一种基于多云架构的内容分发服务资源优化调度方法与流程
本发明属于网络多媒体技术和云计算技术领域,具体为一种基于多云架构的内容分发服务资源优化调度方法。
背景技术:
数字内容产业在下一代ip网络的应用中占有十分重要的地位。新一代互联网中,随着宽带的发展,互联网应用已经从单纯的web浏览转向以丰富的内容为中心的综合应用,丰富媒体内容的分发服务将占越来越大的比重,流媒体、iptv、大文件下载、高清视频等应用逐渐成为宽带应用的主流。根据cisco2016年视频网络调查报告,2015年视频流量占到整个internet流量超过70%。这些视频应用所固有的高带宽、高访问量和高服务质量要求对以尽力而为为核心的互联网提出了巨大的挑战,如何实现快速的、自动伸缩、有服务质量保证的内容分发传递成为核心问题。流媒体的服务需求经常超出应用服务提供商自身的it架构能力,这就需要应用服务提供商不断加大系统硬件投入来实现系统的扩展能力。为了节省成本和实现系统的可扩展性,云计算的概念和技术不断发展。云计算(cloudcomputing),是一种基于互联网的开放共享的计算方式,通过这种方式,共享的软硬件资源和内容可以按需求提供给用户。云计算是分布式计算、并行处理和网格计算的进一步发展,能够向各种互联网应用提供硬件服务、基础架构服务、平台服务、软件服务、存储服务。云计算作为一种新型的按需使用、按用付费的商业模式,它以虚拟化技术为基础,并具备了弹性扩展,动态分配和资源共享等特点,不仅改变了当今it基础设施的架构模式,也改变了获取、管理和使用it资源的方式。美国家标准与技术研究院(nationalinstituteofstandardsandtechnology,nist)将云计算系统的部署方式划分为私有云、社区云、公有云和混合云等四种.流媒体服务的提供商首先供给私有云资源进行内容分发服务。由于所有物理设备均由应用服务提供商自身维护,所以它能保证数据及网络传输过程中的性能和安全性。但是,构建私有云的成本较高,且可扩展性不强。一旦建成私有云平台,私有云内的资源总量是固定的,无法随着需求变化自动伸缩提供资源,较低的资源利用率以及无法满足流媒体突发请求将是内容服务提供商面临的一个重大问题。而多云架构(multicloud)是在单一的云计算结构基础上,使用多个云计算服务的架构,并将这些计算云或者存储云逻辑上结合起来。例如,企业可以同时使用不同的云服务供应商基础设施(iaas)和软件(saas)的服务,或者使用多个基础设施(iaas)供应商。在后一种情况下,企业可以为不同的工作负载使用不同的基础设施供应商,在不同的供应商之间负载均衡,或者在一个供应商的云上部署工作负载,并在另一个云上做备份。
经对现有技术的文献检索发现,传统的内容分发网络(cdn)一直依赖于传统的internet数据中心(internetdatacenter,idc)技术的支撑,例如全球最大的cdn提供商akamai在遍布全球的1000多个网络部署了众多服务器,遍及九十多个国家,总数超过15万台。但是传统的idc硬件设施固定,不能动态扩展,而目前的虚拟化技术支撑的云数据中心(clouddatacenter,cdc)的部署不断壮大,包括大型云提供商例如amazon和microsoft提供的大规模云数据中心,也包括众多小型isp提供的微型云数据中心也在蓬勃发展。云数据中心与内容分发技术的结合趋势已经显现,内容分发云或内容云(contentdeliverycloud,contentcloud)的技术也已经出现,在国际学术界已经有初步的研究,但还没有比较成熟的技术和大规模应用出现。diniu等【dcb2012,diniu,chenfeng,baochunli,atheoryofcloudbandwidthpricingforvideo-on-demandproviders,inieeeinfocom2012.】针对vod应用提出一种云带宽的动态定价理论。他们提供一种新的类型服务,如netflix和hulu的视频点播提供商以可协商的价格从云端资源预留相应带宽保障支持连续的流媒体,但最终是依托于单一云提供内容分发服务,还没有用到多云架构。hongqiangliu【hyr2012,hongqiangharryliu,yewang,yangrichardyang,haowang,chentian,optimizingcostandperformanceforcontentmultihoming,sigcomm'12,371-382.】在sigcomm2012上提出目前的视频内容发布商经常利用多个cdn平台来帮助其分发视频内容,这称为contentmultihoming问题,该文研究了contentmultihoming如何达到流媒体性能和所花费用的平衡和优化。该论文用到了多cdn技术提供流媒体服务,cdn服务不能动态扩展,该论文没有用到可以灵活扩展的多云架构。zhewu等在国际权威会议sosp2013上发表【zmd2013,zhewu,michaelbutkiewicz,dorianperkins,ethankatz-bassett,andharshav.madhyastha,spanstore:cost-effectivegeo-replicatedstoragespanningmultiplecloudservices,sosp’13,nov.3–6,2013,usa.】提出spanstore,跨越多个云数据中心构建高性价比的云存储系统,spanstore通过评估应用负载特征,确定分布式副本的放置位置,满足应用延迟的要求和较低的云租用成本,该成果对我们的研究有很好的借鉴作用,该方法侧重于多云数据中心支持的云存储技术,我们的发明侧重于多云架构支持的内容分发服务。
技术实现要素:
本发明的目的在于提出一种新型的基于多云架构下的内容分发服务资源优化调度方法。本发明基于多云架构,包含若干公有云与私有云。在这个模式中,由于公有云的动态弹性,在内容服务提供商内部私有云负载达到饱和的情况下,平台可以根据预测和实时情况完成多云环境下的初部署、扩展与切换,以应对流媒体服务中大量突发性的用户请求。利用此机制,在降低费用成本,保证性能的情况下,用户体验度能得到进一步提升。
本发明基于多云架构系统框架,将多媒体内容分发作为目标应用,设计了内容分发服务资源优化配置与调度方法。本发明在多云架构下,覆盖了多云选择初部署、多云扩展以及多云切换三个机制,并且加入了监控模型、负载预测算法以及内容资源预拷贝precopying机制,使得整个配置与调度机制更具有适用性和通用性。
本发明的技术方案具体介绍如下。
本发明提供一种基于多云架构的内容分发服务资源优化调度方法,其根据预测和实时情况完成多云环境下的初部署、扩展与切换;具体如下:
(1)多云选择初部署阶段
按照多云选择初部署启发式算法,寻找部署开销最小、性能较优的云站点,并启动虚拟机部署流媒体应用,之后针对每一个云站点,找到其上游的最优云站点,并拷贝流媒体内容资源,通过两层的优化,减少部署的开销;
(2)多云扩展阶段
多云扩展阶段针对可预测和云爆发架构下的多云扩展:
在可预测的多云扩展方案中,基于时间序列分析的arima预测模型,通过对历史监控数据分析并将其作为输入,在判定为有效预测值的基础上,完成对未来资源需求量以及需切换时间点的预测分析,并通过多云选择初部署启发式算法,使得分配与分发同时进行,在得到部署拓扑后,完成流媒体应用本身需提供的webservice及流媒体内容的部署与拷贝;当监控模块报警,即已有数据中心无法为用户的访问提供正常服务时,将已部署好的新数据中心激活并投入使用;
在云爆发架构下的多云扩展方案中,监控模块通过实时监控数据检测到超过设定的阈值时,向系统发出警报,通过查看部署拓扑,选择出最小存储租赁开销以及带宽优质的云数据中心cdc,并在所选的新的云数据中心cdc中启动虚拟机集群,之后对于集群中的每一台机器,采用预拷贝precopying的策略将常用内容资源拷贝至虚拟存储当中,在这个过程中采用合适的冲突度小的hash算法,将内容资源散列至不同的虚拟存储中;之后将源云站点中各虚拟机上提供流媒体应用访问的webservice虚拟镜像拷贝至新的云数据中心cdc的每一台虚拟机中,并在所有的新的虚拟机中启动访问服务;
(3)多云切换阶段
首先根据监控数据作为输入,当带宽资源、用户访问量或者整个集群全部宕机时,系统的决策模块做出多云切换的决策,通过查看部署拓扑,选择开销最小并且性能较佳的一个或者若干数据中心作为新集群部署;采用预拷贝precopying的策略进行内容资源初次拷贝,之后在虚拟机流媒体应用服务启动好后,迅速向外提供访问服务,并且在服务稳定之后逐步将剩余的内容资源拷贝至新的内容分发数据中心中。
本发明中,多云选择初部署阶段中,基于备选多个公有云服务资源提供商的计费策略提出一种云选择初部署启发式算法;通过云选择初部署启发式算法,完成了多云选择初部署;所述计费策略中,将虚拟机集群转化为聚合的概念,定义ai为每一个聚合后的服务请求,将每一个ai分配给若干个虚拟机提供服务,同时最小化各项成本,就可得到虚拟机为了满足用户的请求所需要的最低费用,也就是系统运行的最小总费用;系统运行的最小总费用的定义如下式:
cvi表示虚拟机租赁对于每个聚合请求的单价费用,csi表示存储在每个聚合请求上的单价费用,cti表示虚拟机之间流量传输在每个聚合请求上的单价费用。
本发明中,采用zabbix监控方案周期性的获取并保存历史监控信息
本发明中,多元扩展阶段,所述历史监控信息是包括计算节点和存储节点的cpu、内存、diski/o、网络带宽及吞吐量的状态信息;
本发明中,在可预测的多云扩展方案中,用基于时间序列分析的arima(自回归积分滑动平均模型autoregressiveintegratedmovingaveragemodel)预测模型对未来资源需求量以及需切换时间点进行预测分析时,arima模型包括参数选择p和q,平均值估计,随机变量相关系数和白噪声方差;计算未来的需求一共以下几个步骤;
定义o(t)和p(t)分别表示在t时刻的观测值和预测值;使用t表示预测的开始时刻,s表示预测的时长;开始时刻是当前时刻;预测算法是用一系列观测值o(0),o(1),...,o(t)来预测未来的需求值p(t+1),p(t+2),...,p(t+s);
首先测试数据是否具有平稳性和能迅速降低自相关的函数;如果有,算法将继续下一步;否则,使用差分的方法,将序列平滑化,直到它是变成稳定的序列为止;
然后,使用一个变换级数来表示数据零均值处理后的结果,这样将预测转化为,基于{xt}(0≤t≤t),预测{xt}(t>t);
接着,针对预处理后的序列,计算自相关函数acf和偏自相关函数pacf,从而辨别采用ar,ma还是arma模型;一旦数据被转换到变换后的序列{xt},并且序列{xt}可以被应用到零均值的arma模型进行拟合后,根据aic的akaike信息准则,选择合适的p和q的值;
最后,在所有的参数都选择好之后,做模型检查以确保预测的精度;检查一共有两步,第一该模型的稳定性和可逆性,第二残差;如果检查结果满足所有的标准,便可以开始预测,否则,将会回到参数选择和估计,并采取更细粒度的方式找到合适的参数;当所有的数据都适合模型后,对整个过程进行预测;
本发明中,多云扩展阶段和多云切换阶段中的预拷贝precopying策略具体如下:
算法定义流媒体应用共有n种流媒体资源,每个资源i分布在mi个机器上;定义l为不同云的地理位置,假设l=1时为流媒体应用服务提供商的企业私有数据中心,定义hl为在l处的服务器数量;系统所关注的各服务器的计算资源包括:cpu使用量,内存需求量,磁盘和网络带宽的需求量,分别表示为pikl、rikl、dikl、bikl,代表第ith流媒体资源在lth地点的第kth服务器,定义costikl为将第ith流媒体资源移动到lth地点的第kth服务器所花费的成本开销;
定义αikl和βikl为二进制变量,定义如下:
定义c为流媒体资源拷贝的开销:
本方案提出的ilp算法如下:
使得c最小化,确保:
如上述所示,公式1确保每种资源在一个单独的服务器节点上,公式2到公式5确保流媒体内容资源所占的cpu、内存、磁盘和网络带宽资源不超过宿主机的资源总和,公式7和公式8确保所有的内容资源在同一地理位置location;
考虑最简单的架构情形,即只有一个公有云和一个私有云;因此,我们定义多云间流媒体资源拷贝的开销主要由以下三部分构成:
i.将内存状态和存储资源从私有云拷贝到公有云;
ii.存储流媒体内容资源数据;
iii.在公有云运行流媒体应用并关联内容资源。
定义τ为预测的过载时间长度,则有:
costikl=tikl+(rikl*τ)+(sikl*months(τ))(公式9)
其中:
tikl=tsikl+tmikl(公式10)
在公式9和公式10中,tikl表示所有流媒体内容资源拷贝的网络传输成本,具体表现为私有云上虚拟机的存储量(如tsikl)和内存页状态(如tmikl);rikl表示在公有云上运行虚拟机实例的每小时成本;sikl表示在公有云上使用存储服务存储流媒体内容资源数据的存储成本,通常按月支付。
和现有技术相比,本发明的有益效果在于:
本发明解决了在多云环境中,流媒体应用的自动优化初部署,当访问流量突发激增时云架构敏捷扩容,以及当某个私有云数据中心或某公有云宕掉或出现严重带宽等问题时,云服务如何快速切换的问题。
附图说明
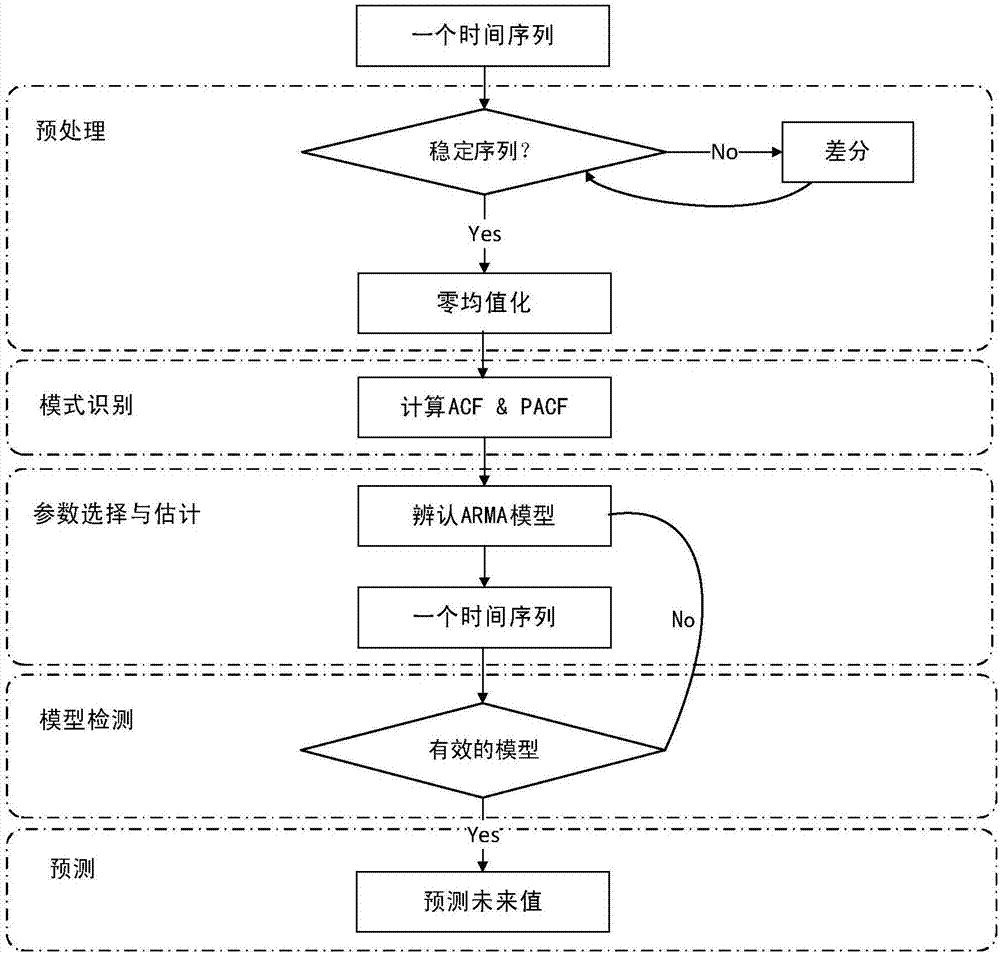
图1为预测模型。
图2多云切换流程图。
图3为费用对比图。
图4为性能对比图。
图5为预拷贝过程中丢包率变化图。
图6为预拷贝与直接拷贝对比图。
图7为本发明总体结构图。
具体实施方式
下面结合附图和实施例对本发明的技术方案具体介绍如下。
本发明的目的在于提出一种新型的基于多云架构下的内容分发服务资源优化配置与调度方法。如图7所示,本发明基于多云架构进行内容分发服务资源配置,包含若干公有云与私有云。视频服务提供商自身具有内部的私有云或者自有数据中心,在这个模式中,由于公有云的动态弹性,在视频服务服务提供商内部私有云负载达到饱和或中断的情况下,平台可以根据预测和实时情况完成多云环境下的初部署、多云扩展与多云切换多重保障机制,以充分应对流媒体服务中大量突发性请求或者自身服务出现中断的情况。利用多云内容分发机制,在降低费用成本,保证性能的情况下,用户体验度能得到进一步提升。
本发明中,基于多云架构下内容分发服务资源优化配置与调度方法,具体分为以下三个阶段:
1.多云选择初部署方法
这里将详细阐述多云选择初部署算法的内容。本算法分配与分发同时进行。算法最终实现的目标是:把区域内的各用户抽象为逻辑上的节点,通过对各个路径开销的计算,最终找到了一个开销最小并且性能较高的路径拓扑,将流媒体内容资源通过启发式初部署算法,逐一分发至其他逻辑上的云站点的虚拟机中,从而完善各个区域用户的访问体验。最终的拓扑结构使得区域内的所有用户都同源节点直接或间接建立连接,并且从原站点到每个用户节点只有一条路径的最小连通图。
每个私有云在各个节点都有不同的数据传输和数据存储的代价开销,在起始状态,只有源站点的c0存有流媒体内容数据,而其他的云站点上的虚拟机在初始化部署和内容资源传输过程中会产生初部署代价。我们从流媒体应用服务提供商的角度出发,寻找部署开销最小、性能较优的云站点,并启动虚拟机部署流媒体应用,之后针对每一个云站点,找到其上游的最优云站点,并拷贝流媒体内容资源,通过两层的优化,来尽量减少部署的开销。
下述算法1是多云选择初部署启发式算法的具体实现。算法中的数学符号描述如下:lmj表示用户区域am到云节点cj的距离;
算法首先计算每个区域am到各个站点的平均距离,并且将区域按l′m升序关系排序,得到集合ao。从前向后遍历ao集合,对于每一个ao中的云节点am,首先将将区域am中所有请求,分配到距离最小lmj的云站点cj,这一个步骤是为了寻找一个性能较优的云站点。根据云节点的计费策略,计算各节点同可以建立上连接的节点连接时的部署开销,计算比较出来最小的开销建立连接,这个过程中有一个前提是不能超出这个节点的连接最大带宽限制。然后在每个节点连接的过程中需要考虑到有重复路径的情况,也就是保证从原站点到用户节点路径的唯一性。如果不能满足这种唯一性就会产生额外冗余的开销。
接下来我们需要针对每一个云节点,找到其上游的最优云站点。这个最优云站点的方式就是遍历所有用户站点am相对于流媒体l的可建立连接的云站点,找出拥有最小连接距离的站点wij=dj+oi,记录在拓扑图中。其中dj是cm中的节点cj的下载代价,使用oj代表云站点虚拟机的部署开销,wij表示两个云站点虚拟机之间的数据传输开销,那么当云站点上已完成流媒体应用部署和内容资源存放时,oj=0,否则oj=wij。
2.多云扩展阶段
前一步中建立了一个部署开销最小的分发拓扑。在多云扩展的机制当中,分为可预测的多云扩展方案和云爆发架构下的多云扩展方案。
本方法引入一个基于差分自回归移动平均模型(arima模型)的负载预测算法,用来预测每一个vm的使用负载情况以及用户服务请求情况。每台vm的cpu使用率,带宽使用,以及流请求数作为模型的输入,从而预测未来的情况。
arima模型采用了广泛的非平稳时间序列的预测。它是arma模型的推广,可以简化arma过程。arima将数据进行初步转换,产生新的,可以适合到arma过程的新序列,然后进行预测。
arima模型包括参数选择p和q,平均值估计,随机变量相关系数和白噪声方差。它需要大量的计算来获取最佳参数,它比其他线性预测方法更复杂一点,但是它的性能很好,并且在一定程度上可以作为预测的基本模型。
计算未来的需求一共有五个步骤,图1描述了本发明所采用的预测模型。定义o(t)和p(t)分别表示在t时刻的观测值和预测值。使用t表示预测的开始时刻,s表示预测的时长。开始时刻一般是当前时刻。简而言之,预测算法试图用一系列观测值o(0),o(1),...,o(t)来预测未来的需求值p(t+1),p(t+2),...,p(t+s)。
首先测试数据是否具有平稳性和能迅速降低自相关的函数。如果有,算法将继续下一步。否则,使用差分的方法,将序列平滑化,直到它是变成稳定的序列为止。例如,o′(t-1)=o(t)-o(t-1),并测试序列o′(t-1)是否稳定。然后,使用一个变换级数来表示数据零均值处理后的结果,例如
接下来,针对预处理后的序列,计算自相关函数(acf)和偏自相关函数(pacf),从而辨别采用ar,ma还是arma模型。
一旦数据被转换到变换后的序列{xt},并且序列{xt}可以被应用到零均值的arma模型进行拟合后,接下来的问题是,面临着选择合适的p和q的值。本算法选择被称为aic的akaike信息准则,因为它是一个更普遍适用的模型选择准则。
在所有的参数都选择好之后,将会做模型检查以确保预测的精度。检查一共有两步,第一该模型的稳定性和可逆性,第二残差。如果检查结果满足所有的标准,便可以开始预测,否则,将会回到参数选择和估计,并采取更细粒度的方式找到合适的参数。
当所有的数据都适合模型后,便可以对整个过程进行预测。
(1)可预测的多云扩展
本节提供了一种基于预测模型的多云扩展方案。首先监控模块根据历史监控数据分析,并通过上面提出的arima预测方案预测出未来一段时间内,现有的数据中心资源不足以提供足够的带宽访问,此时综合考虑备选数据中心的计费策略c及机房地理位置p分布,类似多云选择初部署的过程,选择扩展的数据中心并采用分配与分发同时进行的策略,将流媒体应用的webservice和内容资源复制部署到新的云数据中心中。当某些监控项(例如cpu空闲时间、内存使用量、diski/o、http请求数和网络带宽使用量等)数值超过设定的阈值或现有数据中心可以提供的最大访问量时,将备用数据中心激活,完成多云扩展的过程。
算法的目标是,在现有数据中心资源提供量r达到阈值时,把放置在源节点c0的流媒体信息分发到其他访问量过多的地区或现有地区以满足各个区域用户的访问需求。本算法的核心有以下两点:首先预测模块通过历史监控信息预测出超过资源设定阈值的时间t和额外需要提供的网络带宽资源r′;其次通过在特定的区域集合a中对于新申请的云数据中心cloudbm可以视为一个多云选择初部署的过程。最后,当监控模块报警现有数据中心的资源无法提供正常的服务时,激活已经部署好的cloudbm,从而以看似透明的过程完成可预测的多云扩展。
下述算法2是可预测的多云扩展算法的具体实现:
在上述算法2中,从流媒体应用服务提供商的角度出发,基于时间序列预测分析方法arima预测模型,通过对历史监控数据分析并将其作为输入,在判定为有效预测值的基础上,完成对未来资源需求量以及需切换时间点的预测分析;并通过算法1中提供的多云选择初部署启发式算法,使得分配与分发同时进行,在得到部署拓扑g后,完成流媒体应用本身需提供的webservice及流媒体内容的部署与拷贝;当监控模块报警,即已有数据中心无法为用户的访问提供正常服务时,将已部署好的新数据中心激活并投入使用。本算法2中数学符号描述如下:mi表示过去第i天的历史监控数据;r′表示通过预测模块的arima预测模型分析后,得到的额外需要提供的网络带宽等资源;其余符号同算法1。
(2)云爆发架构下的多云扩展
本发明采用采用云爆发模式的最大优点是可以节省成本,在日常的企业运作过程中,云爆发只需要企业为服务器集群的日常运维所需的资源支付成本,而无须进行超常准备以应付访问请求高峰时段,这使得企业可以更加有效地利用现有资源,同时也可以降低总成本支出;云爆发也具有更高的灵活性,使得系统可以迅速适应意料之外的高峰需求,在需求发生变化时进行调整。
虽然目前云爆发架构有诸多好处,然而现有的解决方案通常无法满足本发明所需求的流媒体应用大量的内容资源迁移所能够等待的时间,事实上,这个过程通常需要2到10天的时间才能够将已有的流媒体内容资源完全从私有云迁移至公有云,这对于突发状况下用户访问流媒体应用请求或流量激增的情况下是无法达到相应的qos标准的。这种长时间的延迟主要原因是在私有云和公有云之间有限的带宽连接环境下,大量的流媒体内容资源传输,以及流媒体应用本身虚拟机迁移需要复制的磁盘镜像所产生的较长时间延迟。
本发明针对上述问题提出了一种基于“预拷贝(precopying)”机制的云爆发多云扩展方法。
在上述算法3中,在云爆发的架构下,监控模块通过实时监控数据m检测到超过设定的阈值时,向系统发出警报,现有资源可能无法为用户提供正常速度的访问服务,系统即作出在云爆发架构下多云扩展的决策。此时通过查看在算法1和算法2中的拓扑g,选择出最小存储租赁开销以及带宽优质的云数据中心cdc为ao,并在所选的新的云数据中心cdc中启动一定配额的虚拟机集群。之后对于集群中的每台机器,采用预拷贝precopying的机制将常用的内容资源r0拷贝至虚拟存储当中,在这个过程中我们采用合适的冲突度小的hash算法,将内容资源散列至不同的虚拟存储中。之后系统将源云站点中各虚拟机上提供流媒体应用访问的webservice虚拟镜像拷贝至新的云数据中心cdc的每一台虚拟机hm中,并在所有的新的虚拟机中启动访问服务。当资源优化调整后的服务器集群可以良好稳定的提供流媒体访问服务时,将剩余的内容资源r′逐步拷贝至新的云数据中心cdc中。
由于云爆发架构下多云扩展方案的不可预测性,为了维持良好的访问服务,需要将应用扩展和内容拷贝的时延(copy-delay)尽量降低,本系统采用了预拷贝precopying的方案,将最常被访问的内容资源优先拷贝至多云扩展申请的新的云数据中心cdc中,同时完成webservice的迁移,系统通过监控模块检测到所有的监控项(monitoringmetrics)在一段时间内处于正常的状态后,将剩余的内容资源在不影响现有的访问服务的前提下,逐步拷贝至扩展的云数据中心中。
3.多云切换
当某个或某些云数据中心由于某些原因宕机或无法提供正常服务时,比如由于云数据中心突然停电、硬件故障或网络带宽受限,导致当前数据中心无法正常处理用户请求。此时需要暂停现有出现问题的流媒体应用,并申请新的可用的云架构提供流媒体服务,将现有的流媒体访问服务和内容资源快速迁移到新的数据中心中,尽量减少这个过程中产生的延迟,从而以最小的影响来继续为用户提供良好的流媒体访问服务。
我们设计的多云切换的流程如图2所示。在现有云服务出现问题报警时,系统捕捉报警信号并做出多云切换的决策。首先根据监控数据作为输入,当带宽资源、用户访问量或者整个集群全部宕机时,系统的决策模块迅速做出多云切换的决策,通过查看部署拓扑,选择开销cost最小并且性能较佳的某个或者某些数据中心作为新集群部署。在此过程中,同多云选择初部署的不同点在于,我们必须尽量减少由于数据中心大规模故障,流媒体应用受影响的时间,所以在此我们采用我们第二步设计的预拷贝precopying的策略进行内容资源初次拷贝。之后在相应的虚拟机流媒体应用服务启动好后,迅速向外提供访问服务,并且在服务稳定之后逐步将剩余的内容资源拷贝至新的云数据中心中。
实施例1
一、多云初部署实验
为了实施方法发明的全过程并评估发明算法的性能,本发明实验部分,将应用确定为视频点播内容分发,公有云模型使用aws的ec2,私有云使用openstack平台。
我们在实验中在本地搭建了两个基于虚拟化技术的数据中心,安装openstack作为私有云。同时在aws上申请了账号,租赁ec2服务并申请aws虚拟机,作为公有云。在每个云上启动5台虚拟机作为流媒体服务器,所有的虚拟机上均安装linuxcentos7系统。为了不占用过多的网络带宽资源,我们将带宽最大值设定为10mbps。
在流媒体应用初部署的实验中,本发明实现了3种选择算法。一种算法是最优性能算
法,此算法在选择虚拟机时只考虑虚拟机的性能,每次租用性能最优的虚拟机而不考虑价格。第二种是本发明中设计的多云选择初部署启发式算法,在一定的性能限制下,最小化租赁开销。第三种是贪心算法,此算法在选择虚拟机时只考虑租赁价格,每次都租用价格最低的虚拟机来部署流媒体服务,而完全不考虑性能。在本实验中,我们采用租赁虚拟机的总开销和视频流访问的命中率作为多云初部署的主要评估指标。
图3显示了3种部署方式在租赁虚拟机总开销上的对比,横轴表示部署流媒体内容大小,纵轴表示租赁总开销。
从结果中可以清晰的看出,租赁费用曲线几乎是呈线性递增,通过比较这三种部署方式可知,启发式初部署算法的租赁费用几乎比最优性能算法低30%,这一点比较容易理解,因为最优性能算法完全没有考虑租赁价格的问题。贪心算法的租赁价格最低,但启发式初部署算法仅高出一小部分。
虽然贪心算法的总体费用最低,但如图4所示,贪心算法的总租赁开销虽然最低,但贪心算法的性能相当之差,只有73.6%的用户可以流利的完成对视频的访问。相比之下最优性能算法的性能几乎是100%,表示几乎所有用户都可以完整的看完整部视频。而启发式初部署算法虽然有存在对视频访问失败的情况,但总体来讲同最优性能算法相差不大。
因此,本实验得出以下结论:启发式初部署算法的成本同贪心算法接近,而用户体验度同最优性能算法接近,表示启发式初部署算法在能尽量小的减少部署成本的同时,保证一定的用户体验和视频质量。
二、多云扩展和多云切换实验
本发明定义了一些针对流媒体应用服务器的各种资源和性能测试参数作为评价流媒体服务器性能优劣的指标。从整体的测评角度来看,这些指标主要包括最大的并发流数目、聚合输出带宽、丢包率等。
·最大并发流数目。最大并发流数目指的是流媒体服务器可以在较长的时间支持的最多客户端的数量,在并发量增加到最大的并发流数目之前,流媒体应用不会停止对已经建立连接的客户端提供服务。最大并发流数主要通过流媒体服务器的硬件配置和流媒体应用软件的实现共同来决定,同时受到所访问的视频流码率的影响。
·聚合输出带宽。聚合输出带宽是指流媒体服务器向外面节点传输视频流数据时所能够达到的最大带宽,理论上等于最大并发流数目乘以视频流的码率。影响流媒体服务器聚合输出带宽指标的通常有网卡、内存、cpu、磁盘i/o通道等,但随着硬件的发展,千兆网卡、固态存储设备以及内存大小已经不是流媒体系统的瓶颈。
·丢包率。本发明所指的丢包率是服务器端将需要发送的视频数据丢弃。丢包通常是导致视频图像质量不佳的本质原因。因为视频数据前后关联,并且各类数据包对于恢复图像所起到的作用不同,即便在很低的丢包率情况下,加码器也有可能主动丢弃其他数据包,引起视频质量下降。
基于上述实验环境设计并完成了预拷贝策略的验证实验,主要途径是逐渐增加并发量,并在多云扩展的预拷贝过程中观察用户请求丢包率的变化趋势。我们首先在一个云(clouda)上逐渐增加并发量,如图5所示,在并发量小于30时,单个集群处理用户请求保持在很高的水平,系统的丢包率基本低于5%。当我们逐渐增加并发量时,单个集群逐渐有了较大的丢包率,并且当并发量达到55的时候,丢包率高达35%,此时单个集群的系统很难去处理如此高的并发量访问请求。此时我们采用多云扩展的策略,并且将clouda上的内容资源通过预拷贝的方式拷贝到cloudb中,并继续增加并发量。可以看出,随着预拷贝的逐渐进行,系统丢包率在逐渐下降,由于内容资源的丰富性和空间大的特点,系统的丢包率不会立刻恢复到很低的水平,大概一段时间之后,丢包率恢复到了5%以下。此后我们重复上述过程,逐渐增加请求的并发量,并在丢包率接近30%时继续扩展cloudc,可以从图5中看到在采用预拷贝的策略后,系统的丢包率在逐渐下降。
我们接下来做了一组对比实验,其中一组采用预拷贝策略,另外一组将内容资源直接拷贝至新的云中。实验结果如图6所示,当系统在多云扩展过程中采用预拷贝策略对内容资源进行拷贝时,可以在较短的时间完成较多的内容资源拷贝,从而迅速降低系统的丢包率,提升系统处理请求的能力;而使用直接拷贝时,由于存在大量的内容资源,导致系统无法及时的将大量的多媒体内容资源及时拷贝到新的集群中,采用直接拷贝的方式迁移内容资源对于扩展的丢包率降低效果并没有预拷贝的效果显著。
多云切换实验同样是在较短时间迅速增加新的内容分发服务资源来取代失效的服务,我们也是采用预拷贝方法,试验效果和多云扩展是一致大的。
- 还没有人留言评论。精彩留言会获得点赞!