基于K-S检测的STBC-OFDM信号盲识别方法与流程
本发明属于信号处理领域中非合作通信信号处理技术,具体是指一种基于K-S(Kolmogrov-Smirnov,K-S)检测的STBC-OFDM(Space-Time Block Codes,STBC和Orthogonal Frequency Division Multiplexing,OFDM)信号盲识别方法。
背景技术:
近几年,通信信号自动识别已经延伸到军事通信和民用通信领域。例如频谱监测、电子战、软件无线电和认知无线电等。通信信号自动识别要求在无任何发射端的先验信息和前端处理的前提下,能够在较低的信噪比(Signal Noise Ratio,SNR)条件下较好地识别接收端信号参数。因此通信信号自动识别一直是非合作通信研究的热点和难点。大多数关于通信信号自动识别主要是针对单输入单输出(Single Input Single Output,SISO)通信系统的调制识别、单载波与多载波的传输识别、不同的多载波传输识别和信道编码识别。然而目前通信信号自动识别已经延伸到多输入多输出(Multiple Input Multiple Output,MIMO)通信系统,主要是因为其适应无线通信标准,例如IEEE 802.11n、IEEE 802.16e和3GPP LTE。
目前,在非合作处理领域,对STBC-OFDM信号识别还处于起步阶段。在《IEEE Transaction on Communication》杂志的2014年62期“Blind STBC identification for multiple-antenna OFDM systems”一文中,Marey M采用计算接收信号元素的二阶相关函数盲识别STBC信号,取得了较好的结果。但是该算法在低信噪比和低样本条件下识别效果不是很理想。2015年Eldemerdash Y A等人通过定义一种接收序列块的互相关函数识别STBC信号,在低信噪比下识别性能也较理想;但是该方法只能识别Al-OFDM信号和SM-OFDM信号,并未延伸到一般意义上的STBC识别问题。2015年Karami E E等人计算接收序列的二阶循环平稳性,通过估计的CCF(cyclic cross-function)的幅度,比较其幅度与阈值大小盲识别STBC信号。
然而,已有的方法只局限于多接收信号天线的场合,对单接收天线并不适用。单接收天线是多天线的极端情况,主要因为在某些特定的场合,如平台空间、天线大小和造价限制,只能采用单接收天线。考虑到单接收天线特殊情况,还需研究一种单接收天线STBC-OFDM信号盲识别方法。
技术实现要素:
本发明所要解决的技术问题是,针对现有STBC盲识别技术的不足,考虑频率选择瑞利信道模型,提出了一种基于K-S检测的STBC-OFDM信号盲识别方法,能够满足STBC-OFDM信号识别要求,大大提高了识别算法的性能,并且具有较低的计算复杂度。本发明可直接应用于非合作STBC通信系统,也可用于相应的软件无线电等系统。
为解决上述技术问题,本发明是通过以下技术方案实现的:首先将接收信号重新定义为两个不同的信号序列;然后分别求取两个信号序列的时延相关函数,并分析不同STBC的两个时延相关函数分布情况;最后采用基于K-S检测的方法识别不同STBC。该方法不需要噪声信息、调制信息和信道系数等先验信息,适合非合作通信场合。
所述的将接收信号重新定义为两个不同的信号序列为:考虑具有NTx个发射天线和接收天线NRx=1的STBC-OFDM通信系统,与单载波系统不同的是,STBC-OFDM系统以块为单位进行空时编码。假定发射的符号是复线性调制(如QPSK)且独立同分布随机变量。对于复调制,它的实部和虚部也是独立同分布的。设OFDM块的长度为N,设每个编码矩阵传递的符号数量为L,设编码矩阵的长度为U。输入单个OFDM块的数据流为:
st=[st(0),st(1),…,st(N-1)] (1)
因此,第k组的数据块[sLk,sLk+1,…,sLk+l],其中,l=0,1,…,L-1。进行空时编码后的编码矩阵为C(sLk,sLk+1,…,sLk+l)。
根据OFDM的调制原理,和u=0,1,…,U-1进行反傅立叶变化(IFFT)即可得到时域的OFDM块
为了减小符号间干扰(ISI)和载波间干扰(ICI),需要在前加入长度为v的前缀,共同构成新的OFDM块
天线i的发射序列为xi:
其中,NB为OFDM块的个数,x(i)中第k个元素为x(i)(k)。
因此,接收信号为:
其中,hi(p)代表第i个发射天线和接收天线对应的p路径信道系数,w(k)代表零均值方差为复高斯白噪声,path代表路径的数量。
将长度为K的接收信号y(k)重新分为两个相互重叠的子序列p1和p2:
p1=[y(0),y(1),…,y(K-t-1)] (6)
p2=[y(t),y(t+1),…,y(K-1)] (7)
其中,t代表下文中相关函数的时延。
所述的分别求取两个信号序列的时延相关函数,并分析不同STBC的两个时延相关函数分布情况为:
在接收端,单个OFDM块gUk+u可表示为:
gUk+u=[yUk+u(N-v)…yUk+u(0)…yUk+u(N-1)]T (8)
因此,接收天线接收的OFDM块R可表示为:
其中,NB为OFDM块的个数,R是(N+v)×NB维矩阵,gi代表接收的单个OFDM块。定义两个长度为NB-t的块矩阵:
定义R0和R1中列向量之间的相关函数为:
xi(k)=|[Ri(:,2tk)]TRi(:,2tk+t)| (12)
其中,i=0,1,|·|代表取绝对值,:代表取块矩阵Ri的所有行。不失一般性,设NBmod2t=0,如果其值不为零,可对接收块矩阵R进行处理,去掉尾部NBmod2t=0向量gi。
因此得到自相关向量Xi为:
X0=[x0(0),x0(1),…,x0(M-1)] (13)
X1=[x1(0),x1(1),…,x1(M-1)] (14)
其中,
以Al-OFDM和SM-OFDM码为例,Al码长为2,SM的码长为1,因此取t=1。
对于SM-OFDM编码,第gUk+u-1和gUk+u个OFDM块是独立的,而Al-OFDM编码,第gUk+u-1和gUk+u个OFDM块可能是独立的,也可能是不独立的,取决与gUk+u-1和gUk+u是否在同一编码矩阵内。由式(13)和(14)可知,对于SM-OFDM编码,由于接收OFDM块R的列向量gUk+u是独立同分布向量,因此向量X0和X1均为独立同分布;而对于Al-OFDM编码,由于接收OFDM块R的列向量gUk+u并不是独立同分布的向量,因此向量X0和X1并非是独立同分布。由于在非合作通信中,接收到的第一个OFDM块并不一定是对应Al-OFDM的第一列,因此可能存在两种情况:
Event1:接收的第一个OFDM块若不是对应Al-OFDM的开始,第gUk+u-1和gUk+u个OFDM块是独立的,X1是独立同分布,而X0不是独立同分布。
Event2:接收的第一个OFDM块若是对应Al-OFDM的开始,X0是独立同分布,而X1不是独立同分布。
因此可以通过判定向量X0和X1是否为独立同分布区分SM-OFDM和Al-OFDM编码。同样,t取合适的值,也可以区分其他的码型。
记Event1和Event2任意事件发生的情况为事件Event,若向量X0和X1为独立同分布的情况为iid。记事件Non为未定事件:可能是事件Event,也可能是事件iid。如表1所示,在t∈{1,2,4}时STBC-OFDM对应事件的分布情况,以此作为特征参数区分集合Ω={SM-OFDM,Al-OFDM,ST3-OFDM,ST4-OFDM},可以用一个决策树表示。每一个分支可以用二元假设检验完成,定义事件iid为假设检验的H0,定义非iid为假设检验的H1:
H0:X0和X1均为独立同分布
H1:X0和X1不都为独立同分布
表1 t不同时,STBC-OFDM对应事件
整个决策树的过程为:当t=4时,拒绝H0的STBC-OFDM为ST4-OFDM;当t=2时,拒绝H0的STBC-OFDM为ST3-OFDM;当t=1时,拒绝H0的STBC-OFDM为Al-OFDM。
所述的采用基于K-S检测的方法识别不同STBC为,定义和为向量X0和X1的经验分布函数:
其中M为向量Xi,i=0,1的长度;Ind(.)为指示函数,当输入参数为真时,Fi(z)返回值1;当输入参数为假时,Fi(z)返回值0。两个分布函数之间最大距离可表示为:
作为拟合优度统计值,当成立,拒绝H0,其中
为K-S检验的估计,β为门限值,α为置信区间,可表示为:
其中,
与现有技术相比,本发明的有益效果是:
(1)能够在较低的信噪比条件下识别STBC-OFDM信号类型,能够满足实际应用,且计算复杂度较低。
(2)不需要预先估计噪声信息、调制信息和信道系数等先验信息,适合于非合作通信场合,有很强的军事意义。在不同调制方式、载波频偏和非高斯噪声下算法的稳健性较好。
(3)在频率选择性瑞利衰落信道条件下对STBC-OFDM信号盲识别,与高速传输的信道环境相符合。
附图说明
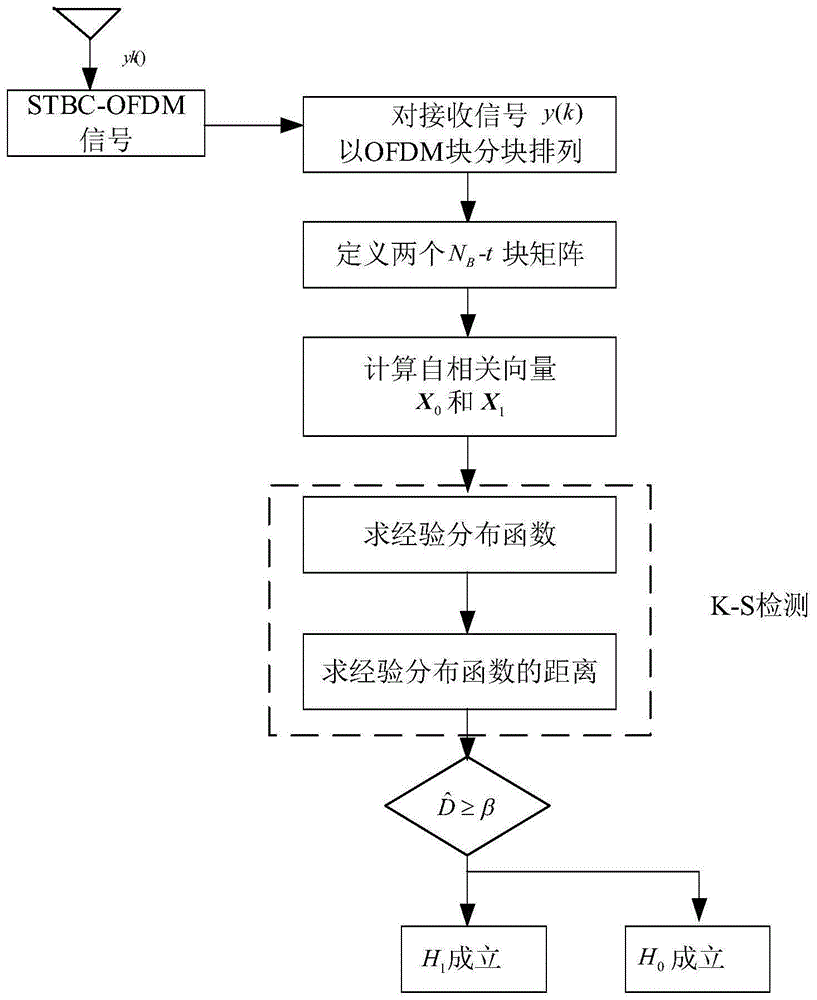
图1是本发明所述方法的总体流程图;
图2是STBC-OFDM信号发射结构;
图3是计算自相关向量X1和X2原理图;
图4是树型识别方案;
图5是实例中不同的STBC-OFDM信号识别性能比较;
图6是实例中不同子载波数量时STBC-OFDM的识别性能比较;
图7是实例中不同块数量时STBC-OFDM的识别性能比较;
图8是实例中不同前缀长度时STBC-OFDM的识别性能比较;
具体实施方式
下面结合附图和实施例对本发明进一步详细描述。
图1是本发明的总体流程图,本实施例所述方法实现过程如下:
(1)截获单根接收天线的STBC-OFDM信号y(k);
(2)对截获信号y(k)以OFDM块为单位分组,定义新的OFDM块矩阵R,定义两个新的长度为NB-t的块矩阵R0和R1,
(3)并且计算列向量的自相关向量Xi;
(4)计算门限值β;
(5)求取经验累积分布函数Fi(z),并计算Fi(z)之间最大距离
(6)如果判定H0成立,否则判定H1成立。
实施例中:OFDM信号是基于IEEE802.11e标准,OFDM符号子载波个数N=256,循环前缀长度为v=N/4,接收天线的个数为NRx=1,接收的OFDM块数量NB=2000,置信区间99%,信道采用频率选择性瑞利衰落信道,且包含4条统计独立的路径,以上4条路径具有指数功率时延且σ2(p)=exp(-p/5),p=0,1,...,path-1。噪声为零均值加性高斯白噪声,且信噪比信号采用QPSK调制方式,采用正确识别概率P(λ|λ),λ∈{SM-OFDM,Al-OFDM,ST3-OFDM,ST4-OFDM}和平均识别概率Pc衡量算法的性能。
图5给出了不同的STBC-OFDM信号的正确识别概率。从图5中可以看出,SM-OFDM识别效果最好,SM-OFDM正确识别概率接近置信区间0.99;ST3-OFDM的识别效果最差,这是因为ST3-OFDM码矩阵中包含符号0,这将影响Xi的分布特性,使得经验分布函数和之间的距离变小,从而导致ST3-OFDM在低信噪比下识别效果不理想。Al-OFDM、ST3-OFDM和ST4-OFDM的识别性能随着信噪比SNR的提高而提高。主要原因是由于在低信噪比环境下,强噪声使得经验分布函数和之间的距离变小,从而使得STBC-OFDM的识别性能在低SNR识别效果不理想。
图6给出了子载波N为64、128、256、512时平均正确识别概率Pc随子载波变化的曲线。由图6可以看出,在低信噪比下识别性能随着子载波个数提高性能提高。主要是当子载波数目N增加,式(9)中的OFDMgUk+u块的元素增多,R0和R1中列向量之间的相关函数xi(k)更准确,从而使经验分布函数和更精确,因此,它的正确识别概率随着子载波的个数而提高。
图7给出了OFDM块数量为1000、2000、3000、4000时,平均正确识别概率Pc随OFDM块变化曲线。由图7可以看出,在低信噪比环境下平均正确识别概率Pc在OFDM块数量为4000时识别效果更理想,而在高信噪比下,OFDM块数量为1000识别效果最不理想,其他的OFDM块数量下平均正确识别概率都达到1。当OFDM块数量较小,如果t取值过大时会使经验分布函数和中元素较小,不利于抑制噪声和信道对经验分布函数的影响,从而导致ST3-OFDM和ST4-OFDM的正确识别概率较低,从而影响了平均正确概率Pc。
图8给出了前缀长度为N/4、N/16、N/32时,平均正确识别概率Pc随前缀长度变化曲线。由图8可以看出,算法的性能基本不随前缀v长度变化,主要是因为前缀长度并不改变相关函数的估计值,也不影响它的自相关函数Xi的估计值,进而也不影响它的经验分布函数估计值的计算。所以前缀长度v对算法基本无影响。
- 还没有人留言评论。精彩留言会获得点赞!