,Turbo信道编码器输出的系统比特流的速率匹配后的比特在循环缓冲器的前IΠ个位置,而Turbo信道编码器输出的奇偶校验1比特流的速率匹配后的比特和奇偶校验2比特流的速率匹配后的比特交替地占据循环缓冲器后面的2I∏个位置。
信道交织器根据HARQ参数从循环缓冲器中依次读取比特。
针对以上方案存在的问题,提出了本发明。本发明的目的之一在于不需要信道编码器输出缓冲器而实现直接地对信道编码器的输出比特流进行速率匹配。
图3示出了根据本发明的一个实施方式的方法的流程图。
如图3所述,根据该方法300,首先,在步骤S310,信道编码器对数据块进行信道编码。
然后,在步骤S320,在信道编码器还没有完成对整个数据块的信道编码的情况下,直接对信道编码器的输出的比特流进行速率匹配。
最后,在步骤S330,将所述速率匹配后的比特流输入到信道交织器。
在信道编码器为Turbo信道编码器的情况下,所述信道编码器输出3个比特流,分别为系统比特流、奇偶校验1比特流、奇偶校验2比特流,并且如前面所描述的,对3个比特流中的每个比特流分别进行速率匹配,并且将每个速率匹配后的比特流都输入到信道交织器。
根据本发明的一个实施方式,速率匹配的输入是每个输出的比特流的依次顺序,而速率匹配的输出是交织顺序,与上面所提到的方案中速率匹配的输入是每个输出的比特流的交织顺序,而速率匹配的输出是依次顺序完全相反。
根据该实施方式,速率匹配的输入与速率匹配的输出之间的关系可以如下:
从等式4可以看出,每个输出的比特流的矩阵中的第i个比特,对应于每个输出的比特流的速率匹配后的第π′(i)个输出比特。
i与π′(i)之间的关系为:
其中,i为相应输出的比特流的矩阵中的比特编号,为相应输出的比特流的矩阵的行数,IΠ为相应输出的比特流的矩阵的大小,即如上所述的,P为一个转置函数,如在文献1中所定义的,以及当相应输出的比特流为奇偶校验2比特流时,Δ=1,否则Δ=0。
根据该实施方式,由于在整个数据块被完全信道编码之前就可以进行速率匹配,因此不需要额外的缓冲器来存储信道编码器输出的结果并且能够更快速地进行速率匹配,实现速率匹配的快速处理和低实现成本的技术效果。
根据本发明的一个实施方式,其中上述速率匹配是上行链路速率匹配,即从用户设备130和140到第一基站110和第二基站120的方向上的通信中的速率匹配。
根据本发明的一个实施方式,所述信道编码器为卷积信道编码器。
对于本领域的技术人员来说,可以设想到多种将上面所述的3个速率匹配后的比特流输入到信道交织器中的循环缓冲器中的方式,例如,如上所述的那样,Turbo信道编码器输出的系统比特流的速率匹配后的比特在循环缓冲器的前I∏个位置,而Turbo信道编码器输出的奇偶校验1比特流的速率匹配后的比特和奇偶校验2比特流的速率匹配后的比特交替地占据循环缓冲器后面的2IΠ个位置。
由于这并不是本发明的重点,因此,这里省略了对其的详细描述,总体上可以用m′(k)(i)=f(k)(π′(i))表示,其中k=0,1,2对应于Turbo信道编码器的3个输出流。
另外,为了计算发送给信道交织器的地址m(k)(i),应该丢弃构造相应矩阵时添加的伪比特。因此,需要计算循环缓冲器中位于正在处理的比特的位置之前的伪比特的数量nullOffset(k)(i)。研究循环缓冲器中伪比特的位置,发现其很有特点并且易于计算:每个子块中具有伪比特的行中最多有一行没有充满伪比特。假定未充满伪比特的行是行R,总体上,可以计算nullOffset(k)(i)为:
nullOffset(k)(i)=(R-1)*32+nullNum(k)(Row(R))
那么发送给信道交织器的地址为m(k)(i)=m′(k)(i)-nullOffset(k)(i)。
图4示出了根据本发明的一个实施方式的装置的框图。
如图4所示,该速率匹配装置400包括:速率匹配单元410,用于在信道编码器还没有完成对整个数据块的信道编码的情况下,直接对信道编码器的输出的比特流进行速率匹配;以及输出单元420,用于将所述速率匹配后的比特流输入到信道交织器。
根据本发明的一个实施方式,所述信道编码器为Turbo信道编码器,所述信道编码器输出3个比特流,分别为系统比特流、奇偶校验1比特流、奇偶校验2比特流,其中所述装置400包括3个速率匹配单元410(图中未示出),用于对3个比特流中的每个比特流分别进行速率匹配,并且所述输出单元420将每个速率匹配后的比特流都输入到信道交织器。
根据本发明的一个实施方式,速率匹配的输入是每个输出的比特流的依次顺序,而相应的速率匹配的输出是交织顺序。
根据本发明的一个实施方式,每个输出的比特流的依次顺序与速率匹配的输出的交织顺序的关系为:
其中,i为相应输出的比特流的矩阵中的比特编号,为相应输出的比特流的矩阵的行数,I∏为相应输出的比特流的矩阵的大小,即如上所述的,P为一个转置函数,如在文献1中所定义的,以及当相应输出的比特流为奇偶校验2比特流时,Δ=1,否则Δ=0。
根据本发明的一个实施方式,所述速率匹配是上行链路速率匹配。也就是说,上述速率匹配装置400包括在上述用户设备130和/或140中。
根据本发明的一个实施方式,所述速率匹配是LTE无线通信系统中的速率匹配。
根据本发明的一个实施方式,所述信道编码器为卷积信道编码器。
应当注意,为了使本发明更容易理解,上面的描述省略了对于本领域的技术人员来说是公知的、并且对于本发明的实现可能是必需的更具体的一些技术细节。
因此,选择并描述实施方式是为了更好地解释本发明的原理及其实际应用,并使本领域普通技术人员明白,在不脱离本发明实质的前提下,所有修改和变更均落入由权利要求所限定的本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!