基于图论算法的互联网保险领域的业务报文自动处理方法和系统与流程
本发明涉及一种业务报文自动处理方法和系统,尤其涉及一种互联网保险领域的业务报文自动处理方法和系统。
背景技术:
在互联网保险业务场景下,保险产品追求长尾效应,更碎片化和高频化,因此,互联网保险公司日受理的保单量远大于传统保险公司的日处理量。这种情况下,根据不同的产品形态,对于有些日单量巨大且实时承保性要求不高产品,保险公司会选择将业务数据汇总在不同类型的报文(例如投保人报文、被保人报文、保单报文、账单报文等)中,异步、定期地进行批量处理。其中,由于报文之间通常具有依赖关系,对报文的处理通常需要按照一定的顺序进行,也就是处理时需要先对报文进行排序,以决定处理报文的顺序。
对于传统的小型保险公司,因为业务单数少,业务类型单一,相应地报文的类型和数量也就少,因此会选择人工对报文进行排序,如通过运维人员凭经验或经简单的人工组合试验确认后将需要处理的报文依次上传到系统服务器上,以形成符合该报文内部依赖关系的排序并供系统服务器调用处理。这种排序方式需要的人力成本大,易出错。此外,当报文类型和/或数量逐渐上升时,成本和出错性上的弊端会愈加明显。
为了使得系统可以自动对报文进行排序和处理,以在保证低成本和低出错率的前提下满足互联网保险业务场景中巨大的保单处理量导致的巨大的报文处理量的需求,现有技术中通常根据报文间的依赖关系,线性地对报文执行的优先级进行排序。如对于承保业务,会以“投/被保人报文→保单报文→账单报文”这样的线性顺序设定在程序中,然后由程序定期按照该线性顺序执行。但这种线性排序方式带来的弊端包括:首先,报文必须按照线性顺序依次处理,当出现两个可并行处理的、相互之间无依赖关系的报文时,程序也只能挨个处理,影响报文处理效率;其次,当某一环节报文出现异常时,后续报文必须全部重新处理,而无法自动挑选出受上述环节报文依赖关系影响的报文,同样影响了报文处理效率。
技术实现要素:
本发明的目的之一是提供一种基于图论算法的互联网保险领域的业务报文自动处理方法,基于该方法能对互联网保险领域的业务报文进行自动排序并按照该排序得到的处理顺序进行自动处理,该处理允许相互之间无依赖关系的报文并行处理,同时还允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理,以在低成本、低出错率地满足巨大的报文处理量需求的同时,大大提高报文处理效率。
根据上述目的之一,本发明提出了一种基于图论算法的互联网保险领域的业务报文自动处理方法,其包括:
采集报文信息数据和报文依赖关系数据;
以图论算法中的有向无环图构建报文依赖关系模型,其中,所述报文信息数据对应有向无环图中的各顶点,报文依赖关系数据对应有向无环图中的各边;
根据所述报文依赖关系模型,采用拓扑算法计算得到所有报文的处理顺序;
根据所述处理顺序对报文进行自动处理。
本发明的构思是:由于报文之间的依赖关系都是单向的(即如果报文A依赖于报文B,那么报文B则不可能依赖于报文A),且存在多种报文同时依赖于同一父级报文的情况,因此与图论算法中的有向无环图高度匹配,每一种报文对应有向无环图中的一个顶点,而报文之间的关系则对应有向无环图中的边。由此可以基于图论算法为报文构建报文依赖关系模型,并采用拓扑算法计算得到所有报文的处理顺序。这样得到的处理顺序不是简单的线性关系,而是全面、准确反映了报文之间的依赖关系,并且不受依赖关系以外的条件约束,因此基于该处理顺序允许相互之间无依赖关系的报文并行处理,同时还允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理。
本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法,其基于报文信息数据和报文依赖关系数据以图论算法中的有向无环图构建报文依赖关系模型,并采用拓扑算法计算得到所有报文的处理顺序,以根据所述处理顺序对报文进行自动处理。由此,该方法能对互联网保险领域的业务报文进行自动排序并按照该排序得到的处理顺序进行自动处理,此外,由于所述处理顺序全面、准确反映了报文之间的依赖关系,并且不受依赖关系以外的条件约束,因此基于该处理顺序的自动处理允许相互之间无依赖关系的报文并行处理,同时还允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理,以在低成本、低出错率地满足巨大的报文处理量需求的同时,大大提高报文处理效率。
进一步地,本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法中,将采集到的报文信息数据和报文依赖关系数据进行存储。
上述方案中,所述存储可以通过数据库,尤其是关系型数据库实现。
进一步地,本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法中,所述报文信息数据至少包括投保人报文、被保人报文、保单报文和账单报文。
本发明的另一目的是提供一种基于图论算法的互联网保险领域的业务报文自动处理系统,基于该系统能对互联网保险领域的业务报文进行自动排序并按照该排序得到的处理顺序进行自动处理,该处理允许相互之间无依赖关系的报文并行处理,同时还允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理,以在低成本、低出错率地满足巨大的报文处理量需求的同时,大大提高报文处理效率。
基于上述发明目的,本发明还提供了一种基于图论算法的互联网保险领域的业务报文自动处理系统,其包括:
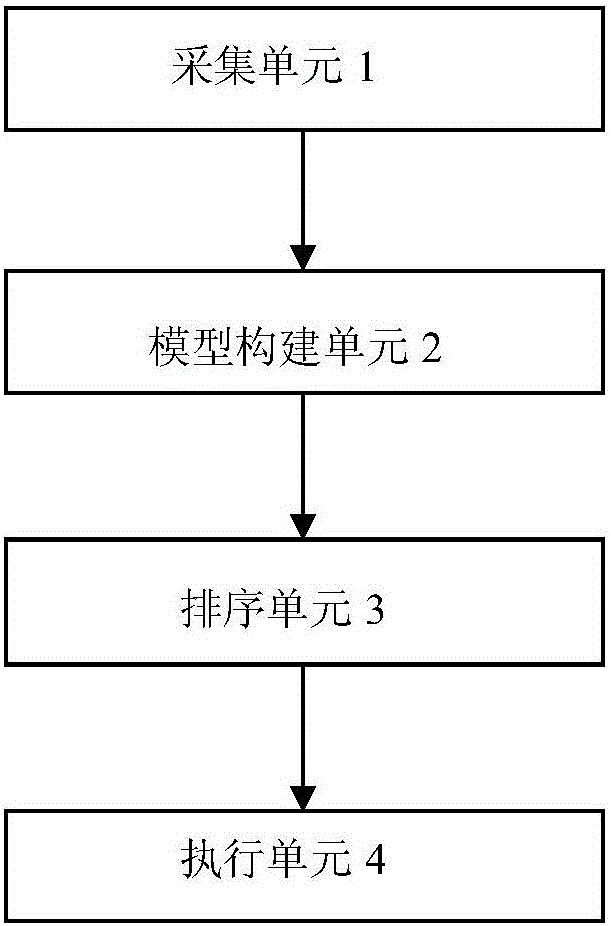
采集单元,其采集报文信息数据和报文依赖关系数据;
模型构建单元,其以图论算法中的有向无环图构建报文依赖关系模型,其中,所述报文信息数据对应有向无环图中的各顶点,报文依赖关系数据对应有向无环图中的各边;
排序单元,其根据所述报文依赖关系模型,采用拓扑算法计算得到所有报文的处理顺序;
执行单元,其根据所述处理顺序对报文进行自动处理。
本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统,其通过采集单元采集报文信息数据和报文依赖关系数据,并基于报文信息数据和报文依赖关系数据通过模型构建单元以图论算法中的有向无环图构建报文依赖关系模型,并通过排序单元采用拓扑算法计算得到所有报文的处理顺序,以通过执行单元根据所述处理顺序对报文进行自动处理。其中,所述采集单元、模型构建单元、排序单元以及执行单元可以是具有相应功能的程序模块,通过执行程序模块中的程序实现相应功能,其中,采集单元可通过数据库,尤其是关系型数据库实现。本发明的系统与上述本发明的方法相对应,因此,本发明的系统能对互联网保险领域的业务报文进行自动排序并按照该排序得到的处理顺序进行自动处理,并且基于该处理顺序的自动处理允许相互之间无依赖关系的报文并行处理,同时还允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理,以在低成本、低出错率地满足巨大的报文处理量需求的同时,大大提高报文处理效率。
进一步地,本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统中,还包括存储单元,其对采集到的报文信息数据和报文依赖关系数据进行存储。
上述方案中,存储单元可以是具有相应功能的程序模块,通过安装有该程序模块的计算机执行该程序模块中的程序实现相应功能。上述方案中,采集单元和存储单元可通过数据库,尤其是关系型数据库实现。
进一步地,本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统中,所述报文信息数据至少包括投保人报文、被保人报文、保单报文和账单报文。
本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法,其相对于现有技术中的线性排序和自动处理方法,具有以下优点和有益效果:
(1)本发明中的处理顺序全面、准确反映了报文之间的依赖关系,并且不受依赖关系以外的条件约束。
(2)基于本发明中的处理顺序的自动处理允许相互之间无依赖关系的报文并行处理。
(3)基于本发明中的处理顺序的自动处理允许当某一环节报文出现异常时自动挑选出受该环节报文依赖关系影响的报文进行重新处理。
(4)在低成本、低出错率地满足巨大的报文处理量需求的同时,大大提高报文处理效率。
本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统,其同样具有上述优点和有益效果。
附图说明
图1为本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法的流程示意图。
图2为本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统在一种实施方式下的结构示意图。
图3为本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统在另一种实施方式下的结构示意图。
图4为图3所示系统的一种工作流程示意图。
图5~图8为图4所示流程中生成的数据结构示意图。
图9为图4所示流程中生成的处理顺序示意图。
具体实施方式
下面将结合说明书附图和具体的实施例来对本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法和系统进行进一步地详细说明,但是该详细说明不构成对本发明的限制。
图1显示了本发明所述的基于图论算法的互联网保险领域的业务报文自动处理方法的流程。如图1所示,该基于图论算法的互联网保险领域的业务报文自动处理方法包括:
采集报文信息数据和报文依赖关系数据;
以图论算法中的有向无环图构建报文依赖关系模型,其中,报文信息数据对应有向无环图中的各顶点,报文依赖关系数据对应有向无环图中的各边;
根据上述报文依赖关系模型,采用拓扑算法计算得到所有报文的处理顺序;
根据上述处理顺序对报文进行自动处理。
在某些实施方式中,将采集到的报文信息数据和报文依赖关系数据进行存储。其中,存储可以通过数据库,尤其是关系型数据库实现。
在某些实施方式中,报文信息数据至少包括投保人报文、被保人报文、保单报文和账单报文。
图2显示了本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统在一种实施方式下的结构示意图。如图2所示,该基于图论算法的互联网保险领域的业务报文自动处理系统包括:采集单元1,其采集报文信息数据和报文依赖关系数据;模型构建单元2,其以图论算法中的有向无环图构建报文依赖关系模型,其中,报文信息数据对应有向无环图中的各顶点,报文依赖关系数据对应有向无环图中的各边;排序单元3,其根据报文依赖关系模型,采用拓扑算法计算得到所有报文的处理顺序;执行单元4,其根据该处理顺序对报文进行自动处理。其中,采集单元1、模型构建单元2、排序单元3以及执行单元4是具有相应功能的程序模块,通过安装有该程序模块的计算机执行该程序模块中的程序实现相应功能。本实施方式中,采集单元1通过关系型数据库实现。
图3显示了本发明所述的基于图论算法的互联网保险领域的业务报文自动处理系统在另一种实施方式下的结构示意图。如图3所示,该基于图论算法的互联网保险领域的业务报文自动处理系统在图2所示系统的基础上,还包括存储单元5,其对采集到的报文信息数据和报文依赖关系数据进行存储。其中,存储单元5是具有相应功能的程序模块,通过安装有该程序模块的计算机执行该程序模块中的程序实现相应功能。本实施方式中,采集单元1、和存储单元5通过关系型数据库实现。
本发明所述系统在某些实施方式中,报文信息数据至少包括投保人报文、被保人报文、保单报文和账单报文。
图4显示了图3所示系统的一种工作流程。如图4所示,该实施方式的基于图论算法的互联网保险领域的业务报文自动处理系统的工作流程包括:
步骤110:通过采集单元1采集报文信息数据和报文依赖关系数据,并且通过存储单元5将该报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中。其中,报文关系表中每条记录都存放了两个具有依赖关系的报文标识。当添加新的报文信息数据时,则需要在报文信息表中加入该报文的记录和在报文关系表中添加该报文与所有已有报文的一对一的依赖关系。
步骤120:通过模型构建单元2以图论算法中的有向无环图构建报文依赖关系模型,其中,报文信息数据对应有向无环图中的各顶点,报文依赖关系数据对应有向无环图中的各边。
步骤130:通过排序单元3根据上述报文依赖关系模型,采用拓扑算法计算得到所有报文的处理顺序;
步骤140:通过执行单元4根据上述处理顺序对报文进行自动处理。
下面给出基于图4流程的一个具体实施例。图5~图8显示了图4所示流程中生成的数据结构;图9显示了图4所示流程中生成的处理顺序。
结合参考图4,该实施例按照上述图4对应流程对报文A~F进行处理,其中:
通过步骤110采集和存储报文A~F的报文信息数据和报文依赖关系数据,包括:
步骤111:将报文A的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中。
步骤112:将报文B的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中,其中,报文B依赖于报文A,因此设定报文B的依赖关系为“报文A→报文B”。
步骤113:将报文C的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中,其中,报文C也依赖于报文A,因此设定报文C的依赖关系为“报文A→报文C”。
步骤114:将报文D的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中,其中,报文D同时依赖于报文B和报文C,因此设定报文D的依赖关系为“报文B→报文D,报文C→报文D”。
步骤115:将报文E的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中,其中,报文E不依赖于当前存在的任意一个报文,却又被报文C依赖,因此将报文E的依赖关系设定为“报文E→报文C”。
步骤116:将报文F的报文信息数据和报文依赖关系数据分别以报文信息表和报文关系表的形式存储在关系型数据库中,其中,报文F被报文C依赖且依赖于报文E,因此将报文F的依赖关系设定为“报文E→报文F,报文F→报文C”。
通过步骤120将步骤110存储的报文信息数据和报文依赖关系数据映射到如图5的报文依赖关系模型中有向无环图的数据结构具体实现中。
通过步骤130得到报文A~F的处理顺序,其计算原理是重复执行“选出所有不依赖于其他报文的报文作为当前并行序列,同时将其从当前数据结构中移除”,按照先后顺序排列上述并行序列,得到最终的处理顺序,具体过程包括:
步骤131:选出当前所有不依赖于其他报文的报文A、报文E作为当前并行序列a1,同时将其从如图5的数据结构中移除,剩下的数据结构如图6所示。
步骤132:选出当前所有不依赖于其他报文的报文B、报文F作为当前并行序列a2,同时将其从如图6的数据结构中移除,剩下的数据结构如图7所示。
步骤133:选出当前所有不依赖于其他报文的报文C作为当前并行序列a3,同时将其从如图7的数据结构中移除,剩下的数据结构如图8所示。
步骤134:选出当前所有不依赖于其他报文的报文D作为当前并行序列a4,同时将其从如图8的数据结构中移除。
步骤135:所有报文已排序,输出如图9所示的处理顺序:并行序列a1(报文A、报文E)→并行序列a2(报文B、报文F)→并行序列a3(报文C)→并行序列a4(报文D)。
通过步骤140对报文A~F进行自动处理。
需要说明的是,当整个报文处理流程中因某个报文中的数据出现异常需要重新执行时,只需重复步骤131~步骤135,然后将得到的处理顺序中从出现过异常的报文所在的并行序列到最后一个并行序列进行重新处理即可。
需要注意的是,以上列举的仅为本发明的具体实施例,显然本发明不限于以上实施例,随之有着许多的类似变化。本领域的技术人员如果从本发明公开的内容直接导出或联想到的所有变形,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!