一种儿童照相的方法及装置与流程
本发明属于计算机技术领域,尤其涉及一种儿童照相的方法及装置。
背景技术:
随着科技的发展和生活水平的提高,越来越多具备照相功能的设备进入人们的生活,使得照相成为常见的一种娱乐和记录方式。家长们在孩子的成长过程中,通常也会采取照相的方式来记录孩子慢慢长大的时光。
然而,当家长在给年龄较小的孩子拍照时,由于孩子活泼好动常常很难拍摄到满意的照片,有时候时拍摄不到正脸,有时候好不容易拍摄到正脸却又是模糊的。
技术实现要素:
本发明的目的在于提供一种儿童照相的方法及装置,旨在解决由于现有技术无法提供一种有效的儿童照相方法,导致在给儿童拍摄照片时拍摄到儿童脸部的难度较大、照片拍摄质量不佳以及拍摄耗时长的问题。
一方面,本发明提供了一种儿童照相的方法,所述方法包括下述步骤:
当接收到用户输入的照片拍摄指令时,启动预设的摄像头;
对所述摄像头获取的图像进行人脸检测,确定所述获取的图像中是否存在儿童;
当检测到所述获取的图像中存在儿童时,从预先构建的语音库按预设的语音选择方式选择对应的语音进行播放;
在播放所述对应的语音的预设时间段内通过所述摄像头拍摄包含所述儿童的照片。
另一方面,本发明提供了一种儿童照相的装置,所述装置包括:
摄像头启动模块,用于当接收到用户输入的照片拍摄指令时,启动预设的摄像头;
儿童检测模块,用于对所述摄像头获取的图像进行人脸检测,确定所述获取的图像中是否存在儿童;
语音播放模块,用于当检测到所述获取的图像中存在儿童时,从预先构建的语音库中按预设的语音选择方式选择对应的语音进行播放;以及
照片拍摄模块,用于在播放对应的语音的预设时间段内通过所述摄像头拍摄包含所述儿童的照片。
本发明在接收到照片拍摄指令时启动摄像头,检测摄像头获取的图像中是否存在儿童,当确定存在儿童时,按预设的语音选择方式从预先构建的语音库选择对应的语音进行播放,以吸引儿童,在语音播放的预设时间段内拍摄包含儿童的照片,从而有效地提高了儿童照相的智能化程度,有效地提高了给儿童拍摄照片的效率和质量,降低了拍摄到儿童精彩照片的难度。
附图说明
图1是本发明实施例一提供的儿童照相的方法的实现流程图;
图2是本发明实施例二提供的儿童照相的方法的实现流程图;
图3是本发明实施例三提供的儿童照相的装置的结构示意图;
图4是本发明实施例三提供的儿童照相的装置的优选结构示意图;以及
图5是本发明实施例三提供的儿童照相的装置的优选结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的儿童照相的方法的实现流程,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤s101中,当接收到用户输入的照片拍摄指令时,启动预设的摄像头。
本发明实施例适用于手机、平板电脑以及数码相机等具有照相功能的智能设备,在这些设备上用户可通过按键或触屏等方式输入照片拍摄指令。接收到照片拍摄指令时,启动这些设备自身的摄像头。
在步骤s102中,对摄像头获取的图像进行人脸检测,确定获取的图像中是否存在儿童。
在本发明实施例中,启动摄像头后,通过预设的人脸检测算法,检测摄像头获取的图像中是否存在人脸,在检测到图像中的人脸时,可再通过预设的年龄识别算法识别图像中所有人脸的年龄,将这些年龄与预设的年龄阈值一一比较,当存在识别后的年龄不超过预设的年龄阈值时,确定图像中存在儿童。
在步骤s103中,当检测到获取的图像中存在儿童时,从预先构建的语音库中按预设的语音选择方式选择对应的语音进行播放。
在本发明实施例中,当检测到图像中存在儿童时,对图像进行场景识别,可提取图像背景中的图像特征,将这些图像特征与预先存储的场景图像特征进行匹配,并根据匹配结果确定当前的拍摄场景。在语音库中查找该拍摄场景对应的语音,播放该拍摄场景对应的语音,以吸引儿童的注意力。具体地,语音库中可包括儿童歌曲、动物声音、玩具声音等,也可以包括录制的儿童父母等家人的声音。
作为示例地,可预先存储游乐场、动物园、客厅、草地等场景的图像特征,当匹配到摄像头获取的图像特征为动物园的图像特征时,确定当前的拍摄场景为动物园,并在语音库中查找动物园对应的语音,即与动物园相关的声音。
在步骤s104中,在播放对应的语音的预设时间段内通过摄像头拍摄包含儿童的照片。
在本发明实施例中,在播放对应的语音的预设时间段内,可通过预设的眼睛定位算法,检测儿童的眼睛,并通过预设的表情识别算法识别儿童的表情,当定位到儿童的眼睛时或者识别到儿童的表情为预设的拍摄表情时,通过摄像头拍摄下该场景,得到包含儿童的照片。具体地,预设的拍摄表情可为微笑、大笑、哭泣、惊讶等。
在本发明实施例中,通过人脸检测、年龄识别检测摄像头获取的图像中是否存在儿童,在确定存在儿童后,通过对图像进行场景识别确定当前的拍摄场景,根据拍摄场景播放语音库中对应的语音,以吸引儿童的注意力,在语音播放时通过眼睛定位和表情识别,拍摄下包含儿童的照片,从而有效地提高了儿童照相的智能化程度,有效地提高了儿童照相时拍摄照片的效率和质量。
实施例二:
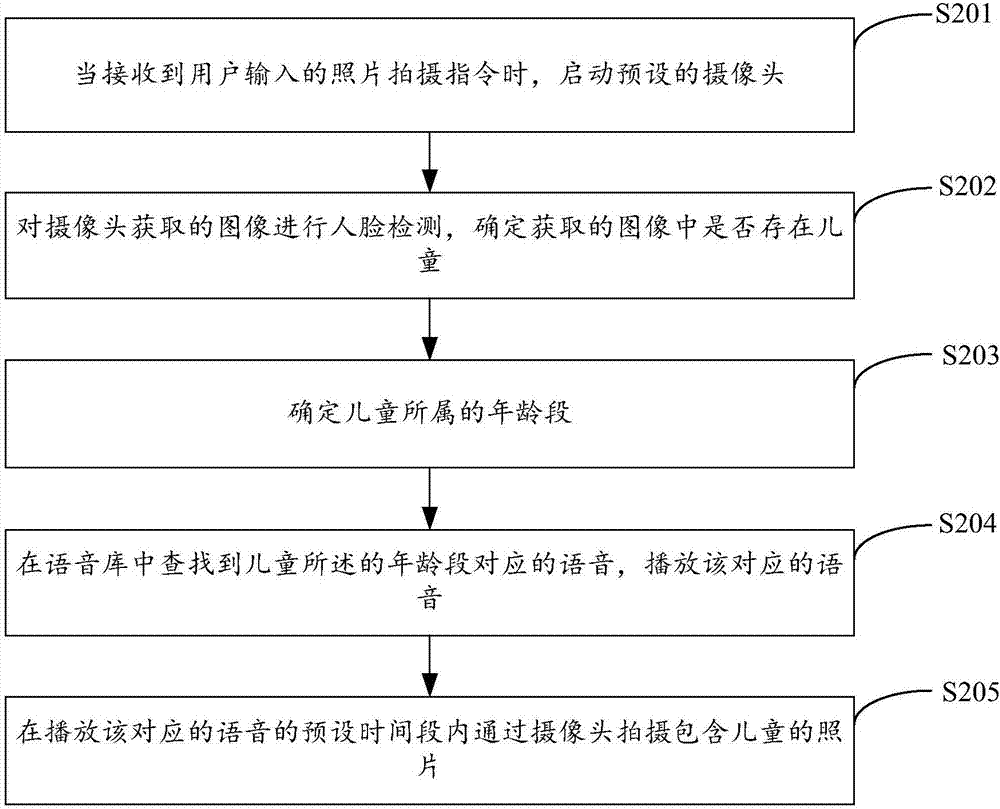
图2示出了本发明实施例二提供的儿童照相的方法的实现流程,详述如下:
在步骤s201中,当接收到用户输入的照片拍摄指令时,启动预设的摄像头。
在步骤s202中,对摄像头获取的图像进行人脸检测,确定获取的图像中是否存在儿童。
在本发明实施例中,启动摄像头后,通过预设的人脸检测算法,检测摄像头获取的图像中是否存在人脸,在检测到图像中的人脸时,可再通过预设的年龄识别算法识别所有人脸的年龄,将这些年龄与预设的年龄阈值一一比较,当存在识别后的年龄不超过预设的年龄阈值时,确定图像中存在儿童。
在步骤s203中,确定儿童所属的年龄段。
在本发明实施例中,可根据年龄识别后得到的该儿童的年龄,确定儿童目前所处的年龄段。作为示例地,对于儿童来说,0~1岁为婴儿期,1~3岁为幼儿期,3~6岁为学龄前期,所以年龄段可分为0~1岁、1~3岁以及3~6岁。
在步骤s204中,在语音库中查找到儿童所属的年龄段对应的语音,播放该对应的语音。
在本发明实施例中,随着大脑的发育和性格的成长,对于不同年龄段的儿童,同一语音的吸引力不同,因此为了达到更好的吸引效果,可根据年龄段对语音库中的语音进行分类,在确定儿童的年龄段后,在语音库中查找该年龄段对应的语音,并播放该语音。
作为示例地,年龄段在0~1岁的儿童可通过拍手声、妈妈说话声等进行吸引,1~3岁的儿童可通过玩具声音、动物声音进行吸引,3-6岁的儿童可通过动画片中的语音进行吸引,类似音乐这类语音可能对不同年龄段的儿童都具有吸引力,可将音乐划分到每个年龄段。
在步骤s205中,在播放该对应的语音的预设时间段内通过摄像头拍摄包含儿童的照片。
在本发明实施例中,在播放该对应的语音的预设时间段内,可通过预设的眼睛定位算法,检测儿童的眼睛,并通过预设的表情识别算法识别儿童的表情,当定位到儿童的眼睛时或者识别到儿童的表情为预设的拍摄表情时,通过摄像头拍摄下该场景,得到包含儿童的照片。
在本发明实施例中,通过人脸检测、年龄识别检测摄像头获取的图像中是否存在儿童,在确定存在儿童后,确定儿童所属的年龄段,并根据年龄段播放语音库中对应的语音,以更好地吸引儿童的注意力,在语音播放时通过眼睛定位和表情识别,拍摄下包含儿童的照片,从而有效地提高了儿童照相的智能化程度,有效地提高了儿童照相时拍摄照片的效率和质量。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如rom/ram、磁盘、光盘等。
实施例三:
图3示出了本发明实施例三提供的儿童照相的装置的结构,为了便于说明,仅示出了与本发明实施例相关的部分,其中包括:
摄像头启动模块31,用于当接收到用户输入的照片拍摄指令时,启动预设的摄像头。
在本发明实施例中,用户可在手机、平板电脑以及数码相机等具有照相功能的智能设备上通过按键或触屏等方式输入照片拍摄指令,接收到照片拍摄指令时,启动这些设备自身的摄像头。
儿童检测模块32,用于对摄像头获取的图像进行人脸检测,确定获取的图像中是否存在儿童。
在本发明实施例中,启动摄像头后,通过预设的人脸检测算法,检测摄像头获取的图像中是否存在人脸,在检测到图像中的人脸时,可再通过预设的年龄识别算法识别图像中所有人脸的年龄,将这些年龄与预设的年龄阈值一一比较,当存在识别后的年龄不超过预设的年龄阈值时,确定图像中存在儿童。
语音播放模块33,用于当检测到获取的图像中存在儿童时,从预先构建的语音库中按预设的语音选择方式选择对应的语音进行播放。
在本发明实施例中,当检测到图像中存在儿童时,对图像进行场景识别,可提取图像背景中的图像特征,将这些图像特征与预先存储的场景图像特征进行匹配,并根据匹配结果确定当前的拍摄场景。在语音库中查找该拍摄场景对应的语音,播放该拍摄场景对应的语音,以吸引儿童的注意力。具体地,语音库中可包括儿童歌曲、动物声音、玩具声音等语音。
照片拍摄模块34,用于在播放对应的语音的预设时间段内通过摄像头拍摄包含儿童的照片。
在本发明实施例中,在播放对应的语音的预设时间段内,可通过预设的眼睛定位算法,检测儿童的眼睛,并通过预设的表情识别算法识别儿童的表情,当定位到儿童的眼睛时或者识别到儿童的表情为预设的拍摄表情时,通过摄像头拍摄下该场景,得到包含儿童的照片。
优选地,如图4所示,儿童检测模块32包括人脸检测模块421、年龄识别模块422以及儿童确定模块423,其中:
人脸检测模块421,用于通过预设的人脸检测算法,检测获取的图像中是否出现人脸;
年龄识别模块422,用于当检测到获取的图像中出现人脸时,对人脸进行年龄识别;以及
儿童确定模块423,用于根据识别的年龄和预设的年龄阈值,确定获取的图像中是否存在儿童。
优选地,语音播放模块33包括场景识别模块431和第一播放模块432,其中:
场景识别模块431,用于对获取的图像进行场景识别,以确定当前的拍摄场景;以及
第一播放模块432,用于在语音库中查找拍摄场景对应的语音,播放拍摄场景对应的语音。
优选地,照片拍摄模块34包括照片拍摄子模块441,其中:
照片拍摄子模块441,用于在时间段内检测儿童的眼睛并识别儿童的表情,当检测到儿童的眼睛或识别到儿童的表情为预设的拍摄表情时,通过摄像头拍摄包含儿童的照片。
优选地,如图5所示,语音播放模块33还包括
年龄段确定模块531,用于确定儿童所属的年龄段。
在本发明实施例中,可根据年龄识别后得到的该儿童的年龄,确定儿童目前所处的年龄段。
第二播放模块532,用于在语音库中查找年龄段对应的语音,播放年龄段对应的语音。
在本发明实施例中,随着大脑的发育和性格的成长,对于不同年龄段的儿童,同一语音的吸引力不同,因此为了达到更好的吸引效果,可根据年龄段对语音库中的语音进行分类,在确定儿童的年龄段后,在语音库中查找该年龄段对应的语音,并播放该语音。
在本发明实施例中,通过人脸检测、年龄识别检测摄像头获取的图像中是否存在儿童,在确定存在儿童后,根据拍摄场景或者儿童所属的年龄段从语音库中选取对应的语音进行播放,以更好地吸引儿童的注意力,在语音播放时通过眼睛定位和表情识别,拍摄儿童的照片,从而有效地提高了儿童照相的智能化程度,有效地提高了儿童照相时拍摄照片的效率和质量。
在本发明实施例中,儿童照相的装置的各模块可由相应的硬件或软件模块实现,各模块可以为独立的软、硬件模块,也可以集成为一个软、硬件模块,在此不用以限制本发明。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!