一种增加新主播留存的方法与系统与流程
本发明涉及互联网直播技术,尤其涉及一种增加新主播留存的方法与系统。
背景技术:
随着直播行业的快速发展,各行各业的人开始进入直播行业,但新主播一般人气都很低,没有人与主播一起弹幕互动,主播很容易失去直播的兴趣,所以新主播很容易流失。为了增加新主播的直播热情,让新主播能顺利度过人气较低的初始直播期,本方案描述了一种增加新主播留存的解决方案。该方案通过在新主播直播间中增加智能聊天机器人和语音识别的方法,与主播进行弹幕互动。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种增加新主播留存的方法与系统。
本发明解决其技术问题所采用的技术方案是:一种增加新主播留存的方法,包括:
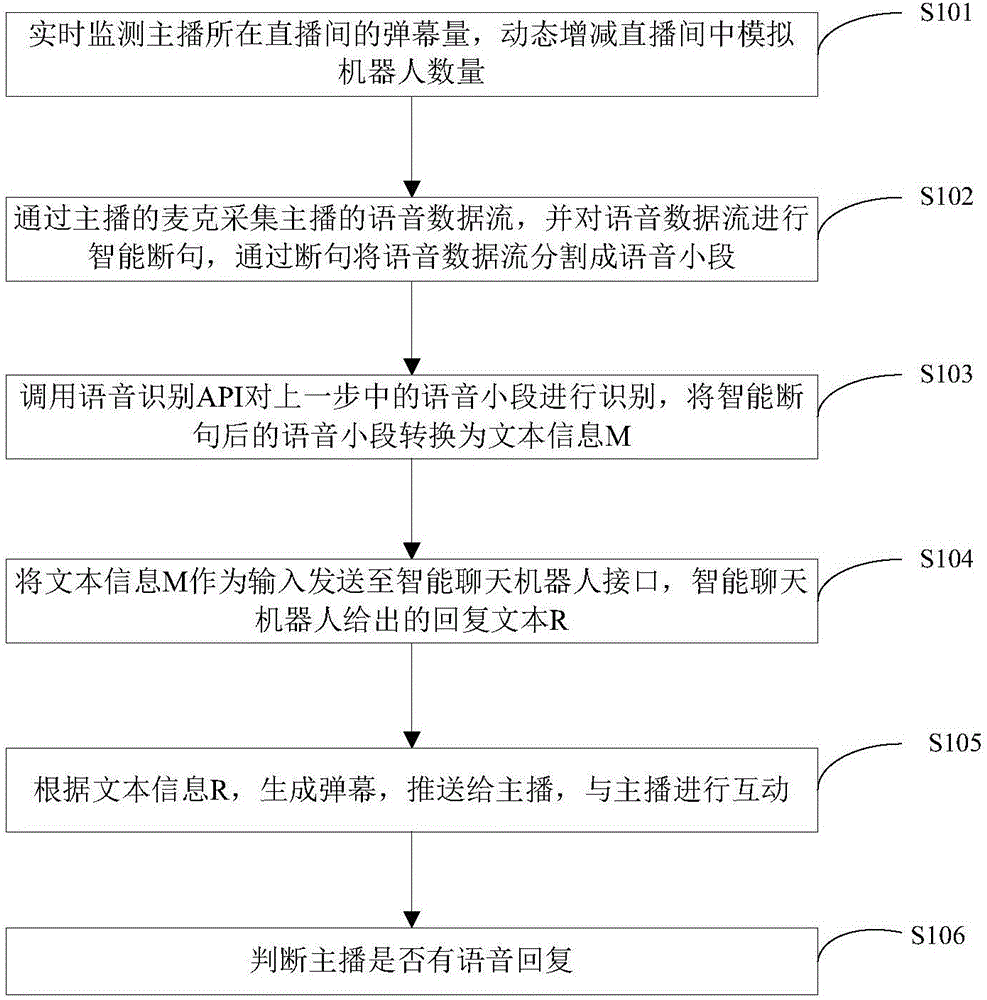
1)实时监测主播所在直播间的弹幕量,动态增减直播间中智能聊天机器人数量;
2)采集主播的语音数据流,并对语音数据流进行智能断句,通过断句将语音数据流分割成语音小段;
3)调用语音识别API对上一步中的语音小段进行识别,将智能断句后的语音小段转换为文本信息M。
4)将文本信息M作为输入发送至智能聊天机器人接口,智能聊天机器人给出的回复文本R;
5)根据步骤4)得到的文本信息R,生成弹幕,推送给主播;
6)判断主播是否有语音回复,如果有,则重复步骤1)至5),直接进行主播与智能聊天机器人之间的弹幕互动;如果判断主播没有语音回复,则发布初始设置的弹幕。
按上述方案,所述步骤2)中对语音数据流进行智能断句具体如下:采用基于熵的语音信号端点检测方法,构造一个语音信息熵函数,用以从一段语音流中提取主播的语音信息,剔除噪声信息;当把语音帧的标准化幅度谱|X(i)|看作一个概率分布时,谱域的熵计算可以取第i个幅度谱的概率来代替取第i个信源符号的概率P(Si),即用以下公式表示:
那么,语音谱的熵可以表示如下:
计算出熵值后根据熵值大小对语音数据流进行智能断句:相对于背景噪声而言,语音信号中的语音段幅度变化的绝对值大于设定阈值,熵值大;而静音段的幅度变化的绝对值小于设定阈值,分布相对集中,熵值小。
按上述方案,所述步骤5)中生成弹幕的方法为:首先创建一个模拟机器人账户,并随机从预先设定好的ID与昵称库中,选择一个作为该模拟机器人的昵称;然后模拟机器人模拟正常观众登录进入主播的直播间;最后调用直播应用自带的弹幕发送接口,将步骤4)得到的文本信息R通过接口发送到聊天室中。
按上述方案,所述模拟机器人登入直播间时有以下登入效果:为模拟机器人增加随机的等级与网站头衔,当模拟机器人进入直播间时,增加对模拟机器人的进直播间欢迎语句,增加对特殊头衔的欢迎特效。
按上述方案,所述步骤1)中对直播间机器人数量的动态增减采用以下方法:当主播直播间人气值低于人气阈值T1时,增加设定数量的智能聊天机器人,当直播间人气值达到或超过人气阈值T1时,减少设定数量的智能聊天机器人;所述直播间人气值P,由后台数据库维护,当人气值P<T1,T1=100时,表示直播间人气不足,需要引入一定数量的智能聊天机器人;当人气值P≥T1,T1=100时,表示直播间人气值上升了,需要减少一定数量的智能聊天机器人;
引入机器人的数量由以下规则决定:
其中,P为直播间人气值,人气值的获取方式:每个直播间在后台维护一个数据库,实时将当前直播间中的真实观众的数量进行累加,得到当前直播间的人气值。
按上述方案,所述步骤6)中判断是否有主播语音回复,使用的方法是基于熵的语音信号端点检测方法,判断当前有语音谱中的熵值大于一定的阈值T2,即可判断当前主播有语音回复,其中T2表示语音谱熵值的阈值。
按上述方案,所述语音谱熵值的阈值T2为50。
本发明还提供一种增加新主播留存的系统,包括:
模拟机器人数量确定模块,通过实时监测主播所在直播间的弹幕量,动态增减直播间中智能聊天机器人数量;
智能断句模块,通过主播的麦克采集主播的语音数据流,对语音数据流进行智能断句,根据断句结果将语音数据流分割成语音小段;
语音识别模块,用于调用语音识别API对分割的语音小段进行识别,将智能断句后的语音小段转换为文本信息M;
回复文本生成模块,用于将文本信息M作为输入发送至智能聊天机器人接口,智能聊天机器人给出的回复文本R;
弹幕模块,用于根据回复文本生成模块得到的文本信息R,生成弹幕,推送给主播,与主播进行互动;
主播回复判断模块,用于判断主播是否有语音回复,如果有,则继续进行主播与系统之间的弹幕互动;如果判断主播没有语音回复,则发布初始设置的弹幕,提高主播回复弹幕的热情。
按上述方案,所述模拟机器人数量确定模块中对直播间机器人数量的动态增减采用以下方法:当主播直播间人气值低于人气阈值T1时,增加设定数量的智能聊天机器人,当直播间人气值达到或超过人气阈值T1时,减少设定数量的智能聊天机器人;
引入机器人的数量由以下规则决定:
其中,P为直播间人气值,人气值的获取方式如下:每个直播间在后台维护一个数据库,实时将当前直播间中的真实观众的数量进行累加,得到当前直播间的人气值。
按上述方案,所述智能断句模块中对语音数据流进行智能断句方法如下:采用基于熵的语音信号端点检测方法,构造一个语音信息熵函数,用以从一段语音流中提取主播的语音信息,剔除噪声信息;把语音帧的标准化幅度谱|X(i)|看作一个概率分布,谱域的熵计算可以取第i个幅度谱的概率来代替取第i个信源符号的概率P(Si),即用以下公式表示:
那么,语音谱的熵可以表示如下:
计算出熵值后根据熵值大小对语音数据流进行智能断句:相对于背景噪声而言,语音信号中的语音段幅度变化的绝对值大于设定阈值,熵值大;而静音段的幅度变化的绝对值小于设定阈值,分布相对集中,熵值小。
本发明产生的有益效果是:本发明要想解决的问题是主播在直播初期会遇到人气不够的问题,在开始直播的时候,人气不够,没有持续的观众互动,主播的直播积极性会有很大的损伤,所以本发明提出使用结合语音识别、智能聊天机器人、弹幕互动的方式,增加主播在人气不足的时候,增加互动乐趣,提升新主播的留存率,使其积极进行直播。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,一种增加新主播留存的方法,包括:
1)实时监测主播所在直播间的弹幕量,动态增减直播间中模拟聊天机器人数量;
当主播直播间人气较少时,增加一定数量的模拟机器人。当直播间人气达到一定值T1(人气阈值)时,减少一定数量的模拟机器人。直播间人气值P,由后台数据库维护,当人气值P<T1,T1=100时,表示直播间人气不足,需要引入一定数量的模拟机器人;当人气值P≥T1,T1=100时,表示直播间人气值上升了,需要减少一定数量的模拟机器人;
引入模拟机器人的数量由以下规则决定:
人气值的获取方式:每个直播间在后台维护一个数据库,其中包含当前在直播间观众的ID信息、观众是否是机器人等数据,后台实时将当前直播间中的真实观众的数量进行累加,得到当前直播间的人气值。
2)通过主播的麦克采集主播的语音数据流,并存入语音流缓存中,然后对语音数据流进行智能断句,通过断句将语音数据流分割成语音小段;
采用语音信号的端点检测是进行语音信号处理(如语音识别、讲话人识别等)重要且关键的第一步。作为本例的实施方案,智能断句采用基于熵的语音信号端点检测方法。根据信息熵的定义,把它应用到语音中,构造一个语音信息熵函数,用以从一段语音流中提取主播的语音信息,剔除噪声信息。当把语音帧的标准化幅度谱|X(i)|看作一个概率分布时,谱域的熵计算可以取第i个幅度谱的概率来代替取第i个信源符号的概率P(Si),即用以下公式表示:
那么,语音谱的熵可以表示如下:
相对于背景噪声而言,语音信号中的语音段幅度的动态范围比较大,因此直观地说,可以认为语音段在信号中的随机事件多,故平均信息量大,也就是熵值大。而静音段的幅度变化小,分布相对集中,因而熵值小。
由此,可以将缓存中的语音流分割成语音小段,其中每段都包含主播的若干语音回复。
与传统的断句方式相比,语音信息熵能够较好的区分语音小段与噪声语音信息,具有较好的区分性。
3)调用语音识别API对上一步中的语音小段进行识别,将智能断句后的语音小段转换为文本信息M。
调用语音识别API对上一步中的语音小段进行识别,将智能断句语音信息转换为文字信息。作为本例的实施方案,可以采用目前百度语音识别SDK或者讯飞语音识别SDK,通过接入语音识别API,对主播的语音进行识别,将语音转换为文本信息M。
4)将文本信息M作为输入发送至智能聊天机器人接口,智能聊天机器人给出的回复文本R;作为本例的实施方案,可以直接调用第三方厂商的聊天机器人,如SimSimiAPI,图灵机器人API。
5)根据步骤4)得到的文本信息R,生成弹幕,推送给主播,与主播进行互动。生成弹幕的方法:首先为模拟机器人创建一个账户,并随机从预先设定好的ID与昵称库中,选择一个作为该机器人的昵称,其次模拟正常观众登录进入主播的直播间,最后调用直播应用自带的弹幕发送接口,将步骤④得到的文本信息R通过接口发送到聊天室中,此过程完全模拟正常用户发送弹幕的过程,唯一区别是以模拟机器人发送弹幕。
模拟机器人登入直播间的效果,具体有以下效果:为模拟机器人增加随机的等级与网站头衔,当模拟机器人进入直播间时,增加对模拟机器人的进直播间欢迎语句,增加对特殊头衔的欢迎特效等。
6)判断主播是否有语音回复,如果有,则重复步骤1)至5),直接进行主播与模拟机器人之间的弹幕互动;如果判断主播没有语音回复,则发布初始设置的弹幕,提高主播回复弹幕的热情。初始设置的弹幕信息有类似:“你是哪里人?”,“你今年几岁?”等初次见面的招呼用语。
判断是否有主播语音回复,使用的方法是前文所述的基于熵的语音信号端点检测方法,判断当前有语音谱中的熵值大于一定的阈值T2,T2=50(根据平台经验值),即可判断当前主播有语音回复。T2表示语音谱熵值的阈值。
本发明也可通过直播间真实观众的人数来确定是否增减直播间中智能聊天机器人数量,具体如下:判断当前直播间是否有真实观众进入直播间,如果有真实观众进入直播间且人数达到阈值,则逐步减少智能聊天机器人的数量,减少机器人的数量的方法即是将将机器人推出本房间即可。判断当前直播间是否有真实观众进入直播间的方式是,后台数据库对每个用户有个标记,标记当前用户是否为真实注册的观众,如果是后续增加人气得到的机器人用户,则不会生成该标记,后续只需要判断该标记,即可判断是否是真实用户进入直播间。
本发明还提供一种增加新主播留存的系统,包括:
模拟机器人数量确定模块,通过实时监测主播所在直播间的弹幕量,动态增减直播间中模拟机器人数量;
智能断句模块,通过主播的麦克采集主播的语音数据流,对语音数据流进行智能断句,根据断句结果将语音数据流分割成语音小段;
语音识别模块,用于调用语音识别API对分割的语音小段进行识别,将智能断句后的语音小段转换为文本信息M;
回复文本生成模块,用于将文本信息M作为输入发送至智能聊天机器人接口,智能聊天机器人给出的回复文本R;
弹幕模块,用于根据回复文本生成模块得到的文本信息R,生成弹幕,推送给主播,与主播进行互动;
主播回复判断模块,用于判断主播是否有语音回复,如果有,则继续进行主播与系统之间的弹幕互动;如果判断主播没有语音回复,则发布初始设置的弹幕,提高主播回复弹幕的热情。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!