样本区域合并技术的制作方法
技术领域
本发明是有关于用于二维采样信息信号(诸如视频或静止图像)的编码方案。
背景技术:
在影像及视频编码中,图像或针对该图像的特定样本数组集合通常分解成区块,该区块与特定编码参数关联。图像通常是由多个样本数组组成。此外,一图像也可关联额外辅助样本数组,该样本数组(例如)表明透明信息或深度图。一图像的样本数组(包括辅助样本数组)也可集合成一或多个所谓的平面群组,此处各个平面群组是由一或多个样本数组组成。一图像的平面群组可独立地编码,或者,若该图像关联多于一个平面群组,则利用来自同一图像的其它平面群组的预测进行编码。各平面群组通常分解成多个区块。该区块(或样本数组的相对应区块)是通过跨图像预测或图像内预测而预测。各区块可具有不同尺寸且可以是正方形或矩形。一图像分割成多个区块可通过语法固定,或可(至少部分地)在位流内部信号通知。经常发送的语法元素信号通知针对区块细分的预定大小。这种语法元素可表明一区块是否且如何细分成更小型区块及相关联的编码参数,例如用于预测目的。针对一区块(或样本数组的相对应区块)的全部样本,相关联的编码参数的解码是以某个方式表明。在该实例中,在一区块的全部样本是使用相同预测参数集合预测,该预测参数诸如是参考指数(标识在已编码图像集合中的一参考图像)、运动参数(表明一参考图像与该目前图像间的区块运动的测量值)、表明插值滤波器的参数、内部预测模式等。运动参数可以由具有一水平分量及一垂直分量的位移向量表示,或通过高阶运动参数表示,诸如包括六个分量的仿射运动参数。也可能多于一个特定预测参数集合(诸如参考指数及运动参数)是与单一区块相关联。该种情况下,针对此特定预测参数的各集合,产生针对该区块(或样本数组的相对应区块)的单一中间预测信号,并且最终预测信号是由包括叠加中间预测信号的一组合所建立。相对应加权参数及可能地,也包括一常数偏移(加至该加权和)可针对一图像或一参考图像或一参考图像集合为固定,或其包括在针对相对应区块的预测参数集合中。原始区块(或样本数组的相对应区块)与其预测信号之间的差,也称作为残差信号,该差通常被变换及量化。经常,施加二维变换至该残差信号(或针对该残差区块的相对应样本数组)。针对变换编码,已经使用特定预测参数集合的区块(或样本数组的相对应区块)可在施加变换之前被进一步分裂。变换区块可等于或小于用于预测的区块。也可能是,一变换区块包括多于一个用来预测的区块。不同变换区块可具有不同大小,变换区块可表示正方或矩形区块。在变换后,所得变换系数经量化,获得所谓的变换系数位准。变换系数位准及预测参数以及若存在时,细分信息被熵编码。
在影像及视频编码标准中,由语法所提供的将一图像(或一平面群组)细分成区块的可能性极为有限。通常只能规定是否(以及可能地如何)具有预先界定尺寸的一区块可细分成更小型区块。举个实例,H.264的最大区块尺寸为16×16。16×16区块也称作为宏区块,在第一步骤,各图像分割成宏区块。针对各个16×16宏区块,可信号通知其是否编码成16×16区块,或两个16×8区块,或两个8×16区块,或四个8×8区块。若16×16区块被细分成四个8×8区块,则各个8×8区块可编码为一个8×8区块,或两个8×4区块,或两个4×8区块,或四个4×4区块。在当前影像及视频编码标准中表明分割成区块的小集合可能性具有的优点是用于信号通知细分信息的侧边信息率可保持较小,但具有的缺点是针对该区块传输预测参数所需的位率相当大,稍后详述。信号通知预测信息的侧边信息率确实通常表示针对一区块的显著大量总位率。当这种侧边信息降低时,编码效率增高,例如可通过使用较大型区块大小来实现侧边信息降低。视频序列的实际影像或图像是由具有特定性质的任意形状对象组成。举个实例,此对象或对象部分是以独特纹理或独特运动为其特征。通常相同预测参数集合可应用于此对象或对象部分。但对象边界通常并不吻合大型预测区块(例如,按照H.264的16×16宏区块)可能的区块边界。
编码器通常决定细分(在有限种可能性集合中)导致特定率失真成本测量的最小化。针对任意形状对象,如此可能导致大量的小区块。并且由于此小区块是与需要传输的一预测参数集合相关联,故侧边信息率变成总位率的一大部分。但由于小区块中的数个仍然表示同一对象或对象一部分的区,故对多个所得区块的预测参数为相同或极为相似。
换言之,一图像细分或拼贴成较小型部分或拼贴块或区块实质上影响编码效率及编码复杂度。如前文摘述,一图像细分成多个较小区块允许编码参数的空间更精细设定,藉此允许此编码参数更佳适应于图像/视频材料。另一方面,以更细粒度设定编码参数对通知解码器有关需要的设定值的所需侧边信息量加诸更高负荷。再者,须注意编码器(进一步)空间上细分图像/视频成为区块的任何自由度,剧增可能的编码参数设定值量,及因而通常使得针对导致最佳率/失真折衷的编码参数设定值的搜寻更困难。
技术实现要素:
一个目的是提供一种用以编码表示空间采样二维信息信号(诸如但非限于视频图像或静止图像)的信息样本数组的编码方案,该方案允许达成在编码复杂度与可达成的率失真比之间更佳的折衷,及/或达成更佳率失真比。
依据一实施例,该信息样本数组所细分而成的一单纯连接区有利的合并或分组是以较少数据量编码。为了达成此项目的,针对单纯连接区,界定一预定相对位置关系,其允许针对一预定单纯连接区而识别在多个单纯连接区内部与该预定单纯连接区具有预定相对位置关系的单纯连接区。换言之,若该数目为零,则在该数据流内部可能不存在有针对该预定单纯连接区的一合并指标。此外,若与该预定单纯连接区具有预定相对位置关系的单纯连接区数目为1,则可采用该单纯连接区的编码参数,或可用来预测针对该预定单纯连接区的编码参数而无需任何额外语法元素。否则,即,若与该预定单纯连接区具有预定相对位置关系的单纯连接区数目为大于1,则可抑制一额外语法元素的引入,即便与这些经识别的单纯连接区相关联的编码参数彼此为相同亦复如此。
依据一实施例,若该邻近单纯连接区的编码参数彼此为不等,则一参考邻近识别符可识别与该预定单纯连接区具有预定相对位置关系的单纯连接区数目的一适当子集,及当采用该编码参数或预测该预定单纯连接区的编码参数时使用此一适当子集。
依据其它实施例,通过递归地多重分割将表示该二维信息信号的空间采样的一样本区而空间细分成多个具有不同大小的单纯连接区是取决于在该数据流中的一第一语法元素子集而执行的,接着为取决于与该第一子集不相连接的在该数据流内的一第二语法元素子集而组合空间邻近单纯连接区,来获得将该样本数组中间细分成不相连接的单纯连接区集合,其联合为该多个单纯连接区。该中间细分是用在从该数据流重建该样本数组时。如此允许使得就该细分而言的最佳化较为不具关键重要性,原因在于实际上过细的细分可通过随后的合并加以补偿。此外,细分与合并的组合允许达成单独通过递归多重分割不可能达成的中间细分,因此通过使用不相连接的语法元素集合执行细分与合并的级联(concatenation)允许有效或中间细分更佳地调整适应该二维信息信号的实际内容。与其优点相比较,由用于指示合并细节的额外语法元素子集所导致的额外开销是可忽略的。
依据一个实施例,首先表示空间采样信息信号的信息样本数组在空间上置于树根区,然后根据抽取自一数据流的多元树细分信息,通过递归地多次分割该树根区的子集,而至少将该树根区的一子集分割成不同尺寸的更小型单纯连接区。为了允许就率失真意义上,找出以合理编码复杂度的过度细小细分与过度粗大细分间的良好折衷,信息样本数组进行空间分割成的树根区的最大区尺寸是含括在该数据流内且在解码端从该数据流抽取。据此,解码器可包括一抽取器,其被配置为从数据流抽取最大区尺寸及多元树细分信息;一细分器,其被配置为将表示空间采样信息信号的一信息样本数组空间分割成最大区尺寸的树根区,及依据该多元树细分信息,将该树根区的至少一个子集通过递归地多重分区该树根区的该子集而细分成更小型单纯连接不同尺寸区;及一重建器,其被配置为使用该细分而将来自该数据流的信息样本数组重建成较小型单纯连接区。
依据一个实施例,数据流也含有高达树根区子集经历递归地多重分区的最高阶层式层级。通过此办法,多元树细分信息的信号通知变得更容易且需更少编码位。
此外,重建器可被配置为以取决于中间细分的粒度,执行下列措施中的一者或多者:至少在内预测模式及跨预测模式中决定欲使用哪一个预测模式;从频域变换至空间域,执行及/或设定跨预测的参数;执行及/或设定针对用于内预测的参数。
此外,抽取器可被配置为以深度优先遍历顺序而从数据流抽取与经分区的树区块的叶区相关联的语法元素。通过此种办法,抽取器可开发已经编码的邻近叶区的语法元素统计学量,其具有比使用宽度优先遍历顺序更高的机率。
依据另一个实施例,使用又一细分器来依据又一多元树细分信息来将该较小型单纯连接区的至少一个子集细分成又更小型单纯连接区。第一级细分可由重建器用来执行信息样本区的预测,而第二级细分可由重建器用来执行自频域至空间域的再变换。定义残差细分相对于预测细分为从属,使得总细分的编码较少耗用位;另一方面,由从属所得的残差细分的限制度及自由度对编码效率只有微小的负面影响,原因在于大部分具有相似运动补偿参数的图像部分比具有相似频谱性质的部分更大。
依据又另一实施例,又一最大区尺寸是含在该数据流内,又一最大区尺寸界定树根子区大小,该树根子区是在该树根子区的至少一子集依据又更多元树细分信息而细分成为又更小型单纯连接区的前先被分割。如此转而允许一方面预测细分的最大区尺寸的独立设定,及另一方面允许残差细分,如此可找出较佳率/失真折衷。
依据本发明的又另一实施例,数据流包括与形成该多元树细分信息的第二语法元素子集分离的第一语法元素子集,其中在该解码端的一合并器允许依据第一语法元素子集而组合空间邻近的多元树细分的小型单纯连接区来获得该样本数组的一中间细分。重建器可被配置为使用中间细分而重建样本数组。通过此方式,编码器更容易以发现的最佳率/失真折衷将有效细分调适为信息样本数组的性质的空间分布。举例言之,若最大区尺寸为大,则多元树细分信息可能因树根区变大而更复杂。但另一方面,若最大区尺寸为小,则更可能是邻近树根区是有关具有相似性质的信息内容,使得此树根区也可一起处理。合并填补前述极端间的此一间隙,通过此允许接近最佳化的粒度细分。从编码器观点,合并语法元素允许更轻松的或运算上更不复杂的编码程序,原因在于若编码器错误使用太精细的细分,则此误差可通过编码器随后补偿,通过由随后设定合并语法元素有或无只调整适应一小部分在合并语法元素设定前已经被设定的语法元素达成。
依据又另一实施例,最大区尺寸及多元树细分信息是用于残差细分而非预测细分。
用来处理表示空间采样信息信号的一信息样本数组的多元树细分的单纯连接区的一深度优先遍历顺序而非宽度优先遍历顺序是依据一实施例使用。通过由使用该深度优先遍历顺序,各个单纯连接区有较高机率来具有已经被遍历的邻近单纯连接区,使得当重建个别目前单纯连接区时,有关这些邻近单纯连接区的信息可被积极地利用。
当信息样本数组首先被分割成零层级的阶层式尺寸的树根区规则排列,然后再细分该树根区的至少一个子集成为不同大小的更小型单纯连接区时,重建器可使用锯齿形扫描来扫描该树根区,针对各个欲分区的树根区,以深度优先遍历顺序处理该单纯连接的叶区,随后又更以锯齿形扫描顺序步入下个树根区。此外,依据深度优先遍历顺序,具有相同阶层式层级的单纯连接的叶区也可以按照锯齿形扫描顺序遍历。如此,维持具有邻近单纯连接叶区的可能性增高。
依据一个实施例,虽然与多元树结构的节点相关联的标记是按照深度优先遍历顺序来循序排列,但标记的循序编码使用机率估算上下文,其针对在多元树结构的相同阶层式层级内部与多元树结构节点相关联的标记为相同,但针对在多元树结构的不同阶层式层级内部的多元树结构节点相关联的标记为不同,通过此允许欲提供的上下文数目间的良好折衷,及另一方面,调整适应标记的实际符号统计数字。
依据一个实施例,针对所使用的预定标记的机率估算上下文也是取决于依据深度优先遍历顺序在该预定标记之前的标记,且是对应于与该预定标记相对应的区具有预定相对位置关系的树根区的各区。类似于前述方面潜在的构想,使用深度优先遍历顺序保证高机率:已经编码的标记也包括与该预定标记对应的区相邻的区所对应的标记,该知晓可用来更优异地调适上下文用于该预定标记。
可用于设定针对一预定标记的上下文的标记可以是对应于位于该预定标记相对应区上区及/或左区的该标记。此外,用以选择上下文的标记可限于与属于预定标记相关联的节点相同阶层式层级的标记。
依据一个实施例,编码信号通知包括最高阶层式层级的指示及与不等于最高阶层式层级的节点相关联的一标记序列,各个标记表明相关联节点是否为中间节点或子节点,以及按照深度优先或宽度优先遍历顺序循序解码得自该数据流的标记序列,跳过最高阶层式层级的节点而自动地指向相同叶节点,因而降低编码率。
依据又一个实施例,多元树结构的编码信号通知可包括最高阶层式层级的指示。通过此方式,可能将标记的存在限于最高阶层式层级以外的阶层式层级,原因在于总而言之排除具有最高阶层式层级的区块的进一步分区。
在空间多元树细分属于一次多元树细分的叶节点及未经分区树根区的二次细分的一部分的情况下,用于编码二次细分标记的上下文可经选择使得该上下文针对与相等大小区相关联的标记为相同。
附图说明
下面,针对以下附图来描述本发明的优选实施例,其中:
图1显示依据本申请的一实施例编码器的方块图;
图2显示依据本申请的一实施例解码器的方块图;
图3A至图3C示意地显示四叉树细分的一具体实施例,其中图3A显示第一阶层式层级,图3B显示第二阶层式层级,及图3C显示第三阶层式层级;
图4示意地显示依据一实施例针对图3A至图3C的说明性四叉树细分的树结构;
图5A、图5B示意地显示图3A至图3C的四叉树细分及具有指示个别叶区块的指标的树结构;
图6A、图6B图示意地显示依据不同实施例表示图4的树结构及图3A至图3C的四叉树细分的二进制串或标记序列;
图7显示一流程图,显示依据一实施例由数据流抽取器所执行的步骤;
图8显示一流程图,例示说明依据又一实施例的数据流抽取器的功能;
图9A、图9B显示依据一实施例例示说明性四叉树细分的示意图,强调一预定区块的邻近候选区块;
图10显示依据又一实施例数据流抽取器的功能的一流程图;
图11示意地显示依据一实施例来自平面及平面群组中的一图像的组成且例示说明使用跨平面适应/预测的编码;
图12A及图12B示意地例示说明依据一实施例的一子树结构及相对应细分来描述继承方案;
图12C及12D示意地例示说明依据一实施例的一子树结构来描述分别使用采用及预测的继承方案;
图13显示一流程图,显示依据一实施例通过编码器实现继承方案所执行的步骤;
图14A及图14B显示一次细分及从属细分,来例示说明依据一实施例具体实现关联跨-预测的一继承方案的可能性;
图15显示一方块图例示说明依据一实施例关联该继承方案的一种解码方法;
图16示出了残差解码顺序;
图17显示依据一实施例解码器的方块图;
图18A至图18C显示一示意图,例示说明依据其它实施例不同的细分可能性;
图19显示依据一实施例编码器的方块图;
图20显示依据又一实施例解码器的方块图;及
图21显示依据又一实施例编码器的方块图。
具体实施方式
在后文附图的详细说明中,出现在数幅附图间的组件是以共通组件符号指示来避免重复说明此等组件。反而有关一个附图内部呈现的组件的解释也适用于其中出现个别组件的其它附图,只要在此其它附图所呈现的解释指出其中的偏差即可。
此外,后文说明始于就图1至图11解释的编码器及解码器实施例。就此附图呈现的实施例组合本申请的多个方面,但若个别对编码方案内部实施也优异,如此,就随后的附图,实施例将简短讨论前述个别方面,此实施例是以不同意义表示就图1及图11描述的实施例的摘要。
图1显示依据本发明的实施例的编码器。图1的编码器1010包括一预测器12、一残差前置编码器14、一残差重建器16、一数据流插入器18及一区块分割器20。编码器10是用以将一时空采样信息信号编码成一数据流22。时空采样信息信号例如可为视频,亦即一图像序列。各图像表示一影像样本数组。时空信息信号的其它实例例如包括由例如光时(time-of-light)相机拍摄的深度影像。又须注意一空间采样信息信号可包括每个帧或时间戳多于一个数组,诸如于彩色视频的情况下,彩色视频例如包括每个帧一亮度样本数组连同二个色度样本数组。也可能对信息信号的不同分量(亦即亮度及色度)的时间采样率可能不同。同理,适用于空间分辨率。视频也可伴随有额外空间采样信息,诸如深度或透明度信息。但后文描述的注意焦点将集中在此数组中的一者的处理来首先更明白了解本发明的主旨,然后转向多于一个平面的处理。
图1的编码器10被配置为形成数据流22,使得数据流22中的语法元素描述粒度在全图像与个别影像样本间的图像。为了达成此目的,分割器20被配置为将各图像24细分为不同大小的单纯连接区26。后文中,此区将简称为区块或子区26。
正如稍后详述,分割器20使用多元树细分来将图像24细分成不同尺寸的区块26。更详细地,后文就图1至图11所摘述的特定实施例大部分使用四叉树细分。正如稍后详述,分割器20内部可包括细分器28的级联用来将图像24细分成前述区块26,接着为合并器30其允许将此区块26组合成群组来获得位于图像24的未经细分与细分器28所界定的细分之间的有效细分或粒度。
如图1的虚线举例说明,预测器12、残差预编码器14、残差重建器16及数据流插入器18是在由分割器20所界定的图像细分上操作。举例言之,正如稍后详述,预测器12使用由分割器20所界定的预测细分来针对预测细分的个别子区而决定是否该个别子区应当经历具有依据所选用的预测模式针对该个别子区的相对应预测参数的设定值的图像内预测或跨图像预测。
残差预编码器14又转而使用图像24的残差子区来编码由预测器12所提供的图像24的预测残差。残差重建器16从残差预编码器14所输出的语法元素重建残差,残差重建器16也在前述残差细分上操作。数据流插入器18可利用前述分割,亦即预测及残差细分,来利用例如熵编码决定语法元素间的插入顺序及邻近关系用于将残差预编码器14及预测器12输出的语法元素插入数据流22。
如图1所示,编码器10包括一输入端32,此处该原始信息信号进入编码器10。一减法器34、残差预编码器14及数据流插入器18以所述顺序在数据流插入器18的输入端32与编码数据流22输出的输出端间串联。减法器34及残差预编码器14为预测回路的一部分,该预测回路是由残差重建器16、加法器及预测器12所包围,这些组件是以所述顺序在残差预编码器14的输出端与减法器34的反相输入端间串联。预测器12的输出端也是连接至加法器36的又一输入端。此外,预测器12包括直接连接至输入端32的一输入端且可包括又另一输入端,其也是经由可选的回路内滤波器38而连接至加法器36的输出端。此外,预测器12于操作期间产生侧边信息,因此预测器12的输出端也耦接至数据流插入器18。同理,分割器20包括一输出端其是连接至数据流插入器18的另一输入端。
已经描述编码器10的结构,其操作模式的进一步细节详述如后。
如前述,分割器20针对各个图像24决定如何将图像细分成小区26。依据欲用于预测的图像24的细分,预测器12针对相对应于此种细分的各个小区决定如何预测个别小区。预测器12输出小区的预测给减法器34的反相输入端,及输出给加法器36的又一输入端,及将反映预测器12如何从视频的先前编码部分获得此项预测的方式的预测信息输出给数据流插入器18。
在减法器34的输出端,如此获得预测残差,其中残差预编码器14是依据也由分割器20所规定的残差细分来处理此种预测残差。如在后文中对于图3A至图3B至图10进一步详细说明,由残差预编码器14所使用的图像24的残差细分可与预测器12所使用的预测细分相关,使各预测子区采用作为残差子区或更进一步细分成为更小的残差子区。但也可能有完全独立的预测及残差细分。
残差预编码器14将各个残差子区通过二维变换经历从空间至频域的变换,接着为或特有地涉及所得变换区块的所得变换系数量化,因此失真结果是来自于量化噪声。例如,数据流插入器18可使用(例如)熵编码而将描述前述变换系数的语法元素无损地编码成数据流22。
残差重建器16又使用再量化接着为再变换,将变换系数重新转换成残差信号,其中该残差信号是在加法器36内部组合由减法器34所得的预测来获得预测残差,通过此获得在加法器36的输出端一目前图像的重建部分或子区。预测器12可直接使用该重建图像子区用于内-预测,换言之,用来通过由从先前在邻近重建的预测子区外推法而用来预测某个预测子区。但通过由从邻近频谱预测目前子区频谱而在频域内部直接进行内-预测理论上也属可能。
用于交互预测,预测器12可使用先前已经编码及重建的图像版本,据此已经通过选择性回路内滤波器38滤波。滤波器38例如可包括一解区块滤波器或一适应性滤波器,具有适合优异地形成前述量化噪声的移转功能。
预测器12选择预测参数,显示通过由使用与图像24内部的原始样本比较而预测某个预测子区的方式。正如稍后详述,预测参数对各个预测子区可包括预测模式的指示,诸如图像内-预测及跨图像预测。在图像内-预测的情况下,预测参数也包括欲内-预测的预测子区内缘主要延伸的角度指示;及在跨图像预测的情况下,运动向量、运动图像指数及最终高次幂运动变换参数;及在图像内部及/或跨图像预测二者的情况下,用来过滤重建影像样本的选择性滤波信息,基于此可预测目前预测子区。
正如稍后详述,前述由分割器20所界定的细分实质上影响通过残差预编码器14、预测器12及数据流插入器18所能达成的最高率/失真比。在细分太细的情况下,由预测器12所输出欲插入数据流22的预测参数40需要过高编码速率,但通过预测器12所得的预测可能较佳,及通过残差预编码器14欲编码的残差信号可能较小使其可通过较少位编码。在细分太过粗大的情况下,则适用相反情况。此外,前述思考也以类似方式适用于残差细分:图像使用个别变换区块的较细粒度变换,结果导致用来运算变换的复杂度降低及结果所得变换的空间分辨率增高。换言之,较少残差子区允许在个别残差子区内部的内容的频谱分配更为一致。然而,频谱分辨率减低,显著系数及不显著系数(亦即量化为零)的比变差。换言之,变换粒度须调整适应局部图像内容。此外,独立于更细小粒度的正面效果,更细小粒度规则地增加需要的侧边信息量来指示对该解码器所选用的细分。正如稍后详述,后述实施例对编码器10提供极为有效的调整适应细分至欲编码信息信号内容,其通过指示数据流插入器18将细分信息插入数据流22来信号通知欲用在解码端的细分。细节显示如下。
但在以进一步细节定义分割器20的细分之前,依据本发明的实施例的解码器将就图2以进一步细节详细说明。
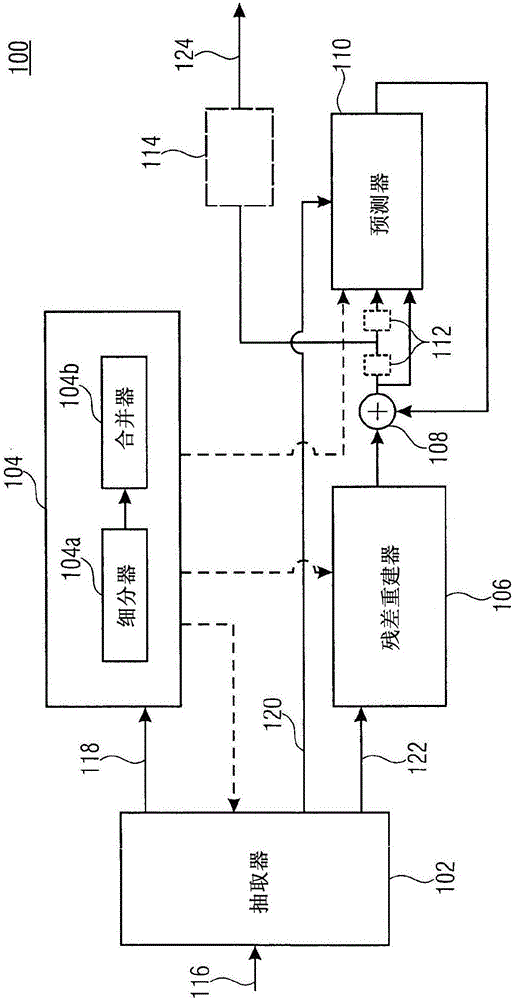
图2的解码器是以参考标号100指示及包括一抽取器102、一分割器104、一残差重建器106、一加法器108、一预测器110、一选择性回路内滤波器112及一选择性后滤波器114。抽取器102在解码器100的输入端116接收编码数据流,及从该编码数据流中抽取细分信息118、预测参数120及残差数据122,抽取器102分别将这些信息输出给图像分割器104、预测器110及残差重建器106。残差重建器106具有一输出端连接至加法器108的第一输入端。加法器108的另一输入端及其输出端是连接至一预测回路,在该预测回路中选择性回路内滤波器112及预测器110是以所述顺序串联从加法器108的输出端至预测器110的旁通路径,直接类似于前文于图1所述加法器36与预测器12间的连接,换言之,一者用于图像内-预测及另一者用于跨图像预测。加法器108的输出端或选择性回路内滤波器112的输出端可连接至解码器100的输出端124,此处重建信息信号例如是输出至再现装置。选择性后滤波器114可连接至导向输出端124的路径来改良在输出端124的重建信号的视觉印象的视觉质量。
概略言之,残差重建器106、加法器108及预测器110的作用类似图1的组件16、36及12。换言之,同样仿真前述图1组件的操作。为了达成此项目的,残差重建器106及预测器110由预测参数120,及通过图像分割器104依据得自抽取器102的细分信息118指明的细分进行控制,来以预测器12所进行或决定进行的相同方式预测该预测子区,及如同残差预编码器14的方式,以相同粒度重新变换所接收的变换系数。图像分割器104又仰赖细分信息118以同步方式重建由分割器20所选用的细分。抽取器可使用细分信息来控制数据抽取,诸如就上下文选择、邻近决定、机率估算、数据流语法的剖析等。
对前述实施例可进行若干偏差。某些偏差将在后文详细说明就细分器28所执行的细分及合并器30所执行的合并中述及,而其它偏差将就随后图12至图16做说明。在无任何障碍存在下,全部这些偏差皆可个别地或呈子集而施加至前文图1及图2的详细说明部分。举例言之,分割器20及104并未决定预测细分而只决定每个图像的残差细分。反而其也可能分别针对选择性回路内滤波器38及112决定滤波细分。其它预测细分或其它残差编码细分独立无关或具有相依性。此外,通过这些组件决定细分可能并非以逐帧为基础进行。反而对某个帧所进行的细分可重新使用或采用于某个数目的下列帧,单纯随后转移新细分。
在提供有关图像分割成为子区的进一步细节中,后文说明首先是把关注焦点集中在细分器28及104a推定所负责的细分部分。然后描述合并器30及合并器104b所负责进行的合并处理程序。最后,描述跨平面适应/预测。
细分器28及104a分割图像的方式使得一图像可分割成为可能具有不同大小的多个区块用于影像或视频数据的预测及残差编码。如前述,图像24可用作为一个或多个影像样本值数组。在YUV/YCbCr彩色空间的情况下,例如第一数组可表示亮度信道,而另二个数组表示色度信道。这些数组可具有不同维度。全部数组可分组为一或多个平面群组,各个平面群组是由一个或多个连续平面所组成,使得各平面包含在一个且唯一一个平面群组。后文适用于各个平面群组。一特定平面群组的第一数组可称作为此一平面群组的一次数组。可能的随后数组为从属数组。一次数组的区块分割可基于四叉树办法进行,正如稍后详述。从属数组的区块分割可基于一次数组的分割而导算出。
依据后述实施例,细分器28及104a被配置为将一次数组分割成为多个相等大小的方形区块,后文中称作为树区块。当使用四叉树时,树区块的边长典型为2的倍数,诸如16、32或64。但为求完整,须注意使用其它类型的树以及二元树或有任何叶数目的树皆属可能。此外,树的子代数目可取决于树的层级且取决于该树表示何种信号。
此外如前文说明,样本数组也可分别表示视频序列以外的其它信息,诸如深度图或光字段。为求简明,后文说明的关注焦点是聚焦在四叉树作为多元树的代表例。四叉树为在各个内部节点恰有四个子代的树。各个树区块组成一个一次四叉树连同在该一次四叉树的各个叶子的从属四叉树。一次四叉树决定该给定树区块的细分用来预测,而从属四叉树决定一给定预测树区块的细分用以残差编码。
一次四叉树的根节点是与完整树区块相对应。举例言之,图3A显示一树区块150。须记住,各个图像被分割成此种树区块150的列及行的规则格网,因而无间隙地覆盖样本数组。但须注意针对后文显示的全部区块细分,不含重叠的无缝细分不具关键重要性。反而邻近区块可彼此重叠,只要并无叶区块为邻近叶区块的适当子部分即可。
连同树区块150的四叉树结构,各个节点可进一步分割成为四个子节点,在一次四叉树的情况下,表示树区块150可分裂成四个子区块,具有树区块150的半宽及半高。在图3A中,这些子区块是以参考标号152a至152d指示。以相同方式,这些子区块各自进一步再分割成为四个更小的子区块具有原先子区块的半宽及半高。在图3B中,是针对子区块152c举例显示,子区块152c被细分成为四个小型子区块154a至154d。至目前为止,图3A至图3C显示树区块150如何首先被分割成为四个子区块152a至152d,然后左下子区块152c又被分割成四个小型子区块154a至154d;及最后如图3C所示,这些小型子区块的右上区块154b再度被分割成为四个区块,各自具有原始树区块150的八分之一宽度及八分之一高度,这些又更小的子区块标示以156a至156d。
图4显示如图3A至图3C所示基于四叉树分割实例的潜在树结构。树节点旁的数字为所谓的细分标记值,将于后文讨论四叉树结构信号通知时进一步详细说明。四叉树的根节点显示于该图顶端(标示为层级“0”)。此根节点于层级1的四个分支是与图3A所示四个子区块相对应。因这些子区块中的第三者又在图3B中被细分成其四个子区块,图4于层级1的第三节点也具有四个分支。再度,与图3C的第二(右上)子节点的细分相对应,有四个子分支连接在四叉树阶层层级2的第二节点。在层级3的节点不再进一步细分。
一次四叉树的各叶是与个别预测参数(亦即内部或跨、预测模式、运动参数等)可被指明的可变尺寸区块相对应。后文中,这些区块称做预测区块。特别,这些叶区块为图3C所示区块。简短回头参考图1及图2的说明,分割器20或细分器28决定如前文解说的四叉树细分。细分器152a-d执行树区块150、子区块152a-d、小型子区块154a-d等中哪一个被再细分或更进一步分割的决策,目标是获得如前文指示太过细小预测细分与太过粗大预测细分间的最佳折衷。预测器12转而使用所指明的预测细分来以依据预测细分的粒度或针对例如图3C所示区块表示的各个预测子区来决定前述预测参数。
图3C所示预测区块可进一步分割成更小型区块用以残差编码。针对各预测区块,亦即针对一次四叉树的各叶节点,通过一个或多个用于残差编码的从属四叉树决定相对应细分。例如,当允许16×16的最大残差区块大小时,一给定32×32预测区块将分割成四个16×16区块,各自是通过用于残差编码的从属四叉树决定。本实例中各个16×16区块是与从属四叉树的根节点相对应。
恰如一给定树区块细分成预测区块的情况所述,各预测区块可使用从属四叉树分解来分割成多个残差区块。一从属四叉树的各叶是对应于一个残差区块,对该残差区块可通过残差预编码器14而表明个别残差编码参数(亦即变换模式、变换系数等),该等残差编码参数又转而分别控制残差重建器16及106。
换言之,细分器28可配置为针对各图像或针对各图像群组决定一预测细分及一从属预测细分,可首先将图像分割成树区块150的规则排列,通过四叉树细分而递归地分区这些树区块的一子集来获得预测细分成预测区块,若在个别树区块未进行分区,则该预测区块可为树区块,或然后进一步细分这些预测区块的一子集,则为四叉树细分的叶区块;同理,若一预测区块是大于从属残差细分的最大尺寸,经由首先将个别预测区块分割成子树区块的规则排列,然后依据四叉树细分程序,将这些子树区块的一子集细分来获得残差区块,若在个别预测区块未进行分割成子树区块,则该残差区块可为预测区块,或若该个别子树区块未进行分割成又更小区,则该残差区块为子树区块,或为残差四叉树细分的叶区块。
如前文摘述,针对一次数组所选用的细分可映射至从属数组。当考虑与一次数组相同维度的从属数组时此点相当容易。但当从属数组维度是与一次数组维度不同时必须采用特殊措施。概略言之,在不同尺寸情况下,一次数组细分映射至从属数组可通过空间映射进行,亦即经由将一次数组细分的区块边界空间映射至从属数组。特别,针对各个从属数组,在水平方向及垂直方向可有定标因子,其决定一次数组对从属数组的维度比。从属数组分割成用于预测及残差编码的子区块可分别通过一次四叉树、一次数组的共同定位树区块各自的从属四叉树决定,从属数组所得树区块是通过相对定标因子定标。当水平方向及垂直方向的定标因子相异(例如在4:2:2色度次采样中)时,所得从属数组的预测区块及残差区块将不再是方形。此种情况下,可预先决定或适应性选择(针对整个序列,该序列中的一个图像或针对各个单一预测区块或残差区块)非方形残差区块是否应分裂成方形区块。例如,在第一情况下,编码器及解码器将在每次映射区块并非方形时在细分时同意细分成方形区块。在第二情况下,细分器28将经由数据流插入器18及数据流22向细分器104a信号通知该选择。例如,在4:2:2色度次采样的情况下,从属数组具有一次数组的半宽但等高,残差区块的高度为宽度的两倍。通过将此区块纵向分裂,可再度获得两个方形区块。
如前述,细分器28或分割器20分别经由数据流22向细分器104a信号通知基于四叉树的分割。为了达成此项目的,细分器28通知数据流插入器18有关针对图像24所选用的细分。数据流插入器又传输一次四叉树及二次四叉树的结构,因此,传输图像数组分割成为可变尺寸区块用于在数据流或位流22内部的预测区块或残差区块给解码端。
最小及最大可容许区块大小传输作为侧边信息且可依据不同图像而改变。或者,最小和最大容许区块大小可在编码器及解码器固定。这些最小及最大区块大小可针对预测区块及残差区块而有不同。针对四叉树结构的信号通知,四叉树必须被遍历,针对各节点必须表明此特定节点是否为四叉树的一叶节点(亦即相对应区块不再进一步细分),或此特定节点是否分支成其四个子节点(亦即相对应区块以对半尺寸分割成四个子区块)。
一个图像内部的信号通知是以光栅扫描顺序逐树区块进行,诸如由左至右及由上至下,如图5A于140显示。此种扫描顺序也可不同,例如以棋盘方式从右下至左上进行。在较佳实施例中,各树区块及因而各四叉树是以深度优先方式遍历用来信号通知该细分信息。
在较佳实施例中,不仅细分信息(亦即树结构),同时预测数据等(亦即与该树的叶节点相关联的有效负载)是以深度优先级传输/处理。如此进行的原因在于深度优先遍历具有优于宽度优先的优点。在图5B中,四叉树结构是以叶节点标示为a、b、…、j呈现。图5A显示所得区块分割。若区块/叶节点是以宽度优先顺序遍历,则获得下列顺序:abjchidefg。但按照深度优先顺序,该顺序为abc…ij。如从图5A可知,按照深度优先顺序,左邻近区块及顶邻近区块总是在目前区块之前传输/处理。如此,运动向量预测及上下文建模可以总使用对左及顶邻近区块所指明的参数来达成改良编码性能。对于宽度优先顺序,并非此种情况,原因在于区块j例如是在区块e、g及i之前传输。
结果,针对各个树区块的信号通知是沿一次四叉树的四叉树结构递归进行,使得针对各个节点传输一标记,表明相对应区块是否分裂成四个子区块。若此标记具有值“1”(用于“真”),则此信号通知程序对全部四个子节点递归地重复,亦即子区块以光栅扫描顺序(左上、右上、左下、右下)直到达到一次四叉树的叶节点。注意叶节点的特征为具有细分标记的值为“0”。针对节点是驻在一次四叉树的最低阶层式层级及如此对应于最小容许预测区块大小的情况,无须传输细分标记。用于图3A至图3C的实例,如图6A的190所示,首先将传输“1”表明树区块150被分裂成为其四个子区块152a-d。然后,以光栅扫描顺序200递归地编码全部四个子区块152a-d的细分信息。针对首二个子区块152a、b,将传输“0”,表明其未经细分(参考图6A中202)。用于第三子区块152c(左下),将传输“1”,表明此一区块是经细分(参考图6A中204)。现在依据递归办法,将处理此一区块的四个子区块154a-d。此处将针对第一子区块(206)传输“0”及针对第二(右上)子区块(208)传输“1”。现在图3C的最小子区块大小的四个区块156a-d将被处理。若已经达到本实例的最小容许区块大小,则无须再传输数据,原因在于不可能进一步细分。否则,表明这些区块不再进一步细分的“0000”将传输,如图6A于210指示。随后,将对图3B的下方两个区块传输“00”(参考图6A中212),及最后对图3A的右下区块传输“0”(参考214)。故表示四叉树结构的完整二进制串将为图6A所示。
图6A的此种二进制串表示型态的不同背景阴影是对应于基于四叉树细分的阶层关系中的不同层级。阴影216表示层级0(对应于区块大小等于原始树区块大小),阴影218表示层级1(对应于区块大小等于原始树区块大小一半),阴影220表示层级2(对应于区块大小等于原始树区块大小的四分之一),阴影222表示层级3(对应于区块大小等于原始树区块大小的八分之一)。相同阶层式层级(对应于在示例性二进制串表示型态中的相同区块大小及相同色彩)的全部细分标记例如可通过插入器18使用一个且同一个机率模型做熵编码。
注意针对宽度优先遍历的情况,细分信息将以不同顺序传输,显示于图6B。
类似于用于预测的各树区块的细分,各个所得预测区块分割成残差区块必须于位流传输。又针对作为侧边信息传输且可能依图像而改变的残差编码可有最大及最小区块大小。或针对残差编码的最大及最小区块大小在编码器及解码器可固定。在一次四叉树的各个叶节点,如图3C所示,相对应预测区块可分割成最大容许大小的残差区块。这些区块为从属四叉树结构用于残差编码的组成根节点。举例言之,若图像的最大残差区块大小为64×64及预测区块大小为32×32,则整个预测区块将对应于大小32×32的一个从属(残差)四叉树根节点。另一方面,若针对图像的最大残差区块为16×16,则32×32预测区块将由四个残差四叉树根节点所组成,各自具有16×16的大小。在各个预测区块内部,从属四叉树结构的信号通知是以光栅扫描顺序(左至右,上至下)逐根节点进行。类似于一次(预测)四叉树结构的情况,针对各节点,编码一标记,表明此一特定节点是否分裂成为四个子节点。然后若此标记具有值“1”,则针对全部四个相对应的子节点及其相对应子区块以光栅扫描顺序(左上、右上、左下、右下)递归地重复直到达到从属四叉树的叶节点。如同一次四叉树的情况,针对在从属四叉树最低阶层式层级上的节点无须信号通知,原因在于这些节点是对应于最小可能残差区块大小的区块而无法再进一步分割。
用于熵编码,属于相同区块大小的残差区块的残差区块细分标记可使用一个且同一个机率模型编码。
如此,依据前文就图3A至图6A所呈现的实例,细分器28界定用于预测的一次细分及用于残差编码目的的一次细分的具有不同大小区块的子从属细分。数据流插入器18是通过针对各树区块以锯齿形扫描顺序信号通知来编码一次细分,位序列是依据图6A建立,连同编码一次细分的最大一次区块大小及最大阶层式层级。针对各个如此界定的预测区块,相关联的预测参数已经含括在位流。此外,类似信息(亦即依据图6A的最大尺寸大小、最大阶层式层级及位序列)的编码可针对各预测区块进行,该预测区块的大小是等于或小于残差细分的最大尺寸大小;以及针对各个残差树根区块进行,其中预测区块已经被预先分割成超过对残差区块所界定的最大尺寸大小。针对各个如此界定的残差区块,残差数据是插入该数据流。
抽取器102在输入端116从该数据流抽取个别位序列及通知分割器104有关如此所得的细分信息。此外,数据流插入器18及抽取器102可使用前述顺序用在预测区块及残差区块间来传输额外语法元素,诸如通过残差预编码器14所输出的残差数据及通过预测器12所输出的预测参数。使用此种顺序的优点在于通过利用邻近区块已经编码/解码的语法元素,可选择针对某个区块编码个别语法元素的适当上下文。此外,同理,残差预编码器14及预测器12以及残差重建器106及预编码器110可以前文摘述的顺序处理个别预测区块及残差区块。
图7显示步骤的流程图,该步骤可通过抽取器102执行来当编码时以前文摘述的方式从数据流22抽取细分信息。在第一步骤中,抽取器102将图像24划分成为树根区块150。此步骤在图7是以步骤300指示。步骤300涉及抽取器102从数据流22抽取最大预测区块大小。此外或可替换地,步骤300可涉及抽取器102从数据流22抽取最大阶层式层级。
接下来,在步骤302中,抽取器102从该数据流解码一标记或一位。进行第一时间步骤302,抽取器102知晓个别标记为按照树根区块扫描顺序140属于第一树根区块150的位顺序的第一标记。因此该标记为具有阶层式层级0的标记,在步骤302中,抽取器102可使用与该阶层式层级0相关联的上下文建模来决定一上下文。各上下文具有个别机率估算用于与其相关联的标记的熵编码。上下文的机率估算可个别地适应上下文于个别上下文符号统计数字。例如,为了在步骤302决定用来解码阶层式层级0的标记的适当上下文,抽取器102可选择一上下文集合中的一个上下文,其是与阶层式层级0相关联,取决于邻近树区块的阶层式层级0标记,又更取决于界定目前处理树区块的邻近树区块(诸如顶及左邻近树区块)的四叉树细分的位串中所含的信息。
下一步骤中,亦即步骤304,抽取器102检查目前解码标记是否提示分区。若属此种情况,则抽取器102将目前区块(目前为树区块)分区,或在步骤306指示此一种分区给细分器104a,其于步骤308检查目前阶层式层级是否等于最大阶层式层级减1。举例言之,抽取器102例如也具有在步骤300从数据流所抽取的最大阶层式层级。若目前阶层式层级不等于最大阶层式层级减1,则在步骤310抽取器102将目前阶层式层级递增1及返回步骤302来从该数据流解码下一个标记。此时,在步骤302欲解码的标记属于另一个阶层式层级,因此依据一实施例,抽取器102可选择不同上下文集合中的一者,该集合是属于目前阶层式层级。该选择也可基于已经解码的邻近树区块依据图6A的细分位序列。
若解码一标记,及步骤304的检查揭示此标记并未提示目前区块的分区,则抽取器102前进步骤312来检查目前阶层式层级是否为0。若属此种情况,抽取器102就步骤314按照扫描顺序140的下一个树根区块进行处理,或若未留下任何欲处理的树根区块,则停止处理抽取细分信息。
须注意,图7的描述关注焦点是聚焦在只有预测细分的细分指示标记的解码,故实际上,步骤314涉及有关例如目前树区块相关联的其它仓(bin)或语法元素的解码。该种情况下,若存在有又一个或下一个树根区块,则抽取器102由步骤314前进至步骤302,从细分信息解码下一个标记,亦即有关新树区块的标记序列的第一标记。
在步骤312中,若阶层式层级不等于0,则操作前进至步骤316,检查是否存在有有关目前节点的其它子节点。换言之,当抽取器102在步骤316进行检查时,在步骤312已经检查目前阶层式层级为0阶层式层级以外的阶层式层级。如此又转而表示存在有亲代节点,其是属于树根区块150或小型区块152a-d或又更小区块152a-d等中的一者。目前解码标记所属的树结构节点具有一亲代节点,该亲代节点为该目前树结构的另外三个节点所共享。具有一共享亲代节点的这些子节点间的扫描顺序举例说明于图3A,针对阶层式层级0具有参考标号200。如此,在步骤316中,抽取器102检查是否全部四个子节点皆已经在图7的处理程序中被访问。若非属此种情况,亦即目前亲代节点有额外子节点,则图7的处理程序前进至步骤318,此处在目前阶层式层级内部依据锯齿形扫描顺序200的下一个子节点被访问,因此其相对应子区块现在表示图7的目前区块,及随后,在步骤302从有关目前区块或目前节点的数据流解码一标记。然而,在步骤316,若对目前亲代节点并无额外子节点,则图7的方法前进至步骤320,此处目前阶层式层级递减1,其中随后该方法是以步骤312进行。
通过执行图7所示步骤,抽取器102与细分器104a协力合作来在编码器端从数据流取回所选用的细分。图7的方法关注焦点集中在前述预测细分的情况。组合图7的流程图,图8显示抽取器102及细分器104a如何协力合作来从数据流取回残差细分。
特定言之,图8显示针对从预测细分所得各个预测区块,通过抽取器102及细分器104a分别所进行的步骤。如前述,这些预测区块是在预测细分的树区块150间依据锯齿扫描顺序140遍历,且例如图3C所示使用在各树区块150内部目前访问的深度优先遍历来通过树区块。依据深度优先遍历顺序,经过分区的一次树区块的叶区块是以深度优先遍历顺序访问,以锯齿形扫描顺序200访问具有共享目前节点的某个阶层式层级的子区块,以及在前进至此种锯齿形扫描顺序200的下一个子区块之前首先主要扫描这些子区块各自的细分。
用于图3C的实例,树区块150的叶节点间所得扫描顺序是以参考标号350显示。
用于目前访问的预测区块,图8的处理程序始于步骤400。在步骤400,标示目前区块的目前大小的内部参数设定为等于残差细分的阶层式层级0的大小,亦即残差细分的最大区块大小。须记住最大残差区块大小可小于预测细分的最小区块大小,或可等于或大于后者。换言之,依据一个实施例,编码器可自由选择前述任一种可能。
在下一步骤,亦即步骤402,执行检查有关目前访问区块的预测区块大小是否大于标示为目前大小的内部参数。若属此种情况,则可能是预测细分的一叶区块或预测细分的一树区块而未经任何进一步分区的目前访问预测区块是大于最大残差区块大小,此种情况下,图8的处理程序前进至图7的步骤300。换言之,目前访问的预测区块被分割成残差树根区块,此种目前访问预测区块内部的第一残差树区块的标记序列的第一标记是在步骤302解码等等。
但若目前访问预测区块具有大小等于或小于指示目前大小的内部参数,则图8的处理程序前进至步骤404,此处检查预测区块大小来决定其是否等于指示目前大小的内部参数。若为是,则分割步骤300可跳过,处理程序直接前进至图7的步骤302。
但若目前访问预测区块的预测区块大小是小于指示目前大小的内部参数,则图8的处理程序前进至步骤406,此处阶层式层级递增1,目前大小设定为新阶层式层级的大小,诸如以2分割(在四叉树细分情况下载二轴方向)。随后,再度进行步骤404的检查,通过步骤404及406所形成的回路效果为阶层式层级经常性地与欲分区的相对应区块大小相对应,而与具有小于或等于/大于最大残差区块大小的个别预测区块独立无关。如此,当在步骤302解码标记时,所进行的上下文建模是同时取决于该标记所指的阶层式层级及区块大小。针对不同阶层式层级或区块大小的标记分别使用不同上下文的优点在于机率估算极为适合标记值发生的实际机率分布,另一方面具有欲管理的适中上下文数目,因而减少上下文管理开销,以及增加上下文调整适应于实际符号统计数字。
如前文已述,有多于一个样本数组,这些样本数组可分组成一个或多个平面群组。例如进入输入端32的欲编码输入信号可为视频序列或静止影像的一个图像。如此该图像是呈一个或多个样本数组形式。在视频序列或静止影像的一图像编码上下文中,样本数组为指三个彩色平面,诸如红、绿及蓝,或指亮度平面及色度平面例如于YUV或YCbCr的彩色表示型态。此外,也可呈现表示α(亦即透明度)及/或3-D视频资料的深度信息的样本数组。多个这些样本数组可一起分组成为所谓的平面群组。例如,亮度(Y)可为只有一个样本数组的一个平面群组,及色度(诸如CbCr)可为有两个样本数组的另一个平面群组;或在另一实例中,YUV可为有三个矩阵的一个平面群组及3-D视频资料的深度信息可以是只有一个样本数组的不同平面群组。针对每个平面群组,一个一次四叉树结构可在数据流22内部编码用来表示分割成预测区块;及针对各个预测区块,二次四叉树结构表示分割成残差区块。如此,依据前述第一实例,亮度分量为一个平面群组,此处色度分量形成另一个平面群组,一个四叉树结构是针对亮度平面的预测区块,一个四叉树结构是针对亮度平面的残差区块,一个四叉树结构是针对色度平面的预测区块,及一个四叉树结构是针对色度平面的残差区块。但在前述第二实例中,可能有一个四叉树结构针对亮度及色度一起的预测区块(YUV),一个四叉树结构针对亮度及色度一起的残差区块(YUV),一个四叉树结构针对3-D视频资料的深度信息的预测区块,及一个四叉树结构针对3-D视频资料的深度信息的残差区块。
此外,在前文说明中,输入信号是使用一次四叉树结构分割成多个预测区块,现在描述这些预测区块如何使用从属四叉树结构而进一步细分成残差区块。依据另一实施例,细分并非结束在从属四叉树级。换言之,使用从属四叉树结构从细分所得的区块可能使用三元四叉树结构进一步细分。此种分割又转而用在使用额外编码工具的目的,其可能协助残差信号的编码。
前文描述关注焦点集中在分别通过细分器28及细分器104a进行细分。如前述,分别通过细分器28及104a进行细分可控制前述编码器10及解码器100的模块的处理粒度。但依据后文叙述的实施例,细分器228及104a分别接着为合并器30及合并器104b。但须注意合并器30及104b为选择性且可免除。
但实际上及正如稍后详述,合并器对编码器提供以将预测区块或残差区块中的若干者组合成群组或群簇的机会,使得其它模块或其它模块中的至少一部分可将这些区块群组一起处理。举例言之,预测器12可通过使用细分器28的细分最佳化来牺牲所测定的部分预测区块的预测参数间的偏差,及使用对全部这些预测区块共享的预测参数来取代,只要预测区块分组连同属于该组的全部区块的共享参数传输的信号通知就率/失真比意义上而言,比全部这些预测区块的预测参数个别地信号通知更具有展望性即可。基于这些共享预测参数,在预测器12及110取回预测的处理程序本身仍然是以预测区块逐一进行。但也可能预测器12及110甚至对整个预测区块群组一次进行预测程序。
正如稍后详述,也可能预测区块群组不仅使用针对一组预测区块的相同的或共享的预测参数,反而另外或替换地,允许编码器10发送针对此一群组的一个预测参数连同对属于此一群组的预测区块的预测残差,因而可减少用来信号通知此一群组的预测参数的信号通知开销。后述情况下,合并程序只影响数据流插入器18而非影响由残差预编码器14及预测器12所做的决策。但进一步细节正如稍后详述。然而,为求完整,须注意前述方面也适用于其它细分,诸如前述残差细分或滤波细分。
首先,样本集合(诸如前述预测区块及残差区块)的合并是以更一般性意义激励,亦即并非限于前述多元树细分。但随后的说明焦点将集中在前述实施例由多元树细分所得区块的合并。
概略言之,用于传输相关联的编码参数的目的合并与特定样本集合相关联的语法元素,允许于影像及视频编码应用上减少侧边信息率。举例言之,欲编码的信号的样本数组通常是分区成特定样本集合或样本集合,其可表示矩形区块或方形区块,或样本的任何其它集合,包括任意形状区、三角形或其它形状。在前述实施例中,单纯连接区为从多元树细分所得的预测区块及残差区块。样本数组的细分可通过语法固定;或如前述,细分也可至少部分在位流内部信号通知。为了将用于信号通知细分信息的侧边信息率维持为小,语法通常只允许有限数目的选择来导致简单的分区,诸如将区块细分成为更小型区块。样本集合是与特定编码参数相关联,其可表明预测信息或残差编码模式等。有关此议题的细节是如前文说明。针对各样本集合,可传输诸如用来表明预测编码及/或残差编码的个别编码参数。为了达成改良编码效率,后文描述的合并方面,亦即将二个或多个样本集合合并成所谓的样本集合群组,允许达成若干优点,正如稍后详述。举例言之,样本集合可经合并,使得此一群组的全部样本集合共享相同编码参数,其可连同群组中的样本集合中的一者传输。通过此方式,编码参数无须针对样本集合群组中的各个样本集合个别地传输,反而取而代之,编码参数只对整个样本集合群组传输一次。结果,用来传输编码参数的侧边信息减少,且总编码效率可改良。至于替代之道,一个或多个编码参数的额外精制可针对一样本集合群组中的一个或多个样本集合传输。精制可施加至一群组中的全部样本集合,或只施加至针对其传输的该样本集合。
后文进一步描述的合并方面也对编码器提供以形成位流22时的较高自由度,原因在于合并办法显著增加用来选择分区一图像样本数组的可能性数目。因编码器可在较多选项间选择,诸如用来减少特定率/失真测量值,故可改良编码效率。操作编码器有数种可能。在简单办法,编码器可首先决定样本数组的最佳细分。简短参考图1,细分器28将在第一级决定最佳细分。随后,针对各样本集合,检查是否与另一样本集合或另一样本集合群组合并减低了特定率/失真成本测量值。就此方面而言,与一合并样本集合群组相关联的预测参数可重新估算,诸如通过执行新的运动搜寻和估算;或已经针对共享样本集合及候选样本集合或用于合并的样本集合群组已经测定的预测参数可针对所考虑的样本集合群组而评估。更综合性办法中,特定率/失真成本测量值可对额外候选样本集合群组评估。
须注意后文描述的合并办法并未改变样本集合的处理顺序。换言之,合并构想可以一种方式具体实施,使得延迟不再增加,亦即各样本集合维持可在同一个时间瞬间解码而未使用合并办法。
举例言之,若通过减少编码预测参数数目所节省的位率是大于额外耗用在编码合并信息用来指示合并给解码端的位率,合并办法(正如稍后详述)导致编码效率增高。进一步须提及所述用于合并的语法延伸对编码器提供额外自由度来选择图像或平面群组分区成多个区块。换言之,编码器并非限于首先进行细分及然后检查所得区块中的若干者是否具有预测参数相同集合或类似集合。至于一个简单的替代之道,依据率-失真成本测量值,编码器首先决定细分,及然后针对各个区块编码器可检查与其邻近区块或相关联已经测定的区块群组中的一者合并是否减低率-失真成本测量值。如此,可重新估算与该新区块群组相关联的预测参数,诸如通过由进行新运动搜寻;或已经对目前区块及邻近区块或区块群组确定的该预测参数可针对新区块群组评估。合并信息以区块为单位进行信号通知。有效地,合并也可解译为针对目前区块的预测参数推论的结果,其中推论的预测参数是设定为等于邻近区块中的一者的预测参数。另外,针对一区块群组中的区块可传输残差。
如此,稍后描述的合并构想下方潜在的基本构想是通过将邻近区块合并成为一区块群组来减低传输预测参数或其它编码参数所需的位率,此处各区块群组是与编码参数诸如预测参数或残差编码参数的一个独特集合相关联。除了细分信息(若存在)外,合并信息也在位流内部信号通知。合并构想的优点为从编码参数的侧边信息减少导致编码效率增高。须注意此处所述合并方法也可延伸至空间维度以外的其它维度。举例言之,在数个不同视频图像的内部的一样本或区块集合群组可合并成一个区块群组。合并也可适用于4-压缩及光字段编码。
如此,简短回头参考前文图1至图8的说明,注意在细分后的合并程序是有优势的,而与细分器28及104a细分图像的特定方式独立无关。更明确言之,后者也可以类似于H.264的方式细分图像,换言之,将各图像细分成具有预定尺寸诸如16×16亮度样本或在数据流内部信号通知大小的矩形或方形聚集区块的规则排列,各宏区块具有与其相关联的若干编码参数,包括例如针对各宏区块界定分区成1、2、4或若干其它分区数目的规则子格用作为预测粒度以及位流中的相对应预测参数以及用来界定残差及相对应的残差变换粒度的分区用的分区参数。
总而言之,合并提供前文简短讨论的优点,诸如减少在影像及视频编码应用中的侧边信息率位。表示矩形或方形区块或任意形状区或任何其它样本集合诸如任何单纯连接区或样本的特定样本集合通常是连接特定编码参数集合;针对各样本集合,编码参数是含括在位流,编码参数例如表示预测参数其规定相对应样本集合是如何使用已编码样本加以预测。一图像样本数组分区成样本集合可通过语法固定,或可通过在该位流内部的相对应细分信息信号通知。针对该样本集合的编码参数可以预定顺序(亦即语法所给定的顺序)传输。依据合并功能,合并器30可针对一共享样本集合或一目前区块(诸如与一或多个其它样本集合合并的预测区块或残差区块),合并器30可信号通知入一样本集合群组。一群组样本集合的编码参数因此只须传输一次。在特定实施例中,若目前样本集合是与已经传输编码参数的一样本集合或既有样本集合群组合并,则目前样本集合的编码参数未传输。反而,目前样本集合的编码参数是设定为等于目前样本集合与其合并的该样本集合或该样本集合群组的编码参数。至于替代之道,编码参数中的一者或多者的额外精制可对目前样本集合传输。精制可应用于一群组的全部样本集合或只施加至针对其传输的该样本集合。
依据一实施例,针对各样本集合(诸如前述预测区块、前述残差区块或前述多元树细分的叶区块),全部先前编码/解码样本集合的集合是称作为“因果样本集合的集合”。例如参考图3C。本图显示的全部区块皆为某种细分结果,诸如预测细分或残差细分或任何多元树细分等,这些区块间定义的编码/解码顺序是以箭头350定义。考虑这些区块间的某个区块为目前样本集合或目前单纯连接区,其因果样本集合的集合是由沿着顺序350在目前区块前方的全部区块所组成。但须记住只要考虑后文有关合并原理的讨论,则未使用多元树细分的其它细分亦属可能。
可用来与目前样本集合合并的该样本集合于后文中称作为“候选样本集合的集合”,经常性为“因果样本集合的集合”的一子集。如何形成该子集的方式为解码器所已知,或可从编码器至解码器而在数据流或位流内部表明。若特定目前样本集合是经编码/解码,则此候选样本集合的集合非空,其是在编码器在数据流内部信号通知,或在解码器从该数据流导算该共享样本集合是否与本候选样本集合的集合中的一个样本集合合并,及若是,是与该样本集合中的哪一者合并。否则,合并无法用于本区块,原因在于候选样本集合的集合经常性为空。
有不同方式来测定因果样本集合的集合中将表示候选样本集合的集合的该子集。举例言之,候选样本集合的测定可基于目前样本集合内部的样本,其具有独特的几何形状定义,诸如矩形区块或方形区块的左上影像样本。始于此种独特几何形状定义样本,决定特定非零数目样本,表示此种独特几何形状定义样本的直接空间邻近样本。举例言之,此种特定非零数目样本包括目前样本集合的独特几何定义样本的上邻近样本及左邻近样本,故邻近样本的非零数目至多为2,或者若上或左邻近样本中的一者无法取得或是位于该图像外侧,则非零数目为1;或者,若缺失二邻近样本的情况下,则非零数目为0。
候选样本集合的集合可经决定来涵盖含有前述邻近样本的非零数目中的至少一者的那些样本集合。例如参考图9A。目前样本集合目前考虑为合并对象,须为区块X,而其几何形状独特定义样本须举例说明为左上样本,以400指示。样本400的顶及左邻近样本分别指示为402及404。因果样本几何的集合或因果区块的集合是以加阴影方式强调。因此这些区块中,区块A及B包括邻近样本402及404中的一者,这些区块形成候选区块集合或候选样本集合的集合。
依据另一实施例,用于合并目的所决定的候选样本集合的集合可额外地或排它地包括含有一特定非零数目样本的样本集合,该数目可为1或2,二者具有相同空间位置,但是含在不同图像,亦即先前编码/解码图像。举例言之,除了图9A的区块A及B之外,可使用先前编码图像的区块,其包括在样本400的相同位置的样本。通过此方式,注意只有上邻近样本404或只有左邻近样本402可用来定义前述邻近样本的非零数目。大致上,候选样本集合的集合可从在目前图像或其它图像内部先前经过处理的数据而导算出。导算可包括空间方向信息,诸如与目前图像的特定方向及影像梯度相关联的变换系数;或可包括时间方向信息,诸如邻近运动表示型态。由这些在接收器/解码器可利用的数据及在数据流内部的其它数据及侧边信息(若存在),可导算出候选样本集合的集合。
须注意候选样本集合的导算是通过在编码器端的合并器30及在解码器端的合并器104b并排执行。恰如前述,二者可基于对二者已知的预先界定的方式决定彼此独立无关的候选样本集合的集合;或编码器可在位流内部信号通知暗示线索,其是将合并器104b带到一个位置来以于在编码器端决定候选样本集合的集合的合并器30的相同方式,执行这些候选样本集合的导算。
正如稍后详述,合并器30及数据流插入器18合作来针对各样本集合传输一或多个语法元素,其表明该样本集合是否与另一样本集合合并,该另一样本集合又可为已经合并的样本集合群组的一部分,以及候选样本集合的该集合中的哪一者是用于合并。抽取器102转而据此抽取这些语法元素及通知合并器104b。特别,依据后文描述的特定实施例,针对一特定样本集合传输一或二个语法元素来表明合并信息。第一语法元素表明目前样本集合是否与另一样本集合合并。若第一语法元素表明该目前样本集合是与另一样本集合合并,唯有此种情况才传输的第二语法元素表明候选样本集合的集合中的哪一者用于合并。若导算出候选样本集合的集合为空,则可抑制第一语法元素的传输。换言之,若导算出的候选样本集合的集合并非空,则唯有此种情况才传输第一语法元素。唯有导算出的候选样本集合的集合含有多于一个样本集合时才传输第二语法元素,原因在于若在该候选样本集合的集合中只含有一个样本集合,则绝不可能做进一步选择。再者,若候选样本集合的集合包括多于一个样本集合,则第二语法元素的传输可被抑制;但若候选样本集合的集合中的全部样本集合是与同一个编码参数相关联时则否。换言之,第二语法元素唯有在一导算出的候选样本集合的集合中的至少两个样本集合是与不同编码参数相关联时才传输。
在该位流内部,一样本集合的合并信息可在与该样本集合相关联的预测参数或其它特定编码参数之前编码。预测参数或编码参数唯有在合并信息信号通知目前样本集合并未与任何其它样本集合合并时才传输。
例如,某个样本集合(即,一区块)的合并信息可在适当预测参数子集之后编码;或更一般性定义,已经传输与该个别样本集合相关联的编码参数。预测/编码参数子集可由一个或多个参考图像指数、或运动参数向量的一个或多个分量或参考指数、及运动参数向量的一个或多个分量等所组成。已经传输的预测参数或编码参数子集可用来从恰如前文说明已经导算的较大的候选样本集合的临时集合中导算出一候选样本集合的集合。举个实例,可计算目前样本集合的已编码预测参数及编码参数与先前候选样本集合的相对应预测参数或编码参数间的差值测量值或依据预定距离测量值的距离。然后,只有计算得的差值测量值或距离是小于或等于预定临界值或导算出的临界值的那些样本集合被含括在最终集合(亦即缩小的候选样本集合的集合)。例如参考图9A。目前样本集合须为区块X。有关本区块的编码参数的一子集须已经插入位流22。例如,假设区块X为预测区块,该种情况下,编码参数的适当子集可为此区块X的预测参数子集,诸如包括图像参考指数及运动映射信息(诸如运动向量)的一集合中的一子集。若区块X为残差区块,则编码参数的子集为残差信息子集,诸如变换系数或指示在区块X内部的显著变换系数位置的映射表。基于此项信息,数据流插入器18及抽取器102二者可使用此项信息来决定区块A及B中的一子集,该子集在本特定实施例中构成前述候选样本集合的初步集合。特定言之,因区块A及B属于因果样本集合的集合,其编码参数在区块X的编码参数为目前编码/解码时由编码器及解码器二者可利用。因此,使用不同办法的前述比较可用来排除候选样本集合A及B的初步集合中的任何数目区块。然后,所得缩小的候选样本集合的集合可如前文说明使用,换言之,用来决定合并指示器是否指示从该数据流中传输合并或从该数据流中抽取合并,取决于在该缩小候选样本集合的集合内部的样本集合数目以及第二语法元素是否必须在其中传输而定;或已经从该数据流中抽取出,具有第二语法元素指示在该缩小候选样本集合内部哪一个样本集合须为合并伴侣区块。换言之,针对一预定单纯连接区的个别合并语法元素的合并决策或传送可取决于与该预定单纯连接区具有预定相对位置关系的单纯连接区数目,且同时,具有与其相关联的编码参数其是满足与针对该预定单纯连接区的第一编码参数子集的预定关系,及采用或以抽取该预测残差进行预测可在针对该预定单纯连接区的该第二编码参数子集执行。换言之,与该预定单纯连接区具有预定相对位置关系的单纯连接区数目且同时具有与其相关联的编码参数其是满足与针对该预定单纯连接区的第一编码参数子集的预定关系中的一者或所识别的一者的仅只一编码参数子集可被采用来形成该预定单纯连接区的第二子集,或可用来预测该预定单纯连接区的第二子集。
前述距离相对于其做比较的前述临界值可为固定且为编码器及解码器二者所已知,或可基于计算得的距离而导算出,诸如不同值的中数或若干其它取中倾向等。此种情况下,无可避免地,缩小候选样本集合的集合须为候选样本集合的初步集合的适当子集。另外,唯有依据距离测量值为最小距离的那些样本集合才从该候选样本集合的初步集合中选出。另外,使用前述距离测量值,从该候选样本集合的初步集合中只选出恰好一个样本集合。在后述情况下,合并信息只须表明哪一个目前样本集合是欲与单一候选样本集合合并即可。
如此,候选区块集合可如后文就图9A所示而形成或导算出。始于图9A的目前区块X的左上样本位置400,在编码器端及解码器端导算出其左邻近样本402位置及其顶邻近样本404位置。如此,候选区块集合至多只有两个元素,亦即图9A的加画阴影的因果集合中含有两个样本位置中的一者(属于图9A的情况)中的区块为区块B及A。如此,候选区块集合只具有目前区块的左上样本位置的两个直接相邻区块作为其元素。依据另一实施例,候选区块集合可由在目前区块之前已经编码的全部区块给定,且含有表示目前区块任何样本的直接空间邻近样本的一个或多个样本。直接空间邻近限于目前区块的任何样本的直接左邻近样本及/或直接顶邻近样本及/或直接右邻近样本及/或直接底邻近样本。例如参考图9B显示另一区块细分。此种情况下,候选区块包括四个区块,亦即区块A、B、C及D。
另外,候选区块集合可额外地或排它地包括含有一个或多个样本(其是位在目前区块的任何样本相同位置,但含在不同图像,亦即已编码/解码图像)的区块。
又另外,候选区块集合表示前述区块集合的一子集,其是通过空间方向或时间方向的邻近关系决定。候选区块子集可经固定、信号通知或导算。候选区块子集的导算可考虑在该图像或其它图像中对其它区块所做的决策。举个实例,与其它候选区块相同或极为相似的编码参数相关联的区块不可含括在候选区块集合。
后文对实施例的描述适用于含有目前区块的左上样本的左及顶邻近样本只有两个区块被考虑作为至多可能的候选者的情况。
若候选区块集合非空,则称作为merge_flag的一个标记被信号通知,表明目前区块是否与任何候选区块合并。若merge_flag是等于0(用于“假”),则此区块不会与其候选区块中的一者合并,通常传输全部编码参数。若merge_flag等于1(用于“真”),则适用后述者。若候选区块集合含有一个且只有一个区块,则此候选区块用于合并。否则,候选区块集合恰含二区块。若此二区块的预测参数为相同,则这些预测参数用于目前区块。否则(该二区块具有不同预测参数),信号通知称作为merge_left_flag的标记。若merge_left_flag是等于1(用于“真”),则含有目前区块的左上样本位置的左邻近样本位置的该区块是从该候选区块集合中被选出。若merge_left_flag是等于0(用于“假”」),则从该候选区块集合中选出另一(亦即顶邻近)区块。所选定区块的预测参数是用于目前区块。
就合并摘述前述实施例中的数者,参考图10显示通过抽取器102执行来从进入输入端116的数据流22中抽取合并信息所进行的步骤。
处理始于450,识别针对目前样本集合或区块的候选区块或样本集合。须记住,区块的编码参数是以某个一维顺序而在数据流22内部传输,及据此,图10是指针对目前访问的样本集合或区块取回合并信息的方法。
如前述,识别及步骤450包括基于邻近方面而在先前解码区块(亦即因果区块集合)中的识别。例如,那些邻近区块可指向候选者,候选者含有于空间或时间上在目前区块X的一个或多个几何形状预定样本邻近的某个邻近样本。此外,识别步骤可包括两个级,亦即第一级涉及基于邻近恰如前述识别导致一初步候选区块集合;及第二级据此单纯该等区块为在步骤450前已经从数据流解码的指向区块,该区块已经传输的编码参数满足对目前区块X的编码参数的适当子集的某个关系。
其次,方法前进至步骤452,于该处决定候选区块数目是否大于零。若属此种情况,则在步骤454从数据流中抽取merge_flag。抽取步骤454可涉及熵解码。在步骤454用于熵解码merge_flag的上下文可基于属于例如候选区块集合或初步候选区块集合的语法元素,其中对语法元素的相依性可限于下述信息:属于关注集合的区块是否经历合并。选定上下文的机率估算可经调整适应。
但是,若候选区块数目决定为零452,图10方法前进至步骤456,此处目前区块的编码参数是从位流抽取,或在前述二级性识别替代之道的情况下,其中在抽取器102以区块扫描顺序(诸如图3C所示顺序350)处理下一区块进行后,其余编码参数。
参考步骤454,步骤454的抽取之后该方法前进步骤458,检查所抽取的merge_flag是否提示目前区块合并的出现或不存在。若未进行合并,则方法前进至前述步骤456。否则,方法以步骤460前进,包括检查候选区块数目是否等于1。若属此种情况,候选区块中某个候选区块指示的传输并非必要,因此图10方法前进至步骤462,据此目前区块的合并伴侣设定为唯一候选区块,其中在步骤464之后合并伴侣区块的编码参数是用来调整编码参数或目前区块的其余编码参数的调适或预测。以调适为例,目前区块遗漏的编码参数单纯是复制自合并伴侣区块。在另一种情况下,亦即预测的情况下,步骤464可涉及从数据流进一步抽取残差数据,有关目前区块的遗漏编码参数的预测残差的残差数据及得自合并伴侣区块的这些残差数据与这些遗漏编码参数的预测的组合。
但是,若候选区块数目在步骤460中决定为大于1,图10方法前进至步骤466,此处进行检查编码参数或编码参数的关注部分,亦即在目前区块的数据流内部尚未移转的部分相关联的子部分是彼此一致。若属此种情况,这些共享编码参数是设定为合并参考,或候选区块是在步骤468设定为合并伴侣,或个别关注编码参数是用在步骤464的调适或预测。
须注意,合并伴侣本身可以是已经信号通知合并的区块。在本例中,合并伴侣的经调适或经预测所得编码参数是用于步骤464。
但否则,在编码参数不同的情况下,图10方法前进至步骤470,此处额外语法元素是抽取自数据流,亦即该merge_left_flag。上下文的分开集合可用于熵解码此标记。用于熵解码merge_left_flag的上下文集合也可包括单纯一个上下文。在步骤470后,merge_left_flag指示的候选区块在步骤472设定为合并伴侣,及在步骤464用于调适或预测。在步骤464后,抽取器102以区块顺序处理下一个区块。
当然,可能有其它替代之道。例如,组合语法元素可在数据流内部传输,而非如前述分开语法元素merge_flag及merge_left_flag,组合语法元素信号通知合并处理程序。此外,前述merge_left_flag可在数据流内部传输,而与两个候选区块是否具有相同预测参数无关,通过此减低执行图10处理程序的运算开销。
如前文就例如图9B已述,多于二个区块可含括在候选区块集合。此外,合并信息,亦即信号通知一区块是否合并的一信息;若是,欲合并的候选区块可通过一个或多个语法元素信号通知。一个语法元素可表明该区块是否与前述候选区块中的任一者(诸如前述merge_flag)合并。尽在候选区块的集合非空时,才传输标记。第二语法元素可信号通知哪一个候选区块采用于合并,诸如前述merge_left_flag,但通常指示两个或多于两个候选区块间的选择。唯有第一语法元素信号通知目前区块欲合并候选区块中的一者时才可传输第二语法元素。第二语法元素又更唯有在候选区块集合含有多于一个候选区块时,及/或候选区块中的任一者具有与候选区块的任何其它者不同的预测参数时才传输。语法可取决于给予多少候选区块及/或不同预测参数如何与候选区块相关联。
信号通知欲使用候选区块中的哪些区块的语法可在编码器端及解码器端同时及/或并排设定。举例言之,若于步骤450识别三项候选区块选择,语法是选用为只有三项选择为可利用,例如在步骤470考虑用于熵编码。换言之,语法元素是经选择使得其符号字母表仅仅具有与所存在的候选区块的选择同样多个元素。全部其它选择机率可考虑为零,熵编码/解码可在编码器及解码器同时调整。
此外,如前文就步骤464所记,称作为合并方法结果的预测参数可表示与目前区块相关联的预测参数完整集合,或可表示这些预测参数的一子集,诸如针对其使用多重假说预测的区块的一个假说的预测参数。
如前述,有关合并信息的语法元素可使用上下文建模进行熵编码。语法元素可由前述merge_flag及merge_left_flag组成(或类似语法元素)。在一具体实例中,三个上下文模型或上下文中的一者可于步骤454用于编码/解码merge_flag。所使用的上下文模型指数merge_flag_ctx可如下导算出:若候选区块集合含有二个元素,则merge_flag_ctx的值是等于两个候选区块的merge_flag的值之和。但是,若候选区块集合含有一个元素,则merge_flag_ctx的值是等于此一候选区块的merge_flag值的两倍。因邻近候选区块的各merge_flag可为1或0,针对merge_flag有三个上下文可用。merge_left_flag可只使用单一机率模型编码。
但依据替代实施例,可使用不同上下文模型。例如,非二进制语法元素可映射至二进制符号序列(所谓的仓)。界定合并信息的若干语法元素或语法元素仓的上下文模型可基于已经传输的邻近区块的语法元素或候选区块数目或其它测量值而导算出,同时其它语法元素或语法元素仓能够以固定上下文模型编码。
有关前文区块合并的描述,须注意候选区块集合也可以对前述任何实施例所述的相同方式导算出而有下列修正:候选区块限于使用运动补偿预测或解译的区块。唯有那些元素可为候选区块集合的元素。合并信息的信号通知及上下文建模可以前述方式进行。
转向参考前述多元树细分实施例的组合及现在描述的合并方面,若该图像是通过使用基于四叉树细分结构而分割成不等大小的方形区块,例如merge_flag及merge_left_flag或其它表明合并的语法元素可与针对四叉树结构各个叶节点所传输的预测参数交插。再度考虑例如图9A。图9A显示一图像基于四叉树细分成可变大小预测区块的实例。最大尺寸的上二个区块为所谓的树区块,亦即其为最大可能尺寸的预测区块。该图中的其它区块是获得为其相对应树区块的细分。目前区块标示为“X”。全部阴影区块是在目前区块之前编/解码,故其形成因果区块集合。如在针对实施例中的一者候选区块集合的导算描述,唯有含有目前区块的左上样本位置的直接(亦即顶或左)邻近样本才可成为候选区块集合的成员。如此,目前区块合并区块“A”或区块“B”。若merge_flag是等于零(用于“假”),目前区块“X”并未合并二个区块中的任一者。若区块“A”及“B”具有相同预测参数,则无须做区别,原因在于与二个区块中的任一者合并将导致相同结果。因此,此种情况下,未传输merge_left_flag。否则,若区块“A”及“B”具有不同预测参数,merge_left_flag=1(用于“真”)将合并区块“X”与“B”,而merge_left_flag等于0(用于“假”)将合并区块“X”与“A”。在另一较佳实施例中,额外邻近(已经传输的)区块表示合并候选者。
图9B显示另一实例。此处目前区块“X”及左邻近区块“B”为树区块,亦即其具有最大容许区块大小。顶邻近区块“A”的大小为树区块大小的四分之一。属于因果区块集合的元素的区块加阴影。注意依据较佳实施例中的一者,目前区块“X”只可与二区块“A”或“B”合并,而不与任何其它顶相邻区块合并。在另一较佳实施例中,额外相邻(已经传输的)区块表示合并候选者。
继续描述有关依据本申请实施例如何处理图像的不同样本数组的该方面之前,须注意前文讨论有关多元树细分,及一方面信号通知及另一方面合并方面显然这些方面可提供彼此独立探讨的优点。换言之,如前文解释,多元树细分与合并的组合具有特定优点,但优点也来自于替代例,此处合并特征例如是以通过细分器30及104a进行细分具体实现,而非基于四叉树或多元树细分,反而是与这些宏区块规则分区成为更小型分区的宏区块细分相对应。另一方面,多元树细分连同位流内部的最大树区块大小传输的组合,以及多元树细分连同深度优先遍历顺序传送区块的相对应编码参数的使用具有与是否同时使用合并特征独立无关的优点。大致上,直觉地考虑当样本数组编码语法是以不仅允许细分一区块,同时也允许合并二个或多个细分后所获得的区块的方式扩展时,编码效率提高,可了解合并的优点。结果,获得一组区块其是以相同预测参数编码。此组区块的预测参数只须编码一次。此外,有关样本集合的合并,再度须了解所考虑的样本集合可为矩形区块或方形区块,该种情况下,合并样本集合表示矩形区块及/或方形区块的集合。另外,所考虑的样本集合为任意形状图像区,及合并样本集合表示任意形状图像区的集合。
后文描述的关注焦点在于当每个图像有多于一个样本数组时一图像的不同样本数组的处理,后文次描述中摘述的若干方面为与所使用的细分种类独立无关的优点,亦即与细分是否基于多元树细分独立无关且与是否使用合并独立无关。始于描述有关图像的不同样本数组的处理的特定实施例前,本实施例的主要议题是简短介绍每个图像不同样本数组的处理领域。
后文讨论的焦点集中在影像或视频编码应用用途中,在一图像的不同样本数组的区块间编码参数,特别一图像的不同样本数组间适应性预测编码参数的方式应用于例如图1及图2的编码器及解码器或其它影像或视频编码环境。如前述,样本数组表示与不同彩色分量相关联的样本数组,或与额外信息(诸如透明度信息或深度映射图像)关联的图像。与图像的彩色分量相关的样本数组也称作为彩色平面。后文描述的技术也称作为跨平面采用/预测,可用在基于区块的影像及视频编码器及解码器,通过此针对一图像的样本数组区块的处理顺序为任意顺序。
影像及视频编码器典型是设计用于编码彩色图像(静止图像或视频序列图像)。彩色图像包括多个彩色平面,其表示不同彩色分量的样本数组。经常,彩色图像被编码为一亮度平面及二个色度平面组成的样本数组集合,此处后者表明色差分量。在若干应用领域,也常见编码样本数组集合是由表示三原色红、绿、及蓝的样本数组的三个彩色平面组成。此外,为了改良彩色表示型态,彩色图像可由多于三个彩色平面组成。此外,一图像可与表明该图像的额外信息的辅助样本数组相关联。例如,这些辅助样本数组可以是表明相关彩色样本的透明度的样本数组(适合用于表明显示目的),或为表明深度图的样本数组(适合用来呈现多个视线,例如用于3D显示)。
在常规影像及视频编码标准(诸如H.264),彩色平面通常一起编码,因而特定编码参数(诸如宏区块及次宏区块预测模式、参考指数及运动向量)用于一区块的全部彩色分量。亮度平面可考虑为一次彩色平面,在位流中表明特定编码参数;而色度平面可视为二次平面,相对应的编码参数是从一次亮度平面推定。各亮度区块是与表示该图像中同一区的两个色度区块相关联。依据所使用的色度采样格式,色度样本数组可比针对一区块的亮度样本数组更小。针对由一亮度分量及二个色度分量所组成的各宏区块,使用在分区成更小型区块(若宏区块经细分)。针对由一亮度样本区块及二个色度样本区块所组成的各区块(可为宏区块本身或为宏区块的一子区块),采用相同预测参数集合,诸如参考指数、运动参数及偶尔内-预测模式。在常规视频编码标准的特定轮廓中(诸如在H.264的4:4:4轮廓),可独立编码一图像的不同彩色平面。在该配置中,可针对一宏区块的彩色分量或子区块分开选择宏区块分区、预测模式、参考指数及运动参数。常规编码标准或为全部彩色平面是使用相同特定编码参数(诸如细分信息及预测参数)集合一起编码,或为全部彩色平面是各自完全独立编码。
若彩色平面是一起编码,细分及预测参数的一个集合须用于一区块的全部彩色分量。如此确保侧边信息维持小量,但相比于独立编码,可能导致编码效率的降低,原因在于对不同色彩分量使用不同区块分解及预测参数,可能导致率-失真成本的减低。举例言之,针对色度分量使用不同运动向量或参考帧,可显著减少色度成分的残差信号能,及增高其总编码效率。若彩色平面是独立编码,则编码参数(诸如区块分区、参考指数及运动参数)可针对各个彩色分量分开选择来针对各个彩色分量最佳化编码效率。但不可能采用彩色分量间的冗余。特定编码参数的多元传输确实导致侧边信息率的增加(与组合编码相比),此种提高侧边信息率可能对总体编码效率造成负面影响。此外,在现有视频编码标准(诸如H.264)中,支持辅助样本数组是限于辅助样本数组是使用其本身的编码参数集合编码。
如此,至目前为止,所述全部实施例中,图像平面可如前述处理,但如前文讨论,多个样本数组的编码的总编码效率(可能与不同彩色平面及/或辅助样本数组有关)可能增高,此时可基于区块基准(例如)决定对于一区块的全部样本数组是否皆以相同编码参数编码,或是否使用不同编码参数。后文跨平面预测的基本构想例如允许以区块为基础做出此种适应性决策。例如基于率失真标准,编码器可选择针对一特定区块的全部或部分样本数组是否使用相同编码参数编码,或针对不同样本数组是否使用不同编码参数编码。通过针对一特定样本数组区块,信号通知从不同样本数组的已编码共同定位区块是否推论特定编码参数,也可达成此项选择。可能针对群组中的一图像配置不同样本数组,其也称作为样本数组群组或平面群组。各个平面群组可含有一图像的一个或多个样本数组。然后,在一平面群组内部的样本数组区块共享相同所选编码参数,诸如细分信息、预测模式及残差编码模式;而其它编码参数(诸如变换系数位准)是针对该平面群组内部的各个样本数组分开传输。一个平面群组是编码为一次平面群组,亦即从其它平面群组并未推定或预测编码参数。针对二次平面群组的各区块,适应性选择所选编码参数的一新集合是否传输,或所选编码参数是否从一次平面集合或另一二次平面集合推定或预测。针对特定区块所选编码参数是否是推定或预测的决策是含括在该位流中。跨平面预测允许侧边信息率与预测质量间的折衷,相比于由多个样本数组所组成的当前图像编码有更高自由度。优点为相对于由多个样本数组所组成的常规图像编码,编码效率改良。
平面内采用/预测可扩展影像或视频编码器,诸如前述实施例的影像或视频编码器,使得可针对一彩色样本数组或辅助样本数组的一区块或彩色样本数组及/或辅助样本数组的一集合,适应性选择所选定的编码参数集合是否从在同一个图像内其它样本数组的已经编码的共同定位区块推定或预测,或针对该区块所选定的编码参数集合是否分开编码而未参考同一个图像内部的其它样本数组的共通定位区块。所选定的编码参数集合是否针对一样本数组区块或多个样本数组区块推定或预测的决策可含括于该位流。与一图像相关联的不同样本数组无须具有相同大小。
如前述,与一图像相关联的样本数组(样本数组可表示彩色分量及/或辅助样本数组)可排列成二或多个所谓的平面群组,此处各平面群组是由一或多个样本数组组成。含在特定平面群组的样本数组无需具有相等大小。注意此种排列成平面群组包括各样本数组被分开编码的情况。
更明确言之,依据一实施例,针对一平面群组的各区块,适应性选择编码区块是否表明一区块如何从针对同一图像的不同平面群组的已经编码的共同定位区块推定或预测,或这些编码参数是否针对该区块分开编码。表明一区块如何预测的编码参数包括下列编码参数中的一者或多者:区块预测模式表明针对该区块使用哪一种预测(内预测、使用单一运动向量及参考图像的跨-预测、使用二个运动向量及参考图像的跨-预测、使用高阶的跨-预测,亦即非平移运动模型及单一参考图像、使用多个运动模型及参考图像的跨-预测),内-预测模式表明如何产生内-预测信号,一识别符表明多少预测信号组合来产生针对该区块的最终预测信号,参考指数表明哪一个(哪些)参考图像用于运动补偿预测,运动参数(诸如位移向量或仿射运动参数)表明预测信号如何使用参考图像而产生,一识别符表明参考图像如何被滤波来产生运动补偿预测信号。注意大致上,一区块可只与所述编码参数的一子集相关联。举例言之,若区块预测模式表明一区块为内-预测,则一区块的编码参数可额外地包括内-预测模式,但未表明编码参数,诸如表明如何产生跨-预测信号的参考指数及运动参数;或若区块预测模式表明跨-预测,则相关联的编码参数可额外地包括参考指数及运动参数,但未表明内-预测模式。
二个或多个平面群组中的一者可在该位流内部编码或指示作为一次平面群组。针对此一次平面群组的全部区块,表明预测信号如何产生的编码参数经传输而未参考同一图像的其它平面群组。其余平面群组被编码为二次平面群组。针对二次平面群组的各区块,传输一或多个语法元素,该语法元素信号通知表明该区块如何预测的编码参数是否从其它平面群组的共同定位区块推定或预测,或针对该区块是否传输这些编码参数的一新集合。一个或多个语法元素中的一者可称作为跨平面预测标记或跨平面预测参数。若语法元素信号通知未推定或预测相对应编码参数,则该区块的相对应编码参数的新集合在该位流内传输。若语法元素信号通知相对应编码参数是经推定或预测,则决定在所谓的参考平面群组中的共同定位区块。针对该区块的参考平面群组的指定可以多种方式组配。一个实施例中,特定参考群组是针对各个二次平面群组指定;此种指定可为固定,或可于高阶语法结构(诸如参数集合、存取单元报头、图像报头或片报头)中信号通知。
在第二实施例中,参考平面群组的指定是在位流内部编码,及通过针对一区块编码的一个或多个语法元素信号通知来表明所选定的编码参数是否经推定或预测或是否分开编码。
为了容易了解关联跨平面预测及后文详细说明实施例的前述可能,参考图11,示意地显示由三个样本数组502、504及506所组成的一图像500。为求更容易了解,图11只显示样本数组502-506的子部。样本数组显示为彷佛其在空间中彼此对齐,使得样本数组502-506彼此沿方向508重叠,样本数组502-506的样本沿方向508突起结果导致全部样本数组502-506的样本是彼此在空间上正确定位。换言之,平面502及506是沿水平方向及垂直方向展开来彼此调整适应其空间分辨率及彼此对齐。
依据一实施例,一图像的全部样本数组属于空间景象的同一部分,其中沿垂直方向及水平方向的分辨率在单独样本数组502-506间可不同。此外,为了用于举例说明目的,样本数组502及504被考虑属于一个平面群组510,而样本数组506被考虑属于另一个平面群组512。此外,图11显示实例情况,此处沿样本数组504的水平轴的空间分辨率为在样本数组502的水平方向的分辨率的两倍。此外,样本数组504相对于样本数组502被视为形成一次数组,样本数组502形成相关于一次数组504的从属数组。如前文说明,此种情况下,如通过图1细分器30决定,样本数组504被细分成多个区块是由从属数组502所采用,其中依据图11的实例,因样本数组502的垂直分辨率为一次数组504的垂直方向分辨率一半,各个区块已经对半平分成两个水平并排区块,当以样本数组502内的样本位置为单位测量时,各区块由于对半故再度成为方形区块。
如图11举例说明,对样本数组506所选用的细分是与另一样本群组510的细分不同。如前述,细分器30可与平面群组510的细分分开地或独立无关地选择像素数组506的细分。当然,样本数组506的分辨率也可与平面群组510的平面502及504的分辨率不同。
现在,当编码个别样本数组502-506时,编码器10开始例如以前述方式编码平面群组510的一次数组504。图11所示区块例如可为前述预测区块。另外,区块可为界定粒度用来定义某些编码参数的残差区块或其它区块。跨平面预测并未限于四叉树或多元树细分,但四叉树或多元树细分举例说明于图11。
在一次数组504的语法元素传输后,编码器10可决定宣布一次数组504为从属平面502的参考平面。编码器10及抽取器30分别可经由位流22来信号通知此项决定,同时从样本数组504形成平面群组510的一次数组的事实显然易明其中关联性,该信息又转而也可为位流22的一部分。总而言之针对在样本数组502内部的各区块,插入器18或编码器10的任何其它模块连同插入器18可决定是否抑制此区块的编码参数在位流内部的移转,以及在位流内部信号通知及取而代之针对该区块在位流内部信号通知将使用在一次数组504内部的共同定位区块的编码参数替代;或决定在一次数组504内部的共同定位区块的编码参数是否将用作为样本数组502的目前区块的编码参数的预测,而只移转在位流内部针对该样本数组502的目前区块的其残差资料。在负面决策的情况下,编码参数如常在数据流内部移转。针对各区块决策是在数据流22中信号通知。在解码器端,抽取器102使用针对各区块的此种跨平面预测信息来据此获得样本数组502的个别区块的编码参数,换言之,若跨平面采用/预测信息提示跨平面采用/预测,则通过推论一次数组504的共同定位区块的编码参数,或另外从该数据流抽取该区块的残差资料且将此残差数据与得自一次数组504的共同定位区块的编码参数的预测组合;或如常与一次数组504独立无关,抽采样本数组502的目前区块的编码参数。
也如前述,参考平面并非限于驻在跨平面预测目前关注的该区块所在相同位平面。因此如前文说明,平面群组510表示一次平面群组或二次平面群组512的参考平面群组。此种情况下,位流可能含有一语法元素,该语法元素针对样本数组506的各区块指示前述一次平面群组或参考平面群组510的任何平面502及504的共同定位宏区块的编码参数的采用/预测是否应进行,在后述情况下,样本数组506的目前区块的编码参数是如常传输。
须注意针对在一平面群组内部的多个平面的细分和/或预测参数可相同,亦即由于其对一平面群组只编码一次(一平面群组的全部二次平面是从同一个平面群组内部的一次平面推定细分信息及/或预测参数),细分信息及/或预测参数的适应性预测或干扰是在多个平面群组间进行。
须注意参考平面群组可为一次平面群组或二次平面群组。
在一平面群组内部的不同平面区块间的共同定位容易了解一次样本数组504的细分是由从属样本数组502在空间采用,但前述区块细分来使所采用的叶区块变成方形区块除外。在不同平面群组间跨平面采用/预测的情况下,共同定位可以一种方式定义,因而允许这些平面群组的细分间的更高自由度。给定该参考平面群组,决定在该参考平面群组内部的共同定位区块。共同定位区块及参考平面群组的导算可通过类似后文说明的方法进行。选定二次平面群组512的样本数组506中的一者在目前区块516内部的特定样本514。目前区块516的左上样本亦同,如图11显示于514用于举例说明目的;或于目前区块516的样本接近目前区块516中央或目前区块内部的任何其它样本,其几何形状经独特定义。计算在参考平面群组510的样本数组502及504内部的此种选定样本515的位置。样本数组502及504内部的样本514位置于图11分别指示于518及520。参考平面群组510内实际上使用哪一个平面502及504可经预先决定或可在位流内部信号通知。决定在参考平面群组510的相对应样本数组502或504内部最接近位置518及520的样本,含有此样本的区块被选用作为个别样本数组502及504内部的共同定位区块。在图11的情况下,分别为区块522及524。用来在其它平面决定共同定位区块的替代办法正如稍后详述。
在一实施例中,表明目前区块516的预测的编码参数是在相同图像500的不同平面群组510内部使用共同定位区块522/524的相对应预测参数完全推定而未传输额外侧边信息。推定可包括单纯拷贝相对应编码参数,或编码参数的调整适应将目前平面群组512与参考平面群组510间的差异列入考虑。举个实例,此种调整适应可包括加入运动参数校正(例如位移向量校正)用来考虑亮度及色度样本数组间的相位差;或调整适应可包括修改运动参数的精度(例如修改位移向量的精度)来考虑亮度及色度样本数组的不同分辨率。在额外实施例中,用来表明预测信号产生的一个或多个所推定的编码参数并未直接用于目前区块516,反而是用作为目前区块516的相对应编码参数的预测,及目前区块516的这些编码参数的精制是于位流22传输。举个实例,未直接使用推定的运动参数,反而表明运动参数间的偏差的运动参数差(诸如位移向量差)是用于目前区块516,推定的运动参数是编码于位流;在解码器端,经由组合推定的运动参数及传输的运动参数差获得实际使用的运动参数。
在另一实施例中,一区块的细分,诸如前述预测细分成预测区块的树区块(亦即使用相同预测参数集合的样本区块)是从根据图6A或6B相同图像亦即位序列的不同平面群组已经编码的共同定位区块而适应性地推定或预测。一个实施例中,二个或多个平面群组中的一者是编码为一次平面群组。针对此一次平面群组的全部区块,传输细分参数而未推定同一图像内的其它平面群组。其余平面群组是编码为二次平面群组。针对二次平面群组的区块,传输一个或多个语法元素,信号通知细分信息是否从其它平面群组的共同定位区块推定或预测,或细分信息是否于该位流传输。一或多个语法元素中的一者可称作为跨平面预测标记或跨平面预测参数。若语法元素信号通知未推定或预测细分信息,则该区块的细分信息是在该位流传输而未述及同一个图像的其它平面群组。若语法元素信号通知该细分信息是经推定或预测,则决定在所谓的参考平面群组中的共同定位区块。该区块的参考平面群组的组态可以多种方式组配。在一个实施例中,一特定参考平面群组指定给各个二次平面群组;此项指定可为固定,或可于高阶语法结构信号通知作为参数集合、存取单元报头、图像报头或片报头。于第二实施例中,参考平面的指定是在位流内部编码,及通过一个或多个语法元素信号通知,这些语法元素是针对一区块编码来表明细分信息是否经推定或预测或分开编码。参考平面群组可为一次平面群组或其它二次平面群组。给定参考平面群组,决定在该参考平面群组内部的共同定位区块。共同定位区块为对应于目前区块的相同影像区的参考平面群组,或表示共享该影像区与目前区块的最大部分的参考平面群组内部的区块。共同定位区块可被分区成更小型预测区块。
在额外实施例中,目前区块的细分信息,诸如依据图6A或6B的基于四叉树的细分信息是使用在同一个图像的不同平面群组的共同定位区块的细分信息推定,而未传输额外侧边信息。举一个特定实例,若共同定位区块被分区成2或4个预测区块,则该目前区块也分区成2或4个子区块用以预测目的。至于另一特定实例,若共同定位区块被分区成四个子区块,且这些子区块中的一者进一步分区成四个更小型子区块,则目前区块也被分区成四个子区块及这些子区块中的一者(对应于共同定位区块的该子区块进一步分解者)也被分区成四个更小型子区块。在又一较佳实施例中,推定的细分信息并未直接用于目前区块,反而是用作为目前区块的实际细分信息的预测,相对应精制信息是于位流传输。举个实例,由共同定位区块所推定的细分信息可进一步精制。针对与共同定位区块中未被分区成更小型区块的一子区块相对应的各个子区块,语法元素可于位流编码,其表明子区块是否在目前平面群组进一步分解。此种语法元素的传输可以子区块的大小作为条件。或可于位流中信号通知在参考平面群组进一步分区的子区块未在目前平面群组进一步分区成更小型区块。
在又一实施例中,一区块至预测区块的细分及表明子区块如何预测的编码参数二者是从针对同一图像的不同平面群组的已经编码的共同定位区块适应性推定或预测。在本发明的较佳实施例中,二个或多个平面群组中的一者是编码作为一次平面群组。针对此种一次平面群组的全部区块,细分信息和预测参数是未参考同一图像的其它平面群组而传输。剩余平面群组编码为二次平面群组。针对二次平面群组的区块,传输一个或多个语法元素,其信号通知细分信息及预测参数是否从其它平面群组的共同定位区块推定或预测;或细分信息及预测参数是否在位流传输。一个或多个语法元素中的一者可称作为跨平面预测标记或跨平面预测参数。若语法元素信号通知细分信息及预测参数是未经推定或预测,则该区块的细分信息及结果所得子区块的预测参数是于该位流传输而未述及相同图像的其它平面群组。若语法元素信号通知针对该子区块的细分信息及预测参数是经推定或预测,则决定该所谓的参考平面群组中的共同定位区块。针对该区块的参考平面群组的指定可以多种方式组配。在一个实施例中,一特定参考平面群组指派给各个二次平面群组;此种指派可为固定或可于高阶语法结构(诸如参数集合、存取单元报头、图像报头或片报头)信号通知。在第二实施例中,参考平面群组的指派是在位流内部编码,及通过针对一区块编码的一个或多个语法元素信号通知来表明细分信息及预测参数是否经推定或预测或分开编码。参考平面群组可为一次平面群组或其它二次平面群组。给定参考平面群组,决定在该参考平面群组内部的共同定位区块。该共同定位区块可以是在参考平面群组中与目前区块的相同影像区相对应的区块,或表示在该参考平面群组内部与该目前区块共享最大部分影像区的区块的该区块。共同定位区块可划分成更小型预测区块。在较佳实施例中,针对该目前区块的细分信息以及所得子区块的预测参数是使用在相同图像的不同平面群组中共同定位区块的细分信息及相对应子区块的预测参数,而未传输额外侧边信息。作为特定实例,若共同定位区块被分割成2或4个预测区块,则目前区块也分割成2或4个子区块用于预测目的,及针对目前区块的子区块的预测参数是如前述导算。举另一个特定实例,若共同定位区块被分割成四个子区块,且这些子区块中的一者被进一步分割成四个更小型子区块,则目前区块也分割成四个子区块,且这些子区块中的一者(与共同定位区块被进一步分解的该子区块相对应者)也分割成四个更小型子区块,但未进一步分区的全部子区块的预测参数是如前文说明推定。在又一较佳实施例中,细分信息完全是基于在参考平面群组中的共同定位区块的细分信息推定,但该子区块推定的预测参数只用作为子区块的实际预测参数的预测。实际预测参数与推定预测参数间的偏差是在位流编码。在又一实施例中,推定的细分信息是用作为目前区块的实际细分信息的预测,差异是在位流(如前述)中传输,但预测参数完全经推定。在另一个实施例中,推定的细分信息及推定的预测参数二者是用作为预测,而实际细分信息与预测参数间的差及其推定值是在位流传输。
在另一实施例中,针对一平面群组的一区块,适应性选择残差编码模式(诸如变换类型)是否针对相同图像从不同平面群组的已经编码共同定位区块推定或预测,或残差编码模式是否针对该区块分开编码。此一实施例是类似于前述针对预测参数的适应性推定/预测的实施例。
在另一实施例中,一区块(例如一预测区块)的细分成变换区块(亦即应用二维变换的样本区块)是从针对同一图像的不同平面群组的已经编码的共同定位区块适应性推定或预测。本实施例是类似前述细分成预测区块的适应性推定/预测的实施例。
在另一实施例中,一区块细分成变换区块及所得变换区块的残差编码模式(例如变换类型)是从针对同一图像的不同平面群组的已经编码的共同定位区块推定或预测。本实施例是类似前文细分成预测区块的适应性推定/预测及针对所得预测区块的预测参数的实施例。
在另一实施例中,一区块细分成预测区块、相关联的预测参数、预测区块的细分信息、及针对该变换区块的残差编码模式是从针对同一图像的不同平面群组已经编码的共同定位区块适应性推定或预测。本实施例表示前述实施例的组合。也可能只推定或预测所述编码参数中的一部分。
如此,跨平面采用/预测可提高前述编码效率。但通过跨平面采用/预测所得编码效率增益也可在基于多元树细分所使用的其它区块细分取得,而与是否实施区块合并无关。
就跨平面适应/预测的前述实施例可应用于影像及视频编码器及解码器,其将一图像的彩色平面及(若存在)与该图像相关联的辅助样本数组分割成区块及将这些区块与编码参数相关。针对各区块,一编码参数集合可含括在位流。例如,这些编码参数可为描述在解码器端一区块如何预测和解码的参数。作为特定实例,编码参数可表示宏区块或区块预测模式、细分信息、内-预测模式、用于运动补偿预测的参考指数、运动参数诸如位移向量、残差编码模式、变换系数等。与一图像相关联的不同样本数组可具有不同大小。
接下来,描述前文参考图1至图8所述在基于树的分割方案内部用于编码参数加强信号通知的一方案。至于其它方案,亦即合并及跨平面采用/预测,加强信号通知方案(后文中常称作为继承)的效果及优点是与前述实施例独立描述,但后述方案可与前述实施例中的任一者或单独或组合式组合。
大致上,在一基于树的分割方案的内部用来编码侧边信息的改良编码方案(称作为继承,说明如下)允许相对于常规编码参数处理获得下列优点。
在常规影像及视频编码中,图像或针对图像的特定样本数组集合通常分解成多个区块,这些区块是与特定编码参数相关联。图像通常是由多个样本数组组成。此外,图像也可关联额外辅助样本数组,其例如可表明透明信息或深度图。一图像的样本数组(包括辅助样本数组)可分组成一个或多个所谓的平面群组,此处各个平面群组是由一个或多个样本数组组成。一图像的平面群组可独立编码,或若该图像是与多于一个平面群组相关联,则一图像的平面群组可从同一图像的其它平面群组预测。各个平面群组通常分解成多个区块。该区块(或样本数组的相对应区块)是通过跨图像预测或图像内-预测而预测。区块可具有不同大小且可为方形或矩形。一图像分割成为多个区块可通过语法固定,或可(至少部分)在位流内部信号通知。经常传输的语法元素信号通知具有预定大小区块的细分。这些语法元素可表明一区块是否细分及如何细分成更小型区块,且与编码参数关联用于例如预测目的。针对一区块的全部样本(或相对应样本数组的区块),相关联编码参数的解码是以预定方式表明。在该实例中,一区块的全部样本是使用预测参数的同一集合预测,诸如参考指数(识别在已经编码图像集合中的一参考图像)、运动参数(表明一参考图像与目前图像间的一区块运动的测量)、表明内插滤波器的参数、内-预测模式等。运动参数可以具有水平分量及垂直分量的位移向量表示,或以更高阶运动参数(诸如六个成分所组成的仿射运动参数)表示。可能有多于一个特定预测参数集合(诸如参考指数及运动参数)是与单一区块相关联。该种情况下,针对这些特定预测参数的各集合,产生针对该区块(或样本数组的相对应区块)的单一中间预测信号,最终预测信号是通过包括重叠中间预测信号的组合建立。相对应加权参数及可能也常数偏移(加至该加权和)可针对一图像或一参考图像或一参考图像集合而固定;或可含括在针对相对应区块的预测参数集合中。原始区块(或相对应样本数组区块)与其预测信号间的差也称作为残差信号通常经变换及量化。经常将二维变换应用至残差信号(或残差区块的相对应样本数组)。针对变换编码,已经使用特定预测参数集合的区块(或相对应样本数组区块)可在应用该变换之前进一步分割。变换区块可等于或小于用于预测的区块。也可能一变换区块包括用于预测的区块中的多于一者。不同变换区块可具有不同大小,变换区块可表示方形区块或矩形区块。在变换后,所得变换系数经量化,及获得所谓的变换系数层次。变换系数层次以及预测参数及(若存在)细分信息是经熵编码。
按照若干影像及视频编码标准,通过语法提供将一图像(或一平面群组)细分成多个区块的可能性极为有限。通常只表明是否(以及可能地如何)具有预定大小的区块可细分成更小型区块。举例言之,按照H.264的最大型区块为16×16。该16×16区块也称作为宏区块,在第一步骤各图像分区成为宏区块。针对各个16×16宏区块,可信号通知是否编码成16×16区块,或编码成两个16×8区块,或两个8×16区块,或四个8×8区块。若16×16区块细分成四个8×8区块,则这些8×8区块各自可编码成一个8×8区块,或两个8×4区块,或两个4×8区块或四个4×4区块。在当前影像及视频编码标准中表明细分成为多个区块的可能性的最小集合具有用以信号通知细分信息的侧边信息率维持为小的优点,但具有传输针对区块的预测参数所要求的位率变大的缺点,正如稍后详述。用以信号通知预测参数的侧边信息率通常确实表示一区块的显著量总位率。及当此侧边信息减少时,例如可使用较大型区块大小达成时,可提高编码效率。一视频序列的实际影像或图像是由具特定性质的任意形状对象组成。举个实例,这些对象或对象部分是以独特纹理或独特运动为其特征。通常相同预测参数集合可应用于此种对象或对象部分。但对象边界通常并未重合大型预测区块可能的区块边界(例如于H.264的16×16宏区块)。编码器通常决定导致最小型特定率-失真成本测量值的细分(于有限可能性集合中)。针对任意形状对象,如此可导致大量小型区块。且因这些小型区块是与须传输的一预测参数集合相关联,故侧边信息率变成总位率的显著部分。但因若干小型区块仍然表示相同对象或对象部分的区,多个所得区块的预测参数为相同或极为相似。直觉上,当语法是以一种方式扩充,其不仅允许细分一区块,同时也在细分后所得多个区块间共享编码参数时可提高编码效率。于基于树的细分中,通过由以基于树的阶层式关系指定编码参数或其部分给一个或多个亲代节点,可达成针对一给定区块集合的编码参数的共享。结果,共享参数或其部分可用来减少针对细分后所得区块信号通知编码参数实际选择所需的侧边信息。减少可通过删除随后区块的参数的信号通知而达成,或可通过针对随后区块的参数的预测模型化及/或上下文模型化的共享参数而达成。
后述继承方案的基本构想是通过由沿该等区块的基于树的阶层关系共享信息,来减少传输编码信息所需的位率。共享信息是在位流内部信号通知(除细分信息的外)。继承方案的优点为针对编码参数由减低侧边信息率结果导致编码效率增高。
为了减少侧边信息率,根据后述实施例,针对特定样本集合的个别编码参数,亦即单纯连接区,其可表示多元树细分的矩形区块或方形区块或任意形状区或任何其它样本集合是以有效方式在数据流内部信号通知。后述继承方案允许编码参数无须针对样本集合中的各个样本集合明确地含括在位流。编码参数可表示预测参数,其表明对应样本集合是使用已编码样本预测。多项可能及实例已经如前文说明确实也适用于此处。如前文已述,及正如稍后详述,有关下列几种方案,一图像的样本数组基于树状划分成为多个样本集合可通过语法固定,或可通过在位流内部的相对应细分信息信号通知。如前述,针对样本集合的编码参数可以预先界定的顺序传输,该顺序是通过语法而给定。
依据继承方案,解码器或解码器的抽取器102被配置为以特定方式导算出有关个别单纯连接区或样本集合的编码参数的信息。特定言之,编码参数或其一部分(诸如用于预测目的的参数)是沿该给定基于树的分割方案而在各区块间共享,沿该树状结构的共享群组分别是由编码器或插入器18决定。在一特定实施例中,分割树的一给定内部节点的全部子节点的编码参数的共享是使用特定二进制值共享标记指示。至于替代之道,针对各节点可传输编码参数的精制,使得沿基于树的区块的阶层式关系,参数的累积精制可应用至在一给定叶节点的该区块的全部样本集合。在另一实施例中,沿基于树的该区块阶层关系传输用于内部节点的编码参数的一部分可用于在一给定叶节点针对该区块的编码参数或其一部分的上下文适应性熵编码及解码。
图12A及图12B显示使用基于四叉树分割的特例的继承的基本构想。但如前文数次指示,其它多元树细分方案也可使用。该树状结构是显示于图12A,而与图12A的树状结构相对应的空间分割是显示于图12B。其中所示分割是类似就图3A至3C所示。概略言之,继承方案将允许侧边信息指派给在该树结构内部的不同非叶层的节点。依据侧边信息指派给在该树的不同层的节点,诸如图12A的树的内部节点或其根节点,在图12B所示区块的树阶层式关系中可达成不同程度的共享侧边信息。例如,若决定在层4的全部叶节点,在图12A的情况下全部具有相同亲代节点,虚拟地共享侧边信息,这意味着图12B中以156a至156d指示的最小型区块共享此侧边信息,而不再需要针对全部这些小型区块156a至156d完整传输侧边信息,亦即传输四次,但如此维持为编码器的选项。然而,也可能决定图12A的阶层式层次1(层2)的全区,亦即在树区块150右上角的四分之一部分包括子区块154a、154b及154d及前述又更小型子区块156a至156d,是用作为其中共享编码参数的区。如此,增加共享侧边信息的区。下一个增加层次为加总层1的全部子区块,亦即子区块152a、152c及152d及前述更小型区块。换言之,此种情况下,整个树区块具有指派给该区块的侧边信息,此树区块150的全部子区块共享侧边信息。
在后文继承说明中,下列注记是用来描述实施例:
a.目前叶节点的重建样本:r
b.相邻叶的重建样本:r’
c.目前叶节点的预测器:p
d.目前叶节点的残差:Res
e.目前叶节点的重建残差:RecRes
f.定标及反变换:SIT
g.共享标记:f
作为继承的第一实例,可描述在内部节点的内-预测信号通知。更精确言之,描述如何信号通知在基于树区块的内部节点划分用的内-预测模式用以预测目的。通过从根节点至叶节点来遍历树,内部节点(包括根节点)可传递部分侧边信息,该信息将由其相对应的子节点利用。更明确言之,共享标记f是针对内部节点发送而具有下列意义:
·若f具有数值1(“真”),则该给定内部节点的全部子节点共享相同内-预测模式。除了共享具有数值1的标记f之外,内部节点也信号通知内-预测模式参数来由全部子节点使用。结果,全部随后子节点并未携带任何预测模式信息及任何共享标记。为了重建全部相关叶节点,解码器从相对应内部节点应用内-预测模式。
·若f具有数值0(“假”),则相对应内部节点的子节点并未共享相同内-预测模式,属于内部节点的各个子节点携带一分开共享标记。
图12C显示前述于内部节点的内-预测信号通知。在层1的内部节点传递由内-预测模式信息所给定的共享标记及侧边信息,且子节点并未携带任何侧边信息。
作为第二继承实例,可描述跨-预测精制。更明确言之,描述如何在基于树的区块分割内部模式,信号通知跨-预测模式的侧边信息用于例如通过运动向量所给定的运动参数的精制目的。通过从根节点通过至叶节点来遍历树,内部节点(包括根节点)可传递部分侧边信息,该信息将由其相对应的子节点精制。更明确言之,共享标记f是针对内部节点发送而具有下列意义:
·若f具有数值1(“真”),则该给定内部节点的全部子节点共享相同运动向量参考。除了共享具有数值1的标记f外,内部节点也信号通知运动向量及参考指数。结果,全部随后子节点未携带额外共享标记,反而可携带此一继承的运动向量参考的精制。对于全部相关叶节点的重建,解码器在该给定叶节点加运动向量精制给属于其相对应内部亲代节点具有共享标记f的数值1的继承的运动向量参考值。如此表示在一给定叶节点的运动向量精制为欲应用至自此叶节点用于运动补偿预测的实际运动向量与其相对应内部亲代节点的运动向量参考值间的差。
·若f具有数值0(“假”),则相对应内部节点的子节点并未必然共享相同跨-预测模式,以及在该子节点并未通过使用得自相对应内部节点的运动参数而进行运动参数的精制,属于内部节点的各个子节点携带一分开共享标记。
图12D显示前述运动参数精制。层1的内部节点是传递共享标记及侧边信息。属于叶节点的子节点只携带运动参数精制,例如层2的内部子节点未携带侧边信息。
现在参考图13。图13显示流程图,例示说明解码器(诸如图2的解码器)用于从数据流重建表示空间实例信息信号的一信息样本数组(其通过多元树细分而细分成不同大小的叶区)的操作模式。如前述,各叶区具有与其相关的选自于多元树细分的一系列阶层式层级中的一个阶层式层级。例如,图12B所示全部区块皆为叶区。叶区156c例如是与阶层式层级4(或层级3)相关联。各叶区具有与其相关联的编码参数。这些编码参数的实例已经说明如前。针对各叶区,编码参数是以一个别语法元素集合表示。各个语法元素为选自于一语法元素类型集合中的一个个别语法元素类型。各语法元素类型例如为预测模式、运动向量分量、内-预测模式的指示等。依据图13,解码器进行下列步骤。
在步骤550,继承信息是抽取自数据流。在图2的情况下,抽取器102是负责步骤550。继承信息指示继承是否用于目前信息样本数组。后文描述将显示继承信息有若干可能,诸如共享标记f及多元树结构划分成一次部分及二次部分的信号通知。
信息样本数组已经构成一图像的一子部分,诸如树区块,例如图12B的树区块150。如此继承信息指示针对特定树区块150是否使用继承。此种继承信息例如可针对全部预测细分的树区块而插入数据流。
此外,若指示使用继承,则继承信息指示由一叶区集合所组成的且对应于多元树细分的该阶层式层级序列的一阶层式层级的该信息样本数组的至少一个继承区是低于该叶区集合相关联的各个阶层式层级。换言之,继承信息指示针对目前样本数组(诸如树区块150)是否使用继承。若为是,表示此树区块150的至少一个继承区或子区内部的叶区共享编码参数。如此,继承区可能不是叶区。在图12B的实例中,继承区(例如)可为由子区块156a至156b所形成的区。另外,继承区可更大,也额外涵盖子区块154a、b及d,及甚至另外,继承区可为树区块150本身,其全部叶区块共享与该继承区相关联的编码参数。
但须注意,在一个样本数组或树区块150内部可界定多于一个继承区。例如,假设左下子区块152c也分割成更小型区块。此种情况下,子区块152c可形成一继承区。
在步骤552,检查继承信息,是否使用继承。若为是,图13的处理程序前进至步骤554,此处相对于每个跨继承区,包括预定语法元素类型的至少一个语法元素的继承子集是从数据流抽取出。随后步骤556中,然后此继承子集拷贝入在该语法元素集合内部的一相对应语法元素继承子集,或用作为该继承子集的预测,该继承子集表示至少一个继承区的叶区集合组成相关联的编码参数。换言之,针对在该继承信息内部指示的各个继承区,数据流包括语法元素的继承子集。又换言之,继承是有关可用于继承的至少某一个语法元素类型或语法元素类别。举例言之,预测模式或跨-预测模式或内-预测模式语法元素可经历继承。例如针对继承区在该数据流内部所含的继承子集可包括跨-预测模式语法元素。继承子集也包括额外语法元素,其语法元素类型是取决于与该继承方案相关联的前述固定式语法元素类型的值。举例言之,在跨-预测模式为继承子集的固定式分量的情况下,定义运动补偿的语法元素(诸如运动向量分量)可通过语法而可含括或可未含括于该继承子集。例如,假设树区块150的右上四分之一(亦即子区块152b)为继承区,则单独跨-预测模式可指示用于本继承区,或连同运动向量及运动向量指标而用于跨-预测模式。
含在继承子集的全部语法元素是拷贝入在该继承区内部的叶区块(亦即叶区块154a、b、d及156a至156d)的相对应编码参数,或用作为其预测。在使用预测的情况下,针对个别叶区块传输残差。
针对叶区块150传输继承信息的一项可能性为前述共享标记f的传输。在步骤550,继承信息的抽取在本例中包括后述。更明确言之,解码器可被配置为使用从较低阶层式层级至较高阶层式层级的阶层式层级顺序,针对与该多元树细分的至少一个阶层式层级的任何继承集合相对应的非叶区,抽取及检查得自该数据流的共享标记f,有关是否个别继承标记或共享标记表明继承与否。举例言之,阶层式层级的继承集合可通过图12A的阶层式层1至层3形成。如此,针对并非叶节点且是位在于任何层1至层3的子树结构的任何节点,可具有在该数据流内部与其相关联的一共享标记。解码器是以从层1至层3的顺序(诸如以深度优先或宽度优先遍历顺序)抽取这些共享标记。一旦共享标记中的一者等于1,则解码器知晓含在相对应继承区的叶区块共享该继承子集,随后接着在步骤554的抽取。针对目前节点的子节点,不再需要继承标记的检查。换言之,这些子节点的继承标记并未在数据流内部传输,原因在于显然这些节点区已经属于其中语法元素的继承子集为共享的该继承区。
共享标记f可以前述信号通知四叉树细分的位交叉。例如,包括细分标记及共享标记二者的交叉位序列可为:
10001101(0000)000,
其为图6A所示的相同细分信息,具有二散置的共享标记,该标记通过下方画线强调来指示图3C中在树区块150左下四分之一的子区块共享编码参数。
定义指示继承区的继承信息的另一种方式是使用彼此以从属方式定义的二细分,如前文分别参考预测细分及残差细分的解释。概略言之,一次细分的叶区块可形成该继承区,该继承区界定其中语法元素的继承子集为共享的区;而从属细分定义这些继承区内部的区块,针对该区块语法元素的继承子集是经拷贝或用作为预测。
例如,考虑残差树作为预测树的延伸。进一步考虑预测区块可进一步分割成更小型区块用于残差编码目的。针对与预测相关四叉树的叶节点相对应的各预测区块,用于残差编码的相对应细分是由一个或多个从属四叉树决定。
此种情况下,替代在内部节点使用任何预测参数,发明人考虑残差树是以下述方式解译,残差树也表明预测树的精制表示使用恒定预测模式(通过预测相关树的相对应叶节点信号通知)但具有经过精制的参考样本。后述实例举例说明此种情况。
例如,图14A及14B显示用于内-预测的四叉树分割,邻近参考样本是针对一次细分的一个特定叶节点强调,而图14B显示相同预测叶节点的残差四叉树细分带有已精制的参考样本。图14B所示全部子区块针对在图14A强调的个别叶区块共享含在数据流内部的相同内-预测参数。如此,图14A显示常规用于内-预测的四叉树分割实例,此处显示一个特定叶节点的参考样本。但在发明人的较佳实施例中,经由使用在残差树中已经重建的叶节点的邻近样本(诸如图4的灰色阴影线条指示),针对残差树中各个叶节点计算一分开内-预测信号。然后,通过将量化残差编码信号加至此预测信号而以寻常方式获得一给定残差叶节点的重建信号。然后此重建信号用作为随后预测程序的参考信号。注意用于预测的解码顺序是与残差解码顺序相同。
如图15所示,在解码程序中,针对各残差叶节点,经由使用参考样本r’依据实际内-预测模式(通过预测相关四叉树叶节点指示),计算预测信号p。
在SIT处理程序后,
RecRes=SIT(Res)
计算重建的信号r及储存用于下一个预测计算程序:
r=RecRes+p
用于预测的解码程序是与图16所示残差解码顺序相同。
各个残差叶节点是如前段所述解码。重建信号r是储存于缓冲器,如图16所示。该缓冲器中,参考样本r’将取用于下次预测及解码程序。
在已经就图1至图16以前文摘述的各方面的组合式分开子集描述特定实施例后,将描述本申请的额外实施例,关注焦点是集中在前述某些方面,但实施例表示前述若干实施例的普及化。
特定言之,有关图1及图2的架构的前述实施例主要组合本申请的多个方面,也可优异地采用在其它应用用途或其它编码领域。如前文经常述及,例如多元树细分可未经合并及/或未经跨平面采用/预测及/或无继承而使用。举例言之,最大区块大小的传输、深度优先遍历顺序的使用、依据个别细分标记的阶层式层级的上下文适应、及在位流内部最大阶层式层级的传输来节省侧边信息位率,全部这些方面皆优异但彼此独立。当考虑合并方案时也是如此。合并的优点为与一图像被细分成单纯连接区的确切方式独立无关,及其优点为与多于一个样本数组的存在或跨平面采用/预测及/或继承的使用独立无关。同样适用于涉及跨平面采用/预测及/或继承的优点。
据此,后文摘述的实施例笼统概括前述有关合并方面的实施例。至于表示前述实施例的概括说明的下列实施例,多个前述细节可视为与后文描述的实施例可相容。
图17显示依据本申请实施例的解码器。图17的解码器包括一抽取器600及一重建器602。该抽取器600被配置为针对表示一空间采样信息信号的一信息样本数组被细分而成的多个单纯连接区的各区,从一数据流604抽取有效载荷数据。如前述,该信息样本数组被细分成的单纯连接区可植源于一多元树细分,且可为方形或矩形形状。此外,特别描述的用来细分一样本数组的实施例仅为特定实施例,也可使用其它细分。若干可能性是显示于图18A至图18C。例如图18A显示一样本数组606细分成彼此毗连的非重叠树区块608的规则二维排列,其中部分树区块依据多元树结构而被细分成具有不同大小的子区块610。如前述,虽然四叉树细分例示说明于图18A,但在任何其它数目子节点的各亲代节点分割亦属可能。图18B显示一实施例,据此,通过直接应用多元树细分至全像素数组606上,一样本数组606被细分成具有不同大小的子区块。换言之,全像素数组606是被视为树区块处理。图18C显示另一实施例。依据此一实施例,样本数组被结构化成彼此毗连的方形或矩形宏区块的规则二维排列,及各个这些宏区块612是个别地与分割信息相关联,据此,一宏区块612保留未经分割或被分割成由该分割信息所示大小的区块的规则二维排列。如此可知,图13的全部细分导致该样本数组606细分成单纯连接区,依据图18A至18C的实施例,各单纯连接区是以非重叠显示。但数种替代之道亦属可能。举例言之,各区块可彼此重叠。但重叠可限于各区块有一部分未重叠任何邻近区块的程度,或使得各区块样本是沿一预定方向与目前区块并排排列的邻近区块中的至多一个区块重叠。换言之,后者表示左及右邻近区块可重叠目前区块,因而完全覆盖该目前区块,但未彼此重叠,同理适用于垂直及对角线方向的邻近区块。
如前文就图1至图16所述,信息样本数组并不必表示一视频或静止图像的图像。样本数组606也可表示某个景物的深度图或透明映射图。
如前文讨论,与多个单纯连接区各自相关联的有效载荷数据可包括空间域或变换域的残差数据,诸如变换系数及识别在一变换区块内部与一残差区块相对应的显著变换系数位置的一显著性映射图。笼统言之,从该数据流604针对各个单纯连接区而通过抽取器600抽取的有效载荷数据为下述数据,其空间上在空间域或在频谱域,且或为直接或例如作为残差至其某种预测而描述其相关联的单纯连接区。
重建器602被配置为针对各个单纯连接区,通过以与个别单纯连接区相关联的编码参数描述的方式处理个别单纯连接区的有效载荷数据,来从该信息样本数组的单纯连接区的有效载荷数据而重建该信息样本数组。类似前文讨论,编码参数可以是预测参数及据此,图18A至18B所示单纯连接区可对应于前述预测区块,亦即以数据流604为单位的区块界定用以预测个别单纯连接区的预测细节。但编码参数非仅限于预测参数。编码参数可指示用以变换该有效载荷数据的变换,或可定义一滤波器,其当重建该信息样本数组时是用来重建该个别单纯连接区。
抽取器600被配置为针对一预定单纯连接区,识别在多个单纯连接区内部与该预定单纯连接区具有预定相对位置关系的单纯连接区。有关此一步骤细节在前文已就步骤450详细说明。换言之,除了预定相对位置关系外,识别可取决于与该预定单纯连接区相关联的一编码参数子集。在识别后,抽取器600从该数据流604抽取针对该预定单纯连接区的一合并指标。若与该预定单纯连接区具有预定相对位置关系的单纯连接区数目大于零。此是与步骤452及454的前文描述相对应。若合并指标提示作为该预定区块的合并处理,则抽取器600被配置为检查与该预定单纯连接区具有预定相对位置关系的单纯连接区数目是否为1,或若与该预定单纯连接区具有预定相对位置关系的单纯连接区数目是否大于1但其编码参数彼此相同。若二替代例中的一者适用,则恰如前文就步骤458至468所述,抽取器采用编码参数或使用编码参数用来预测预定单纯连接区或其剩余子集的编码参数。如前文就图10所述,在抽取器检查揭示与该预定单纯连接区具有预定相对位置关系的单纯连接区数目是大于1且彼此具有不同编码参数的情况下,可通过抽取器600而从数据流604抽取额外指标。
通过使用后述检查,指示候选单纯连接区的一个或一子集的额外指标的传输可被抑制,因而减少侧边信息开销。
图19显示用以产生可通过图17的解码器解码的数据流的编码器的大致结构。图19的编码器包括一数据产生器650及一插入器652。数据产生器650被配置为针对信息样本数组所细分而成的多个互连区中的每一个连同与个别单纯连接区相关联的编码参数,将该信息样本数组编码成有效载荷数据,来指示如何重建个别单纯连接区的有效载荷数据。插入器652如同图12的解码器的抽取器600那样执行识别及检查,但是执行合并指标的插入而非其抽取,及抑制编码参数插入数据流,或替代前文就图12A至图12D及图10所述采用/预测,通过个别预测残差的插入来完整置换编码参数的插入数据流。
此外,须注意图19的编码器结构为相当示意性质,实际上,有效载荷数据、编码参数及合并指针的决定可能是迭代处理程序。举例言之,若邻近单纯连接区的编码参数为相似,但非彼此相同,当考虑合并指标允许完全抑制单纯连接区中的一者的编码参数,及通过只递交残差来完整置换这些编码参数的递交时,迭代处理程序可判定放弃这些编码参数间的小差异可能优于信号通知这些差值给解码器。
图20显示解码器的又一实施例。图20的解码器包括一细分器700、一合并器702及一重建器704。细分器被配置为依据语法元素子集是否含在数据流,将表示二维信息信号的空间采样的样本数组,通过递归地多重分割而空间地细分成多个具有不同大小的非重叠单纯连接区。如此,多重分割可与前文就图1至图16或图18A或图18B摘述的实施例相对应。含在数据流用以指示细分的语法元素可如前文就图6A或图6B指示定义或以其它方式定义。
合并器702被配置为取决于数据流中的第二语法元素子集与第一子集不相连接,组合多个单纯连接区的空间上邻近单纯连接区而获得样本数组的中间细分成不相连接的单纯连接区集合,其联合具有多个单纯连接区。换言之,合并器702组合单纯连接区,及是以独特方式合并单纯连接区群组。恰如前述的第二语法元素子集指示,合并信息可以前文就图19或图10或若干其它方式呈现的方式界定。但编码器通过使用与指示合并的该子集不相连接的一子集而指示细分的能力,提高编码器将样本数组细分调整适应实际样本数组内容的自由度,故可提高编码效率。重建器704被配置为使用中间细分而从数据流重建样本数组。如前文指示,重建器可通过针对一目前单纯连接区的合并伴侣的编码参数的采用/预测而利用中间细分。另外,重建器704甚至可应用变换或预测程序至单纯连接区的合并群组的组合区。
图21显示用来产生可通过图15的解码器解码的一数据流的可能的编码器。该编码器包括一细分/合并级750及一数据流产生器752。细分/合并级被配置为决定表示二维信息信号及两个不相连接单纯连接区集合的一信息样本数组的中间细分,其联合为多个单纯连接区,利用一第一语法元素子集定义此中间细分,据此通过递归地多重分割而将该信息样本数组细分成多个不相重叠的不同大小单纯连接区;及一第二语法元素子集与该第一子集不相连接,据此多个单纯连接区的空间上邻近单纯连接区被组合而获得中间细分。数据流产生器752使用该中间细分来将信息样本数组编码成数据流。细分/合并级750也将第一及第二子集插入数据流。
再度,如同图14A和图14B的情况,决定第一及第二子集及由数据流产生器752产生语法元素的处理程序可以是迭代重复操作的处理程序。举例言之,细分/合并级750可初步地决定最佳细分,其中在数据流产生器752以细分/合并级使用样本细分而决定用以编码样本数组的相对应最佳语法元素集合后,设定描述合并的语法元素,因而减少侧边信息开销。但编码程序可能未停在此处。反而,细分/合并级750连同数据流产生器752可协力合作,试图偏离先前由数据流产生器752所决定的细分及语法元素的最佳集合,来判定通过利用合并的正向性质是否达成较佳率/失真比。
如前述,就图17至21所述实施例表示前文就图1至16所示实施例的普及化,据此,可独特地关联图1至图16的组件至图17至图21所示组件。举例言之,抽取器102连同细分器104a及合并器104b推定负责由图17抽取器600所执行的工作。细分器负责个别单纯连接区间的邻近关系的细分与管理。合并器104b又转成管理单纯连接区合并成一群组,在合并事件是由目前解码合并信息指示的情况下,定位欲拷贝或欲用作为目前单纯连接区的预测的正确编码参数。在使用熵解码用于数据抽取的情况下,抽取器102推定负责使用正确上下文而从该数据流的实际数据抽取。图2的其余组件为重建器602的实例。当然,重建器602可与图2所示差异地实施。举例言之,重建器602可未使用运动补偿预测及/或内-预测。反而,也适用其它种可能性。
此外,如前述,关联图17的描述所述单纯连接区,类似残差细分或滤波细分,如前文指示是对应于前述预测区块,或对应于前述其它细分中的任一者。
比较图19的编码器与图1的实例,数据产生器650将涵括数据流插入器18以外的全部组件,而后者是与图19的插入器652相对应。再度,数据产生器650可使用图1所示混成编码办法以外的其它编码办法。
比较图20的解码器与图2所示实例,细分器104a及合并器104b分别将对应于图20的细分器100及合并器102,而组件106及114将对应于重建器704。抽取器102常见参与图20所示全部组件的功能。
至于图21的编码器,细分/合并级750将对应于细分器28及合并器30,而数据流产生器752将涵括图10所示全部其它组件。
虽然已经就装置上下文说明数个方面,但显然这些方面也表示相对应方法的说明,此处一区块或一装置是对应于一方法步骤或一方法步骤特征。同理,在方法步骤上下文中所描述的方面也表示对应区块或项目或对应装置的特征的描述。部分或全部方法步骤可通过(或使用)硬件装置,例如微处理器、可编程计算机或电子电路执行。在若干实施例中,最重要方法步骤中的某一者或某多个可通过此种装置执行。
本发明的编码/压缩信号可储存在数字储存介质上,或可在诸如互联网的传输介质(诸如无线传输介质或有线传输介质)传输。
依据若干具体实现要求,本发明的实施例可于硬件或软件具体实现。具体实现可使用数字储存介质执行,例如软盘、DVD、蓝光盘、CD、ROM、PROM、EPROM、EEPROM或闪存,其上储存可电子式读取的控制信号,其是与可编程计算机系统协力合作(或可协力合作)因而执行个别方法。因此,数字储存介质可为计算机可读取。
依据本发明的若干实施例包括具有可电子式读取控制信号的数据载体,其可与可编程计算机系统协力合作因而执行此处所述方法中的一者。
一般而言,本发明的实施例可实施为具有程序代码的一种计算机程序产品,该程序代码可操作用来当计算机程序产品在计算机上运行时执行这些方法中的一者。程序代码例如可储存在机器可读取载体上。
其它实施例包括储存在机器可读取载体上的用来执行此处所述方法中的一者的计算机程序。
换言之,因此,本发明方法的实施例为一种计算机程序,该计算机程序具有程序代码用来当该计算机程序在计算机上运行时执行此处所述方法中的一者。
因此本发明的又一实施例为一种数据载体(或数字储存介质或计算机可读取介质)包括于其上记录用来执行此处所述方法中的一者的计算机程序。
因此本发明方法的又一实施例为表示用来执行此处所述方法中的一者的计算机程序的数据流或信号序列。该数据流或信号序列例如被配置为经由数据通信连接,例如经由互联网传输。
又一实施例例如包括一种处理手段,例如计算机或可程序逻辑装置,其被配置为或调适来执行此处所述方法中的一者。
又一实施例包括其上安装有用以执行此处所述方法中的一者的计算机程序的计算机。
在若干实施例中,可编程逻辑装置(例如现场可编程门阵列)可用来执行此处所述方法的部分或全部功能。在若干实施例中,现场可编程门阵列可与微处理器协力合作来执行此处所述方法中的一者。概略言之,该方法较佳是通过任一种硬件装置执行。
前述实施例仅用于举例说明本发明的原理。须了解此处所述配置的细节的修改及变化为熟谙技艺人士显然易知。因此意图仅受随附的权利要求的范围所限而非受用于举例说明此处实施例的特定细节所限。
- 还没有人留言评论。精彩留言会获得点赞!