一种信息处理方法、设备和系统与流程
本发明涉及数据业务领域,尤其涉及一种信息处理方法、设备和系统。
背景技术:
流量分析系统需要对全省各本地网各个节点网元的输入输出字节进行高频率的采集,根据规则计算周期时间内的流量、速率。在单位时间内产生的数据量大、计算量也大。oracle数据库的特点是在插入,写操作的时候,一般情况下也会先写入内存,然后由dbwr进程调度写入到数据文件。如此高频率的写库操作很耗服务器的性能,当采集量越来越大的时候,服务器性能的瓶颈体现的越来越明显,导致采集效率降低。而且查询终端从oracle服务器查询采集数据时,也随着数据量的不断加大使得响应速度不断变慢。
现有技术中,由于oracle服务器的性能不够,处理能力也有局限性,只能分本地网,分别针对重点olt网元进行采集分析,无法对全网网元流量进行采集分析。
技术实现要素:
为解决上述技术问题,本发明实施例提供一种信息处理方法、设备和系统,实现网元流量采集不因为采集节点增多和采集频率的增加,而影响采集数据的保存和查询。
本发明的技术方案是这样实现的:
本发明实施例提供一种信息处理系统,所述系统包括:第一服务器、第二服务器、第三服务器、网元设备,所述网元设备包括第四服务器,其中,
所述第一服务器,用于保存所述第二服务器的采集结果记录和第三服务器的统计结果记录;
所述第二服务器,用于从网元设备同步采集任务,根据所述采集任务确定结果队列,并对所述结果队列中的数据进行编码;
所述第三服务器,用于对网元设备的流量进行统计分析;
所述网元设备,用于采集流量指标;
所述第四服务器,用于保存采集任务。
进一步地,所述第二服务器,具体用于实时将第一数据库中的采集任务同步到第二数据库;将所述第二数据库中的采集任务根据预设调度规则调入任务队列;根据所述任务队列中的采集任务确定结果队列;根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库,将编码结果更新所述第一数据库。
进一步地,所述第二服务器,具体用于获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
进一步地,所述第三服务器,具体用于将第一数据库中的统计任务读取到第二数据库和任务队列;根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计,将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
本发明实施例提供一种信息处理方法,所述方法包括:
实时将第一数据库中的采集任务同步到第二数据库;
将所述第二数据库中的采集任务根据预设调度规则调入任务队列;
根据所述任务队列中的采集任务确定结果队列;
根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库,将编码结果更新所述第一数据库。
进一步地,所述根据所述任务队列中的采集任务确定结果队列,包括:
获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
本发明实施例提供一种信息处理方法,所述方法包括:
将第一数据库中的统计任务读取到第二数据库和任务队列;
根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计;
将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
本发明实施例提供一种采集服务器,所述采集服务器包括:同步模块、调度模块、采集模块、编码模块,其中,
所述同步模块,用于实时将第一数据库中的采集任务同步到第二数据库;
所述调度模块,用于将所述第二数据库中的采集任务根据预设调度规则调入任务队列;
所述采集模块,用于根据所述任务队列中的采集任务确定结果队列;
所述编码模块,用于根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库。
进一步地,所述采集模块,具体用于获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
本发明实施例提供一种统计服务器,所述统计服务器包括:读操作模块、统计模块、写操作模块,其中,
所述读操作模块,用于将第一数据库中的统计任务读取到第二数据库和任务队列;
所述统计模块,用于根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计;
所述写操作模块,用于将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
本发明实施例提供了一种信息处理方法、设备和系统,所述系统包括:第一服务器、第二服务器、第三服务器、网元设备,所述网元设备包括第四服务器,其中,所述第一服务器,用于保存所述第二服务器的采集结果记录和第三服务器的统计结果记录;所述第二服务器,用于从网元设备同步采集任务,根 据所述采集任务确定结果队列,并对所述结果队列中的数据进行编码;所述第三服务器,用于对网元设备的流量进行统计分析;所述网元设备,用于采集流量指标;所述第四服务器,用于保存采集任务。本发明实施例提供的信息处理方法、设备和系统,实现网元流量采集不因为采集节点增多和采集频率的增加,而影响采集数据的保存和查询。
附图说明
图1为本发明实施例提供的信息处理系统结构示意图;
图2为本发明实施例提供的信息处理系统示例图;
图3为本发明实施例提供的采集服务器示例图;
图4为本发明实施例提供的信息处理方法流程示意图一;
图5为本发明实施例提供的采集入库时序示例图;
图6为本发明实施例提供的采集入库示例图;
图7为本发明实施例提供的信息处理方法流程示意图二;
图8为本发明实施例提供的统计服务器示例图;
图9为本发明实施例提供的采集服务器结构示意图;
图10为本发明实施例提供的统计服务器结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明实施例提供一种信息处理系统1,如图1所示,所述系统包括:第一服务器10、第二服务器11、第三服务器12、网元设备13;所述网元设备13包括第四服务器130,其中,
所述第一服务器10,用于保存所述第二服务器的采集结果记录和第三服务器的统计结果记录;
所述第二服务器11,用于从网元设备同步采集任务,根据所述采集任务确 定结果队列,并对所述结果队列中的数据进行编码;
所述第三服务器12,用于对网元设备的流量进行统计分析;
所述网元设备13,用于采集流量指标;
所述第四服务器130,用于保存采集任务。
进一步地,所述第二服务器11,具体用于实时将第一数据库中的采集任务同步到第二数据库;将所述第二数据库中的采集任务根据预设调度规则调入任务队列;根据所述任务队列中的采集任务确定结果队列;根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库,将编码结果更新所述第一数据库。
进一步地,所述第二服务器11,具体用于获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
进一步地,所述第三服务器12,具体用于将第一数据库中的统计任务读取到第二数据库和任务队列;根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计,将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
具体的,第一服务器为hbase服务器,第二服务器为采集服务器,第三服务器为统计服务器,第四服务器为oracle服务器。
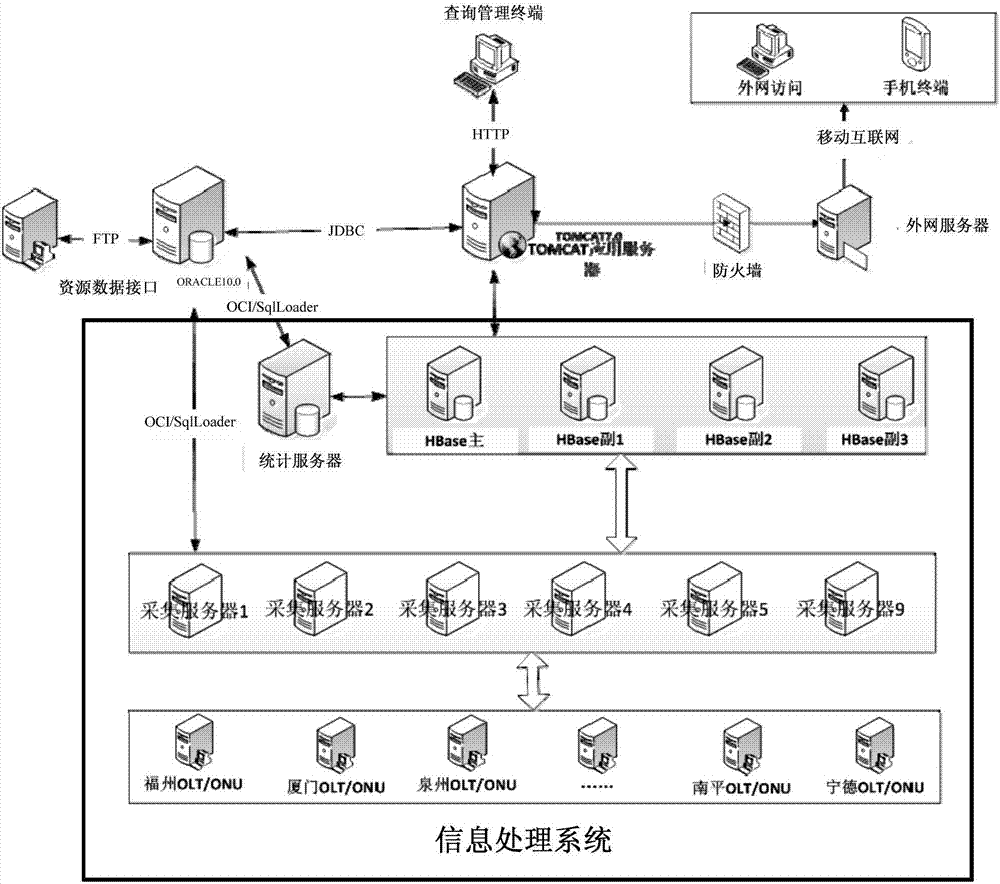
如图2所示,本发明实施例提供的系统示例图,该系统可以包括:oracle服务器、至少一个hbase服务器、至少一个采集服务器、统计服务器;其中,
oracle服务器,用于保存采集任务以及相关的资源分析。
hbase服务器采用集群部署方式,用于保存采集程序的采集结果流水记录和统计程序的统计结果记录。
采集服务器部署sqlite和采集程序,通过sqlite从省平台oracle服务器同步采集任务,按照既定的任务调度规则从网元设备采集流量指标,收集到采集指标后计算单位时段的流量和采集流水记录,结合各采集对象的rowkey编码规则,将key-value及时写入hbase。采集任务执行文笔,将任务结果更新 回平台的oracle服务器。
统计服务器部署统计程序,通过对相关网元节点流量的关联比较分析,统计父节点流量和同级节点的流量大小排序。
网元设备,采集程序直接通过snmp方式访问网元,采集流量指标。
其中,oracle数据库oracledatabase,又名oraclerdbms,或简称oracle。是甲骨文公司的一款关系数据库管理系统。
hbase是一个分布式的、面向列的开源数据库。
sqlite,是一款轻型的数据库,是遵守acid的关系型数据库管理系统,它包含在一个相对小的c库中。
简单网络管理协议(snmp),由一组网络管理的标准组成,包含一个应用层协议(applicationlayerprotocol)、数据库模型(databaseschema)和一组资源对象。该协议能够支持网络管理系统,用以监测连接到网络上的设备是否有任何引起管理上关注的情况。
本发明实施例提供的信息处理系统,在采集节点指标不断增多,采集频率不断加大的情况下,采集数据的保存和查询效率不受影响或者受到的影响可忽略不计;实现了流量分析采集系统的分布式采集指标、集中式管理数据;实现网元流量采集不因为采集节点增多和采集频率的增加,而影响采集数据的保存和查询。
本发明实施例提供一种信息处理方法,该方法应用于采集服务器,如图3所示,采集服务器部署sqlite和采集程序,通过sqlite从省平台oracle服务器同步采集任务,采集程序部署于各本地网,独立进行指标采集、计算和数据入库。
其中,oracle数据库,用于对全省网元采集任务数据管理;
sqlite,用于对采集服务器本地采集任务数据管理;
hbase,用于对全省网元采集指标结果记录数据管理;
synconfig,用于对省平台采集任务数据同步到本地采集服务器;
在调度进程中,按照任务调度规则从本地任务表调度采集任务进入任务队 列;
在采集进程中,根据任务队列的信息,从指定网元采集流量指标,并根据规则计算周期流量、速率等,采集数据和计算结果写入结果队列;
在写库进程中,将采集结果数据写回到hbase,将采集任务结果更新回oracle服务器。
本发明实施例提供一种信息处理方法,如图4所示,该方法可以包括:
步骤101、实时将第一数据库中的采集任务同步到第二数据库;
步骤102、将所述第二数据库中的采集任务根据预设调度规则调入任务队列;
步骤103、根据所述任务队列中的采集任务确定结果队列;
步骤104、根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库,将编码结果更新所述第一数据库。
其中,第一数据库为oracle数据库,第二数据库为sqlite数据库,第三数据库为hbase数据库。
具体的,所述根据所述任务队列中的采集任务确定结果队列,包括:
获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
具体的,如图5、图6所示的采集时序及描述,采集统计以任务为驱动,一个采集任务从任务产生、到最后结果形成。采集任务保存在oracle数据库,管理者通过终端访问数据库的方式管理和查询采集任务;采集程序调度模块实时从oracle数据库同步采集任务到本地sqlite;采集程序任务调度模块将本地sqlite中的采集任务根据调度规则调入到任务队列;采集程序采集模块将任务队列中的采集任务取出,根据任务信息到指定网元采集流量指标,并根据任务中的前次采集指标计算关联指标,写入结果队列;写库进程对结果队列中的结果数据,根据各采集对象的rowkey编码规则,将key-value写回到hbase,将任务结果更新回oracle数据库。
具体的,hbase的rowkey编码规则如下所述:
hbase数据的入库和高效查询,离不开rowkey的准确定义,从hbase的scan工具入手,依靠rowkey的startrow、stoprow范围查询,可以完全不受数据量的约束,实现高效查询。本发明对hbase的rowkey编码规则定义如下:
主要参数固定位数编码规则
ip编码,共12位。包含olt和onu的ip编码,将ip地址4节数字转换为3位的数字字符,不足在前面补0,然后去掉点号分隔符。例如192.168.0.32表示成192168000032;
上联口和pon端口编码,6位。这两个端口的编码一般包含槽位、子槽和端口编号,中间分隔符可能是‘/’或‘-’。将槽位、子槽和端口编号都转换成2位的数字字符,不足在前面补0,,然后去掉点号分隔符。例如,6-0-1表示成060001,其他类推,
onu端口编码,共8位。类似上联口和pon端口编码转换规则,转换为8位。
地区编码,共4位,不足前面补0,例如福州0591,北京0010。
时间、日期和小时编码,时间格式为yyyymmddhh24miss,针对小时的编码则为yyyymmddhh24,针对日期的编码则为yyyymmdd。
采集对象编码规则
olt设备(16):地区(4)+olt_ip(12)
olt上联口(22):地区(4)+olt_ip(12)+上联口(6)
oltpon口(22):地区(4)+olt_ip(12)+pon口(6)
onu设备(16):地区(4)+onu_ip(12)
onu上联口(22):地区(4)+onu_ip(12)+上联口(6),如果上联口不确认,统一为8个0(onu就一个上联口)
onu端口(24):地区(4)+olt_ip(12)+端口id(8)
采集记录表主键编码规则
olt上联口:olt上联口(22)+记录时间(14);
oltpon口:oltpon口(22)+记录时间(14);
onu上联口:onu上联口(22)+记录时间(14)
onu端口:onu端口(24)+记录时间(14)
小时节点统计表主键编码规则
olt上联口:olt上联口(22)+记录时间(10);
oltpon口:oltpon口(22)+记录时间(10);
onu上联口:onu上联口(22)+记录时间(10)
onu端口:onu端口(24)+记录时间(10)
日节点统计表主键编码规则
olt上联口:olt上联口(22)+记录日期(8);
oltpon口:oltpon口(22)+记录日期(8);
onu上联口:onu上联口(22)+记录日期(8)
onu端口:onu端口(24)+记录日期(8)
本发明实施例提供一种信息处理方法,如图7所示,该方法可以包括:
步骤201、将第一数据库中的统计任务读取到第二数据库和任务队列;
步骤202、根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计;
步骤203、将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
其中,第一数据库为oracle数据库,第二数据库为sqlite数据库,第三数据库为hbase数据库。
具体的,本发明实施例提供的信息处理方法应用于统计服务器,统计服务器部署统计程序,通过对相关网元节点流量的关联比较分析,统计父节点流量和同级节点的流量大小排序,如图8所示,统计程序部署于省平台,集中对入库数据进行分析比较、统计运算。
其中,oracle数据库,用于对全省网元统计任务数据管理;
sqlite,用于统计服务器统计任务数据管理;
hbase,用于对全省网元统计指标结果记录数据管理;
dbreader,用于省平台统计任务数据同步到统计服务器;
在统计进程中,根据任务队列的信息,统计指定层级下网元节点的流量指标,进行排序、求和的统计;
在写库进程中,将统计结果数据写回到hbase,将统计任务结果更新回oracle数据库。
本发明实施例提供的信息处理方法,在采集节点指标不断增多,采集频率不断加大的情况下,采集数据的保存和查询效率不受影响或者受到的影响可忽略不计;实现了流量分析采集系统的分布式采集指标、集中式管理数据;实现网元流量采集不因为采集节点增多和采集频率的增加,而影响采集数据的保存和查询。
本发明实施例提供一种采集服务器2,如图9所示,所述采集服务器2包括:同步模块20、调度模块21、采集模块22、编码模块23,其中,
所述同步模块20,用于实时将第一数据库中的采集任务同步到第二数据库;
所述调度模块21,用于将所述第二数据库中的采集任务根据预设调度规则调入任务队列;
所述采集模块22,用于根据所述任务队列中的采集任务确定结果队列;
所述编码模块23,用于根据预设编码规则将所述结果队列中的数据进行编码,写入第三数据库。
进一步地,所述采集模块22,具体用于获取任务队列中的采集任务,根据所述采集任务携带的任务信息采集流量指标,根据所述采集任务的前一次采集流量指标确定关联流量指标,将所述关联流量指标写入结果队列。
具体的,本发明实施例提供的采集服务器的理解可以参考信息处理方法的说明,本发明实施例在此不再赘述。
本发明实施例提供一种统计服务器3,如图10所示,所述统计服务器3包括:读操作模块30、统计模块31、写操作模块32,其中,
所述读操作模块30,用于将第一数据库中的统计任务读取到第二数据库和 任务队列;
所述统计模块31,用于根据所述任务队列的信息对网元设备的流量指标进行排序、求和统计;
所述写操作模块32,用于将统计结果写入第三数据库,并将所述统计结果更新所述第一数据库。
具体的,本发明实施例提供的统计服务器的理解可以参考信息处理方法的说明,本发明实施例在此不再赘述。
本发明实施例提供的采集服务器、统计服务器,在采集节点指标不断增多,采集频率不断加大的情况下,采集数据的保存和查询效率不受影响或者受到的影响可忽略不计;实现了流量分析采集系统的分布式采集指标、集中式管理数据;实现网元流量采集不因为采集节点增多和采集频率的增加,而影响采集数据的保存和查询。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流 程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!