低延时时间触发网络系统及优化方法与流程
本发明涉及总线传输
技术领域:
,具体地,涉及一种低延时时间触发网络系统及优化方法。
背景技术:
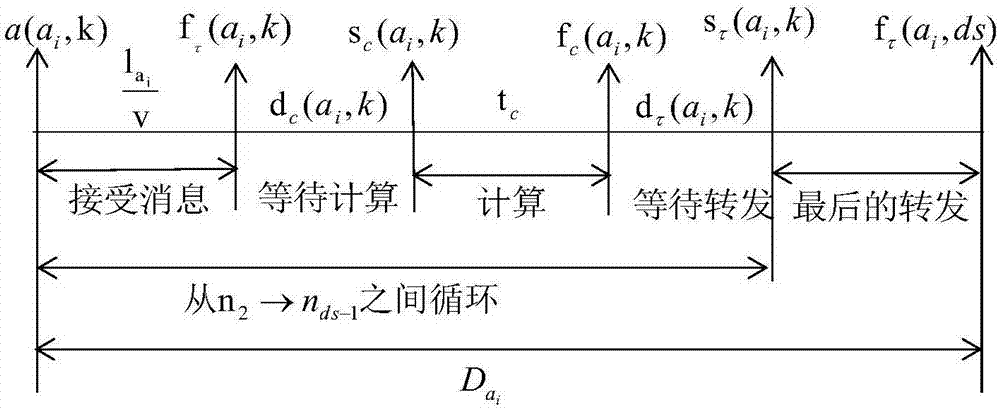
:对于总线结构的系统而言,由于所有的结点都连接在一起,因此在传输信息的过程中,对于信息传输的端对端时延影响最大的就是各结点发送的信息在总线中发生的碰撞。为了降低信息在传输过程中的碰撞率,在过去的几十年间,总线结构的系统经历了从纯ALOHA协议、时隙ALOHA协议、载波侦听多路访问协议、载波侦听多路访问/冲突避免协议等一系列的发展进程。随着工业生产对实时性的要求越来越高,随后产生的时间触发协议,不仅可以满足应用对实时性的要求,同时可以极大地降低信息在总线中的碰撞率,从而提高总线的利用率。采用时间触发协议的总线在传输非实时的数据时,采用的传输方式与其它致力于降低碰撞率的协议相同:数据在结点处理完毕之后,能够马上转发到总线当中;如果总线此时处于忙碌状态,则数据暂时存储在结点的缓冲区中,同时结点在不停地侦听总线状态,如果判断数据在发送阶段不会与别的数据发生碰撞,再将数据发送至总线中,正是由于数据产生的不确定性,导致了其它致力于降低碰撞率的协议并不能保证数据传输的实时性,而时间触发协议能够保证传输的实时性,主要有一下几点原因:1)实时数据包是周期性的任务。在每个周期,相应的结点会产生一个数据包并发送。这个过程被称为任务,实时数据包的发送就是实时任务,或时间触发的任务;相反的,非实时数据包的发送就是非实时任务,或者称为事件触发的任务。非实时的数据包的产生是由于相应的事件触发而产生,而非在固定的时间段内产生。因此非实时数据包的传输具有不可预测性,而实时数据包的传输是可预测的。2)实时数据的优先级高于非实时数据。由于实时数据一般是有时间约束的,所以在时间触发协议中定义实时数据的优先级高于非实时数据,且高优先级的数据具有可抢占低优先级数据传输的权利。也就是说,如果总线使用权轮到了非实时数据,但是产生非实时数据的结点在侦听总线的过程中发现,在发送非实时数据的过程中会与一个实时数据产生冲突,那么总线使用权将退让给对应的实时数据。以上2点清晰解释了时间触发协议中数据的传输过程以及它如何能够保证实时数据的传输时间的确定性,换句话说,对于实时数据,每个结点都有一份时刻表,结点查表获取处理和发送数据的时间。如果在周期最短的数据再次发送之前,所有的数据都已经完成了传送,那么所有的数据在每周期的发送时间可以与初次发送时间相同;但是如果周期最短的数据再次发送的时候,系统中还有数据尚未结束传送,那么这些数据很可能对再次发送的数据(优先级较高)让出总线,这样就导致了数据在每周期的发送时间不能保证与初次发送时间相同,这与传统的调度方式产生了冲突。因此,需要提供一种对时间触发协议调度方式的改进方法,从数据产生的最小公倍数周期的角度出发,来对总线中传送的数据进行调度。技术实现要素:针对现有技术中的缺陷,本发明的目的是提供一种低延时时间触发网络系统及优化方法。根据本发明提供的低延时时间触发网络优化方法,包括如下步骤:步骤1:由安装在多个单核处理器上的多个同步应用在下一个自身周期到达的时候向总线提出占用申请;步骤2:总线依据设定的优先级对每个同步应用的占用申请进行先后顺序判断,得到每个同步应用在相应结点处数据的发送时间,所述相应结点是指相应的单核处理器;步骤3:记录每个节点在最小公倍数周期内数据每次从该结点转发到总线的时间,生成最小公倍数周期调度表;步骤4:采用最小公倍数周期调度表的时间对总线进行调度。优选地,所述步骤1包括:将安装在单核处理器上的多个同步应用记为APP={app1,app2,app3...appi},多个单核处理器记为:Node={n1,n2,n3...nj},appi表示第i个同步应用,nj表示第j个单核处理器,i、j为大于1的正整数;其中:应用的自身周期是指:周期性同步应用各自的循环周期。优选地,所述步骤2包括:步骤2.1:在总线申请表中寻找到申请占用总线时间最早的应用,记为appi;步骤2.2:寻找在应用appi占用总线期间申请总线的应用,记为APPcft1,其中:APPcft1={app1,app2,app3...appy},appy表示第y个在应用appi占用总线期间申请总线的同步应用;依照已经开始的应用优先于尚未开始的应用,应用优先级高的应用优先占用总线的原则,选择出要占用总线的应用,记为appj;y为大于1的正整数;步骤2.3:寻找appj占用总线期间申请总线的应用,记为:APPcft2,其中:APPcft2={app1,app2,app3...appu},appu表示第u个在应用appj占用总线期间申请总线的同步应用;取APPcft1∪APPcft2的同步应用,依照appj的占用时间,延迟应用的申请时间;u为大于1的正整数。优选地,所述步骤3包括:步骤3.1:得到应用appj占用总线的时间,即能够依照应用传输的数据长度,得到应用完全接收的时间;步骤3.2:依照完全接收时间,判断是否有尚未结束运算的应用,记为appk,若无,则应用appj完全接收后立即开始运算,得到开始计算时间;若有应用appk尚未结束计算,则将应用appj加入到缓冲队列中,并依照队列长度和应用appk结束运算的时间,设定应用appj的开始计算时间;步骤3.3:依照开始计算时间能够得到结束计算时间和开始转发时间,从而得到了全部应用的调度时间表。根据本发明提供的低延时时间触发网络系统,应用上述的低延时时间触发网络优化方法,包括:一条总线、多个单核处理器,所述多个单核处理器之间通过总线进行互联;在低延时时间触发网络系统中设置有多个同步应用,所述同步应用分别在多个单核处理器和总线上运行;其中,总线上采用分时来执行总线任务,单核处理器用于完成总线消息的接收、运算以及转发。与现有技术相比,本发明具有如下的有益效果:本发明提供的低延时时间触发网络优化方法显著降低了系统的端对端加权时延,与传统采用基于应用固有周期的调度相比,采用基于最小公倍数周期的调度方式,可以将系统端对端加权时延和缩小3.53%,从而提高采用时间触发协议的总线的工作效率。附图说明通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:图1为一个转发的时间流程示意图;图2为本发明中实施例的系统结点连接图。具体实施方式下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。本发明提供的低延时时间触发网络优化方法从系统最小公倍数角度着手,各应用在完成了一个周期的应用之后,在下一个自身周期到达的时候即向总线提出占用申请,然后由总线依照优先级、转发运算数据优先等规则进行总线占用的先后顺序的判断。与按照应用固有周期的调度方式相比,改变各数据在相应结点的发送时间,即每个结点原本只要存储数据首次传输时间,现在改变了其发送时间,就需要存储在最小公倍数周期内数据每次从该结点转发到总线的时间,其它的时间则是最小公倍数周期的重复。以下是对采用时间触发协议的总线中各个元素的建模:系统架构为多个同步应用APP={app1,app2,app3...appz},多个单核处理器Node={n1,n2,n3...nx},一条总线,处理器之间通过总线互联,各应用在多个处理器和总线上运行;总线上分时运行总线任务,处理器上分时运行处理器任务;不失一般性,处理器任务在单个处理器上执行,分三个连续步骤,接收总线消息,运算,发送总线消息;总线任务执行一个步骤,即传输总线消息。如图1所示,图1表示一个转发的时间流程。值得注意的是,在循环中,将ni的转发时长计算到了ni+1的接收时长中,ni表示第i个单核处理器,ni+1表示第i+1个单核处理器;由于数据包在链路上的传递时间是忽略不计的,所以发送节点的发送过程和接收节点对数据包的接受过程被认为是同步的。假设消息传递顺序为n1→n2→n4,通过图1可以得出,在接收消息阶段,用v表示结点对于帧的传输速率(即带宽),表示app1对应的数据帧的帧长,则数据帧完全到达n2的时间为记为fτ(a1,1),计算公式如下:式中:a(a1,1)表示同步应用app1到达第一个结点的时间,a1表示同步应用app1;在运算阶段,设数据在完全到达n2后,开始运算的时间为sc(a1,1),运算所需要的最长时间为tc,则运算完成的时间fc(a1,1)的计算公式如下:fc(a1,1)=sc(a1,1)+tc(2)因为数据在完全接收之后,会涉及优先级等问题,因此在进行运算前,增加了一段缓冲队列,导致了sc(a1,1)≠fτ(a1,1);假设dc(ai,k)表示appi在khop完全接收到开始运算的等待时间,则有如下的计算关系:sc(a1,1)=fτ(a1,1)+dc(a1,1)(3)其中:khop表示同步应用的第k跳,从源结点到第一个结点视为第一跳;在转发消息阶段,设数据转发阶段开始的时间为sτ(a1,1),类似于接收阶段,那么数据从n2完全到达n4的时间fτ(a1,2)满足如下公式:a(a1,2)=sτ(a1,1)(5)式中:a(a1,2)表示同步应用app1到达第二个结点的时间;由于在总线中传送的消息具有时效性,因此,每个同步应用都必须在截止时间前完成传输,即满足如下的条件:式中:表示同步应用app1的截止时间,即app1一个周期的时间;因为在运算结束后,为了避免总线占用发生冲突,需要在开始转发消息前增加一段缓冲队列,设dτ(ai,k)表示appi在khop从结束运算到开始转发的等待时间,则有sτ(a1,1)=fc(a1,1)+dτ(a1,1)(7)则在这个例子中,端到端时延为:式中:dτ(a1,1)表示同步应用app1在第一个结点结束运算后等待转发的时间,表示同步应用app1完成本周期任务的总的端到端时延;进一步引申,当同步应用appi中的运算节点包含多个时,存在如下关系:式中:fτ(ai,ds)表示同步应用appi在最后一个结点完成接收的时间,ds表示同步应用appi的最后一个结点,a(ai,1)表示同步应用appi开始到达第一个结点的时间;k取ds时表示到达了同步应用的最后一个结点;式中:a(ai,ds)表示同步应用appi开始到达最后一个结点的时间,表示同步应用appi传递的数据帧长,dc(ai,k)表示同步应用appi在第k个结点等待计算的时间,tc表示同步应用appi在第k个结点计算所需的时间,dτ(ai,k)表示同步应用appi在第k个结点等待转发的时间;综上所述,即当只考虑一个同步应用的一个周期的时候,其端到端时延满足:在考虑多个同步应用要传输的时候,会有同一结点转发已有任务和发送新任务的冲突,因为优先转发新任务会增加系统总体的端对端时延,因此选择优先转发已有任务。在工业生产中,不同任务的重要程度往往是不同的,因此对不同的任务引入优先级,即针对每个同步应用appi引入了延迟敏系数设A为同步应用的集合,为appi的优先级系数,则定义延迟敏感系数为:在考虑周期性的时候,按照最小公倍数周期的调度方式,设T为最小公倍数周期,则在第q个周期,同步应用appi在第k跳的开始时间接收结束时间开始运算时间运算结束时间以及开始发送时间的计算公式分别如下所示:式中:a(ai,k)表示同步应用appi开始到达第k个结点的时间,fτ(ai,k)表示同步应用appi在第k个结点完全接收的时间,sc(ai,k)表示同步应用appi在第k个结点开始计算的时间,fc(ai,k)表示同步应用appi在第k个结点结束计算的时间,sτ(ai,k)表示同步应用appi在第k个结点开始转发的时间;由此类推,在第q个最小公倍数周期,appi的第个周期,则appi的端到端时延的计算公式如下:或式中:表示同步应用appi在第q个最小公倍数周期的最后一个结点完全接收的时间,表示同步应用appi在第q个最小公倍数周期的第一个结点开始转发的时间,dc(ai,k)表示同步应用appi在第k个结点等待计算的时间,dτ(ai,k)表示同步应用appi在第k个结点等待转发的时间;设A为所有同步应用的集合,L为整个系统的运行时间,则在整个运行时间,系统的端到端时延的计算公式如下:式中:Dappi,q表示appi在第q个最小公倍数周期的端到端时延,*表示乘法运算;就约束条件而言,考虑同一结点发送消息的顺序要求,要求转发已有任务优先发送新任务;各消息的总线占用时间要求,即避免各消息在总线中发生冲突,要求满足如下关系:式中:a(ai,k1)表示同步应用appi开始到达第k1个结点的时间,a(aj,k2)表示同步应用appj开始到达第k2个结点的时间,aj表示同步应用appj,j的取值范围为除i外所有同步应用标号;结点任务的时间要求:c+τ:fc(ai,k1)+dτ(ai,k1)≤sτ(aj,k2)(23)τ+c:fτ(ai,ki)+dc(ai,ki)≤sc(aj,kj)(24)式中:c表示计算任务,τ表示通信任务,fc(ai,k1)表示同步应用appi在第k1个结点完全接收的时间,dτ(ai,k1)表示同步应用appi在第k1个结点等待转发的时间,sτ(aj,k2)表示同步应用appj在第k2个结点开始转发的时间,fτ(ai,k1)表示同步应用appi在第k1个结点完全接收的时间,dc(ai,k1)表示同步应用appi在第k1个结点等待计算的时间,sc(aj,k2)表示同步应用appj在第k2个结点开始计算的时间;结点的处理器计算能力约束:式中:e(ts,n,c)表示运算任务在ts时间段在n结点的执行情况,表示同步应用appi的计算任务,ts表示系统运行期间的任一计算时间间隔。综上所述,可以得到系统的数学模型如下:优化目标:式中:表示系统中所有同步应用的端到端加权时延总和;约束条件:式中:为1表示在此时刻,同步应用appi已经开始本周期运行;为0表示同步应用appi尚未开始本周期运行。本发明采用时间触发协议的总线无冲突调度模型以及基于最小公倍数周期的调度算法。其中:采用时间触发协议的总线无冲突调度模型主要对总线系统中各个元素进行了建模,系统地描述出了任务与任务,任务自身属性之间的约束关系;基于最小公倍数周期的调度算法是从最小公倍数周期的角度触发,对各应用和各任务执行的顺序进行调度排序,使得最终的系统端对端时延和最短。表1系统配置表任务周期(ms)长度(bytes)优先级运算结点接收结点app135121n2n3app2220481n5、n6n4app3410242n4n6app415123n3n2app5310244n1、n3n5app6320481n1n5表2按固有周期调度总线调度表表3按固有周期调度各处理器调度表注:上表中的Inf表示无穷大,即数据到此结点被接受,没有参与运算。表4按最小公倍数周期调度总线调度表表5按最小公倍数周期调度各处理器调度表注:上表中的Inf表示无穷大,即数据到此结点被接受,没有参与运算。表6不同调度策略系统端对端时延和对比表在本示例中,采用了贪心算法进行调度。图2给出了模型的结点连接示意图,表1是网络中的应用及其相关属性。可以看出,本例中有6个同步应用,各应用的周期、数据长度、优先级、运算和接收结点都不尽相同。当按照固有周期进行调度的时候,通过分析总线调度表、结点调度表可以看出,由于存在优先级抢占总线的调度要求和转发运算数据要优先发送新数据的约束要求,如应用4在最小公倍数周期T内每周期首次出现在总线时间表所示,存在一些应用的调度并没有完全遵守基于自身周期的周期性,即:以app4为例,app4的第一个周期在0.0819ms的时候已经结束了总线的占用,而在开始下一周期调度的时候,与app6和app2发生了冲突,由于此时app4已经属于新产生的数据,所有让出了总线,导致了app4不能按照自身周期为调度周期进行调度;在这种前提下,如果各应用的调度策略还是以自身周期为调度周期为主的话,就容易发生下表所示的情况。从表中可以看出,在2.2867ms—2.5734ms期间,总线是处在空闲状态的,而此时app2并没有利用这段空闲时间开始调度,依然是采用以自身周期为调度周期的方式,等到2.5734ms才开始占用总线,导致app5在开始第4周期的时候不仅没有办法按照自身周期在3ms的时候开始占用总线,而且app2因为没有完成全部任务,并且对app5和app4让出了总线,导致了自身端到端时间延迟的增大。鉴于上述情况,提出了基于最小公倍数周期的调度方式,即各应用在完成了一个周期的应用之后,在下一个自身周期到达的时候即向总线提出占用申请,然后由总线依照优先级、转发运算数据优先等规则进行总线占用的先后顺序的判断,得到了相应的总线、各结点调度表如表4、5。由表格可以看出,按照最小公倍数进行调度后的所有应用的端到端加权时间延迟总和比按照应用自身周期为调度周期的调度策略的端到端加权时间延迟总和减少了3.53%。当所有应用都可以在最小应用周期内完成的时候,基于最小公倍数周期调度和基于自身周期调度在端到端时间延迟和上并没有太大的区别,但是当所有应用无法在最小应用周期内全部完成的时候,采用基于最小公倍数周期调度将显著地减小所有应用的端到端加权时间延迟和。以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1