对抗大数据的推断攻击的隐私的制作方法
本申请请求于2013年2月8日,在美国专利和商标局提交,并且被分配的序列号为61/762480的临时申请的优先权和从其获得的所有利益。
技术领域
本发明一般地涉及用于保护隐私的方法和装置,并且更特别地,涉及根据由用户生成的大量公开数据点生成隐私保护映射机制的方法和装置。
背景技术:
在大数据时代,用户数据的收集和挖掘已经成为大量的私有和公共机构的快速成长的惯常做法。例如,技术公司利用用户数据,以向他们的客户提供个性化服务,政府代理依赖数据以解决各类挑战,例如,国家安全、国民健康状况、预算和经费分配,或者医疗机构分析数据以发现疾病的起源和可能的治疗方案。在一些情形下,收集、分析或与第三方共享用户数据,在未经用户许可或觉察的情况下执行。在另一些情形下,数据被用户自愿向特定分析方公布,以获得服务作为回报,例如,产品评级被公布以获得推荐。这一服务,或者用户从允许访问该用户的数据所获得的其它利益,可以被称为效用。在二者之一的情形下,当一些被收集的数据可能被用户认为是敏感的(例如,政治观点、健康状态、收入水平)时,或乍看可能无害(例如产品评级),仍然导致对与其相关的更为敏感的数据的推断时,隐私风险将会增加。后者的威胁涉及推断攻击(inference attack),这是一种通过利用隐私数据与被公开公布数据的关系,对隐私数据进行推断的技术。
在近些年中,在线隐私滥用的许多威胁已经显露,包括身份窃取、名誉损害、工作丢失、歧视、骚扰、网络恐吓、追踪甚至自杀。同时,对在线社会网络(OSN)提供方的指控已经变成常见的涉嫌非法数据收集、未经用户许可共享数据、未经通知用户改变隐私设置、误导用户追踪他们的浏览行为、不执行用户的删除行为,以及未适当地通知用户关于他们的数据的用途和其他哪些人得以访问这些数据。OSN的赔偿责任可能上升到几千万甚至几亿美元。
互联网中管理隐私的一个中心问题在于同时管理公开数据和隐私数据。许多用户愿意公布关于他们的一些数据,比如他们的观影史或者他们的性别;他们这么做是因为这种数据允许有用的服务,并且因为这些属性很少被认为隐私。然而,用户还有其他他们认为隐私的数据,比如收入水平、政治立场、或医疗条件。在这样的工作中,我们关注用户能够公布她的公开数据,但是能够阻止可以从公开信息得到她的隐私数据的推断攻击的方法。我们的解决方案包括隐私保护映射,该隐私保护映射通知用户关于如何在公布她的公开数据之前使其失真,以致推断攻击不能够成功地得到她的隐私数据。同时,该失真应当是有界的,以便于原来的服务(比如推荐)能够继续有效。
期望用户获得对公开公布的数据的分析的利益,比如电影推荐、或购物习惯。然而,不期望第三方能够分析这一公开数据并推断隐私数据,比如政治立场或收入水平。期待用户或服务能够公布一些公开信息以获得利益,但是控制第三方推断隐私信息的能力,这一点将是受期望的。这一控制机制的困难方面在于,通常非常多的公开数据被用户公布,并且对所有这些数据进行分析以阻止隐私数据的公布是计算上不可行的。因此,期望克服上面的难点,并且向用户提供对于隐私数据安全的体验。
技术实现要素:
根据本发明的一方面,公开了一种装置。根据示例性的实施例,该装置包含:存储器,用于存储多个用户数据,其中该用户数据包含多个公开数据;处理器,用于将所述多个用户数据分组到多个数据簇,其中所述多个数据簇的每一个包括所述用户数据的至少两个;响应于所述多个数据簇的分析,所述处理器还进行操作以确定统计值,其中所述统计值代表隐私数据的实例的概率,所述处理器还进行操作以改变所述用户数据的至少一个以生成改变后的多个用户数据;以及传送器,用于传送所述改变后的多个用户数据。
根据本发明的另一方面,公开了一种用于保护隐私数据的方法。根据示例性的实施例,该方法包含下述步骤:获取用户数据,其中该用户数据包含多个公开数据;将该用户数据分簇到多个簇,并处理数据簇以推断隐私数据,其中所述处理确定所述隐私数据的概率;
根据本发明的另一方面,公开了用于保护隐私数据的第二方法。根据示例性的实施例,该方法包含下述步骤:汇集多个公开数据,其中所述多个公开数据的每一个包含多个特征;生成多个数据簇,其中所述数据簇包含所述多个公开数据的至少两个,并且其中所述多个公开数据的所述至少两个的每一个具有所述多个特征的至少一个;处理所述多个数据簇以确定隐私数据的概率,并且响应于所述概率超过预定值,改变所述多个公开数据的至少一个以生成改变后的公开数据。
附图说明
通过参考下面结合附图对本发明的实施例的描述,本发明的上面提及的和其他特征和优势,以及获得这些的方式,将变得更为明显,且本发明将被更好地理解,其中:
图1为根据本原理的实施例,描述了用于保护隐私的示例性方法的流程图。
图2为根据本原理的实施例,描述了当隐私数据和公开数据之间的联合分布已知时,用于保护隐私的示例性方法的流程图。
图3为根据本原理的实施例,描述了当隐私数据和公开数据之间的联合分布未知且公开数据的边缘概率测度也未知时,用于保护隐私的示例性方法的流程图。
图4为根据本原理的实施例,描述了当隐私数据和公开数据之间的联合分布未知但公开数据的边缘概率测度已知时,用于保护隐私的示例性方法的流程图。
图5为根据本原理的实施例,描述了示例性的隐私代理的框图。
图6为根据本原理的实施例,描述了具有多个隐私代理的示例性系统的框图。
图7为根据本原理的实施例,描述了用于保护隐私的示例性方法的流程图。
图8为根据本原理的实施例,描述了用于保护隐私的第二示例性方法的流程图。
这里提出的范例示出了本发明的优选实施例,并且这些范例不被解释为以任何方式限制本发明的范围。
具体实施方式
现在参考附图,并且更特别地参考图1,示出用于实现本发明的示例性方法100的示图。
图1示出了根据本原理,用于使将被公布的公开数据失真以保护隐私的示例性方法100。方法100起始于105。在步骤110,例如,从不关心他们的公开数据或隐私数据的隐私的那些用户,基于被公布的数据收集统计信息。我们将这些用户表示为“公开用户”,并且将希望使将被公布的公开数据失真的用户表示为“隐私用户”。
统计信息可以通过网络爬虫、访问不同的数据库收集,或者可以被数据整合方提供。哪些统计信息能够被收集取决于公开用户所公布的内容。例如,如果公开用户公布了隐私数据和公开数据,联合分布PS,X的估计能够被获取。在另一示例中,如果公开用户仅公布了公开数据,边缘概率测度PX(而非联合分布PS,X)的估计,能够被获取。在另一示例中,我们可能仅能够获得公开数据的均值和方差。在最差的情形下,我们可能不能获得关于公开数据或隐私数据的任何信息。
在步骤120,假定效用约束,该方法基于统计信息确定隐私保护映射。如之前讨论的,隐私保护映射机制的解决方法取决于可用的统计信息。
在步骤130,在于步骤140向例如服务提供方或数据收集代理公布之前,根据被确定的隐私保护映射,使当前隐私用户的公开数据失真。对隐私用户,假定值X=x,根据分布PY|X=x,值Y=y被采样。这一值y被公布,而非真实值x。注意到该隐私映射的使用以生成被公布的y,不需要知道隐私用户的隐私数据的值S=s。方法100在步骤199结束。
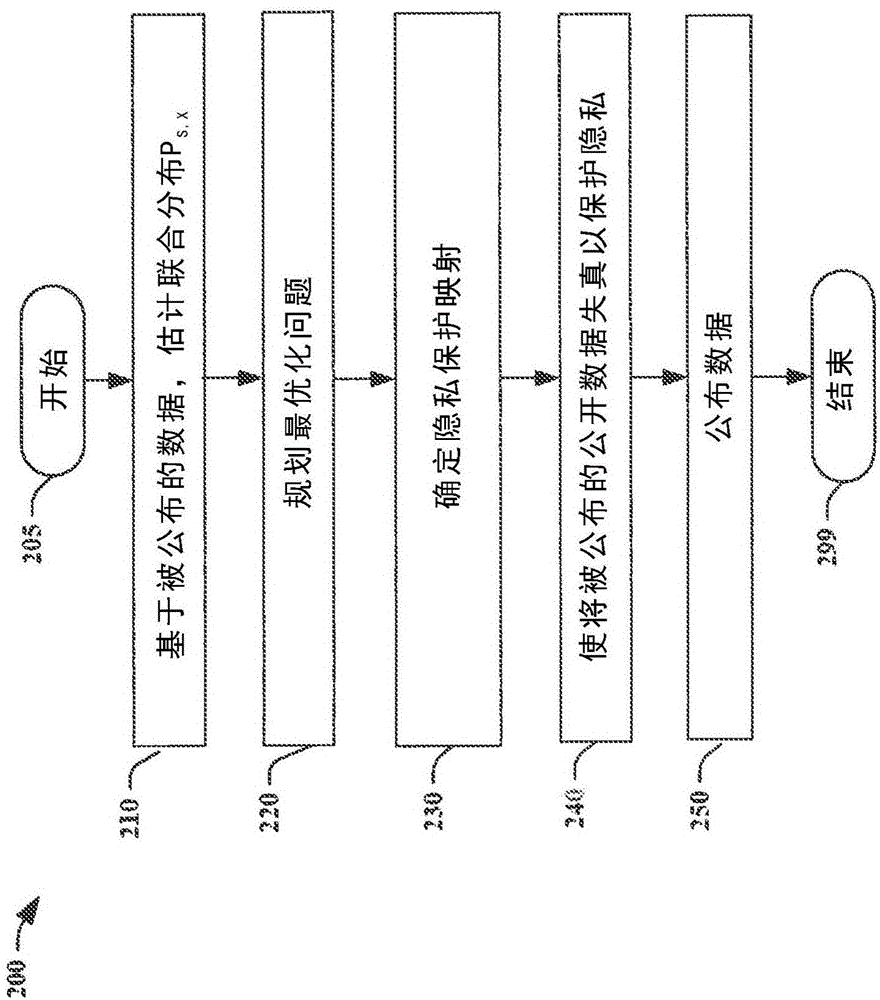
图2-4进一步详细示出了当不同的统计信息可用时,用于保护隐私的示例性方法。具体地,图2示出了当联合分布PS,X已知时的示例性方法200,图3示出了当边缘概率测度PX已知,但联合分布PS,X未知时的示例性方法300,以及图4示出了当边缘概率测度PX和联合分布PS,X都未知时的示例性方法400。方法200、300和400在以下将进一步详细讨论。
方法200起始于205。在步骤210,基于被公布的数据估计联合分布PS,X。在步骤220,该方法被用于规划最优化问题。在步骤230,隐私保护映射被确定为例如凸问题。在步骤240,根据被确定的隐私保护映射,在于步骤250被公布以前,使当前用户的公开数据失真。方法200结束于步骤299。
方法300起始于305。在步骤310,该方法通过最大相关规划最优化问题。在步骤320,例如通过利用幂迭代或兰索斯(Lanczos)算法,该方法确定隐私保护映射。在步骤330,根据被确定的隐私保护映射,在于步骤340被公布以前,使当前用户的公开数据失真。方法300结束于步骤399。
方法400起始于405。在步骤410,基于被公布的数据估计分布PX。在步骤420,通过最大相关规划最优化问题。在步骤430,例如通过使用幂迭代或兰索斯算法,确定隐私保护映射。在步骤440,在于步骤450被公布之前,根据被确定的隐私保护映射,使当前用户的公开数据失真。方法400在步骤499结束。
隐私代理为向用户提供隐私服务的实体。隐私代理可以执行以下的任何操作:
从用户接收哪些数据他认为隐私、哪些数据他认为公开,以及他需要哪个隐私等级;
计算隐私保护映射;
对用户实现该隐私保护映射(即,根据该映射使他的数据失真);以及
例如,向服务提供方或数据收集代理,公布失真后的数据。
本原理能够在保护用户数据的隐私的隐私代理中应用。图5描述了示例性系统500的框图,这里隐私代理能够被使用。公开用户510公布他们的隐私数据(S)和/或公开数据(X)。如之前讨论的,公开用户可以公布公开数据如,即Y=X。被公开用户公布的信息成为对隐私代理有用的统计信息。
隐私代理580包括统计信息收集模块520、隐私保护映射决定模块530和隐私保护模块540。统计信息收集模块520可以被用于收集联合分布PS,X、边缘概率测度PX、和/或公开数据的均值和协方差。统计信息收集模块520还可以从数据整合方(例如bluekai.com)接收统计信息。取决于可用的统计信息,隐私保护映射决定模块530设计隐私保护映射机制PY|X。在隐私用户560的公开数据被公布之前,根据条件概率PY|X,隐私保护模块540使该公开数据失真。在一个实施例中,统计收集模块520、隐私保护映射决定模块530、和隐私保护模块540能够被使用以分别执行方法100中的步骤110、120和130。
注意到隐私代理仅需要该统计信息以运行,而不需了解在数据收集模块中收集的全体数据。因此,在另一实施例中,数据收集模块可以为收集数据并然后计算统计信息的独立模块,且不需为隐私代理的一部分。数据收集模块与隐私代理共享该统计信息。
隐私代理位于用户和用户数据的接收方(例如,服务提供方)之间。例如,隐私代理可以位于用户设备,例如计算机或机顶盒(STB)。在另一示例中,隐私代理可以为单独的实体。
隐私代理的所有模块可以位于一个设备,或可以分布于不同的设备,例如,统计信息收集模块520可以位于仅向模块530公布统计信息的数据整合方,隐私保护映射决定模块530可以位于“隐私服务提供方”或连接至模块520的用户设备上的用户端,且隐私保护模块540可以位于隐私服务提供方或用户设备上的用户端,该隐私服务提供方然后作为用户和用户愿意向其公布数据的服务提供方之间的中间方。
隐私代理可以向服务提供方(例如,康卡斯特公司或奈飞公司)提供被公布的数据,以基于被公布的数据对隐私用户560改进所接收的服务,例如,基于它的被公布的电影评级,推荐系统向用户提供电影推荐。
在图6,我们示出了在系统中存在多个隐私代理。在不同的失真中,由于隐私代理对于隐私系统工作并非必要条件,因此不需要每个地方存在隐私代理。例如,可以仅在用户设备,或服务提供方,或二者之处存在隐私代理。在图6,对奈飞公司和脸谱公司二者,我们示出了相同的隐私代理“C”。在另一实施例中,位于脸谱公司和奈飞公司的隐私代理,可以但不需要相同。
发现隐私保护映射作为凸优化的解决方案,依赖于下列基本假设:连接隐私属性A和数据B的先验分布PA,B已知,并且可以作为算法的输入。在实践中,真实的先验分布可能未知,但是相反地,可以从能够被观察的一组样本数据(例如,从不关心隐私且公开地公布他们的属性A和他们的原始数据B的一组用户观察到的一组样本数据)估计。基于来自于非隐私用户的这组样本而估计的先验信息然后被用于设计将被用于关心他们的隐私的新用户的隐私保护机制。在实践中,由于例如小数量的观察样本或者由于观察数据的不完整,可能存在被估计的先验信息和真实的先验信息之间的失配。
现在转到图7,根据大数据的隐私保护的方法700。当例如由于大量的可用公开数据项而导致用户数据的基础字母表的尺寸非常大时,扩展性的问题将会发生。为处理这一问题,限制该问题的维度的量化方法被示出。为解决这一限制,通过优化一个小得多的变量集,该方法教导解决这一问题。该方法包括三个步骤。首先,将字母表B降低为C代表性示例,或簇。其次,使用这些簇生成隐私保护映射。最后,输入字母表B中的所有示例b基于对b的代表性示例C的被学习的映射而变成^C。
首先,方法700起始于步骤705。然后,从所有可用的源,所有可用的公开数据被收集和聚集(710)。然后,原始数据被特征化(715),且分簇到限定数目的变量(720),或簇。数据可以根据数据的特征被分簇,为了隐私映射的目的,这些数据的特征可以统计上类似。例如,可以指示政治立场的电影可以被分簇在一起以降低变量的数目。对每一个簇的分析可以被执行以提供权重值等以便于以后计算性分析。这一量化方案的优势为,通过将优化后变量的数目从基础特征字母表的大小的平方降低为簇的数目的平方,计算上变得高效,并且因此使该优化与观察的数据样本的数目无关。对一些现实生活中的示例,这能够引起维度上的数量级降低。
该方法然后被用于确定如何在被簇定义的空间中使数据失真。通过在公布前改变一个或多个簇的值或删除簇的值,可以使数据失真。使用经历失真约束而最小化隐私泄露的凸解算器(convex solver),隐私保护映射被计算(725)。任何因量化引起的另外失真,可以随着样本数据点和最接近的簇中心之间的最大距离线性地增加。
数据的失真可以被重复地执行,直到隐私数据点不能被推断超过某个阈值的概率。例如,可能统计上不期望对人的政治立场仅有70%的确信度。因此,可以使簇或数据点失真,直到推断政治立场的能力低于70%的确定性。这些簇可以与先验数据相比较,以确定推断的概率。
根据隐私映射的数据然后被公布为公开数据或被保护的数据(730)。方法700结束于735。用户可以被通知隐私映射的结果,且然后可以被给出使用隐私映射或公布未失真的数据的选项。
现在转到图8,示出了根据失配的先验信息用于确定隐私映射的方法800。首要的问题为这一方法依赖于了解隐私数据和公开数据之间的联合概率分布(被称为先验)。通常,真实的先验分布不可用,且相反地,仅隐私数据和公开数据的样本的限定集合可以被观察到。这导致先验失配问题。这一方法解决了这一问题且即使面对先验失配也试图提供失真和带来隐私。我们的首要贡献集中于以可观察的样本数据集开始,我们发现先验的改进估计,基于该估计,隐私保护映射被得到。我们发展了对任何另外失真的一些限制,这一过程引起保证给定水平的隐私。更精确地,我们示出了隐私信息泄露与我们的估计和先验之间的L1-norm距离呈对数-线性增长;失真比率与我们的估计和先验之间的L1-norm距离线性地增长;当样本大小增长时,我们的估计和先验之间的L1-norm距离降低。
方法800起始于805。该方法首先从公布隐私数据和公开数据的非隐私用户的数据估计先验。这一信息可以从公开可用的源得到,或者通过调查中的用户输入等生成。如果不能获得足够样本,或者如果一些用户提供由于丢失条目而导致不完整的数据,这些数据的一些可能是不够的。如果大量的用户数据被获取,这一问题可以得到补偿。然而,这些不足可能导致真实的先验和被估计的先验之间的失配。因此,当应用于复杂的解算器时,被估计的先验可能无法提供完全可靠的结果。
然后,关于用户的公开数据被收集(815)。通过比较用户数据与被估计的先验,这一数据被量化(820)。作为比较和确定代表性先验数据的结果,用户的隐私数据然后被推断。隐私保护映射然后被确定(825)。根据隐私保护映射,使该数据失真,并且然后向公众公布为公开数据或被保护的数据(830)。该方法结束于835。
如这里所描述的,本发明提供了用于能够进行公开数据的隐私保护映射的架构和协议。尽管本发明已被描述为具有优选设计,但是本发明可以被进一步修改,而不脱离本公开的精神和范围。因此,本申请意图覆盖利用它的一般原理的本发明的所有变形、用途或修改。进一步地,本申请意图覆盖由于进入了本发明所属领域中的已知或通常实践并落入所附加的权利要求的限制内的那些从本公开的脱离。
- 还没有人留言评论。精彩留言会获得点赞!