IPTV视频业务中用户满意度的智能化预测方法与流程
本发明涉及IPTV视频业务数据的智能化处理领域,尤其是涉及IPTV视频业务中用户满意度的智能化预测方法。
背景技术:
作为电视与互联网融合的产物,IPTV满足了人们愈来愈趋向于多样化、专业化和个性化的视音频需求,给广播电视行业带来了巨大的变化,并且为电视受众带来一场新的电视消费革命。但是,互联网视频生态系统(包括内容提供者,内容传输网络,分析服务商,视频播放器设计师和用户)面临一个迫在眉睫的挑战,即缺乏一个能够预测用户满意度这一具有强烈主观特性的指标的标准方法。
在现有的解决方案中,对于用户满意度的度量和标注,常常采用用户主观打分来进行量化的方式,这样虽然相对直接,但是也存在一些问题,如:当IPTV视频业务数据量很大的时候,这种方式耗时耗力、参与打分的用户所受的环境因素和自身当时状态的因素影响较大,因而不可能大范围应用。此外,目前很多方法试图去寻找并建立IPTV视频业务传输相关参数和用户满意度之间的显式的映射关系,而这样的关系常常不能够全面的反映二者之间真实和内在的联系。因而需要解决两方面问题,包括:(1)寻找能够体现IPTV视频业务中用户满意度的指标,解放主观打分所带来的局限性。(2)寻找IPTV视频业务中用户满意度和IPTV视频传输相关参数的内在关联。基于此,本发明致力于解决现有技术存在的一些技术缺陷,很好地解决了IPTV视频业务中用户满意度的智能化预测问题。
技术实现要素:
本发明目的在于针对上述现有技术的缺陷,提出了一种IPTV视频业务中用户满意度的智能化预测方法,该方法很好地解决了现有用户满意度预测方法中需要通过主观打分来度量用户满意度以及用户满意度与其影响因素之间内在关联性建模不够准确合理的问题。本发明的实施流程为:首先确定影响用户满意度的因素,而后用用户使用业务时长来客观度量用户满意度,接着通过训练建立CART树模型,并用其将带预测数据划分到相关区域,在该区域内用KNN搜索,并最终用距离加权平均值作为预测结果。采用本发明的方法,可以有效地降低预测过程中的运算量,并且可以使得预测精度得到了较大的提升。
本发明解决其技术问题所采取的技术方案是:一种IPTV视频业务中用户满意度的智能化预测方法,该方法包括如下步骤:
步骤1:确定影响用户满意度的因素:从IPTV机顶盒收集的视频业务的关键性能指标(KPI)原始记录中,挑选固定时间长度的KPI数据,每条KPI数据中包含6个属性:设备传输时延df、设备传输抖动jit、设备丢包率lp、平均传输比特率br、业务开始时间、业务结束时间。该时间长度内各个用户的所有KPI数据的前4个属性{df,jit,lp,br}的平均值作为影响用户满意度的因素其中xn=(xn,df,xn,jit,xn,lp,xn,br)。
步骤2:确定用户满意度的客观度量:将每个用户固定时间长度内的每个KPI数据中的结束时间减去开始时间,并将其累加,得到用户在该固定时间长度内使用业务的时长,即,
步骤3:建立分类回归(CART)树模型及训练:
(3-1)将(X,Y)作为训练数据,对于X中的某个属性j(j∈{df,jit,lp,br}),用其作为切分变量;对于该切分变量j,选择切分点s,将X划分成两个区域:R1(j,s)={xn|xn,j≤s}和R2(j,s)={xn|xn,j>s}
(3-2)分别求两个区域中的xn对应的yn的均值c1和c2,即其中N1和N2分别为两个区域中的数据数目。
(3-3)计算平方误差:
(3-4)遍历所有的j和s,选择使得平方误差最小的最优值j*和s*作为分类回归树第一层切分变量和切分点,即,(j*,s*)=argminError(j,s);用最终选定的(j*,s*)划分出子区域R1(j*,s*),R2(j*,s*),保存落在每个子区域的训练数据D1,D2,如下:
R1(j*,s*)={xn|xn,j*≤s*},R2(j*,s*)={xn|xn,j*>s*}
D1={(xn,yn)|xn∈R1(j*,s*)},D2={(xn,yn)|xn∈R2(j*,s*)}
(3-5)对已划分好的两个子区域,考虑剩余的属性,调用(3-1)~(3-4)的步骤,继续对每个子区域进行进一步划分,并对划分好的二级、三级子区域中的训练数据进行存储,直至满足停止条件。需要说明的是,这里的停止条件为所有的4个属性已经全部被遍历或者在子区域生成过程中计算出的Error(j,s)的最小值低于阈值ε;通过本步骤,最终生成CART树;
步骤4:预测用户满意度。
(4-1)对于待预测用户满意度的数据x',按照所生成的CART树的结构,自上而下,将其分配到相应的叶节点所在的区域,设该区域为D'。
(4-2)对于x',在D'中做KNN搜索,基于欧氏距离找到其中的K个近邻数据,计算距离加权平均值,用该均值作为最终的预测值输出y',即:
其中
上式中d(x',xk)为x'与其邻居节点xk的欧氏距离。
进一步的,本发明应用于IPTV视频业务。
有益效果:
1.本发明将用户体验时长作为用户满意度的客观度量,很好地解决了现有方法中需要用户进行主观评价打分所带来的代价过高、受环境因素影响较大等缺点。
2.本发明在影响用户满意度的因素和用户体验视频业务的时长之间建立的是回归模型,很好地解决了现有方法基于分类模型来进行用户满意度预测所带来的精确度不高的问题。
3.本发明采用CART树将待预测数据进行划分,而后在所在区域内进行KNN,大大的减轻了运算量和搜索开销。
4.本发明在用KNN预测用户体验时长时,用了距离加权平均值,根据K个最近邻的贡献进行加权加权,将较大的权值赋给较近的近邻,提高了最终预测的准确率。
附图说明
图1为IPTV视频业务中用户满意度的智能化预测方法流程图。
图2为本发明的方法与三种现有的回归方法的误差对比结果。
图3为本发明的方法与三种现有的回归方法的相关系数对比结果。
图4为本发明的方法与KNN、CART方法在不同训练与预测数据比例下的误差对比结果。
图5为本发明的方法与KNN、CART方法在不同训练与预测数据比例下的相关系数对比结果。
具体实施方式
下面结合说明书附图和具体实例对本发明作进一步的详细说明。
如图1所示,本发明提供了一种IPTV视频业务中用户满意度的智能化预测方法,该方法包括如下步骤:
步骤1:确定影响用户满意度的因素:从IPTV机顶盒收集的视频业务的关键性能指标(即KPI)数据中,挑选不同用户在固定时间长度(如30分钟)的KPI数据,每条KPI数据中包含6个属性:设备传输时延df、设备传输抖动jit、设备丢包率lp、平均传输比特率br、业务开始时间、业务结束时间。将固定时间长度内某个用户各条KPI数据的前4个属性{df,jit,lp,br}的平均值作为影响用户满意度的因素,其可以反映在该时间段内的网络状况。即,将其用作本方法的输入其中xn=(xn,df,xn,jit,xn,lp,xn,br)。
步骤2:确定用户满意度的客观度量:当用户对现有视频业务满意度高时,其会长时间观看该视频/使用该业务,反之,则使用该业务的时间较短。基于此,摒弃传统的用户打分的满意度度量方式,采用用户体验业务的时长来间接、客观地衡量用户的满意度。即,统计每个用户在固定时间长度内的KPI数据,如现有IPTV机顶盒每5分钟有一条KPI记录,在30分钟这一时间段内,则可能有0~5条KPI数据。将每条KPI中的结束时间减去开始时间,并将其累加,得到用户在30分钟内使用某业务的时长,即,
步骤3:建立分类回归(即CART)树模型及训练:将已经统计好的带有用户使用业务时长的数据作为训练数据,即训练数据集为(X,Y)。
(3-1)对于X中的某个属性j(j∈{df,jit,lp,br}),用其作为切分变量;对于该切分变量j,选择切分点s,将X划分成两个区域:R1(j,s)={xn|xn,j≤s}和R2(j,s)={xn|xn,j>s}
(3-2)分别求两个区域中的xn对应的yn的均值c1和c2,即其中N1和N2分别为两个区域中的数据数目。
(3-3)计算平方误差:
(3-4)遍历所有的j和s,选择使得平方误差最小的最优值j*和s*作为分类回归树第一层切分变量和切分点,即,(j*,s*)=argminError(j,s);用最终选定的(j*,s*)划分出子区域R1(j*,s*),R2(j*,s*),保存落在该区域的训练数据D1,D2,如下:
R1(j*,s*)={xn|xn,j*≤s*},R2(j*,s*)={xn|xn,j*>s*}
D1={(xn,yn)|xn∈R1(j*,s*)},D2={(xn,yn)|xn∈R2(j*,s*)}
(3-5)对已划分好的两个子区域,考虑剩余的属性,调用(3-1)~(3-4)的步骤,继续对每个子区域进行划分,并对划分好的二级、三级子区域中的训练数据进行存储,直至满足停止条件。需要说明的是,这里的停止条件为所有的4个属性已经全部被遍历或者在子区域生成过程中计算出的Error(j,s)的最小值低于阈值ε。ε通常取0.01。通过这样的方式,生成CART树。
步骤4:预测用户满意度:
(4-1)对于待预测用户满意度的数据x'(x'的产生方式和X中的数据相同,y'未知待预测),按照所生成的CART树的结构,自上而下,将其分配到相应的叶节点所在的区域,设该区域为D'。
(4-2)对于x',在D'中做KNN搜索,基于欧氏距离找到其中的K个近邻数据,计算距离加权平均值,用该均值作为最终的预测值输出y',即:
其中
上式中d(x',xk)为x'与其邻居节点xk的欧氏距离。
实施例及性能评价
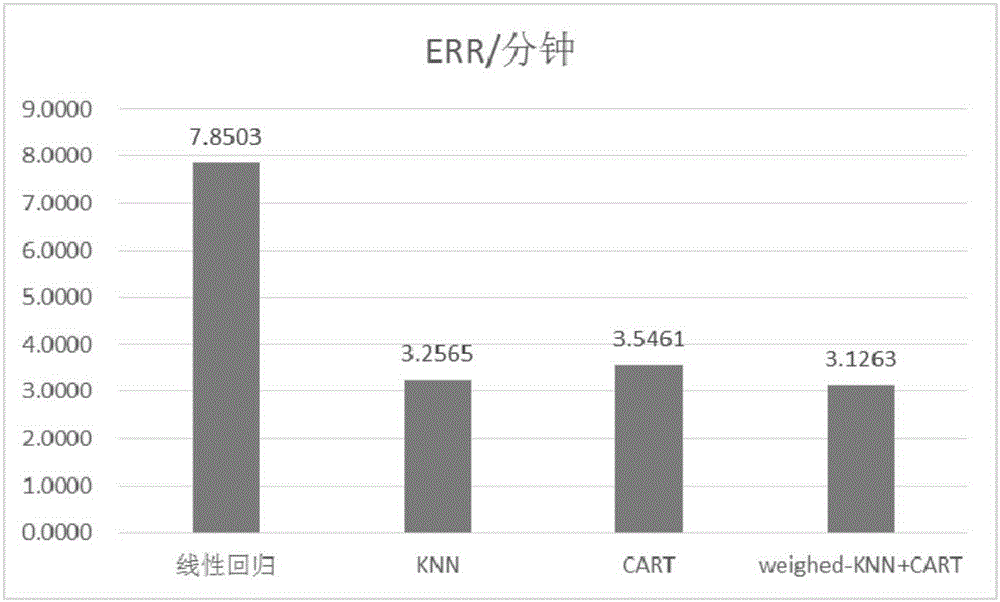
为了更好地说明本发明所设计的IPTV视频业务中用户满意度的智能化预测方法的优势,对来自于IPTV机顶盒的35160条视频业务数据,采用本发明的方法的步骤1和步骤2进行处理,得到影响用户满意度的因素的输入数据和用户使用业务的时长,在其中随机抽取50%的数据作为训练数据(X,Y),剩下的数据用于预测。为了比较本发明所提出的预测方法的性能,分别使用线性回归、KNN、CART、以及本发明方法(即:用weighted-KNN-CART表示)进行训练和预测,重复50次实验,得到的平均参数如图2和图3所示。
图2比较了四种方法的预测误差,其为所有待预测样本(假设为M条)所预测出的y'与其真实值之间的绝对误差的。绝对误差的计算公式如下:
图3比较了四种方法预测出y'与其真实值之间的相关系数,该系数的绝对值越大,表明y'与关联性越大。相关系数的计算公式如下:
从图2和图3中可以看出,使用线性回归方法得到预测误差较大,相关性较小,所以影响用户满意度的网络性能参数和用户使用业务的时长并不是单纯的线性关系。在训练和预测数据1:1情况下,本发明方法获得了最优的性能。
众所周知,如果可以用较少量训练数据生成的模型,对较大数据量都有很好的预测性能,或预测性能下降很小,说明所建立的模型具有较高的鲁棒性。基于此,调整用于训练和预测数据之间的比例,使其分别为1:0.5、1:1、1:1.5、1:2倍的情况下,依然进行50次实验,三种方法(KNN,CART以及本发明所设计weighted-KNN-CART)的误差和相关系数分别如图4和图5所示,可以看出,本发明的方法的性能最优。
- 还没有人留言评论。精彩留言会获得点赞!