HA系统状态的处理方法及装置与流程
本公开涉及ha状态监控技术,尤其涉及ha状态的处理方法及装置。
背景技术:
相关技术中,mw-ha(ha配置的安全监管平台)指为安全监管平台提供的高可用功能,它在两台安全监管平台上,构建集群,提供虚拟ip,作为外部用户或设备接入的接口,在内部ha软件监控节点的状态和相关资源的状态,实现资源的故障迁移(failover)。两台安全监管平台在ha状态下,都对外提供服务。主备之分只是名义上的概念,没有实质区别。一般ha都基于心跳数据,检测节点的状态(启动、宕机等)以及各个ha管理的各种资源或者服务的状态。因此,心跳数据的传输在ha应用中至关重要。
一般来说,ha所依赖的相关系统服务、基础软件以及应用软件比较多,任何一个服务或者应用出问题,都有可能影响整个ha系统的稳定性以及可用性。普通监控软件需要搭建独立的监控服务器,来集中管理监控数据,但是由于ha系统需要监控的资源比较多,监控的参数比较复杂,因此相关技术中的监控软件不适合于监控资源受限的工控环境。
技术实现要素:
为克服相关技术中存在的问题,本公开提供一种ha系统状态的处理方法及装置。
根据本公开实施例的第一方面,提供一种ha系统状态的处理方法,所述方法包括:
通过主监控进程监控至少一个子监控进程的状态,其中,所述子监控进程用于检查监控的所述ha系统的资源状态;以及
当监控到所述ha系统的资源状态存在异常情况时,调用与所述异常情况相对应的恢复进程进行恢复。
进一步地,所述当监控到所述ha系统的资源状态存在异常情况时包括:
通过所述至少一个子监控进程对所述ha系统的资源状态进行检测;
当所述至少一个子监控进程检测到所述ha系统的资源状态存在异常情况时,创建系统事件;以及
将所创建的系统事件发布到事件总线。
进一步地,所述调用与所述异常情况相对应的恢复进程进行恢复包括:
从所述事件总线中订阅系统事件;以及
接收订阅的系统事件,并根据所述系统事件中的资源状态的异常情况,调用与所述异常情况相对应的恢复进程,以将ha系统的资源状态恢复至正常状态。
进一步地,所述方法还包括:
在所述通过所述主监控进程监控至少一个子监控进程的状态之前,将所述主监控进程注册为至少一个子监控进程的观察者,以对所述至少一个子监控进程的状态进行监控。
进一步地,所述方法还包括:
通过所述至少一个子监控进程对所述ha系统的资源状态进行检测;以及
当检测到所述ha系统的资源状态变化时,修改ha状态数据中与所述资源状态对应的数据并向所述主监控进程更新所述资源状态。
进一步地,所述ha系统的状态包括以下至少之一者:
分布式复制块设备drbd状态、所述ha系统管理的资源状态、网络状态。
进一步地,所述方法还包括:
根据ha状态数据、ha系统的资源状态参数和资源状态异常情况发生节点,确定ha系统的健康指数。
进一步地,所述方法还包括:
根据所述ha系统的健康指数的数值范围,显示对应的健康标志。
进一步地,所述方法还包括:
响应于初始化请求,以初始化所述主监控进程。
根据本公开实施例的第二方面,提供一种ha系统状态的处理装置,包括:
监控单元,用于通过主监控进程监控至少一个子监控进程的状态,其中,所述子监控进程用于检查监控的所述ha系统的资源状态;以及
恢复单元,用于当监控到所述ha系统的资源状态存在异常情况时,调用与所述异常情况相对应的恢复进程进行恢复。
本公开的实施例提供的技术方案可以包括以下有益效果:创建了ha系统的轻量级监控机制,在不需要搭建独立的监控服务器的情况下,便于工控设备等资源受限的情况下对ha进行监控,还实现了同时对ha系统涉及的各种系统服务、网络、基础软件和应用软件的监控,捕获各种异常情况,并及时对异常进行恢复,以提高ha系统的整体稳定性和服务的可用性。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是根据一示例性实施例示出的一种ha系统的总体逻辑架构图;
图2是根据一示例性实施例示出的一种ha系统状态的处理方法的流程图;
图3是根据一示例性实施例示出的一种ha系统状态的处理方法中ha状态数据示意图;
图4是根据一示例性实施例示出的一种ha系统状态的处理装置结构框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
本公开提供一种ha系统状态的处理方法,通过监控ha系统涉及的各种系统服务、网络、基础软件和应用软件,从而发现各种异常情况,并及时对异常进行恢复。
为了使本领域技术人员能够清楚、准确地理解本公开的技术方案,在对本公开实施例进行详细描述之前,下面首先结合附图对ha系统中的结构框架进行详细介绍。
如图1所示,提供了根据一示例性实施例示出的ha系统的总体逻辑架构图。ha系统可以包括四个组成部分,分别为数据备份层、节点管理层、服务管理层、ha状态监测与自动恢复模块。
1)数据备份层:负责将数据从主节点同步备份到备用节点,同时维护备用节点的数据备份的状态,例如数据是否处于更新,还是未同步,或者脑裂。以及在主节点发生故障时,将主节点自动切换到原来的备用节点,然后继续提供数据共享服务。
2)节点管理层:其依靠心跳数据通讯,心跳数据要保证高度的可靠性,以确保每个节点状态的正确性,在主节点故障时,可以将服务正确地迁移到正常的节点(例如备用节点)上。在正确心跳数据的基础上,ha软件会记录节点的状态,正常或者掉线,并不断及时更新节点状态。
3)服务管理层:用于管理各个ha资源(例如,ha软件管理的系统服务),选择正确的节点部署资源,在节点故障时,将ha资源迁移到正常节点。在本公开中,ha资源可以包括:虚拟ip,mysql服务,其他系统服务,kafka等。
此外,服务管理层还可以具备检测外部网络的功能,例如,当单个节点的外部网络异常,而另外一个节点外部网络正常时,可以将ha资源迁移到外部网络正常的节点上。
4)ha状态监测与自动恢复模块:可以定期检测或者实时监测各个系统服务的状态,在系统服务出现异常时,可以控制异常的系统服务恢复正常工作状态。ha系统往往会运行多个系统服务,且ha系统的稳定性依赖于这些系统服务,因此在ha系统中配置ha状态监测与自动恢复模块,可以确保系统服务的正常运行。
基于上述ha系统的结构框架,本公开提供一种用于对上述ha系统的结构框架中涉及的各种系统服务、网络、基础软件和应用软件的状态进行处理的方法,通过本公开提供的处理方法,在不需要搭建独立的监控服务器的情况下,实现对ha系统涉及的各种系统服务、网络、基础软件和应用软件的监控,以便及时对异常进行恢复,以提高ha系统的整体稳定性和服务的可用性。下面将结合附图对本公开的技术方案进行详细描述。
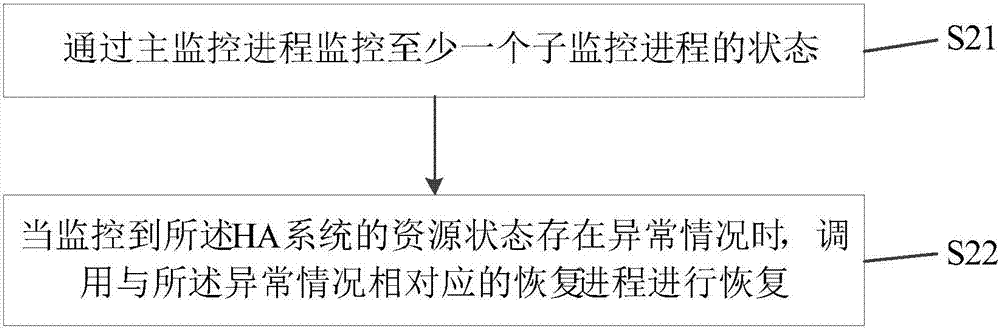
图2是根据一示例性实施例示出的一种ha系统状态的处理方法的流程图,如图2所示,所述ha系统状态的处理方法包括以下步骤:
在步骤s21中,通过主监控进程监控至少一个子监控进程的状态,其中,所述子监控进程用于检查监控的所述ha系统的资源状态。
在通过主监控进程监控至少一个子监控进程的状态之前,接收第三方装置通过特定接口(例如,restapi)发送的初始化请求,所述ha系统响应于所述初始化请求,进行自动配置,以初始化所述主监控进程。
以基于linux的ha系统状态处理为例,结合linux本身的系统特性,可以预先定义的函数例如hamonitor作为ha状态监控的主监控进程以及预先定义用于对ha的资源状态进行监控的函数(如所示子监控进程)。所述主监控进程hamonitor可以先调用自身init方法进行初始化,然后启动各个服务的监控器,例如至少一个子监控进程,以对所述ha系统的资源状态进行监控。
需要说明的是,主监控进程hamonitor可以理解为是ha状态监控的逻辑主入口,为ha监控部分的总调度程序。采用observer设计模式,可以从其他monitor子类(即子监控进程)中获取ha状态更新数据。其中,主监控进程hamonitor中还可以定义有其他的子类,例如:status,用于表示当前的ha状态参数;overallhealth,用于计算和表示当前的总体健康指数;getnodestatus,用于获取子监控进程监测到的ha系统各个资源的当前状态参数;updatestatus,用于根据getnodestatus获取到的参数更新当前的状态参数,以及控制其他线程(例如,子监控进程)根据对应的ha系统的资源的状态进行状态更新,且进行状态更新之前需预先取得解锁,否则以免造成数据阻塞;calculateoverallhealth,用于计算整体健康指数。
另外,在一些实施例中,在所述通过所述主监控进程监控至少一个子监控进程的状态之前,将所述主监控进程注册为至少一个子监控进程的观察者。其中,以drbdmonitor、haresourcesmonitor和networkmonitor三个子监控进程为例,分别用于监控drbd状态、ha管理的资源状态和网络状态,将hamonitor作为drbdmonitor、haresourcesmonitor和networkmonitor的观察者,以便对上述三个子监控进程的状态进行监控。
在一些实施例中,通过所述至少一个子监控进程对所述ha系统的资源状态进行检测;以及当检测到所述ha系统的资源状态变化时,修改ha状态数据中与所述资源状态对应的数据并向所述主监控进程更新所述资源状态。
其中,其中如图3所示,ha状态数据为一个宽度为32位的由0/1代码组成的整数。总体按照每8位为一组,分别表示不同类型的资源状态,分别有ha资源组、drbd组、网络组和预留组四类。每一位分别代表一个资源状态,正常为0,异常为1。整个ha状态最终表示为一个整数,对状态进行查询或者设置时,需要对相关的0/1代码位进行操作。
以drbd组、所述ha资源组以及网络组中的资源状态为例,当检测到ha资源组中的资源状态变化时,修改ha状态数据中与所述资源状态对应的数据,即将所述ha资源组中对应的资源状态由0修改为1,同时通知观察者hamonitor,并向所述主监控进程hamonitor更新所述资源状态;类似的,当检测到drbd状态变化时,ha状态数据中与所述资源状态对应的数据,即将所述drbd组中对应的资源状态由0修改为1,同时通知观察者hamonitor,并向所述主监控进程hamonitor更新所述资源状态;类似的,当检测到网络状态变化时,ha状态数据中与所述资源状态对应的数据,即将所述网络组中对应的资源状态由0修改为1,同时通知观察者hamonitor,并向所述主监控进程hamonitor更新所述资源状态。
在步骤s22中,当监控到所述ha系统的资源状态存在异常情况时,调用与所述异常情况相对应的恢复进程进行恢复。
在一些实施例中,通过所述至少一个子监控进程对所述ha系统的资源状态进行检测;当所述至少一个子监控进程检测到所述ha系统的资源状态存在异常情况时,创建系统事件;将所创建的系统事件发布到事件总线。
其中,所述系统事件是对存在异常情况的状态的描述,以函数systemevent表示系统事件为例,其中包括诸如系统事件的时间戳、事件类型等插件,如eventid插件用于表示系统事件的uuid(universallyuniqueidentifier,通用唯一标识符);hostname插件用于表示发生系统事件的主机名;hostipaddr插件用于表示发生系统事件的ip地址;message插件用于表示系统事件的提示内容;priority插件用于表示系统事件的优先级;eventtype插件用于表示系统事件类型;timestamp插件用于表示系统事件的时间戳等等。
其中,对于ha系统而言,在事件总线中发送和接收的对象都是系统事件。事件总线用于在多个子系统、代码之间提供弱耦合的应用集成。事件总线的物理基础是消息机制(messagebroker),基于message来封装系统事件,构建整个事件驱动的架构。
在另一些实施例中,从所述事件总线中订阅系统事件;接收订阅的系统事件,并根据所述系统事件中的资源状态的异常情况,调用与所述异常情况相对应的恢复进程进行恢复。
其中,多个程序可以订阅系统事件,当订阅的系统事件出现后,即会被发送到所订阅的程序,当程序接收到订阅的系统事件后,根据所述系统事件中的资源状态的异常情况,调用与所述异常情况相对应的恢复进程进行恢复。例如,ha资源管理器hamanager和drbd管理器drbdmanager在订阅相关的系统事件后,当所订阅的系统事件发送到hamanager或drbdmanager时,hamanager或drbdmanager会根据所述系统事件中的资源状态的异常情况,调用与所述异常情况相对应的恢复进程进行恢复。
例如,函数hamanager的onsystemevent插件用于处理ha系统中资源异常相关的系统事件;函数drbdmanager的onsystemevent插件用于处理drbd相关的系统事件。
另外,同一个系统事件也可能会由多个程序进行恢复处理,主要是看订阅系统事件的程序有哪些,一旦系统事件发生,所述系统事件将会发送到订阅的程序进行恢复处理。
在另一些实施例中,根据ha状态数据、ha系统的资源状态参数和资源状态异常情况发生节点,确定ha系统的健康指数。
在确定ha系统的健康指数之前,首先按照资源的重要程度对资源进行分级,分为:一般资源,资源发生异常时不会影响其他资源,也可以简单恢复;重要资源,资源异常时会影响其他资源,恢复时可能需要恢复多个服务;关键资源,资源异常时,会影响用户使用,恢复时可能导致数据丢失等。
根据上述分级得到所述ha系统的每个资源状态参数,例如,每一种资源都有一个基础分数,正常的+5分,异常的-5分。资源按照重要度不同,会给分数乘以权重,例如一般资源的权重为1,重要资源的权重为3,关键资源的权重为5。同时还会区分资源异常是发生在主节点上,还是备用节点上。若异常发生在备用节点上,分数乘以权重1,若异常发生在主节点上,分数乘以权重3。
根据所述ha状态数据中的32位由0/1组成的代码,由于每一位分别代表一个资源状态,正常为0,异常为1,可以得到每种资源的状态,再结合ha系统的每个资源状态参数和对应资源状态异常情况发生节点,确定ha系统的健康指数。
在另一个实施例中,根据所述ha系统的健康指数的数值范围,显示对应的健康标志。
例如,计算得到整个ha系统的健康指数后,还可以根据数值的范围,通过不同颜色作为健康标志为用户展示,例如使用红色、黄色或绿色健康标志。
例如,主监控进程hamonitor会定期调用函数calculateoverallhealth通过上述规则来计算ha系统的健康指数。外部调用者还可以通过函数overallhealth来获取当前的总体健康指数。
本公开实施例中的ha系统在异常发生后,基于事件总线将对应的系统事件发送给相关的订阅者去处理。异常处理程序在收到系统事件后,会根据异常情况的具体情况,调用自身的不同方法进行异常恢复。监控和异常恢复的密切配合,确保了ha系统异常会在第一时间自动恢复,确保了ha系统的稳定性和服务的可用性。另外,基于事件总线将监控与异常恢复集成在一起,提高了模块的内聚,弱化了模块之间的耦合度,同时也便于多个系统事件的处理程序对于同一个系统事件进行不同的处理。
通过ha系统的轻量级监控机制,便于工控设备等资源受限的情况下对ha状态进行监控,能捕获各种异常情况,并及时对异常进行恢复,以提高ha系统的整体稳定性和服务的可用性。另外由于对ha系统进行定期监控,基于各种服务和资源的不同权重计算整体的ha健康状况,为用户提供直观清晰的ha健康状况。
图4是根据一示例性实施例示出的一种ha系统状态的处理装置结构框图。参照图4,一种ha系统状态的处理装置40包括监控单元41和恢复单元42。
监控单元41,用于通过主监控进程监控至少一个子监控进程的状态,其中,所述子监控进程用于检查监控的所述ha系统的资源状态;以及
恢复单元42,用于当监控到所述ha系统的资源状态存在异常情况时,调用与所述异常情况相对应的恢复进程进行恢复。
通过ha系统的轻量级监控机制,便于工控设备等资源受限的情况下对ha状态进行监控,捕获各种异常情况,并及时对异常进行恢复,以提高ha系统的整体稳定性和服务的可用性。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!