一种基于流数约减的自适应公平抽样方法与流程
本发明属于网络流量测量领域,具体的涉及一种基于流数约减的自适应公平抽样保证方法。
背景技术:
网络流量测量将流的各项指标量化,直观地描述当前网络流量的组成成分,反映网络当前的运行状态,在流量计费,流量识别,故障检测和网络安全等应用中起着极其重要的作用。由于网络上数据的增长速度远远超过存储器性能的增长速度,因此对每个流进行实时统计成为高速骨干网实时流量测量的巨大难题,通过抽样对数据进行压缩是实时测量高速网络的重要手段。然而现有的抽样算法以牺牲大流的准确性为代价来提高小流的准确性,从而导致算法的公平性不强。虽然通过对每个流进行统计可以提高算法的公平性,但是从存储开销的角度来看,并不能实现可扩展的流量测量。
由于小流统计准确性低往往严重影响到网络安全和异常检测的正常进行,网络流量测量希望进一步提高小流的准确性以满足公平性要求,并且解决算法的可扩展性问题。目前网络流量测量虽然实现了一定程度的公平抽样,但是缺乏对算法扩展性和公平性的综合考虑。如何实现算法的公平性和扩展性,是网络流量测量面临的重要挑战。
技术实现要素:
本发明针对现有的抽样算法以牺牲大流的准确性为代价来提高小流的准确性,从而导致算法的公平性不强,不能很好的解决算法的可扩展性等问题,提出一种基于流数约减的自适应公平抽样保证方法。
本发明的技术方案是:一种基于流数约减的自适应公平抽样方法,包括以下步骤:
步骤1:根据到达分组是否属于已有流表项,得到不同的网络流公平性抽样策略;
步骤2:利用流数约减对该分组所属流进行大小流区分计数,得到选择性抽取比例,并建立存储器缓存中的新流表项;
步骤3:根据后续流到达测量点的速度进行自适应抽取,得到流个数整体压缩的所有样本流集合;
步骤4:根据所有样本流集合的流量大小分布特征,提出一个新的抽样概率函数簇;
步骤5:根据概率函数簇对样本流集合进行公平抽样,得到样本中大小流的公平性抽样结果。
所述的基于流数约减的自适应公平抽样方法,所述步骤1中网络流公平性抽样策略包括:
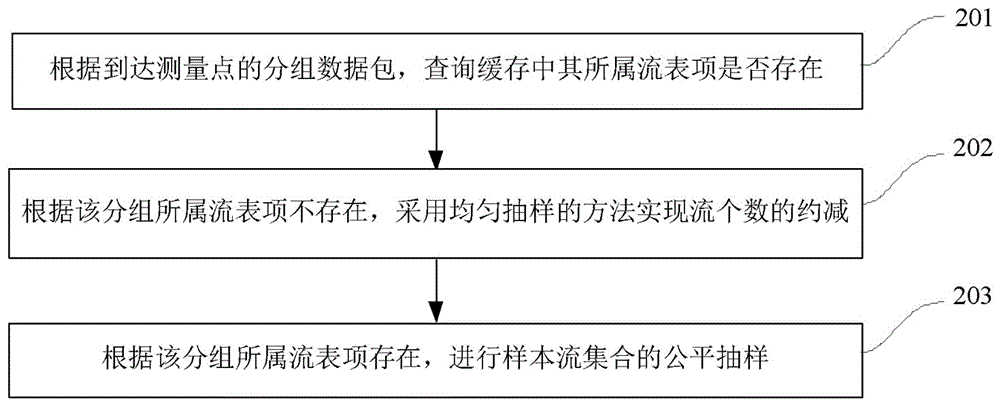
步骤201:根据到达测量点的分组数据包,查询缓存中所属流表项是否存在;
步骤202:根据该分组所属流缓存存在与否,判断是否采用流数约减策略,得到所有样本流集合;
步骤203:根据得到的所有样本流集合,进行样本集合的网络流公平抽样。所述的基于流数约减的自适应公平抽样方法,所述步骤2的具体包括:
步骤301:根据流数约减策略对分组所属流采用计数型布鲁姆过滤器进行大小流区分计数;
步骤302:根据不同大小流的计数值,以概率Pf进行选择性抽取分组;
步骤303:根据选中的流分组数目,建立存储器新的缓存流表项。
所述的基于流数约减的自适应公平抽样方法,所述步骤3具体包括:
步骤401:根据新流表项到达测量点的速度,得到被抽取建立表项的新到达分组的数目;
步骤402:根据已建立流表项的分组数目,自适应改变流个数的压缩集合;
步骤403:根据得到的流数整体约减的分组集合,得到需要统计的所有样本流集合。
所述的基于流数约减的自适应公平抽样方法,所述步骤4获得抽样概率函数簇具体包括:
步骤501:根据样本流中流大小的重尾分布特征,结合两个类幂指数抽样概率函数,寻求一个流大小是减函数的抽样概率函数;
步骤502:根据流大小估计值的相对误差不超过参数值ε,使得小流的抽样概率准确性提高;
步骤503:根据不同的抽样函数特性,提出一个新的抽样概率函数簇。
所述的基于流数约减的自适应公平抽样方法,所述步骤5样本中大小流的公平性抽样结果操作包括:
步骤601:根据当前分组所属流的大小决定抽样概率P;
步骤602:根据抽样概率函数簇决定包所对应计数器为i的流的抽样概率Pi;
步骤603:根据不同流大小的抽样概率,得到所有流相对误差基本一致的公平性抽样结果。
本发明的有益效果是:本发明与现有技术相比,具有以下优点:具有可扩展性和公平性,本发明提供的公平抽样方法通过流数约减方法对流进行等比例抽取,实现了测量的可扩展性;同时利用新的概率抽样函数簇对样本流集合进行公平抽样,提高了算法的公平性;算法不需要提取每个流的统计特征,能够有效地降低算法的机算复杂度,提高小流的统计准确性。
附图说明
图1为本发明的整体步骤流程示意图;
图2为流数约减和公平抽样策略步骤流程示意图;
图3为新的缓存流表项构建步骤流程示意图;
图4为抽样概率函数簇步骤流程示意图;
图5为新的抽样概率函数簇步骤流程示意图;
图6为公平抽样结果步骤流程示意图;
具体实施方式
结合图1-图6,为了方便本领域的技术人员理解本发明,下面对本文出现的技术名词或术语进行解释;
网络流量测量:获得网络行为实时参数和指标最有效的手段,分为主动测量和被动测量。
流数约减:采用均匀抽样的方法对流进行等比例抽取,实现对流个数的整体压缩。
抽样:一种非常有效的数据压缩技术,具备良好的可适性和抽样精度,广泛应用于高速骨干网链路数据流的流量测量。
一种基于流数约减的自适应公平抽样方法,包括以下步骤:
步骤1:根据到达分组是否属于流表项,得到不同的网络流公平性抽样策略;具体得到网络流公平性抽样策略,该开发过程包括:
步骤201:根据到达测量点的分组数据包,查询缓存中所属流表项是否存在;
步骤202:若该分组所属流缓存不存在,则判断采用流数约减策略,该策略利用均匀抽样的方法对流进行等比例抽取,从而将原始流数目按照等比例压缩以适应高速缓存内存小的限制,得到约减的样本流集合;
步骤203:根据约减的样本流集合以及分组所属缓存存在的样本流集合,得到需要统计的所有样本流集合,进行不同样本集合的网络流公平抽样。
步骤2:根据流数约减策略对该分组所属流进行大小流区分计数,得到选择性抽取比例,并建立存储器中的新缓存流表项;建立新缓存流表项,该开发过程包括:
步骤301:根据流数约减策略对分组所属流采用计数型布鲁姆过滤器进行大小流区分计数,实现对小流流量的逐包精确统计;
步骤302:根据大小流服从重尾分布以及不同大小流的计数值,定义抽取比例Pf,Pf是按照大小流数目占比进行抽取的比例函数,使得能够在不改变数据流在整体中所占比例的情况下进行选择性抽取分组;
步骤303:根据选中的流分组数目,建立存储器新的缓存流表项。
步骤3:根据后续流的到达的测量点的速度进行自适应抽取,得到流个数整体压缩的样本流集合;得到所有样本流集合,该开发过程包括:
步骤401:根据后续流到达测量点的速度,自适应改变流抽样比Pf的数值,利用计数器得到被抽取建立表项的新到达分组的数目;
步骤402:根据后续到达需要建立流表项的分组数目,将这些分组添加到缓存流表项,得到压缩流个数的约减集合;
步骤403:根据流数整体压缩的约减集合和已在存储器缓存中的分组集合,从原始流中选取得到需要统计的所有样本流集合。
步骤4:根据样本流集合的流量大小分布特征,提出一个新的抽样概率函数簇;提出抽样概率函数簇,该开发过程包括:
步骤501、根据样本流中流大小的重尾分布特征,结合两个类幂指数抽样概率函数,寻求一个流大小是减函数的抽样概率函数;
步骤502、根据流大小估计值的相对误差不超过参数值ε,其中ε为常数,代表任意流大小估计值的最大误差值,从而使得小流的抽样概率准确性提高;
步骤503、根据流大小的分布特性和不同的抽样概率函数特性,结合SGS算法和ANLS算法类似幂指数函数的推导过程,提出一个新的为流大小减函数的抽样概率函数簇,其中a为取值范围为(O,1)的常数。
步骤5:根据概率函数簇对样本流集合进行公平抽样,得到样本中大小流的公平性抽样结果:得到公平抽样结果,该开发过程包括:
步骤601、根据当前分组所属流的大小,为使得统计结果符合流大小重尾分布,流的大小越大,抽样率Pi越小,其中Pi由抽样概率函数g决定,即Pi=g(i);
步骤602、根据抽样概率函数簇决定包所对应计数器为i的流的抽样概率Pi;
步骤603、根据不同流大小的抽样概率,得到所有流相对误差基本一致的公平性抽样结果。
- 还没有人留言评论。精彩留言会获得点赞!