一种用于发布北斗地基增强系统的智能分组方法和装置与流程
本发明涉及一种应用发布的方法和装置,尤其涉及一种用于发布北斗地基增强系统的智能分组方法和装置。
背景技术:
北斗地基增强系统可以显著或成倍提高定位和授时精度,可时终端的定位精度提高到米级以内。目前北斗地基增强系统的关于应用发布及回滚主要通过以下方式:
首先通过文本记录各个省份此次进行发布的接收机IP地址、及所对应的版本信息;然后人为手工的依次进行各个区域基站接收机的应用发布、版本升级操作。一旦发生故障或变更,然后同样以方式进行回滚发布操作,且所有负责各区域的集成商代维需要待命,确保因一些远程无法处理的故障可在现场进行维护。而且需要人为的把所有需要发布升级的IP地址、版本信息维护进文本中,然后通过文本进行手工一台台核对并进行发布操作,国内各省份及区域的基站接收机越来越多,这样的方式即耗时耗力也容易出错。由于进行应用发布、版本升级并不是100%可靠,如果当中出现了变更,也需要以同样的方式进行回滚发布,无论发布是否成功,大量的人力投入也是个问题。
技术实现要素:
针对上述问题,本发明提出一种用于发布北斗地基增强系统的智能分组方法,包括以下步骤:
步骤01:通过客户端网络协议来获取收集远端各个接收机的节点信息,按照程序所定义的数据模版格式导入程序中,程序在内存中组合成一个带有索引的线性表,其中还有个包含动态数组子表,用于专门存放所有待分组的节点数,记为第一动态数组;
步骤02,程序对外提供给客户端2个接口用以自定义分组的策略配置,所述接口分别命名为第一接口和第二接口:
第一接口:用于指定在进行应用发布中的第一组节点群的数量。
第二接口:用于指定在进行应用发布中除第一组之外的组内节点群的数量;
步骤03,首先内部初始化生成一个动态数组记为第二动态数组,并且为其划分2个内存地址空间,记为第一索引和第二索引,所述第一索引的索引指针为0,用于存放版本信息;所述第二索引的索引指针为1,用作存放所述第一动态数组所分组后的结果;接着用所述线性表把索引指针移动到所述第一索引和所述第二索引,分别获取版本信息和所有待分组的节点,之后先把所述版本信息存放在所述第一索引中,然后把所述第二索引的节点信息,根据客户端所定义好的所述第一接口和所述第二接口的数据,构建成一种可包含多子树的树数据结构;
步骤04,将分组后的结果进行输出,供发布系统进行调用和操作。
步骤01客户端网络协议可以为简单网络管理协议。
构建成一种可包含多子树的树数据结构包括如下方法:设n为根结点、x为分组数值且其初始化值为1,即x=1;把树的最左子树值设为T作为第一组,即T=1;每组的叶子结点作为存放每组包含的接收机数值;
每一个树结点都有两个用于引用其它结点的属性,第一个引用指向的是当前结点的第一个子结点,而第二个引用所指向的则是其下一个兄弟结点,形成一个多路搜索树的数据结构。
形成一个多路搜索树的数据结构还包括如下方法:
计算所述第一接口:通过所述第一接口的数值作为索引值,然后使用分片技术得到所述第一组包含节点元素的范围;
计算所述第二接口:通过除去所述第一组之外的所有节点进行递归T+(x+1)次;所述第二接口的数值作为遍历的条件次数,在遍历的过程中把所述第一动态数组中的节点依次附加到所述第二动态数组中的索引指针为1的内存地址空间;
计算得出所有的节点的分组数值,以及每组可包含的节点数值,每次递归后得到新子树的结果保存在缓存中,每次计算新组时把上一子树的结果从缓存中获取并直接计算;每一个发布版本即是一颗树n,而多个版本就是多棵树,构成了一片树林的数据结构。
一种用于发布北斗地基增强系统的智能分组装置,包括:
收集模块,用来收集基站接收机集群节点信息;
策略模块,与收集模块相连接,提供给客户端进行可自定义分组策略设置;
分组模块,与策略模块相连接,根据收集模块收集的发布条件和策略模块定义的分组策略进行分组运算;
输出模块,与分组模块相连接,根据分组模块的运算将分组结果格式化为一种通用型结构并输出给发布系统。
本发明技术方案实现的有益效果:
本发明可以提供给客户端两个简单的接口用于自定义分组策略,将一个或多个不同的发布版本所对应的大量节点集群,进行动态的分成若干个组,且每组包含多个节点。通过这些分组后的结果,客户端可以自行选择需要进行发布组中的节点群,用来帮助提高发布的可靠、可控性,降低人力维护成本。
附图说明
图1是本发明一种用于发布北斗地基增强系统的智能分组方法的步骤示意图。
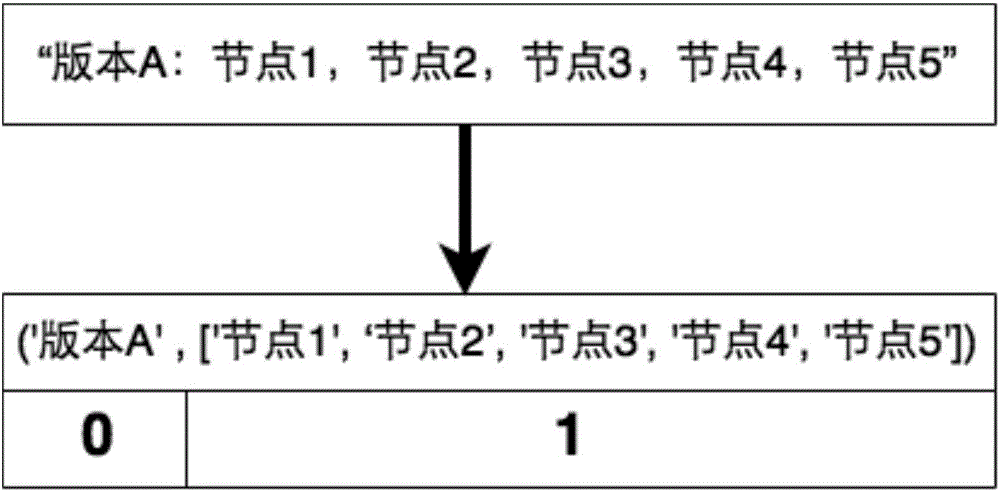
图2是本发明一种用于发布北斗地基增强系统的智能分组方法中动态数组示例。
图3是本发明一种用于发布北斗地基增强系统的智能分组方法的树数据结构示意图。
图4是经动态规划算法优化后的树结构示意图。
图5是多树的数据结构示意图。
图6是本发明一种用于发布北斗地基增强系统的智能分组方法的完整的工作流程。
图7是本发明一种用于发布北斗地基增强系统的智能分组装置的示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐述本发明,本发明实施例仅用以说明本发明的技术方案而非限制本发明的保护范围。
本发明的实施方式公开了一种用于发布北斗地基增强系统的智能分组方法,如图1该方法包括以下步骤:
首先根据步骤01,通过客户端SNMP协议或其他网络协议来获取收集远端各个接收机的节点信息,按照程序所定义的数据模版格式导入程序中,程序在内存中组合成一个带有索引的线性表,其中还有个包含动态数组子表,用于专门存放所有待分组的节点数,记为第一动态数组,如图2;
步骤02,程序对外提供给客户端2个接口用以自定义分组的策略配置,该接口分别以第一接口和第二接口来描述其作用:
第一接口:用于指定在进行应用发布中的第一组节点群的数量。
例:第一接口定义整数3,那么第一组所包含的节点数为3台接收机。
第二接口:用于指定在进行应用发布中除第一组之外的组内节点群的数量。
例:第二接口定义整数5,那么除第一组外的其它组中,每组所包所的节点数为5。
步骤03,首先内部会初始化一个动态数组记为第二动态数组,并且为其划分2个内存地址空间,即索引为0和1,其0用于存放版本信息,其1用作存放第一动态数组所分组后的结果;接着用图2定义好的线性表把索引指针移动到0和1,分别获取版本信息和所有待分组的节点,之后先把版本信息存放在第二动态数组的索引指针0中,然后把图2中索引为1的节点信息,根据客户端所定义好的第一接口和第二接口的数据,通过递归技术以及参考了分治算法的思想来构建成一种可包含多子树的树数据结构中,结合图3大致实现的描述如下:
设n为根结点、x为分了多少次组并初始化1,即x=1;把树的最左子树设T作为第一组,即T=1;把每组的叶子结点作为存放每组包含多少个接收机节点元素,设为k个节点。
初步实现这种树结构的思路是每一个树结点都有两个用于引用其它结点的“指针”或属性。第一个引用指向的是当前结点的第一个子结点,而第二个引用所指向的则是其下一个兄弟结点。换句话说,这里的各个结点所应用的是一个(其子结点)兄弟结点链表,并且这些兄弟结点各自引用了属于它们自己的那个兄弟结点链表(见图3的虚线箭头),这样就实现了一个多路搜索树的数据结构。
图3中的“计算A”:通过第一接口的数值作为索引值,然后使用分片技术就可以得到第一组包含节点元素的范围。
图3中的“计算B”:通过除去第1组之外的所有节点进行递归T+(x+1)次组。因为每次递归中会把第二接口的数值作为遍历的条件次数,在遍历的过程中把第一动态数组中的节点依次附加到第二动态数组中的索引指针为1的内存地址空间。
通过以上计算方法就能根据对外提供给客户端的2个自定义分组策略得出所有的节点可分成多少个组,以及每组可包含多少个节点。由图3观察也可以看出,当接收机的节点数越大,所分的组数量也就越多,因此得出所构建子树也就越多,但其实子树和子树之间并不是相互独立的。所以用分治法来解这类问题,则分解得到的子问题数目太多,以至于最后解决原问题需要耗费指数时间。进一步的分析,在用分治法求解时,有些子问题被重复计算了许多次。如果能够保存已经解决的子问题的答案,而在需要时再找出已求解的答案,这样就可以避免大量重复计算。所以通过参考动态规划算法的思想,把每次递归后得到新子树的结果保存在缓存中,每次计算新组时,只需要把上一子树的结果从缓存中获取并直接计算即可,而无需在从头把上一子树的结果计算一遍,这样可大大提供算法的性能,如图4是优化后的结果。
通过这一思路而知,每一个发布版本即是一颗树n,而多个版本,就是多棵树,即形成了一片树林的数据结构N,由此实现了针对单、多版本的应用发布动态分组的技术功能,如图5。
步骤04,将分组后的结果进行输出,供发布系统进行调用和操作,图6为完整的工作流程。
与上述方法相对应,本发明实施例还提供了一种用于发布北斗地基增强系统的智能分组装置,如图7所示,该装置包括:
收集模块71:用来收集基站接收机集群节点信息;
策略模块72:与收集模块71相连接,提供给客户端进行可自定义分组策略设置;
分组模块73:与策略模块72相连接,根据收集模块71收集的发布条件和策略模块72定义的分组策略进行分组运算;
输出模块74:与分组模块73相连接,根据分组模块73的运算将分组结果格式化为一种通用型结构并输出给发布系统。
- 还没有人留言评论。精彩留言会获得点赞!