用于确定有目标的内容消息的适宜性的方法和系统与流程
分案申请的相关信息本申请是分案申请。该分案申请的母案是申请日为2008年11月14日、申请号为200880123930.9、发明名称为“用于确定地理用户简档以基于所述简档确定有目标的内容消息的适宜性的方法和系统”的发明专利申请案。本申请主张的优先权本申请案主张以下美国临时专利申请案的优先权且并入有其全部内容:2007年12月14日申请的标题为“用于确定地理感兴趣点和用户简档信息的方法和系统(methodandsystemfordeterminginggeographicpointsofinterestanduserprofileinformation)”的第61/013,941号(高通公司代理人案号072406p1)。本申请案主张以下美国临时专利申请案的优先权且并入有其全部内容:2007年11月14日申请的标题为“用于移动环境中的用户简档匹配指示的方法和系统(methodandsystemforuserprofilematchindicationinamobileenvironment)”的第60/988,029号(高通公司代理人案号071913p1);2007年11月14日申请的标题为“用于移动环境中的关键词相关的方法和系统(methodandsystemforkeywordcorrelationinamobileenvironment)”的第60/988,033号(高通公司代理人案号071913p2);2007年11月14日申请的标题为“用于移动环境中的用户简档匹配指示的方法和系统(methodandsystemforuserprofilematchindicationinamobileenvironment)”的第60/988,037号(高通公司代理人案号071913p3);以及2007年11月14日申请的标题为“用于移动环境中的消息值计算的方法和系统(methodandsystemformessagevaluecalculationinamobileenvironment)”的第60/988,045号(高通公司代理人案号071913p4)。本申请案还并入有以下美国非临时专利申请案的全部内容:2008年11月11日申请的标题为“移动环境中的用户简档匹配指示方法和系统(userprofilematchindicationinamobileenvironmentmethodsandsystems)”的第12/268,905号(高通公司代理人案号071913u1);2008年11月11日申请的标题为“移动环境中使用关键词向量和相关联度量来学习和预测有目标的内容消息的用户相关的的方法和系统(methodandsystemusingkeywordvectorsandassociatedmetricsforlearningandpredictionofusercorrelationoftargetedcontentmessagesinamobileenvironment)”的第12/268,914号(高通公司代理人案号071913u2);2008年11月11日申请的标题为“用于在移动环境中使用高速缓冲存储器未中状态匹配指示符来确定有目标的内容消息的用户适宜性的方法和系统(methodandsystemforusingacachemissstatematchindicatortodetermineusersuitabilityoftargetedcontentmessagesinamobileenvironment)”的第12/268,927号(高通公司代理人案号071913u3);2008年11月11日申请的标题为“用于移动环境中的消息值计算的方法和系统(methodandsystemformessagevaluecalculationinamobileenvironment)”的第12/268,939号(高通公司代理人案号071913u4);2008年11月11日申请的标题为“移动环境中使用关键词向量和相关联度量来学习和预测有目标的内容消息的用户相关的方法和系统(methodandsystemusingkeywordvectorsandassociatedmetricsforlearningandpredictionofusercorrelationoftargetedcontentmessagesinamobileenvironment)”的第12/268,945号(高通公司代理人案号071913u5)。本发明涉及无线通信。明确地说,本发明涉及可用于确定移动装置的用户的地理感兴趣点的无线通信系统。
背景技术:
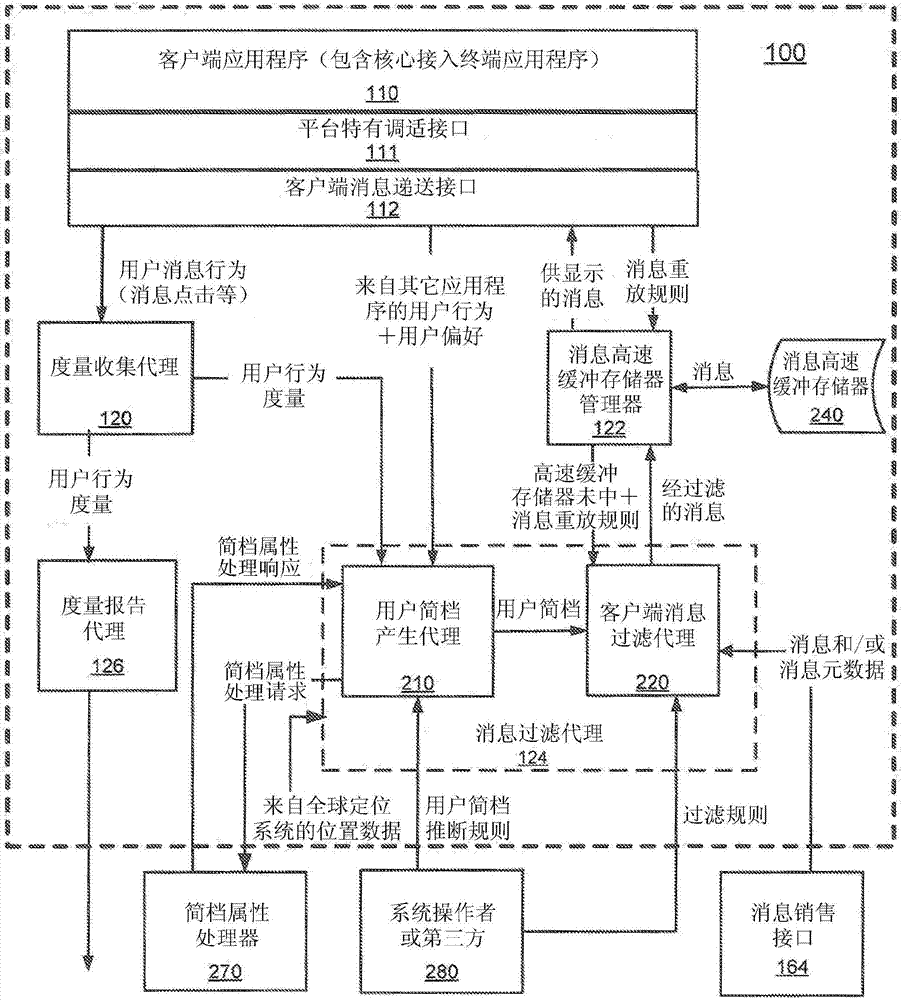
:可将具有移动有目标内容消息(tcm)功能的系统描述为能够将例如以特定人口统计为目标的本地天气报告和广告等有目标的内容信息递送到例如蜂窝式电话或其它形式的无线接入终端(w-at)等无线通信装置(wcd)的系统。此类系统还可通过呈现用户可能感兴趣的非侵入有目标内容消息来提供较好的用户体验。具有移动tcm功能的系统的实例是能够将广告递送到无线通信装置(wcd)的移动有目标广告系统(mas)。一般来说,mas可提供此类事物作为广告销售渠道,供蜂窝式提供者在w-at以及某一形式的分析界面上提供广告以返回报告各种广告活动的执行情况。移动广告的特定消费者益处是其可为无线服务提供替代/额外收入模型,以便将对无线服务的更经济的接入权许可给那些愿意接受广告的消费者。举例来说,通过广告产生的收入可允许w-at用户在不用支付通常与各种服务相关联的全额预订价的情况下享受此类服务。为了增加tcm在w-at上的有效性,提供有目标的信息(即认为可能被特定人或指定人群完全接收和/或可能为其所感兴趣的tcm)可能是有益的。有目标内容消息(tcm)信息可基于即时需要或境况,例如找到紧急路边服务的需要或对关于旅行路线的信息的需要。有目标的内容消息信息还可基于用户过去已对其表示出兴趣的特定产品或服务(例如,游戏),且/或基于人口统计,例如可能对特定产品感兴趣的年龄和收入群组的确定。有目标的广告是tcm的实例。有目标的广告可提供若干优点(优于一般广告),包含:(1)在基于按观看次数计费的经济结构中,广告商可能够通过将付费广告限于较小的一组可能主顾来增加其广告预算的价值;以及(2)因为有目标的广告可能表示特定用户感兴趣的领域,所以用户将对有目标的广告积极响应的可能性大大增加。遗憾的是,使一些形式的有目标的广告成为可能的信息可能因政府法规和人们限制其个人信息的传播的期望而受到限制。举例来说,在美国,此类政府法规包含金融服务现代化法(graham-leach-blileyact,glba),美国法典第47卷,第222部分—“客户信息的隐私权”。公用事业公司也可能被限制将关于其订户的个人信息用于营销目的。举例来说,glba禁止在无客户事先明确授权的情况下使用可个别识别的客户信息以及揭露所在地信息。因此,用于在无线通信环境中递送有目标的广告的新技术是合乎需要的。技术实现要素:在示范性实施例中,一种用于确定信息由移动客户端接收的适宜性的方法可包含:识别所述移动客户端的位置历史信息的集合;基于所述位置历史信息更新所述移动客户端的用户简档;以及基于所述经更新的用户简档在所述移动客户端上显示和/或存储目标信息。在另一示范性实施例中,一种用于确定信息由移动客户端接收的适宜性的设备可包含:用于识别所述移动客户端的位置历史信息的集合的装置;用于基于所述位置历史信息更新所述移动客户端的用户简档的装置;以及用于基于所述经更新的用户简档在所述移动客户端上显示目标信息的装置和/或存储目标信息的装置。在另一示范性实施例中,一种移动客户端可包含存储器、收发器、处理器,所述处理器耦合到所述存储器和收发器且可操作以:识别所述移动客户端的位置历史信息的集合;基于所述位置历史信息更新所述移动客户端的用户简档。所述移动客户端可进一步包含并入到所述移动客户端中的显示器,其能够基于所述经更新的用户简档在所述移动客户端上显示目标信息。在另一示范性实施例中,一种计算机程序产品可包含计算机可读媒体,所述计算机可读媒体又可包含:用于识别移动客户端的位置历史信息的集合的指令;用于基于所述位置历史信息更新所述移动客户端的用户简档的指令;以及用于基于所述经更新的用户简档在所述移动客户端上显示和/或存储目标信息的指令。附图说明结合图式理解时,本发明的特征和性质将从下文所陈述的详细描述中变得更明白,在图式中,参考符号始终识别对应项目和过程。图1是展示示范性无线接入终端(w-at)与广告基础结构之间的交互的图。广告基础结构是有目标内容消息处理基础结构的实例。图2是展示具有机载用户简档产生代理的示范性w-at的操作的示意性框图。图3是展示用户简档产生代理的数据传送的示范性操作的示意性框图。图4是处置对简档数据处理的示范性请求的示意性框图。图5是展示用户简档产生代理的示范性操作的示意性框图。图6是概述产生和使用用户简档的示范性操作的流程图。图7是概述产生和使用用户简档的另一示范性操作的流程图。图8是说明当可识别数据传送到移动广告/移动有目标内容消息处理服务器时将单向散列函数用于客户端身份保护的图。图9是说明由代理服务器实施的用于使传送到移动广告服务器/移动有目标内容消息处理服务器的可识别数据匿名化的数据流的图。图10是说明由代理服务器实施的用于使传送到移动广告服务器/移动有目标内容消息处理服务器的可识别数据匿名化的第二数据流的图。图11描绘用于具有移动有目标内容消息功能的网络中的广告分布的通信协议。图12描绘用于具有移动消息递送功能的网络中的有目标内容消息分布的另一通信协议。图13描绘用于具有移动消息递送功能的网络中的有目标内容消息分布的另一通信协议。图14描绘用于具有移动消息递送功能的网络中的有目标内容消息分布的另一通信协议。图15描绘用于根据“联系窗”方法下载广告内容的第一通信协议的时间线。图16描绘用于根据所定义的时间表来下载广告内容的通信协议的替代时间线。图17描绘用于根据所定义的时间表来下载内容的第一通信协议的替代时间线。图18是消息过滤过程的说明。图19是消息过滤过程组件的说明。图20是选通过程的说明。图21是随机取样逻辑图的说明。图22是基于单向函数的取样逻辑图的说明。图23是选择过程流程图的说明。图24a和图24b描绘消息选择过程的流程图。图25是说明示范性用户简档匹配指示符(mi)过程的流程图。图26是说明示范性用户简档匹配指示符的框图。图27是示范性关键词相关过程的流程图。图28是说明示范性学习和预测引擎的框图。图29是说明与移动客户端的其它元件联系起来的示范性学习和预测引擎的框图。图30a描绘示范性分级关键词组织。图30b描绘示范性非分级/展平关键词组织。图31描绘表示用于使移动客户端能够适合于用户偏好的示范性学习过程的预期性能的一系列曲线图。图32a和图32b描绘说明用于使移动客户端能够适合于用户偏好的示范性过程的框图。图33是多播/广播消息分布的说明。图34是示范性单播消息分布协议的说明。图35是另一示范性单播消息分布协议的说明。图36是又一示范性单播消息分布协议的说明。图37是再一示范性单播消息分布协议的说明。图38a到图38h描绘具有针对特定用户的历史信息的各种所捕获的位置数据。图39和图40描绘针对用户的示范性位置和路径集合。图41是图39和图40的所述位置和路径集合的示范性马尔可夫模型(markovmodel)。图42是概述用于基于所捕获的位置信息来更新用户简档的示范性操作的过程流的图。具体实施方式可概括地以及依据特定实例和/或特定实施例来描述下文所揭示的方法和系统。对于其中参考详细实例和/或实施例的例子,应了解,所描述的基本原理中的任一者均不限于单个实施例,而是可经扩展以与本文所描述的其它方法和系统中的任一者一起使用,如所属领域的一般技术人员将了解(除非另外明确陈述)。出于实例的目的,本发明常被描绘为实施于蜂窝式电话中(或与其一起使用)。然而,将了解,下文所揭示的方法和系统可涉及移动和非移动系统两者,包含移动电话、pda和膝上型pc,以及任何数目的经特殊装备/修改的音乐播放器(例如,经修改的苹果(apple))、视频播放器、多媒体播放器、电视机(固定、便携式和/或安装在交通工具中)、电子游戏系统、数码相机和可携式摄像机。提供以下术语和相应的“定义/描述”作为对以下揭示内容的参考。然而,请注意,如所属领域的一般技术人员鉴于特定情形可明白,当应用于某些实施例时,所应用的定义/描述中的一些定义/描述可扩展或可以其它方式与下文所提供的特定语言中的一些不一致。tcm-有目标的内容消息。广告可为有目标的内容消息的实例。m-tcm-ps-移动有目标内容消息处理系统mas-移动广告系统,其可被视为m-tcm-ps的一种形式。upg-用户简档产生代理m-tcm-具有移动tcm功能的客户端maec-具有移动广告功能的客户端。此客户端可为具有移动tcm功能的客户端的实例。移动tcm提供者(m-tcm-p)-可能想要通过有目标内容消息处理系统显示有目标的内容消息的人或实体。广告商-可能想要通过移动广告系统(mas)显示广告的人或实体。广告商可提供广告数据连同相应的目标对准和重放规则,其在一些例子中可形成到达mas的广告元数据。广告商是移动tcm提供者的实例。tcm元数据-用于识别可用于提供关于相应的有目标的内容消息(tcm)的额外信息的数据的术语。广告元数据-用于识别可用于提供关于相应广告的额外信息的数据的术语。此广告元数据可包含(但不限于)多用途因特网邮件扩展(mime)类型、广告持续时间、广告观看开始时间、广告观看结束时间等。广告商提供的相应的广告目标对准和重放规则也可作为广告的元数据附加到广告。广告元数据是tcm元数据的实例。应用程序开发者-开发用于可播放广告的具有移动广告功能的客户端(maec)的应用程序的人或实体。系统操作者-操作mas的人或实体。第三方推断规则提供者-可提供将由用户简档产生代理使用的用户简档推断规则的第三方(除系统操作者以外)。用户简档产生代理-客户端处可接收各种相关数据(例如,广告推断规则、来自度量收集代理的用户行为、来自gps的位置数据、用户输入的明确用户偏好(如果存在的话),和/或来自其它客户端应用程序的用户行为),接着产生各种用户简档元素的功能单元。用户简档产生代理可基于可用于表征用户行为的所搜集的信息来持续地更新简档。用户行为合成器-用户简档产生代理内的可用于接收多种数据(例如,用户行为信息、位置信息和用户简档推断规则)以产生合成的简档属性的功能装置或代理。简档元素细化器-用户简档产生代理内的可接收用户行为合成器所产生的简档属性以及若干用户简档推断规则的功能装置或代理。简档元素细化器可细化简档属性,通过发送到简档属性处理器的询问来处理所述简档属性,并产生用户简档元素。简档属性处理器-可处理可能要求数据密集型查找的简档属性请求且接着以经细化的简档属性做出响应的服务器和/或服务器的常驻代理。tcm过滤代理-可接收具有其相应元数据、tcm目标对准规则和tcm过滤规则的若干tcm,接着将所述tcm中的一些或全部存储在tcm高速缓存存储器中的客户端代理。过滤代理还可将用户简档视为来自用户简档产生代理的输入。广告过滤代理-可接收具有其相应元数据、广告目标对准规则和广告过滤规则的若干广告,接着将接收到的广告中的一些或全部存储在广告高速缓存存储器中的客户端代理。过滤代理也可将用户简档视为来自用户简档产生代理的输入。广告过滤代理是tcm过滤代理的实例。tcm高速缓冲存储器管理器-可维护有目标内容消息高速缓冲存储器的客户端代理。高速缓冲存储器管理器可从过滤代理取得经高速缓存的有目标的内容消息,且响应来自接入终端上的其它应用程序的内容消息请求。注意,对于本发明,术语“高速缓冲存储器”可指代一组非常广泛的存储器配置,包含单个存储装置、一组分布式存储装置(本地和/或非本地)等等。一般来说,应了解,术语“高速缓冲存储器”可指代可用于加速信息显示、处理或数据传送的任何存储器。广告高速缓冲存储器管理器-可维护广告高速缓冲存储器的客户端代理。高速缓冲存储器管理器可从过滤代理取得经高速缓存的广告,且响应来自接入终端上的其它应用程序的广告请求。广告高速缓冲存储器管理器是tcm高速缓冲存储器管理器的实例。用户简档属性-可由用户行为合成器合成以形成简档属性的用户行为、兴趣、人口统计信息等等,其可被视为可由简档元素细化器进一步处理和细化成较精细的用户简档元素的数据的中间预合成形式。用户简档元素-用于维护用户简档的信息的项目,其可包含可用于分类或界定用户的兴趣、行为、人口统计等的各种类型的数据。tcm目标对准规则-这些规则可包含与由移动tcm提供者指定的有目标的内容消息的呈现有关的规则。广告目标对准规则-这些规则可包含由广告商指定以对可如何显示广告强加规则/限制的规则,和/或使广告目标对准特定用户段的规则。广告目标对准规则可特定针对若干标准,例如广告活动或广告群组。广告目标对准规则是tcm目标对准规则的实例。tcm重放规则-这些规则可包含由客户端应用程序在询问tcm高速缓冲存储器管理器以获得将在其应用程序的上下文中显示的tcm时指定的显示规则。广告重放规则-这些规则可包含由客户端应用程序在询问广告高速缓冲存储器管理器以获得将在其应用程序的上下文中显示的广告时指定的显示规则。广告重放规则是tcm重放规则的实例。tcm过滤规则-这些规则可包含可过滤tcm所依据的规则。通常,系统操作者可指定这些规则。广告过滤规则-这些规则可包含可过滤广告所依据的规则。通常,系统操作者可指定这些规则。广告过滤规则是tcm过滤规则的实例。用户简档元素推断规则-这些规则可包含由系统操作者(和/或第三方)指定的可用于确定可用于根据人口统计和行为数据建立用户简档的一个或一个以上过程的规则。tcm伸缩-可借以响应于用户请求将额外呈现材料呈现给用户的针对tcm的显示或呈现功能。广告伸缩-可借以响应于用户请求将额外呈现材料呈现给用户的广告显示或呈现功能。广告伸缩是tcm伸缩的实例。如上文所提及,关于电信和隐私权的各种规章可使具有有目标的内容的消息的递送较困难。然而,本发明可提供多种解决方案以在注意隐私权问题的同时将有目标的内容递送到无线接入终端(w-at),例如蜂窝式电话。本发明的用于缓和隐私权问题的许多方法中的一者包含将多种过程卸载到用户的w-at上,所述w-at又可用于产生可能表征用户的信息集,即其可在w-at本身上创建用户的“用户简档”。因此,例如广告和其它媒体等有目标的内容消息可基于用户的简档而导向用户的w-at,而不向外界暴露潜在的敏感性客户信息。移动tcm处理系统(m-tcm-ps)中(且明确地说,移动广告系统(mas)中)可使用各种所揭示的方法和系统,对于本发明,所述移动tcm处理系统可包含可用于将有目标的内容消息(或明确地说,广告)递送到具有tcm功能的w-at(或明确地说,具有移动广告功能的w-at)的端对端通信系统。m-tcm-ps还可提供能够报告特定广告活动的执行情况的分析界面。因此,适当构造的m-tcm-ps可通过仅呈现可能为消费者所感兴趣的非侵入广告来提供较好的消费者体验。虽然以下实例大体针对例如商业广告等内容,但预期所针对内容的较广范围。举例来说,代替于所针对的广告,例如特定针对用户的兴趣的股票报告、天气报告、宗教信息、新闻和体育信息等等内容预期在本发明的界限内。举例来说,虽然所针对的内容可以是广告,但体育赛事的得分和天气报告可无疑也作为所针对的内容。因此,例如广告服务器等装置可被视为较一般的内容服务器,且广告相关代理和装置可较一般地被视为内容相关代理和服务器。在广告的上下文中提供所有进一步论述作为tcm(有目标的内容消息)的实例,且应注意,此类论述大体适用于有目标的内容消息。图1是m-tcm-ps的各种功能元件中的一些元件的图,其展示具有tcm功能的w-at100与具有广告基础结构的通信网络之间的交互。如图1所示,示范性m-tcm-ps包含具有tcm功能的移动客户端/w-at100、具有无线电功能的网络(ran)190,以及内嵌在与无线wan基础结构(图1未图示)相关联的网络中的广告基础结构150。举例来说,消息接发基础结构可在与无线wan中的蜂窝式基站在地理上不位于同一地点的远程服务器处可用。如图1所示,w-at可包含客户端应用程序装置110、客户端消息递送接口112、度量收集代理120、消息高速缓存管理器122、消息过滤代理124、度量报告代理126、消息接收代理120和数据服务层装置130。消息递送基础结构150可包含tcm销售代理160、分析学代理162、消息递送服务器接口164、消息吸收代理170、消息捆绑代理174、消息分布代理176、度量数据库172、度量收集代理178,且具有代理服务器182。在操作中,m-tcm-ps的“客户端侧”可由w-at100(描绘于图1的左手侧)处置。除与w-at相关联的传统应用程序外,当前w-at100还可具有处于应用程序等级110的tcm相关应用程序,所述应用程序等级110又可经由客户端广告接口112链接到m-tcm-ps的其余部分。在各种实施例中,客户端消息递送接口112可提供度量/数据收集和管理。一些所收集的度量/数据可在不暴露可个别识别的客户信息的情况下传送到度量报告代理126和/或传送到w-at的数据服务层130(经由度量收集代理120),以供进一步分布到m-tcm-ps的其余部分。所传送的度量/数据可经由ran190提供给消息递送基础结构150(描绘于图1的右手侧),针对当前实例,所述消息递送基础结构150包含多种tcm相关和隐私权保护服务器。消息递送基础结构150可在数据服务层180处接收度量/数据,所述数据服务层180又可将接收到的度量/数据传送到若干度量/数据收集服务器(此处为度量收集代理178)和/或软件模块。度量/数据可存储在度量数据库172中,并提供给消息递送服务器接口164,在该处所存储的度量/数据可用于营销目的,例如广告、销售和分析学。注意,感兴趣的信息可(尤其)包含w-at处的用户选择和由w-at响应于消息递送基础结构150所提供的指令而执行的对广告的请求。消息递送服务器接口164可提供用于供应广告(广告吸收)、捆绑广告、确定广告的分布和经由消息递送基础结构150的数据服务层180将广告发送到m-tcm-ps网络的其余部分的渠道。消息递送基础结构150可向w-at100提供适当的tcm以及tcm的元数据。消息递送基础结构150可指令w-at100根据消息基础结构150所提供的规则基于任何可用元数据来选择tcm。如上文所提及,示范性w-at100可经启用以整体或部分地产生w-at的用户的用户简档,所述用户简档又可用于启用m-tcm-ps以递送用户可能感兴趣的tcm。这可导致各种广告活动和其它tcm递送活动的较好的“点进率”。然而,如上文所提及,产生用户简档可能因可驻存在用户简档中的数据的潜在敏感性质而引起隐私权问题。然而,如下文在各种装置和系统实施例中将展示,可通过启用用户的w-at以产生用户简档而随后将用户简档限于用户的w-at的范围内(非常有限(且受控)情形中除外)来缓和隐私权问题。图2是展示经配置以产生和使用用户简档的图1的示范性w-at的操作细节的框图。如图2所示,示范性w-at包含能够处理若干应用程序的处理系统,所述应用程序包含若干核心客户端应用程序和一客户端消息递送接口。注意,例如消息接收代理128和数据服务层130等一些组件为了与图2有关的功能的阐释的简单性而从图2中省略。图2的示范性w-at100被展示为具有客户端消息递送接口112与客户端应用程序装置110之间的平台特有调适接口111,且消息过滤代理124具有用户简档产生代理210和响应用户简档产生代理210的客户端消息过滤代理220。高速缓存存储器240被展示为与高速缓冲存储器管理器122通信。外部装置(例如,简档属性处理器270、系统操作者(或第3方)280和消息销售接口164)被展示为与客户端消息过滤代理124通信。装置270、280和164一般来说不是w-at的一部分,而是可能驻存在m-tcm-ps网络的另一部分中。虽然将w-at100的各个组件110到240描绘为单独的功能块,但应了解,这些功能块中的每一者可采取多种形式,包含单独件的专用逻辑、运行单独件的软件/固件的单独处理器、驻存在存储器中且由单个处理器操作的软件/固件的集合等等。在操作中,客户端应用程序装置110可执行可用于电信(例如,呼叫和文本消息接发)或其它任务(例如,游戏)的任何数目的功能应用程序,其使用平台特有调适接口111来与客户端消息递送接口112介接。客户端消息递送接口112又可用于允许w-at100执行若干有用过程,例如监视用户行为和将用户相关信息传递到用户简档产生代理210。除了直接从客户端应用程序接口接收信息外,用户简档产生代理210还可从度量收集代理120产生用户行为信息,所述度量收集代理120本身可从客户端消息递送接口112接收相同或不同信息。用户行为的实例可包含tcm相关响应,例如广告点击以及指示类型和使用频率的其它度量。其它用户行为信息可包含直接用户偏好或授权。度量收集代理120可将度量/数据提供给度量报告代理126,所述度量报告代理126又可将度量/数据信息提供给可m-tcm-ps的在w-at内部或外部的其它组件(下文论述)。简档属性处理器270可处理来自w-at100的要求(或可另外受益于)数据密集型查找的传入的简档属性处理请求,并以经细化的简档属性向用户简档产生代理210做出响应。用户简档产生代理210的一个功能可包含提供可根据相关过滤规则提供给w-at的用户的tcm,以及来自销售接口164的tcm数据和tcm元数据。过滤代理220还可将经过滤的消息提供给高速缓冲存储器管理器122,所述高速缓冲存储器管理器122又可存储并稍后提供此类消息(经由高速缓存存储器240)以呈现给用户。用户简档产生代理可以是驻存在具有移动广告功能的w-at中的硬件和/或软件的任意集合,其可用于收集用户行为信息。潜在的信息源可包含(但不限于)驻存在用户的w-at上的应用程序、各种可存取数据库中可用的公开信息、对于广告的先前用户响应、来自常驻gps无线电设备的位置数据,以及用户输入的明确用户偏好(如果存在的话)。所搜集的任何用户简档信息可接着经处理/合成以产生用户简档属性或元素,所述用户简档属性或元素可在使用较少存储器资源的情况下较好地表征用户。在各种实施例中,由系统操作者(和/或第三方)提供的用户简档推断规则可驱动w-at的用户简档产生代理的特定动作。注意,这些规则可为若干类型,包含:(1)基本规则,其包含将由用户简档产生代理依据与每一动作相关联的预定时间表执行的动作;以及(2)限定规则,其包含由“条件”限定的“动作”,其中“条件”可界定需要为真的行为,且“动作”可界定当检测到所述条件为真时用户简档产生代理的规则引擎所采取的动作。此类规则可用于从特定用户动作或行为推断出信息。举例来说,针对用户简档产生代理的简单规则可能是每隔五分钟存储gps针对用户的w-at而导出的位置信息。相关联规则可以是将一天中09:00到17:00时间范围内最常去的位置标记为用户的可能工作位置。作为第二实例,由条件限定的规则可能是如果用户经常一天将30分钟以上花在其w-at上的游戏应用程序中那么将“游戏”类别添加到用户的兴趣列表。还注意,用户简档产生代理还可将用户偏好视为输入,所述用户偏好包含关于用户对于使用位置数据导出简档的明确授权、用户作出的其它授权以及用户所输入的其它特定信息的用户选择。举例来说,用户可能输入其偏好以观看与旅行有关的广告。用户的w-at中并入的可用于搜集并细化/分类行为数据的各种受规则驱策的方法可缓和用户可能具有的一些隐私权问题。举例来说,通过采集数据并将原始数据合成为w-at内较有意义/有用的形式(与使用外部服务器相对比),可形成敏感或个人信息且稍后用于有目标的广告,而不将此信息暴露于w-at的通信网络的其余部分。在各种实施例中,用户简档的特定方面可控制用户的w-at的若干部分。举例来说,用户简档产生代理可利用任何检索到的w-at信息来以最适合于w-at的方式修整信息内容,包含菜单布局的选择(例如,线性、分级、动画、弹出和自定义功能键)。如上文所提及,虽然大多数简档产生规则可被w-at的内嵌式用户简档产生代理解译,但可能存在一些要求大数据库查找(例如,政府人口普查数据)的规则。由于w-at上的存储器可能太有限而不能容纳大数据库,所以可能通过将适当的细化任务卸载到m-tcm-ps网络的w-ap侧的经特殊配置的服务器来进一步细化已合成的用户行为和人口统计数据。对于本发明,能够辅助用户简档产生的任何此类外部服务器均可称为“简档属性处理器”。下文参看图4提供简档属性处理器的额外论述。图3是在与其它装置312和280交互的情况下展示的先前呈现的用户简档产生代理210的示意性框图。下文部分地提供用户简档产生代理210的各种能力(除上文论述的那些能力之外)。移动电话的特征之一是其可由用户携带,不管他/她去哪里。利用w-at的gps能力,w-at可确定用户周期性地或非周期性地将他/她的一些或大部分时间花在什么地方。因为经常存在与位置相关联的人口统计数据,所以与用户常去的位置相关联的gps信息和人口统计数据的使用可允许形成与用户相关联的人口统计简档的至少一些部分。与使用位置信息的用户的简档相关联的典型的人口统计简档元素可包含(但不限于):位置邮政编码性别针对常去位置的中位数年龄年龄分布和相关联概率去上班的平均行程时间家庭收入或家庭收入范围家庭规模家族收入或家族收入范围家族规模婚姻状况拥有住房的概率租用住房的概率生命阶段群组/分类注意,多个人口统计用户简档可保存在用户的w-at处。举例来说,具有m-tcm功能的客户端可能由网络配置以为用户保存两个人口统计简档—一个简档用于其“住宅”位置(比如21:00到06:00之间最常去的位置),且一个简档用于其“工作”位置(比如09:00到17:00之间最常去的位置)。除一般人口统计外,还可使用w-at的众多应用程序中的任一者来进一步形成用户简档。用户倾向于将其大部分时间花在哪些应用程序(例如,游戏)上或者用户如何与电话上的各种应用程序交互可提供基于用户的行为和偏好为用户建立简档的机会。这种数据采集和用户行为简档确定的大部分可在w-at本身上完成,其由馈送到用户简档产生代理210的用户简档推断规则驱动。与用户相关联的典型的行为简档元素可包含(但不限于)以下各项:应用程序id和花在应用程序上的时间兴趣分类最喜欢的关键词最喜欢的网站感兴趣的广告音乐专辑感兴趣的游戏许多简档元素(包含人口统计)可经由w-at上的本地用户接口应用程序根据通过添加异常分支以观察应用程序行为而采集的行为进行推断。正是通过此些应用程序,用户可启动其它应用程序。用户感兴趣的应用程序和花在这些应用程序上的时间可通过监视用户何时启动和退出特定应用程序来推断。馈送到用户简档产生代理210的规则可基于用户与应用程序的交互而将用户的感兴趣类别相关联。还可使用对w-at处收集到的行为数据的服务器辅助的合作过滤将感兴趣类别指派给用户简档。可下载到用户简档产生代理210的规则可允许服务器以动态方式控制用户简档产生代理210的运作。通过在在职w-at上采集原始数据并将其合成为较有意义的信息(简档属性),与将数据维持为原始形式比较,可将特定的敏感性用户行为信息变换为广告行为类别和用户简档元素。示范性w-at可跟踪用户感兴趣的消息和与此些消息相关联的关键词。举例来说,对同一广告的多次点击可向用户简档代理指示与相关联的关键词和广告相关联的兴趣等级。以同样的方针,可将用户感兴趣的游戏和音乐保存在w-at处。还可使用服务器辅助的模式以基于用户的音乐和游戏播放列表将用户兴趣类别与用户的简档相关联。当形成和保存用户简档时,此简档可采取多种形式,例如合成的简档属性和元素。注意,用户简档中的一些或所有数据属性和元素可具有与其相关联的某一置信等级。即,因为某些元素和属性是基于推断和规则的,所以其结果可能不是确定的且具有与其相关联的“模糊性”。此模糊性可表达为与用户简档属性和元素相关联的置信等级。作为实例,在注意到用户正每月发送五百条以上sms消息的情况下,简档产生器可能假定用户可能以60%的置信等级处于从15到24的年龄群组中。这意味着如果每月发送五百条以上sms消息的100个用户被轮询其年龄,那么其中约60个可能属于15到24的年龄群组。类似地,当基于用户的住宅位置为他/她推断人口统计简档时,可存在与简档属性相关联的置信等级。此处的置信等级可指示在具有相同住宅位置的一百个用户的样本中简档属性预期为准确的次数。示范性用户简档产生代理210还可被馈送用以组合关于来自多个来源的相同简档属性的置信等级以产生针对所述属性的统一置信等级的规则。举例来说,如果sms使用率指示用户以60%置信等级处于15到24岁的年龄群组内,且住宅位置的人口统计简档指示用户以20%置信等级处于15到24岁的年龄群组内,那么这两个项目可以模糊逻辑规则组合,以为处于同一年龄群组中的用户产生统一置信等级。相比之下,如果用户将其兴趣偏好输入到客户端中,那么此类值可能被给予接近100%的置信等级,因为其直接来自用户。类似地,如果运营商基于其所具有的用户数据(在服务签约期间从用户收集的记帐数据或任选的简档数据)指定任何用户简档属性/元素,那么其也将具有与其相关联的较高置信等级。随着在w-at上收集到更多用户行为数据且基于此做出推断,所以简档属性和元素值中的后续置信等级预期将增加。图4是简档属性处理器270处置w-at对简档属性处理的请求的示意性框图。如上文所论述,虽然w-at可能够处置大部分处理,但可能存在需要巨大数据库查找以确定行为或人口统计简档的多个部分的情况。此类情况的实例包含要用到可能需要千兆字节存储的人口普查数据库的例子。因此,可使用简档属性处理器(或其它辅助服务器)来处理用户信息以提供用户简档信息的较精细形式。在请求被简档属性处理器270接收之前,可在相关w-at处搜集合成的简档属性,并将其发送到简档属性处理器270,注意合成简档属性的使用可导致带宽的较好使用。需要数据密集型查找的一些用户简档属性可由简档属性处理器270任选地通过匿名询问技术来处理以保护用户身份。简档属性处理器270可进一步细化任何所接收到的属性,且可以可称为经细化用户简档属性集的形式将经细化的数据提供给适当的w-at。当由来自w-at的请求激活时,简档属性处理器270可处理关于用户的行为和人口统计(例如,简档属性)的各种类型的专有和非专有合成数据,并用适当的经细化简档信息做出响应。为了维护用户隐私权,可经由例如图8的单向散列函数产生器810等装置使用某一形式的数据加扰(例如,散列函数和若干其它工具)。在操作中,有可能在w-at处使用散列函数来向m-tcm-ps网络的其余部分隐藏用户的身份。在各种操作中,w-at中所使用的散列函数可产生可预测且唯一但匿名的与特定用户相关联的值。此方法可使w-at能够在不损害用户的隐私权的情况下询问外部服务器。在各种实施例中,散列函数可基于w-at的初级识别符,例如与w-at相关联的序列号,以及随机值、伪随机值和基于时间的值。此外,散列函数可经计算以提供与其它所产生的值冲突的低概率。w-at可针对后续询问使用相同的随机数字以允许外部服务器关联来自同一客户端的多个询问。随机数字的使用可帮助防止外部服务器(或未经授权的代理)在订户基础上进行反向查找以确定用户的身份。一旦产生散列值,就可使用所述散列值作为w-at的替代用户识别符,并连同来自用户简档的地理信息或者一些信息或若干信息项一起提供,并提供给远程设备。随后,可基于到达远程设备的替代用户识别符和第一广告相关信息和/或能够对用户简档进行补充的其它信息,从远程设备接收一个或一个以上有目标的内容消息。此信息可并入到w-at的用户简档中。为了进一步维护用户隐私权,可使用无线接入点(w-ap)侧的代理服务器(例如,见图1)。图9描绘使用代理服务器在具有移动广告功能的网络中安全地通信的特定通信方案。如图9所示,w-at910(“具有m-tcm功能的客户端”)可将与若干服务(例如,对用户简档信息的细化)有关的请求(或其它消息,例如报告或回复)或对广告内容的请求发送到无线应用协议(wap)代理920。wap代理920又可将请求转发到安全代理服务器930,所述安全代理服务器930可接着创建事务id、改变标头以为了所述事务id而去除w-at的识别信息,并将请求转发到移动消息递送服务器940,同时创建含有可用于中继回复的信息(例如,w-atip地址)的查找表。一旦移动消息递送服务器940接收到并回复请求,代理服务器930就可使用适当的事务id来转发移动消息递送服务器的回复。稍后,代理服务器930可删除查找表条目。注意,可使用图9中所描绘的方案来禁止移动消息递送服务器940接入用户的w-atip地址,这又具有若干益处,例如允许在不危害用户身份的情况下递送有目标的内容(例如,有目标的广告)。为了减轻用户对其位置可能被其w-at实时跟踪的担心,此类w-at可选择不实时询问服务器以获得位置数据的细化。注意,此类询问可匿名且稀疏地在延长的时间周期(例如,一个月一次)内发送。典型的时间表可为(例如)在72小时内每隔5分钟收集位置信息。可使用在此时间范围期间或特定时间范围期间最常去的位置在30天与40天之间的随机选定时间或根据系统操作者指定的某一其它时间表从服务器询问用户的人口统计简档。以上情况是在维护用户隐私权的同时使用用户简档产生代理的受规则驱策的操作连同服务器辅助的模式两者来为用户产生简档元素的混合方法的实例。图5是展示以描绘使用具有用户行为合成器522和简档元素细化器524的用户简档产生代理210的此混合方法的示范性操作的示意性框图。虽然图5的各种装置的功能性的大部分已在上文论述,但下文将相对于以下流程图描述进一步功能性。图6是概述用于产生和使用用户简档的示范性操作的流程图。所述操作在步骤602中开始,此时w-at可从系统操作者或其它方接收(并随后存储)若干用户简档推断规则(基本和/或限定规则)。如上文所论述,基本规则可包含预先安排的事件,例如在特定时间执行用户的询问。类似地,相应的限定规则可能要求同一询问之前是某一条件和/或事件,例如物理状态信息或操作状态信息。接下来,在步骤604中,可使用接收到的规则来收集原始数据,且在步骤606中,可将原始数据处理/合成为用户简档元素或属性,注意虽然所有此类处理/合成可在w-at上发生,但某一细化可使用外部装置(例如,上文论述的简档属性处理器)而发生。即,如上文所论述,原始数据和/或合成数据可合并以形成w-at的用户的用户简档。举例来说,关于监视sms消息的规则在应用于收集原始数据并合成关于sms消息的简档属性/元素时可用于改变用户简档的动态特性。例如用户的出生日期等静态数据可同样使用询问用户的规则来收集,且接着应用作为用户简档中的元素。接着,在步骤608中,可确定用户简档数据的置信等级。注意,置信等级可具有多种形式,例如某一范围的数字、方差统计量或分布概图。在步骤610中,可使用各种所接收到的规则加上关于各种用户简档元素和属性(其可形成用户简档的全部)的原始数据和合成数据来接收tcm。即,如上文所论述,在各种实施例中,w-at上的已使用/可使用的规则可用于连同收集到的原始数据和合成数据一起产生用户简档,以提供用户简档的任何数目的静态或动态特性,且此类信息可用于接收例如针对可能感兴趣的主题的广告、体育得分、天气报告和新闻等内容。注意,在其中用户简档数据可具有与其相关联的置信等级的各种实施例中,规则可应用于所述置信等级,且可基于此置信信息来接收和显示有目标的内容消息。继续,操作的控制可跳回到步骤602,其中可接收新的/更多规则,并使用其来收集数据且修改用户的简档。注意,如上文所提到,可基于w-at的物理配置而使用多个规则,以便利用w-at信息来以适合w-at的方式修整内容显示以创建适宜的显示,例如具有线性、分级、动画、弹出和/或自定义功能键属性的菜单布局。图7是概述用于产生和使用用户简档的另一示范性操作的流程图。所述操作在步骤702中开始,此时w-at从系统操作者或其它方接收若干用户简档推断规则。接下来,在步骤704中,可使用所接收到的规则来收集原始数据,且在步骤706中,可使用机载资源将原始数据处理/合成为用户简档元素或属性。再次注意,用户简档信息的任何项目可具有连同基本数据一起经处理并合成的置信等级信息。继续到步骤710,可作出关于是否需要在w-at上可能不可行的进一步信息或处理的确定。举例来说,假定w-at已产生w-at已使用gps定期访问的一系列位置,w-at上使用一个或一个以上规则的软件代理可确定需要询问较大外部数据库(例如,远程服务器上的地理信息服务或国家人口普查数据库),以确定用户的可能种族性(或其它人口统计)。如果需要进一步信息或处理,那么控制继续到步骤712;否则,操作的控制可跳到步骤720,其中使用简档属性来产生/修改用户的简档。对于需要进一步信息或处理的例子,可(例如)由上文论述的简档属性处理器(任选地使用散列函数和/或代理服务器)对外部装置作出请求(步骤712)以保护用户信息。接下来,在步骤714中,外部装置可执行任何数目的细化步骤,例如询问大数据库,以产生经细化的用户简档属性。接着,在步骤718中,可接着将经细化的用户简档属性提供给适当的w-at,其中(在步骤720中)所述经细化的用户简档属性可用于产生、修改用户简档或以其它方式并入用户简档中。注意,当置信等级可用于处理时,可基于个别置信等级来确定统一置信等级。操作的控制可接着跳回到步骤702,其中可接收新的/更多规则并使用其来收集数据且修改用户的简档。向前跳到图11,描绘具有m-tcm功能的网络中的tcm分布的第一通信协议。此示范性图式说明在来自消息分布基础结构的消息的多播“推送”期间的可能的数据流。注意,用户简档产生代理(在图10的移动装置(w-at)100中)可检索消息,接着通过内部过滤来选择所接收到的所述消息中的一者或一者以上。在操作中,网络系统操作者280(和/或第三方)可将简档属性处理规则提供给简档属性处理器270。简档属性处理器270还可接收来自w-at100上的模块的简档属性处理请求,并经由w-at100上的模块提供适当响应。另外,多播或广播广告可由w-at100通过多播/广播分布服务器1110接收。在此配置中,w-at100(或其它移动装置)可能够接收所有消息,并根据w-at100处产生的用户简档以及也从图11的多播/广播分布服务器1110接收到的过滤规则来确定哪些消息将被存储并呈现给用户。图12描绘具有m-tcm功能的网络中的消息分布的第二通信协议。与图11的实例一样,网络系统操作者280(和/或第三方)可将简档属性处理规则提供给简档属性处理器270,且简档属性处理器270还可接收来自w-at100上的模块的简档属性处理请求,以经由w-at100上的模块提供适当响应。然而,在此实施例中,w-at100可从单播消息分布服务器1210请求单播消息。w-at100可能够经由单播通信链路接收所有消息,并根据w-at100处产生的用户简档以及也从单播消息分布服务器1210接收到的过滤规则来确定哪些消息将被存储并呈现给用户。图13描绘具有m-tcm功能的网络中的消息分布的另一通信协议。再次,与先前实例一样,网络系统操作者280(和/或第三方)可将简档属性处理规则提供给简档属性处理器270,且简档属性处理器270还可接收来自w-at100上的模块的简档属性处理请求,以经由w-at100上的模块提供适当响应。然而,在此实施例中,单播消息分布服务器1310可接收由w-at100提供的用户简档信息、处理接收到的用户简档信息,并接着将适当的tcm提供给w-at100。图14描绘具有m-tcm功能的网络中的消息分布的又一通信协议。此实例可相对于简档属性处理器操作侧与先前实例几乎相同地工作。然而,经由单播通信链路的消息检索实质上是不同的。在操作中,w-at100可发送对消息的请求,之后w-at100可接收代表消息分布服务器1410中可用的各种消息的元数据集。w-at100可接着基于所述元数据并基于w-at100内的过滤规则选择若干消息,并将选择信息提供给消息分布服务器1410。因此,可接着根据用户简档规则将选定消息提供给w-at100并呈现给用户。以上方法保持用户简档在w-at本地,同时在经由单播通信链路将广告递送到w-at时使用最佳网络带宽。图15描绘用于根据“联系窗”(见示范性窗1510到1516)方法下载消息内容的第一通信协议的时间线。此时间线可用于准许在适当的时间下载tcm,而不对w-at的其它功能造成负担。在各种实施例中,w-at可能够将其休眠模式(如果涉及的话)调整到联系窗。在操作中,w-at可在内容消息递送期间被置于休眠模式中以优化平台上的能量消耗。有可能在休眠模式中,w-at可参与其它有用操作。即,w-at可能够被置于休眠模式中,同时各种定时电路(未图示)可经编程或以其它方式操纵而通过在联系窗之前和/或期间解除休眠模式且可能在接收tcm之后或在相对联系窗结束时重新进入休眠模式来响应休眠模式和联系窗或其它时间表。图16描绘用于根据所定义的时间表来下载有目标的内容消息信息的第一通信协议的替代时间线。参看示范性窗1610到1620,此方法可用于准许在适当的时间下载tcm,而不对w-at的其它功能造成负担。所定义的时间表准许w-at除所定义的时间表期间以外均保持在休眠模式中。再次,可使用各种定时/时钟电路来使w-at进入休眠模式/解除休眠模式。另外,有可能当w-at醒来以接收tcm信息时,w-at可接收将来tcm的目标对准元数据和接收时间,所述接收时间可接着用于基于用户简档和目标对准元数据来确定是否接收将来tcm,以及在接收将来tcm递送的接收时间之前安排适当的唤醒时间。图17说明基于示范性信息流1702、1722和1732的高速缓冲存储器建模方案中的一些方案。如图17所示,高速缓冲存储器建模方案是基于各种所列举的分类。注意,消息高速缓冲存储器可以是具有m-tcm功能的客户端处的消息的存储库。消息可在本地高速缓存以在有机会服务tcm时启用消息的即时播出。高速缓冲存储器中的实际存储空间可基于不同类型的分类划分为多个类别。这些分类可由系统操作者使用过滤规则来界定。分配给一分类内的每一类别的空间量可为固定的或可基于某些已定义准则而为动态的,其再次由系统操作者经由过滤规则来界定。感兴趣的一些类别包含:默认消息(1710、1720和1730):这些消息可被视为可由系统操作者标记成这样的“后退”消息。所述消息在没有满足装置应用程序所请求的消息类型的其它消息可供显示时展示。默认消息可以是高速缓冲存储器的候选消息,只要存在至少一个向相应的客户端消息递送引擎预订的能够进行消息递送的应用程序即可,其具有与候选默认消息相同的消息类型。另外,可使默认消息满足装置和应用程序能力一致性的最小选通准则。基于为默认消息计算的值,先前存储的默认消息可被新消息代替,只要在相同消息类型下新消息的“规范化”值大于先前存储的默认消息的值即可。客户端上针对每一消息类型而允许的默认消息的最大数目可由系统操作者经由过滤规则来界定。在各种实施例中,可存在固定数目的消息或消息存储器,或者可基于特定的具有消息功能的应用程序、使用率等来动态地确定消息数目和/或存储器。通常,在若干实施例中,针对每一消息类型所允许的默认消息的最大数目为1。标记为默认消息的消息主要用于两个目的:(1)所述消息充当每一类别中的“后退”消息,且帮助系统利用每次机会将消息呈现给用户;以及(2)所述消息允许系统操作者提供“分层定价”,且(任选地)针对默认消息收费较多。有目标的消息(1712、1722、1724和1738)和无目标的消息(1714、1726和1740):一个分类方案将是将高速缓存存储装置划分为用于有目标的和无目标的消息的空间。有目标消息高速缓冲存储器空间可用于仅存储具有m-tcm功能的客户端的用户的用户简档与相关元数据中所含有的目标用户简档匹配所针对的消息。对于其中目标用户简档不与装置用户的简档匹配的消息,只要所述消息不标记为“仅有目标的显示”,此类消息就可为待放置在无目标的消息高速缓冲存储器空间中的候选消息。具有供显示的无目标的消息可允许系统随时间计量用户兴趣的变化,且相应地修改相应的用户简档和高速缓冲存储器。基于印象的消息(1722)和基于动作的消息(1724):另一分类将是基于消息是tcm递送活动的印象类型还是所述消息是恳求计量用户兴趣的用户动作的消息来划分高速缓冲存储器空间的有目标的或无目标的部分。此子分类的分区大小或比率可由系统操作者界定,或可根据相应w-at上能够进行消息递送的应用程序的能力和使用率动态地决定。基于用户兴趣的分类(1732-1736):有目标的消息分类下的子分类可基于用户兴趣分类。举例来说,高速缓冲存储器的有目标的消息分段内的特定高速缓冲存储器空间的大部分可为前三个用户兴趣类别保留,而任何剩余高速缓冲存储器资源可专用于与用户的简档匹配的其它类别。再次,此分类内的基于兴趣的类别的实际比率或数目可由系统操作者界定,且/或可基于每一兴趣类别内的广告(或其它消息)的相对点进率而为动态的。图18是消息过滤过程的来龙去脉的说明。移动有目标内容消息递送系统内的消息过滤过程的一个目的可为决定进入系统的任何可用新消息中的哪一者应高速缓存在特定移动客户端处。在操作中,过滤过程1810可使用若干输入,例如保存在系统内的用户的用户简档、移动客户端上的装置和应用程序能力、移动客户端上的当前高速缓冲存储器状态以及由系统操作者或某些第3方280界定的过滤规则,来确定哪些新消息将高速缓存。在处理每一所接收到的消息后,可确定若干选定消息,并将其连同相应元数据一起存储在高速缓冲存储器1820中。图19是在各种示范性功能组件的上下文中tcm递送系统内的tcm过滤过程的数据流图。如图19所示,消息过滤可以是多步骤过程。从销售接口164进入过滤代理220的新消息可首先通过选通子过程220-1,所述选通子过程220-1可确定哪些所接收到的消息是消息高速缓冲存储器的可能的候选消息。注意,示范性选通子过程220-1可使用来自与移动客户端相关联的适当存储装置1910的装置和能力信息,以及系统操作者或某些第3方280的过滤规则和来自适当的代理210或存储装置的用户简档信息。继续,选通子过程220-1的可能的候选消息可接着由选择子过程220-2处理,所述选择子过程220-2可确定在消息空间争用的情况下哪些候选消息可被替代。注意,选择子过程220-2可使用系统操作者或某些第3方280的过滤规则、来自适当的代理210或存储装置的用户简档信息,以及来自高速缓冲存储器管理器122的反馈高速缓冲存储器信息。图20展示图19的选通过程内的示范性数据流。此过程的一个目的是确保例如有目标的广告等有目标的内容消息在其被转发到选择过程之前满足某些要求。本过程在步骤2002中开始,其中可从销售接口164或其它装置提供消息和相应的元数据。接下来,在步骤2004中,作出关于步骤2002的消息是否在移动客户端的能力内的确定。即,消息应使得其可由移动装置的有形工厂支持。举例来说,如果消息仅适合于次级装置屏幕,但讨论中的移动装置不具有次级装置屏幕,那么所述消息是不适宜的。倘若所述消息与装置能力匹配,那么控制继续到步骤2006;否则,控制跳到步骤2020,其中拒绝使用所述消息。在步骤2006中,作出关于步骤2002的消息是否在移动客户端的应用程序能力内的确定。即,消息应使得其可由经注册以供移动装置使用的各种软件/固件支持。举例来说,如果消息包含15秒的视频,但装置应用程序中的任一者内不存在codec设施来展示此视频,那么所述消息是不适宜的。倘若所述消息与应用程序能力匹配,那么控制继续到步骤2008;否则,控制跳到步骤2020,其中拒绝使用所述消息。在步骤2008中,作出关于步骤2002的消息是否通过移动客户端的应用程序能力内的系统操作者指定的选通准则匹配的确定。举例来说,如果消息仅适合成人观众,那么此消息将可能最好针对被识别为未成年人的任何用户而过滤掉。倘若所述消息与指定系统操作者所指定的选通准则匹配,那么控制继续到步骤2010;否则,控制跳到步骤2020,其中拒绝使用所述消息。在步骤2010中,作出关于步骤2002的消息是否通过取样准则匹配的确定。举例来说,如果预计将特定广告提供给人口统计的仅30%,那么具有1到100的范围并种植有其自己的esn和服务器指定的种子的随机数产生器(rng)可在所得随机数小于30%的情况下限定所述广告。如果广告/消息通过取样准则,那么控制继续到步骤2030,其中可执行消息选择;否则,控制跳到步骤2020,其中拒绝使用所述消息。图21是描绘随机取样方案的流程图,所述随机取样方案是针对其中操作者可能想要将用户划分为相互排斥的多个集合并使不同消息目标对准到每一个集合的情形而呈现的。举例来说,操作者可能根据约定义务下而不向同一用户展示任何百事可乐广告和任何可口可乐广告。因此,操作者可能想要将百事可乐广告目标对准到订户基础的50%且将可口可乐广告目标对准到订户基础的剩余50%,从而确保不向同一用户展示两种广告。所述过程在步骤2102中开始,其中将随机数产生器种子和esn(电子序列号)提供给移动客户端/w-at。接下来,在步骤2104中,执行随机数产生过程以产生1与100之间或任何其它范围的数字之间的随机数。控制继续到步骤2110。在步骤2110中,作出关于步骤2104的随机数与所定义的范围(例如,1到100的总范围中的1到50或51到100)之间是否形成匹配的确定。如果形成匹配,那么控制跳到步骤2112,其中接受讨论中的消息,或者如果与上文的可口可乐/百事可乐实例一样存在竞争性广告,那么接受两个消息中的第一者;否则,控制跳到步骤2114,其中拒绝讨论中的消息,或者如果与上文的可口可乐/百事可乐实例一样存在竞争性广告,那么拒绝两个广告中的第一者,而接受第二广告。继续到图22,应了解,订户基础内的相互排斥的消息目标对准可对某一唯一id(例如,用户id或装置id)使用如同散列方案的单向函数来完成。在操作中,操作者可基于散列计算的结果来指定不同的目标用户段。可完成此取样以目标对准由其相应esn的散列值的范围界定的用户分段。所述过程在步骤2202中开始,其中将唯一id提供给移动客户端/w-at。接下来,在步骤2204中,可执行单向散列过程以产生任何范围的数字之间的值。控制继续到步骤2210。在步骤2210中,作出关于步骤2204的散列值与所定义的范围之间是否形成匹配的确定。如果形成匹配,那么控制跳到步骤2212,其中接受讨论中的消息,或者如果与上文的可口可乐/百事可乐实例一样存在竞争性广告,那么接受两个消息中的第一者;否则,控制跳到步骤2214,其中拒绝讨论中的消息,或者如果与上文的可口可乐/百事可乐实例一样存在竞争性广告,那么拒绝两个广告中的第一者,而接受第二广告。注意,当客户端的散列值不属于系统操作者所指定的取样范围内时,可拒绝所述消息;否则,消息处理可继续到下一选通准则或选择阶段。还注意,操作者还可能选择混合方法以通过在相互排斥的多个集合内随机地目标对准来针对特定广告/消息分布活动对用户进行取样。作为实例,特定广告活动可能被目标对准到订户基础的未获得第一广告的随机20%。这将通过首先使用基于单向函数的取样来产生相互排斥的集合且接着在相互排斥的集合内随机地目标对准来实现。继续,图23展示消息选择过程2300内的示范性数据流。所述选择过程的目的可为通过选通过程从转发到移动客户端/w-at的消息池选择消息,并将选定的消息存储在存储器(例如,特殊客户端广告/消息高速缓冲存储器)中。在消息空间争用的情况下,也可使用选择过程2300来从高速缓冲存储器选择需要被替代的先前高速缓存的消息。消息选择可在存在对高速缓冲存储器空间的争用,即高速缓冲存储器中没有足够的空间来容纳所有新消息和先前高速缓存的消息时开始起作用。消息选择可以是多步骤过程,且因为高速缓冲存储器可划分为不同类别(动态或静态地),所以争用和选择可在每一消息类别中发生。在操作中,消息选择器2310可从选通装置220或其它执行选通过程的仪器接收新消息,以及从系统操作者或第3方280接收若干消息过滤规则。消息选择器2310可接着将各种过滤规则应用于每一新消息,以确定每一新消息是否通过某些基本准则,例如新消息是否适合年龄或性别。倘若特定消息不符合过滤规则,那么其可被分类为被拒绝的新消息且被丢弃。在过滤规则下未丢弃的消息可由消息选择器2310进一步处理以针对每一所接收到的消息导出“目标用户简档”给匹配指示符计算器2320,所述匹配指示符计算器2320可接着将所述目标用户简档与用户简档产生代理210或存储关于用户的信息的某一其它装置所提供的用户简档进行比较。匹配指示符计算器2320又可执行每一目标用户简档与和用户或移动客户端/w-at相关联的用户简档之间的匹配,且将量化特定传入的/新的消息与用户简档兼容得有多好的匹配指示“得分”提供给消息选择器2310。如果匹配指示“得分”的等级足够好,那么可进一步考虑相应消息;否则,所述消息可变为被拒绝的新消息。由消息选择器2310进一步处理的消息可将匹配指示“得分”连同其它消息值属性(例如,消息大小、持续时间、存储器和显示器要求等等)提供给消息值计算器2330,所述消息值计算器2330又可将此类消息的“消息值”提供回消息选择器2310。继续,消息选择器2310可从高速缓冲存储器管理器122接收关于可用的高速缓冲存储器(或高速缓冲存储器的专用于特定消息类别的部分)的状态的信息,连同高速缓冲存储器命中/未中信息和高速缓冲存储器(或相关部分)中的每一消息的消息值。取决于特定消息的命中/未中信息,可任选地调整给定消息的消息值。消息选择器2310可接着基于相对消息值来确定新接收到的消息是否将替代高速缓冲存储器中的一个或一个以上现有消息,且任何新选择的消息可接着连同相应的消息id和相应的消息值一起发送到高速缓冲存储器管理器122,且可丢弃任何被替代的消息/拒绝在将来使用任何被替代的消息。图24a和图24b描绘概述在移动装置(例如,w-at)处接收到的一个或一个以上新消息的消息选择过程的流程图。示范性过程流程图展示在消息选择期间发生以确定将哪些新消息添加到高速缓冲存储器以及哪些先前高速缓存的消息将被替代/丢弃的高级动作流。所述过程在步骤2400中开始,其中针对第一新消息作出所述消息的大小是否小于或等于针对特定高速缓冲存储器且(任选地)针对特定消息类别(例如,电影预告片、棒球运动精彩场面、天气报告和服装销售)的某一最大消息大小的确定。如果新消息大小符合步骤2400的高速缓存存储器要求,那么控制跳到步骤2402;否则,控制继续到步骤2408。在步骤2402中,将新消息放置在高速缓存存储器中。接下来,在步骤2404中,计算新消息的消息值,且用新消息的消息值来更新高速缓冲存储器中的各种消息以及任选地高速缓冲存储器的消息类别的“优先权队列”。接着,在步骤2406中,基于新消息来更新可用高速缓冲存储器大小(再次具有对特定消息类别的任选更新)。注意,可使用此类消息值来维持高速缓冲存储器内的每一类别的优先权队列。周期性地(依据预定义的时间表),引擎可重新计算高速缓冲存储器中的各种消息值,并基于新的值重新调整优先权队列。此对基于值的优先权队列的周期性更新可导致当将新消息视为高速缓冲存储器替代候选消息时花费较少的时间,因为队列中的值是当前值将成为的值的良好近似。所述过程接着继续到步骤2430(下文论述)。在步骤2408中,计算新消息的消息值。接下来,在步骤2410中,作出关于新消息是否将为默认消息的确定。如果新消息将为默认消息,那么控制跳到步骤2412;否则,控制继续到步骤2420。在步骤2412中,作出关于新消息的值是否大于高速缓冲存储器中已有的相同类型的默认消息的值的确定。标记为默认消息且具有大于已存储的消息中的一者或一者以上的值的新消息可被给予优先权。可计算新消息迎合针对其不存在此类别的先前默认消息的新消息类型的情况的额外大小(如果其在大小上大于将被替代的消息,因为这些消息可容纳在高速缓冲存储器中。具有比新消息低的值的旧的默认消息可经标记以供替代。每一消息类型可通常具有固定数目(通常为1)的默认候选者。如果新消息值较大,那么控制跳到步骤2414;否则,控制继续到步骤2422。在步骤2414中,更新所有默认消息的总大小,且在步骤2424中,标记将被替代的现有经高速缓存的消息以供删除,同时标记新消息以添加到高速缓冲存储器。注意,基于高速缓冲存储器如何划分或分配给各种消息类别,可针对每一类别计算新的空间分配。控制继续到步骤2430。在步骤2422中,标记新消息以供删除,且控制继续到步骤2430。在步骤2420中,可将每一新的非默认消息的新消息值添加到各种消息类别的相应优先权队列,且控制继续到步骤2430。在步骤2430中,作出关于是否存在待考虑的更多消息候选者的确定。如果更多消息候选者可用,那么控制跳回到步骤2440,其中选择下一消息进行考虑,且接着返回直到步骤2400,其中使下一消息可用于处理;否则,控制继续到步骤2450。在步骤2450中,可基于总高速缓冲存储器大小与默认消息所占用的存储器的量之间的差来确定所有新的非默认消息的可用大小。接下来,在步骤2452中,可基于某一“类别比率”、参数等式或通过某些其它规则和/或等式集来计算用于每一类别的消息的可用存储器。控制继续到步骤2454。在步骤2454中,可针对每一消息类别标记具有最低相关联值的各种消息以供删除,以便符合针对每一相应消息类别的可用存储器。接下来,在步骤2456中,可从高速缓冲存储器去除经标记以供删除的那些消息,且其相应值条目也可从相应的优先权队列去除。接着,在步骤2458中,可请求经标记以供删除的那些新消息,且其相应值条目也可从相应的优先权队列去除。控制继续到步骤2460。在步骤2460中,可将未经标记以供删除的那些新消息添加到高速缓冲存储器,且其相应值条目可保留在相应的优先权队列中。控制继续到步骤2470,其中所述过程停止。关于确定消息值和消息值属性,可考虑以下内容:消息值属性:计算消息的值可基于消息的类型而考虑若干属性。虽然这些属性中的若干属性可由服务器界定以维持对消息递送方案(例如,广告活动)的集中控制,但在具有消息功能的通信系统上,进入消息值计算的属性中的一些属性可在移动客户端/w-at上基于相应用户如何与消息交互而确定。基于服务器的值属性:收入指示符(ri):指示根据消息/广告的服务/点击而赚得的收入的在1到n(例如,100)的范围内的值。较高的值指示较高的收入。优先权指示符(pi):指示系统操作者已基于移动消息递送系统上的某一性能量度(例如,广告商的广告活动的有效性)为消息安排的优先权等级的在1到m(例如,10)的范围内的值。此数字可由操作者增加以增加给定消息递送活动的优先权。消息递送活动的开始和结束时间(tstart和tend):消息递送活动观看开始时间和消息活动观看结束时间的utc时间。在消息活动观看结束时间之后,消息可期满,且可不再展示于移动消息递送系统内。所述消息还可在此时从相应的高速缓冲存储器去除。总体系统点进率(ctr):这是服务器包含的任选属性,其用以指示被供应了移动消息递送系统内的消息的具有目标用户简档的所有客户端上的消息活动的总体点进率。ctr可仅对基于用户动作或点击的消息/广告适用。ctr还可具有与其相关联的指示ctr的准确性的置信等级(ctrconfidence)。如果ctrconfidence低于某一阈值,那么可产生1到p(例如,100)的范围内的随机ctr,以替代地用于相应值计算中。这可允许系统测试特定新消息/广告活动将如何处置订户段。目标消息供应计数(maxserve):这是界定同一消息可向同一用户展示的最大次数的属性。目标用户动作计数(maxuseraction):这是界定用户对所供应的消息施加动作的最大次数的属性,在所述最大次数之后,所述消息可从相应的高速缓冲存储器期满。在各种实施例中,此属性可仅对基于用户动作或点击的消息/广告适用。每天最大消息供应计数(dailymaxserve):这是界定单天内同一消息可向同一用户展示的最大次数的属性。每天最大用户动作计数(dailymaxuser_action):这是界定该天内用户对所供应的消息施加动作的最大次数的属性,在所述最大次数之后,不将所述消息供应给用户。在各种实施例中,此属性可仅对基于用户动作或点击的消息/广告适用。基于客户端的值属性:累计消息供应计数(cumserve):现有消息已供应给特定用户的次数。累计用户动作计数(cumuser_action):现有消息已调用用户动作的次数。与累计消息供应计数一起,累计用户动作计数可用于计算消息的本地客户端点进率(lctr)。在各种实施例中,此属性可仅对基于用户动作或点击的消息/广告适用。每天累计消息供应计数(dailycumserve):在给定的一天中现有消息已供应给用户的次数。此值可在每一24小时周期开始时复位为0。每天累计用户动作计数(dailycumuser_action):在给定的一天中现有消息已调用用户动作的次数。此值可在每一24小时周期开始时复位为0。在各种实施例中,此属性可仅对基于用户动作或点击的广告适用。用户简档匹配指示符(mi):通常在1与100之间的此数字可指示目标用户简档可与具有移动消息分布功能的客户端的用户的用户简档匹配得有多好。高速缓冲存储器未中状态匹配指示符(flagcache_miss_mi):可存在应用程序从高速缓冲存储器管理器请求消息但高速缓冲存储器中的消息均不与应用程序选通准则匹配的情况。此类例子可被高速缓冲存储器管理器记录。此属性确定新消息是否与最近记录的高速缓冲存储器未中匹配。如果新消息与最近高速缓冲存储器未中中的一者匹配,那么此属性可为逻辑“1”,且否则为逻辑“0”。一旦所述消息由应用程序从高速缓冲存储器存取,就可使旗标复位。如果为高速缓冲存储器条目选择新消息,那么可从所记录的高速缓冲存储器未中列表中去除所述高速缓冲存储器未中条目。重放概率指示符(ppi):在0到p(例如,100)之间的此数字可指示基于应用程序向能够重放特定消息类型的过滤代理预订的数目、装置用户对应用程序的相对使用率等等的消息的重放概率。由于所述值属性中的一些值属性仅对某种消息适用,所以值计算对于不同类别的消息可不同。可基于使用针对每一类别的公式计算的值而针对所述特定类别维持单独的优先权队列。消息值计算公式:来自系统操作者的过滤规则可确定针对每一类别的值计算公式和进入计算的任何权数。用于计算每一类别中的消息值(v)的公式的示范性一般表示为:v=(∏a=1到mmult_attra*(∑b=1到nadd_attrb/max_add_attrb*wtb))/(∑b=1到nwtb*sizead)其中经规范化消息值为:经规范化v=∑i=k到nv*(maxservei-cumservei)*f(τ)其中mult_attra是第a个乘法值属性,add_attrb是第b个加法值属性,max_add_attrb是第b个加法值属性的最大值,wtb是公式中指派给第b个加法属性的权数,τ=telapsedi/tintervali,且f(τ)是基于时间的值衰减函数,tintervali是其间将展示消息的第i个间隔持续时间,telapsedi是在第i个间隔中已逝去的时间,maxservei是第i个间隔内同一消息可向同一用户展示的最大次数,且cumservei是第i个间隔内现有消息已供应给用户的次数。以下是针对不同类别的值计算公式的一些实例。基于印象的有目标消息的值计算:val=(pi/10*[(ri/100*wtri)+(mi/100*wtmi)+(flagcache_miss_mi*wtcache_miss_mi)+(ppi/100*wtppi)])/((wtri+wtmi+wtcache_miss_mi+wtppi)*sizemsg)基于印象的无目标消息的值计算:val=(pi/10*[(ri/100*wtri)+(flagcache_miss_mi*wtcache_miss_mi)+(ppi/100*wtppi)])/((wtri+wtcache_miss_mi+wtppi)*sizead)基于用户动作的有目标消息的值计算:val=(pi/10*[(ri/100*wtri)+(mi/100*wtmi)+(flagcache_miss_mi*wtcache_miss_mi)+(ppi/100*wtppi)+(ctr*wtctr)+(lctr*wtlctr)])/((wtri+wtmi+wtcache_miss_mi+wtctr+wtlctr+wtppi)*sizemsg)基于用户动作的无目标消息的值计算:val=(pi/10*[(ri/100*wtri)+(flagcache_miss_mi*wtcache_miss_mi)+(ppi/100*wtppi)+(ctr*wtctr)+(lctr*wtlctr)])/(wtri+wtcache_miss_mi+wtctr+wtlctr+wtppi)*sizemsg)其中ri是按1到100的标度的收入指示符值,pi是按1到10的标度的优先权指示符值,ctr是针对给定用户简档的系统内的消息的点进率,lctr是针对特定客户端的消息的点进率,mi是按1到100的标度的目标用户简档与用户的简档之间的匹配指示符,flagcache_miss_mi是具有值0或1的消息类型与高速缓冲存储器未中状态之间的匹配指示符,ppi是按1到100的标度的消息重放概率指示符,wtri是计算中的收入指示符的权数,wtmi是计算中的匹配指示符的权数,wtcache_miss_mi是计算中的高速缓冲存储器未中状态匹配旗标的权数,wtctr是计算中的用户简档特定系统点进率的权数,wtlctr是计算中的消息的客户端特定点进率的权数,且wtppi是值计算中的消息重放概率指示符的权数。针对f(τ)的实例:线性衰减:f(τ)=(1-τ)*u(1-τ)由线性衰减限制的较快指数衰减:f(τ)=(1-τ)e-λτ*u(1-τ),注意到当λ=0时发生线性衰减;当τ=0时,f(τ)=1;且当τ=1时,f(τ)=0。由线性衰减限制的较慢s形曲线衰减:注意到当λ=0时发生线性衰减;当τ=0时,f(τ)=1;且当τ=1时,f(τ)=0,且进一步注意到当x>0时,u(x)=1;且当x<=0时,u(x)=0。并且,λ和是由系统操作者基于时间而指定的值衰减率常数。消息匹配指示符计算:如上文简要暗示,用户简档匹配指示符(mi)可以是数字,且不必在0与100之间,其指示目标用户简档与具有移动消息递送功能的客户端的用户的用户简档以及其过去的消息/广告观看历史或其消息/广告偏好的某一度量匹配得有多好。尽管可将mi描述为标量数值量,但应了解,可例如根据设计偏好,使用多项式函数或向量设计出一个或一个以上替代“加权”方案。因此,可指派其它值(例如,标量或非标量,单一值或多值)而不脱离本发明的精神和范围。出于说明性目的,使用0与100之间的标度量来描述广告匹配指示计算的若干实施方案,因为这是可给出的最简单范围之一。可视需要使用其它范围。一个此类实施方案利用模糊逻辑,其可用于针对广告商指定的独立目标规则群组中的每一者产生置信等级值。依据这些置信等级,可使用这些置信等级的加权求和来获得广告与用户简档的匹配指示符值。以下非限定性等式可用作一种类型的模糊逻辑的实例,mi=(∑b=1到nconf_levelb*wtb)/∑b=1到nwtb)其中消息与用户简档的总体匹配指示符(mi)是与置信等级(conf_level)的和乘以对应于属性值(b)的权数(wt)再除以对应于第b个加法属性的权数(wt)的和有关。作为置信等级计算的实例,假设广告商希望将其广告向女性目标对准,目标对准到在15到24的年龄范围内且具有40k以上的收入或在25到34的年龄范围内且具有70k以上的收入的女性。已知感兴趣的用户简档元素的值,且假设相关联的置信等级为:用户简档元素值置信度女性50%年龄:15到2440%年龄:25到3435%收入:>40k65%收入:>70k45%规则群组的置信等级为:女性=50%对于年龄15到24且具有40k以上的收入或年龄25到34且具有70k以上的收入的复合规则群组,可使用最大值/最小值方法。举例来说,取两个分组的最小值的最大值(例如,max(min(40,65)、min(35,45))产生max(40,35),其是此分组的40%置信等级。整个规则群组的总体mi将是“女性”置信等级50%与复合置信等级40%的组合乘以相关联的wtb并除以相关联wtb的和。如上所述,可使用其它形式的模糊逻辑,而不脱离本发明的精神和范围。虽然这论证一种确定用户简档匹配指示符值的方法,但可使用例如统计平均、曲线拟合、回归分析等等其它方法来获得广告的目标简档与用户的简档之间的匹配的合逻辑的指示。尽管主要将以上方法理解为标量方法,但可使用利用向量表示(例如,点积)、人工神经网拓扑等非标量方法。举例来说,个别规则群组的每一属性的置信等级可由n维向量表示。如果必要的话(例如,如果不同个别规则群组单独向量化),那么所述n维向量可以是与其它m维个别群组的点积,以产生广告规则群组置信度的总体交集或投影。此值可接着以用户的简档的数学表示进行标量操纵或“点积运算”(依据投影空间),以产生匹配指示置信等级。可使用例如气泡或分级方法等其它匹配型算法。当然,应理解,可视需要使用各种形式的这些和其它方法来获得广告匹配的较精确和/或高效的确定。匹配算法可视需要驻存在移动消息递送系统上或具有移动消息递送功能的客户端上。另外,依据所选择的配置和资源,可在消息递送系统或具有消息递送功能的客户端之间解析这些算法的多个部分。图25是说明根据本发明实施例的示范性用户简档匹配指示符(mi)过程2500的流程图。示范性过程2500实施上文所论述的算法/方案中的任何一者或一者以上。示范性过程2500在步骤2510处启始,并继续到步骤2520,其中编译或表征例如广告商的广告目标参数等消息目标参数。接下来,在步骤2530中,示范性过程可进行到产生目标参数的度量或数学表示。在各种实施例中,此步骤可简单地需要将参数特性转换为可管理的数字,例如具有0到100之间的范围的标量值。当然,可依据设计偏好使用不论正和/或负的任何范围。步骤2530可使广告的目标参数能够由数学表达或值来表示。举例来说,如果广告商希望以所有女性为目标,且私下不知悉女性与男性订户的比率,那么广告商的请求将根据提供者的订户群体细分而转换。即,假设提供者的订户群体中的1:1女性与男性比率,那么这将是50%或0.50的值。或者,如果特定提供者的相应订户性别比率为1:2,那么这将转化为近似33.3%的订户群体或0.333的近似值。应理解,可对目标参数执行其它操纵,例如转换为向量或参数化表达。并且,依据呈现目标参数的初始格式,步骤2530可简单地由在极少或无操纵的情况下将参数转发到下一步骤组成。即,目标参数可能已处于能够经受后续步骤处理的形式且可能不需要任何转换。控制继续到步骤2540。在步骤2540中,可发生用公式表示的数学表达或度量的任选调节或变换。举例来说,依据消息的目标参数的复杂性和分配给消息的目标参数的定义空间,可能需要执行进一步处理和操纵。举例来说,可执行不同广告目标参数之间的相关。举例来说,如果广告商想要特定区域代码内作为新订户的具有18到24岁之间的年龄范围的女性目标简档,那么可形成置信等级或其它类型的数学推断,以提供整个广告目标参数集的较简单或较高效的表示。应了解,可在认为适当时使用其它形式的相关或操纵。另外,基于移动客户端的处理能力和/或其它实际考虑因素,可能需要细化度量或减小度量的复杂性以实现较有效或较高效的匹配。控制继续到步骤2540。在步骤2550中,可执行消息匹配算法以确定消息目标简档与用户简档的匹配度量或配合适宜性。应了解,此过程可使用本文所描述或此项技术中已知的若干可能的匹配算法中的任一者。非限定性实例为模糊逻辑、统计方法、神经网、气泡、分级等等。接下来,在步骤2560中,可产生总体用户匹配指示值、总体置信等级或指示消息对用户简档的适宜性等级的其它度量。在确定用户匹配简档指示(其例如可简单地为标量数字或者“是”或“否”值)后,控制继续到步骤2570,其中过程终止。基于以上示范性过程2500,针对目标群体指定的广告和其它消息可与用户的简档匹配以确定消息/广告对用户简档的适宜性。因此,如果给出较高或可接受的匹配指示,那么可将消息/广告转发给用户,期望用户将对消息作出满意的响应,或按照对用户作出的安排。因此,为用户“定制”的广告/消息可高效地散布给用户。图26是说明根据本发明实施例的示范性用户简档匹配指示符2600的框图。示范性用户简档匹配指示符2600包含目标简档产生器2610、广告服务器2620、用户简档产生器2630、简档与简档比较器2640以及存储系统2660。在操作中,比较器2640可容纳在用户系统(未图示)中,且可将目标简档产生器2610转发的信息与用户简档产生器2630转发的信息进行比较。目标简档产生器2610可转发与广告服务器2620提供的广告有关的属性,其中所述信息/属性可与如用户简档产生器2630提供的用户简档的信息/属性进行比较。基于比较器2640中含有的算法,匹配指示可用公式表示,从而指定目标简档对用户简档的适宜性等级或置信等级。基于所述匹配指示,来自广告服务器的与目标简档的属性一致的广告和/或信息可转发到存储系统2660。存储系统2660可驻存在用户系统上。因此,“定制的”广告和/或信息可在不危害用户简档的隐私权的情况下转发给用户。基于过去观看历史的关键词相关:上文所描述的匹配指示符计算中的潜在输入中的一者可为所观看的先前消息(即,用户的“观看历史”)与新消息之间导出的相关值。在此上下文中,或者消息可根据设计偏好而与来自广告销售接口处的词典的关键词相关联。参看图27,描述一过程,其描述关键词相关联消息递送的示范性产生和使用。所述过程在步骤2710中开始并继续到步骤2720,其中可将关键词指派给各种消息。举例来说,针对妇女的服装的广告可具有四个关键词,包含“时尚”、“女性”、“服饰”和“昂贵”。所述关键词可广泛地与一类广告/消息相关联,或可个别地与特定种类的广告/消息相关联。因此,依据所期望的分辨或辨别等级,一个以上关键词可与一特定广告/消息相关联,或反之亦然。在各种实施例中,关键词可限于广告/消息词典或索引。继续,可给予此类关键词权数(例如,0与1之间的数字)以帮助描述特定消息与关键词的含义之间的关联强度。如果确定关键词不具有相关联的或外加的权数,那么其权数可假定为1/n,其中n是与消息相关联的关键词的总数目。以此方式,可以1/n因子应用总平均权数,以在某种意义上将总体关键词值规范化在所要范围内。所指派的权数可提供某一程度的规范化,尤其在多个关键词的情况下(例如,1/n,给定n个关键词,其中每一关键词具有最大值1),或可用于根据预定阈值或估计来对关键词或广告/消息进行“估价”。举例来说,一些关键词可依据当前事件或某一其它因素而具有较高或较低相关性。因此,可在认为适当时经由加权将加重或去加重强加于这些特定关键词。假定步骤2720具有将权数指派给关键词的措施作为用于固定关键词值估计的关键词关联的一部分。然而,在一些例子中,可能未预先指派权数,或权数估价未确定。在那些例子中,可将任意值指派给关键词,例如权数1。假定这些关键词被转发到移动客户端。控制继续到步骤2730。在步骤2730中,可监视用户对消息的响应。在操作中,可将消息呈现给用户,于是用户可选择是否在所述消息上“点击”。如此项技术中应了解,术语“点击”可被假定为表示用户对消息的存在的任何形式的响应,或作为操作消息序列的一部分。在一些用户实施例中,可将缺少响应解释为肯定的无点击或点击离开响应,在一些情况下类似于取消选择。因此,可历史地计量移动客户端用户对各种广告/消息的响应。通过监视关于广告/消息的一般群体或甚至有目标的群体的用户的“点击”响应,可获得对用户的兴趣的初始评定。在各种实施例中,用户对给定广告/消息或一系列广告/消息的响应时间也可用于计量用户对其的兴趣。举例来说,用户可点进若干广告/消息,每一广告/消息具有不同的相关性程度或关键词,且点进率或点通率可被理解为指示用户兴趣。控制继续到步骤2740。在步骤2740中,可执行特定广告/消息的用户选择(例如,点击)与其相应关键词的比较,以建立至少“基线”相关度量。再次,可注意到,所述选择和/或选择率可用于确定用户对关键词相关联广告/消息的兴趣。通过此比较,可提供各种关键词与用户的广告/消息偏好之间的相关。此相关可使用若干方法中的任一者来实现,例如统计方法、模糊逻辑、神经技术、向量映射、主成份分析等等。从步骤2740,可产生用户对广告/消息的响应的相关度量。在各种示范性实施例中,内嵌在消息递送系统和/或w-at上的“关键词相关引擎”可跟踪特定消息/广告可以特定关键词呈现(或转发)给用户的总次数(例如,n_总-关键词)连同对所述关键词的总点击数(例如,n_点击-关键词)。可计算n_点击-关键词/n_总-关键词的比率以确定关键词与用户的响应的相关。如果在没有针对给定消息的相关联权数的情况下指定关键词,那么用于消息的关键词的权数可假定为1。通过如上所述用公式表示比率,可产生用于计量用户对关键词标记的广告的反应或兴趣的度量,且可相应地设计对匹配的细化或改进。在以上实例中,肯定点击可用于指示用户的兴趣。然而,再次还应了解,在一些实施例中,无点击或无直接响应也可用于推断兴趣等级或匹配相关性。作为一个示范性实施方案的说明,假定对于给定广告存在n个关键词。可基于相关联的关键词权数创建n维向量a。可用每一维度中广告的每一关键词与用户的相关度量来创建n维相关向量b。可接着创建用以建立广告与用户的相关的标量相关量度c,其是向量a和b的函数。在一些实施例中,相关量度c可简单地为向量a与b的点积(c=a·b,如c=(1/n)a·b)。此标量相关量度c提供广告有多好地基于特定用户的先前广告观看历史而目标对准到所述特定用户的非常简单且直接的量度。当然,可使用其它方法来使a与b对应相关,例如参数化、非标量变换等等。以上方法假定关键词词典具有彼此独立的关键词。倘若关键词相互关联,那么可使用模糊逻辑来产生用于相互关联的关键词集合的组合权数。可实施其它形式的逻辑或相关,例如多项式拟合、向量空间分析、主成份分析、统计匹配、人工神经网等等。因此,本文所描述的示范性实施例可在认为必要时使用任何形式的匹配或关键词与用户相关算法。控制继续到步骤2750。在步骤2750中,移动客户端或用户可接收与各种预期有目标的消息/广告相关联的“目标关键词”。接下来,在步骤2760中,可评估所接收到的目标关键词以确定是否存在匹配或关键词是否满足可接受的阈值。在各种实施例中,匹配评估可视需要涉及较高算法,例如统计方法、模糊逻辑、神经技术、向量映射、主成份分析等等。应了解,步骤2740的相关过程和步骤2760的匹配过程可以是互补的。即,不同算法可与相应过程一起使用,这取决于设计偏好或取决于所转发的广告/消息关键词的类型。控制继续到步骤2770。在步骤2770中,可将那些被认为在接受阈值内匹配的有目标的消息转发和/或显示给用户。广告/消息的转发可采取若干形式中的任一者,一个此形式(例如)是简单地准许匹配的广告/消息由用户的装置接收和观看。在一些实施例中,非匹配广告/消息可转发给用户,但被停用以便阻止例示或观看。因此,如果用户的偏好或简档随后被修改,那么先前不可接受的广告/消息但现在可接受的广告/消息可驻存在用户的装置上且被适当地观看。当然,可设计出使被认为“匹配”或“不匹配”的广告/消息可用的其它方案,而不脱离本发明的精神和范围。在步骤2770之后,示范性过程2700进行到步骤2780,其中所述过程终止。通过使用以上示范性过程2700,有目标的广告/消息可经过滤以迎合用户的兴趣。用户的兴趣可初始地通过经由关键词指派和匹配历史地监视用户在用户的移动客户端上对一组广告/消息的“点击”响应来建立。接着还可通过基于当前观察到的用户响应更新用户的兴趣简档来实现动态监视。因此,可获得有目标的广告/消息的较直接或较高效的散布,从而产生较令人满意的移动客户端体验。继续,注意,大量信息可在装置的寿命期间流经与用户相关联的移动装置。用户可与呈现给其的某一部分的信息交互。由于存储器约束的缘故,可能不可能将所有此类信息都存储在移动装置本身上。甚至存储与流经装置的所有此类信息相关联的所有元数据和用户响应也是不可行的。因此,可能需要基于用户行为创建捕获用户偏好的用户模型,使得可将相关内容/信息呈现给用户,而不必存储所有与用户有关的过去的信息。因此,如图28所示,可能需要创建能够捕获用户偏好和所呈现的信息的“关键词学习引擎”2810。连同关键词学习引擎一起,可能需要具有基于习得的模型的“关键词预测引擎”2820,以提示用户对呈现给用户的新信息感兴趣的可能性。这可帮助在新内容到达移动装置上时对其进行过滤,使得可将相关信息呈现给用户。在操作中,与到达移动装置的信息相关联的元数据可在学习引擎2810和预测引擎2820中使用。任何与所呈现的信息相关联的用户响应也可在学习引擎2820中使用。在操作期间,学习引擎2810可使用所有过去的信息,例如与相应呈现的信息相关联的元数据和用户行为。基于输入,学习引擎2810可细化此输入以提供习得的用户偏好模型。此用户偏好模型可接着用于预测引擎中,所述预测引擎可接收与新信息有关的元数据,接着使元数据与用户偏好模型相关以提供针对新信息而预测的用户匹配指示符/指示。此用户匹配指示符/指示可接着用于确定是否将所述信息呈现给用户。将了解,用户偏好可相对于正学习的活动具有上下文关系。举例来说,用户可具有关于用户想要观看的广告的不同偏好,以及关于用户想要浏览的网页的一组不同偏好。举例来说,用户可在网上阅读关于本地社会新闻中的犯罪行为的新闻,以从安全观点意识到此活动;然而,这不应暗示用户将对通过广告购买枪支感兴趣。因此,平台上的消息呈现引擎可反映相对于用户的网络浏览器偏好的不同用户偏好。其它情况可包含与平台上的音乐应用程序或平台上的体育应用程序有关的用户偏好。一般来说,每种情况都可能需要学习和预测引擎。在此文献中,提供针对给定情况(例如,处理有目标的内容消息/广告)的用于学习和预测的示范性架构和算法。所提议的架构和算法可应用于不同情况,而不损失一般性。讨论中的一个任务是在给定情况中从用户的电话使用习惯学习用户偏好,例如从其对呈现给用户的有目标的内容消息(例如,广告)的响应学习其喜恶。目标是提供利用较快且不随着所呈现的数据的量缩放的学习算法的解决方案。另外,基于系统所学习的模型,当新消息/信息到达移动装置时,可用的预测引擎可呈现相对于给定用户的习得偏好的信息的匹配指示符。此匹配指示符可连同其它系统约束(例如,任选地,收入或大小信息)一起使用以作出是否将信息实时呈现给用户的决策,或作出是否将信息存储在用户的移动装置上(例如,移动装置上的空间受限的有目标内容消息高速缓冲存储器中)的决策。图29中描绘示范性架构流。如图29所示,当用户2990正走过或驾车经过星巴克(starbucks)店时,消息服务器2620可将单个消息(例如,星巴克咖啡广告)实时递送到用户的移动装置100。基于预测模型,移动装置100基于所产生的与此信息有关的匹配指示符值而作出是否将此消息呈现给用户2990的决策可为有用的。或者,与各种消息有关的元数据信息流可到达移动装置100,且常驻的预测算法可针对每一消息提供匹配指示符的相对值,使得移动装置100可作出将哪些消息存储在移动装置100上的空间受限高速缓冲存储器240中的决策。移动装置100上的选择函数可除使用来自预测引擎2820的命令和信息作出是否向用户2990呈现给定消息的决策的匹配指示符计算外还任选地使用额外指示符,例如相关联收入(消息值计算准则)和大小(选通和/或消息值计算准则)。关于学习引擎2810,针对呈现给用户2990的信息,如果存在与所呈现的信息相关联的用户响应,那么与用户信息相关联的元数据和用户响应两者可由学习引擎2810用来产生习得的用户偏好模型。另外,对于图29的移动装置100,以每消息为基础的个别动作可或可不存储在移动装置100中。即,用户动作连同给定消息的元数据一起可用于细化习得的用户偏好模型,且随后从系统丢弃与用户动作和广告元数据有关的输入。在各种实施例中且如上文所论述,产生并使用描述用户对给定情况的不同可能偏好的关键词词典可为有用的。在操作中,有目标的内容消息的创建者可在用于有目标的内容消息的元数据中指定与有目标的内容消息相关的那些关键词。当将与有目标的内容消息相关联的元数据呈现给用户2990时,学习引擎2810可基于用户2990对信息的响应而更新与关键词有关的用户偏好。另外,当将元数据(包含与有目标的内容消息相关联的关键词)呈现给移动装置100时,预测引擎2820可计算可用于确定是否将有目标的内容消息呈现给用户2990的针对用户的匹配指示符。在实际操作中,可假定关键词词典是用于学习目的的展平表示。注意,暴露于有目标的内容消息提供者的关键词词典在性质上可为展平的或分级的。在分级表示中,处于关键词树中的较高级的节点可表示粗粒度偏好类别,例如体育、音乐、电影或餐馆。关键词树分级中较低的节点可指定用户的较细粒度偏好,例如音乐子类别摇滚、乡村音乐、流行音乐、说唱等。虽然给定关键词词典可为分级的,但关键词树可出于学习的目的而从树的底部开始展平。举例来说,具有四个子类{摇滚、乡村音乐、流行音乐和说唱}的树中的音乐节点可经展平为具有音乐(总体)和4个子类别的五节点表示。如果母节点存在l个叶,那么展平表示针对关键词分级中的母节点的根部转化为(1+l)个叶。因此,可从树的叶开始一直到分级的顶部递归地实现树的展平,使得树的所有中间节点直接连接到树的根部。举例来说,具有k个等级的四叉树表示将由根节点连同4+42+43+.....+4(k-1)个节点组成。使此树展平将导致由直接连接到根节点的4+42+43+.....+4(k-1)=(4k-1)/(4-1)-1=4/3*(4(k-1)-1)个节点组成的关键词词典树。注意,k=1将对应于0个关键词,k=2将对应于4个关键词,k=3将对应于20个关键词,等等。图30a和图30b描绘分级表示的树中的中间母节点处的示范性展平过程。学习和预测算法可对经加权求和的度量起作用,这有效地导致基于分级树的平坦化型式的学习(如果决策制定是在树的顶部处完成)。继续,呈现用于移动装置上的学习和预测引擎的技术。出于注解的目的,假设存在n个关键词,每一关键词对应于可能想要相对于用户捕获的偏好。可抽象地将用户的偏好表示为向量p=(p1,...,pn),其中值pi对应于针对类别i的用户的偏好等级。类似地,可抽象地基于消息与关键词的相关性将消息表示为向量a=(a1,.....,an),其中值ai对应于消息与关键词i的相关程度。可假定消息是依序呈现给学习算法的。应注意,通常可使用较大数目(可能几百个)的关键词,但其中大部分将与特定消息无关。可预期用户将仅对几个关键词具有较强偏好。数学上将此类向量称为“稀疏向量”。可假定输入训练消息关键词向量是稀疏的。还可假定所要用户偏好向量p也是稀疏的。基于用户模型的对用户偏好的当前估计的猜想可表示为下文描述用于学习和预测引擎的算法。学习引擎:输入:消息(表示为向量):a用户响应:“发生点击”持久:用户偏好的当前猜想(作为向量):(初始为0)衰减参数:d计数器:c(初始为0)c:=c+1等式(3)估计可在初始值0处开始。然而,在存在可用信息的情况下,可选择使用不同的开始种子。举例来说,知道本地人口统计可帮助将新移动用户的简档种到某一平均值或混合物(amalgam)。如果种子向量s可用,那么可将的初始值设置为等于种子s,其它步骤没有变化。另外,可能可使用恒定的衰减参数α,在此情况下,在等式(2)中α:=1/d,其中d为常数。预测引擎:输入:消息(表示为向量):a用户偏好的当前猜想(作为向量):返回:在操作中,可提供以下操作保证:(1)如果消息和用户偏好是稀疏的,那么学习引擎可从用户响应(例如,用户的“点击行为”)快速学习用户偏好。即,学习的速率可与消息和/或用户偏好的稀疏度成比例。(2)学习引擎对高噪声是稳健的。即,即使用户在较大数目的无关消息上点击,只要她正在较小百分比的相关消息上点击,学习引擎就将能够学习潜在偏好。(3)如果潜在用户偏好随时间改变,那么学习引擎可较好地适合新偏好。除信息-空间稀疏度外,注意,可基于信息的呈现速率、初始种子的值和用户简档的方面来确定针对用户选择速率的学习速率。图31中提供来自针对可能的关键词学习情境的矩阵实验室(matlab)模拟的结果,图31描绘在活动的经建模的学习引擎,其中水平轴表示不同关键词(总共500个),且垂直轴表示个人的偏好的强度-正暗示用户喜欢,负暗示不喜欢。顶部曲线3102展示潜在的用户偏好,而随后的四个曲线3104到3110展示在分别接收到50、100、500和1000条消息之后算法的最佳猜想。对于图31中表示的模拟,随机选择稀疏向量以表示潜在偏好向量。因为消息是随机选择的,所以用户的行为可模拟如下:用户约25%的时间在真实相关消息上点击,且其余75%的时间用户在无关消息上点击。衰减参数d被设置为3000。关于哪些消息被点击的信息被传递到学习引擎。应注意,对于当前实例的模拟,学习引擎未被给予任何关于每一消息是否与用户真实相关的信息。鉴于图31,显然针对个别学习情况的基于关键词的用户偏好表示在移动平台上可为合乎需要且有用的。应了解,图31的实例可通过若干经典自适应技术来改进。举例来说,向预测模型引入较小程度的随机性以通过进一步挖掘用户的兴趣来细化用户的模型(实际上执行经典神经网络学习的“磨练”过程特征)可能是有用的。另外,可通过随时间的过去或基于用户响应的类型(例如,强正、弱正、中性、弱负、强负)改变衰减参数来修改等式(2)的中央学习/自适应算法。强正响应可对估计具有正贡献(a/d(t))(学习引擎中的步骤6)。然而,如果用户对某一信息显示出某一形式的强负行为,那么响应可对估计具有负贡献(-a/d(t))。如果用户显示出某一形式的弱正响应,那么响应可对估计具有微小贡献(αa/d(t)),其中0≤α≤1。类似地,弱负响应可对估计具有负且微小的贡献(-αa/d(t)),其中0≤α≤1。或者,可通过由系统操作者或响应于某一用户行为对特定关键词强加估计限制(即,上限和下限)来修改等式(2)的中央学习/自适应算法。举例来说,强负用户反应(例如,永不再展示此类型的消息的某一指令)可对一个或一个以上关键词强加上限。更进一步,应了解,在各种实施例中,训练参数和/或学习规则可内嵌在给定消息中,其可反映消息与关键词的相关强度。举例来说,对于具有三个相关关键词kw1、kw2和kw3的第一广告,与关键词kw2和kw3相比,关键词kw1可更紧密地耦合到广告的内容。假定相应的衰减参数500、2500和3000与广告一起发射,那么广告的选择可促使预测模型比针对和更快地改变相应估计注意,预测引擎可经设计以要求基线相关度量超过用以确定目标消息与用户的相关性的阈值。举例来说,代替于图31,可能需要仅使用与超过0.25和/或在-0.20以下的估计值相关联的关键词来选择消息。类似地/或者,可能需要仅使用前10个值关键词和/或最后5个关键词来选择消息。预测模型的此简化可通过消除用户选择“噪声”的影响来改进移动消息递送装置的性能和可靠性。最后,虽然等式(1)到(3)代表被称为“lms最陡下降”自适应/学习算法的算法,但应了解,可使用其它学习算法,例如牛顿算法,或任何其它已知的或以后开发的学习技术。图32a和图32b概述移动客户端执行各种学习和预测过程的示范性操作。所述过程在步骤3204中开始,其中指派一组关键词。如上文所论述,所述组可用关键词可为稀疏的或非稀疏的,且/或以分级或非分级/展平关系布置。接下来,在步骤3206中,可将所述组关键词下载到移动客户端,例如蜂窝式电话或具有无线能力的pda。接着,在步骤3208中,可将一组种子值下载到移动客户端上。在各种实施例中,此类种子值可包含一组零值、一组基于用户的已知人口统计而确定的值或一组通过上文关于初始/种子值论述的其它过程中的任一者确定的值。控制继续到步骤3210。在步骤3210中,可将一组第一消息连同适当的元数据(例如,关键词和(可能)关键词权数)和/或任何数目的学习模型(例如,经修改的最陡下降算法)和/或任何数目的学习参数(例如,上文论述的衰减参数、上限、下限、上下文约束等等)一起下载到移动客户端上。注意,虽然本组操作允许在与元数据和其它信息相同的时间下载消息,但在各种实施例中,消息可在移动客户端经由任何数目的选通或估价操作确定此类消息为适宜的之后下载。控制继续到步骤3212。在步骤3212中,可执行若干预测操作以预测将可能为用户感兴趣的消息(例如,有目标的广告),注意此预测操作可基于由步骤3208的种子值构造的习得模型。接下来,在步骤3214中,可将所需消息显示(或以其它方式呈现)在移动装置上。接着,在步骤3216中,移动装置可监视用户对所显示的消息的响应(例如,观察且可能存储点进率)。控制继续到步骤3220。在步骤3220中,可执行一组一个或一个以上学习算法以更新(或以其它方式确定)各种习得模型来建立一组或一组以上习得用户偏好权数。注意,如上文所论述,习得模型可针对多种情况而提供,可使用任何数目的自适应过程(例如,lms运算),可并入有针对特定消息的算法和学习参数等等。控制继续到步骤3222。在步骤3222中,一组第二/目标消息可连同适当的元数据和/或任何数目的学习模型和/或任何数目的学习参数一起下载到移动客户端上。再次注意,虽然本组操作允许在与元数据和其它信息相同的时间下载消息,但在各种实施例中,消息可在移动客户端经由任何数目的选通或估价/预测操作确定此类消息为适宜的之后下载。控制继续到步骤3224。在步骤3224中,可执行若干预测操作以预测可能为用户感兴趣的消息(例如,有目标的广告),注意此预测操作可基于步骤3220的习得模型。接下来,在步骤3226中,可将所需消息显示(或以其它方式呈现)在移动装置上。接着,在步骤3228中,移动装置可监视用户对所显示的消息的响应(例如,观察且可能存储点进率)。控制接着跳回到步骤3220,其后可视需要或在另外合乎需要时重复步骤3220到3228。对于统计产生的应用-在各种示范性实施例中,用户偏好向量可具有n个维度,但仅m个维度的某一子集可与用户相关。可从n个维度中随机选择k个维度的稀疏集合,但可发射与选定的k个维度相关联的用户偏好值。假定某一人口统计类型(例如,青少年)的群体中存在u个用户。如果所有u个用户将所有n个维度值发射到服务器,那么每一维度可具有可用的u个样本以确定与所述维度相关联的统计结果(例如,平均值或方差)。然而,如果仅发射稀疏(k维)分量,那么平均来说,对于每一维度,可能uk/n个样本为可用。只要u>>n,就存在足够的样本可用于计算每一维度的统计结果,而不要求每一用户发射其偏好向量的所有n个分量。另外,如果仅一部分(r个)用户发射信息,那么平均来说,对于每一维度,可能ukr/n个样本为可用。因此,可在搜集整个用户群体的统计结果的同时维持每一用户的信息的足够程度的隐私权。高速缓冲存储器未中历史属性:每当从高速缓冲存储器请求特定消息/广告且高速缓冲存储器中没有满足所请求的消息/广告类型的消息/广告时,就失去了向用户展示适当消息/广告的机会。因此,需要向具有高速缓冲存储器在新近的过去已针对其而记录未中的类型的消息给予更多加权的值。在各种实施例中,例如上文论述的高速缓冲存储器未中状态匹配指示符(flagcache_miss_mi)等参数可起作用以通过辅助消息/广告值计算而避免此类失去的机会。在各种实施例中,此属性起作用以确定新的预期消息是否与最近记录的高速缓冲存储器未中匹配。如果新的预期消息与最近高速缓冲存储器未中中的一者匹配,那么此属性可为逻辑“1”(或等效物),且否则为逻辑“0”(或等效物)。一旦消息由应用程序从高速缓冲存储器存取并供应给用户,此旗标就可复位。如果为高速缓冲存储器条目选择新消息,那么高速缓冲存储器未中条目可从所记录的高速缓冲存储器未中列表中去除。过滤规则:过滤规则可由系统操作者用来驱动过滤代理的操作。这允许系统操作者以动态方式控制过滤代理的功能性。过滤规则可为不同类型且用于驱动过滤子系统的不同功能性。一些典型使用情况可包含:·可确定用于基于不同分类将高速缓冲存储器空间划分为不同类别的消息高速缓冲存储器比率的过滤规则。所述高速缓冲存储器比率可为固定的或可基于某些已定义准则而为动态的。·可确定每一类别的值计算公式的过滤规则。·可定义消息的作为基于时间的值衰减率的λ的过滤规则。·可用于指定进入依据一类别内的消息值属性对最终消息值的计算中的系数/权数中的任一者的过滤规则。·可定义匹配指示符计算公式的过滤规则。·可定义高速缓冲存储器未中状态匹配指示符计算公式的过滤规则。·可定义消息重放概率指示符计算公式的过滤规则。·可定义最小置信等级阈值的过滤规则,低于所述最小置信等级阈值,在装置上计算随机ctr。·可定义将为每一消息类型存储的默认消息的数目的过滤规则。架构:依据不同的消息分布模型,选通和消息选择子过程可能由存在于服务器上或客户端上的不同代理来实施。下文的以下部分论述用于基于不同广告分布机制进行消息过滤的可能架构。多播/广播消息分布:图33是使用w-at100和多播/广播消息分布服务器150-a的多播/广播消息分布方案的说明。在多播分布的情况下,消息(例如,广告)、相应的元数据和消息过滤规则可由消息递送网络经由广播或多播信道分布给若干用户。因此,对以用户的用户简档为目标的消息的过滤和高速缓存可连同过滤过程的任何选通和选择子过程一起在w-at100上发生。单播消息分布:存在可用于实施从消息分布服务器单播提取消息的若干不同协议。基于此服务器处可用的信息,选通和选择过程可驻存在服务器或各种移动装置上。以下是关于所述协议中的一些协议和在每一情况下可实施的对应消息过滤架构的论述。单播消息分布-协议1:图34说明使用w-at100和单播消息分布服务器150-b的第一示范性单播消息分布方案。在操作中,w-at100可将“消息拉动”请求发送到服务器150-b,藉此服务器150-b可以系统内可用的所有消息来响应。此方法可通过在w-at100上产生并保存简档来向服务器150-b隐藏移动装置的用户简档。然而,如果因与移动装置的用户简档不匹配而导致存在消息的显著部分被拒绝的可能性,那么经由单播会话将消息递送到客户端可能是昂贵的。如在多播分布情况下一样,对以w-at100的用户简档为目标的消息的过滤和高速缓存可连同过滤过程的选通和选择子过程一起在w-at100上发生。单播消息分布-协议2:图35说明使用w-at100和单播消息分布服务器150-c的第二单播分布方案。在此方案中,用户简档可在w-at100上产生但可与服务器150-c同步,因为用户简档的相同副本可驻存在装置100和150-c两者上。w-at100的装置简档也可与服务器150-c同步,且因此在从w-at100接收到消息拉动请求之后,服务器150-c可容易地仅将有目标的消息推送到装置。选通过程,以及基于确定消息是否可向w-at100的用户简档目标对准的选择过程的多个部分可在服务器150-c上实施。消息值确定以及用具有较高值的新消息代替旧消息可在w-at100上实施。在操作中,w-at100与服务器150-c之间的用户和装置简档的任何同步程序可使用单独协议在频带外发生,或在某些实施例中简档可能包含在来自客户端的消息拉动请求中。单播消息分布-协议3:图36说明使用w-at100和单播消息分布服务器150-d的第三示范性单播消息分布方案。在操作中,用户简档可保存在w-at100上,但仅装置简档与服务器150-d同步,而用户简档仅保持在w-at100内。对应地,选通过程可在服务器150-d上实施,且服务器150-d可仅将已通过选通过程的消息推送到w-at100。选通过程的基于需要用户的简档的系统操作者指定的过滤(如果存在的话)的部分可在w-at100处实施。此外,选择过程可完全在w-at100处实施。与协议2一样,w-at100与服务器150-d之间的装置简档的同步可能使用单独协议在频带外发生,或简档可能包含在来自客户端的广告拉动请求中。单播消息分布-协议4:图37说明使用w-at100和单播消息分布服务器150-e的第四单播消息分布方案。在此方案中,在从w-at100接收到消息拉动请求之后,服务器150-e可用通过适当选通过程的消息的元数据来响应。因此,选通过程可在服务器150-e上实施。继续,选择过程可使用服务器150-e所提供的元数据在w-at100处实施。选通过程的基于需要用户的简档的系统操作者指定的过滤(如果存在的话)的部分可在w-at100处实施。接下来,w-at100可用对w-at100基于选择过程决定显示或存储在其高速缓冲存储器中的那些消息的消息选择请求来响应服务器150-e,且服务器150-e可将那些选定的消息提供给w-at100。再次,装置简档或选通参数可能包含在w-at100的初始消息拉动请求中,或者可能使用单独协议在频带外在w-at100与服务器150-e之间同步。处理/合成所捕获的位置数据以影响用户简档位置信息可常用于导出个人人口统计的指示符。在移动通信装置的情况下,位置数据可有时为比记帐信息更好的对关于用户的人口统计数据的指示。除对记帐信息的使用的约束外,记帐信息可能不包含足够数据以指示所要人口统计。此外,住宅人口统计可仅部分指示用户的消息相关兴趣。如果,举例来说,用户维持两个住处或趋向于常去特定位置,那么这可能不会被住宅人口统计指示。因此,举例来说,与特定工作或休闲位置有关的服务和产品可能不会被用户的住宅位置导出的人口统计反映,但仍非常有用。可理解,用户可能不希望发布他/她的位置信息以便保护隐私权或可能认为这过于冒昧。然而,通过保留由移动客户端搜集位置信息并执行基于位置的匹配的能力,有可能获得移动装置内的人口统计目标对准所需要的信息且仍保护隐私权。因此,举例来说,如果用户常带着具有适当功能的移动装置(例如,具有对gps信息的接入权的手机)去特定休闲区域,那么针对用户的休闲兴趣的适当信息可被导出且/或合成,而不会打扰用户和/或违背用户的隐私权。此信息可接着用于导出和/或更新驻存于移动装置的用户简档,所述用户简档又可用于确定哪些有目标的内容消息可下载和/或显示在移动装置上。概念上,这可导致基于实际检测到的位置以适合于与用户相关联的位置信息的方式放置广告和其它信息,而不将位置信息提供给外部代理。在操作中,可使用驻存于移动装置的数据库来存储位置信息。所存储的数据可包含原始位置数据,但在各种实施例中还包含关于以下各项的数据:特定位置区域位置、位置群集、从各种位置到其它位置的路径信息、结合与时间间隔相关联的值的位置类型以及特定位置类型的时间概率分布。继续,在许多情况下,用户动作可能不足以指示特定活动,但如果用户动作可与位置数据的一个或一个以上各种集合链接,那么此类动作可为相关的。以常去休闲区域但通常通过进入特定车道而进入所述休闲区域的人为例。关于所述车道的使用的数据本身将不指示车道的使用和存在以外的过多内容,且本身将不具有与休闲区域的任何关联。然而,通过使个人的位置历史与进入车道的当前动作耦合/相关,有可能建立个人正在去休闲区域的途中的统计上显著的概率。因此,特定位置信息可与和其它特定位置相关联的活动相关。继续的实例包含休闲区域、城市的多个部分、娱乐位置(尤其与日时信息组合)、地理位置与和工作相关联的日时组合,以及与购物相关联的位置。这些实例可与位置群集和时间间隔的识别组合。所述位置可与路径分析组合使用,路径分析可用于建立当前位置(或移动)与其它所存储的数据的关联,例如当前位置、位置历史和路径活动可用于识别特定活动的可能性,且因此使消息提供者能够在用户参与特定活动之前将消息目标对准。举例来说,通过在具有gps功能的移动客户端上测量各种位置,移动客户端可确定用户已下班且正在去用户常去的购物中心的途中。作为响应,mas(或其它有目标内容递送系统)可自动转发与用户可能感兴趣的产品有关的信息,以及提供到达购物中心的各种路线的高级交通信息。继续,在各种实施例中,为正在穿越公路的用户识别例如那些基于特定公路的各种商业可能是有用的。在此类例子中,可提供基于对消费者的活动的确定的有目标的广告或其它信息。此方法在客户具有对其移动装置的有限接入权但授权特定商业或特定种类的商业提供信息的情形中尤其有利。在各种实施例中,系统的显著方面可包含对个人的跟踪可在移动装置内执行且保留在移动装置内。在一种配置中,没有外部方私下知悉跟踪信息。进一步来说,使与各种有目标的内容相关联的跟踪信息匹配所必需的简档形成可在移动装置内执行。再次,通过将个人信息限于用户的移动装置,可能用户可发现此形式的简档形成是可接受的,因为其不是在外部执行。注意,在情形准许的各种实施例中,使移动客户端与其它装置(例如,许多汽车的基于gps的导航装置)上可用的资源相互协调可为可能且/或有利的。因此,只通过使移动装置能够向汽车的系统中的一者或一者以上通信的软件修改(依据特定实施例),gps和其它信息可共享。一般来说,此汽车和移动客户端可使用通常在此类装置中找到的蓝牙或类似无线接口来通信。因此,因为移动客户端的位置信息由汽车的gps/导航装置提供,所以移动装置的常驻用户简档可不以内建到移动装置中的gps系统为代价而更新。注意,除汽车外,特定移动装置可从多种替代来源(例如,远程服务器或其它附近的装置)导出位置信息,以接收位置信息。举例来说,移动客户端可与驻存在咖啡店内的802.11网络,或也许城市内的位置已知或能够被导出的局域无线网络串联系,以确定位置信息。注意,在各种实施例中,移动客户端可基于移动客户端/装置的能量级(例如,低电池电量)而选择信息的来源。还注意,可基于周期性测量(其中允许测量的周期变化)或基于随机测量或随机与周期性测量的组合来获得位置历史。移动客户端还可选择基于可用能量而改变gps捕获的速率,例如在低电池条件下以间歇性掉电来减慢gps捕获速率,以及改变其可能分接到其它可用数据源(例如,移动客户端具有接入权的汽车的加速计和/或速度计)中的速率。图38a到38h描绘显示为具有各种感兴趣点的由特定用户的具有gps功能的蜂窝式电话所捕获的信息屏幕3800-a…3800-h。如这些图中所示,每一信息屏幕3800-a…3800-h包含地图3810、一组控件3820、日历显示3830、每日柱状图3840和每周柱状图3850。在操作中,用户(或自动化程序)可设置所述组控件3820中的每一控件以建立gps取样时间以及显示用于地图3810、日历3820以及柱状图3840和3850的gps信息,注意到虽然柱状图3840是被划分为一小时的若干时隙的每日柱状图,且每周柱状图3850被划分为一天的若干时隙,但此类所捕获的位置数据可组织为任何数目的柱状图,包含展示特定位置、区域、位置群集和甚至表示用户已在各种时间周期(例如,工作日、周末、个别天、整周、整个月等等)的过程内经历的过去采取的路径的信息。注意,日历3830也可被视为柱状图。还注意,通过选择特定位置图标(例如,图38a的位置3850或3852),柱状图3840和3842的数据以及填充日历3830的数字可改变以反映与所收集的gps数据相当的gps数据。继续到图38c,特定位置可被识别(由移动客户端的用户,或由移动客户端中的某一估计软件)为用户的住处3854,且类似地在图38e中,特定位置可被识别为用户的工作场所3856。鉴于图41a到41h,应了解,具有gps功能的蜂窝式电话所捕获的位置信息可用于产生用户简档信息,其使常驻软件能够确定以下各项:(1)用户将在给定时间范围处于特定位置或沿着特定路径行进的可能性,例如职员在4:00pm处于工作位置;(2)用户将在给定时间离开特定开始位置的可能的时间范围,例如职员在5:00pm离开工作位置;以及(3)用户将处于特定第二位置或使用一路径(或位置或路径的集合)的可能的时间范围,例如职员在5:30pm使用特定道路,且在6:00pm与6:30pm之间到达其住处。注意,可能性信息可以许多种方式表达。举例来说,时间可能性可表达为特定时间点,在特定时间点上居中且具有特定方差的高斯分布;具有基于过去用户活动的唯一形式的连续概率分布函数(pdf);在邻接的时间周期(“时间桶”)内测量的离散pdf,其中所述时间桶具有相等或不等的大小,等等。使用此信息,适当启用的移动客户端还可确定用户的感兴趣点,例如用户的住宅、工作、爱好、宗教礼拜场所等等的可能位置,以及用户将处于此类位置的可能时间和此类感兴趣点的其它可能性信息(例如,可能的到达和出发时间)。此信息可接着用于定形或修改其移动客户端中的用户简档信息,且如上文所提及,所得的用户简档可用于确定什么信息(例如,广告、优惠券等)将最可能引起用户的兴趣,这又可导致在移动客户端上存储和/或显示特定目标信息。继续,图39和图40描绘用户在工作日结束时离开工作位置lw的实例的示范性数目的操作。关于各种位置(即,开始位置lw和预期的目的地位置l1到l8)的概率连同使用位置l1到l8之间的相应路径/道路r1到r8的概率一起可被假定是使用(使用gps和其它技术感测到的)用户的过去行为来形成的,且并入到用户的移动客户端中。从图39开始,假定用户在其工作日结束之前不久处于开始/工作位置lw。基于用户的过去行为,其移动客户端中的用户简档可确定用户可能在5:00-5:15pm下班且去往预期目的地位置l1到l8中的任一者,注意在当前实例中,去往位置l7到l8的概率下降到低于特定阈值且不应被考虑。假定用户去往位置l1和l6的概率均为0.1,那么用户使用道路r7和r8的概率也均为0.1。假定对于剩余的感兴趣的目的地来说用户的最终目的地的概率为l2=0.1、l3=0.1、l4=0.4且l5=0.2(其假定用户留下来工作的概率为0.1),那么用户使用道路r1的概率为0.7。因此,显然,移动客户端的用户的可能路线可基于移动客户端的当前位置lw相对于最有可能的目的地位置l1到l8的空间关系,以及最有可能的目的地位置l1到l8之间的空间关系。注意,可通过使用户的位置历史的过去时间数据相关以形成针对工作位置lw和/或用户可能已访问的任何其它位置的用户的过去存在和移动的时间概率分布来形成和更新用户的移动客户端的用户简档;结果是随时间变化的用户在给定位置的存在的概率密度函数(或其精确复制)。此用户简档可确定随时间和/或当前位置而变化的在用户考虑中的任何和所有当前最有可能的可能目的地l1到l6。还注意,最有可能的当前目的地中的任一者可为用户的多个过去识别的目的地的混合物或群集。举例来说,位置l5可实际上由一起紧密间隔的三个单独位置组成,其中所假定的位置通知为所述三个位置的质心(基于经加权地理平均值)或一般区域。类似地,位置l3到l5可能组合为混合物位置,假定位置l3到l5相对于彼此合理地接近/成群集。返回图39,再次,用户的移动客户端可基于日时、用户的当前位置和移动客户端所进行的其它当前观察,以及那些并入到用户简档中的过去的观察来确定最有可能的目的地。此类“其它当前观察”可包含例如最近电话和文本活动等内容。举例来说,如果用户在4:30pm从他的妻子那里接到一个电话,那么其可指示用户可能需要在回家之前去商店的可能性增加,因此改变当前可能目的地l1到l6的概率。类似地,如果用户未展示与其移动客户端的交互,那么其可指示用户可能延迟其从位置lw出发的可能性。继续到图40,注意,可基于离开第一位置lw之后移动客户端的位置改变的“在途中”累积测量来更新去往各种当前可能目的地l1到l6中的任一者的概率。即,当接收到新数据时,可能需要重新评定各种概率。对于图40的实例,这反映在去目的地l1和l6的概率以及用户留在位置lw的概率的变化在假定通过用户的移动客户端确定用户在道路r1上的情况下变得可忽略。因此,去目的地l1和l6或留在位置lw的概率可不予以进一步考虑。同时,到达位置l2、l3、l4、l5、l8和l8中的任一者的概率可增加,注意用户到达位置l2的可能性接近一(由于其与用户以及其它当前目的地位置l3、l4、l5、l8和l8两者的空间关系),即使用户在位置l2处没有停顿。因此,可使用基于其它在途中事件的自适应加权分配来实现确定可能的变换时间,例如离开第一位置或到达另一位置的时间。注意,在各种实施例中,并入到移动客户端中的第k阶马尔可夫模型(其中k是大于1的整数)可用于确定上文所论述的概率中的任一者。继续到图41,描绘针对图39和图40的用户的开始位置lw和预期目的地位置l1到l8的示范性马尔可夫模型4100。如图41所示,位置lw以及l1到l8以路径互连,且每一路径具有概率pn-m。再次,注意,每一概率pn-m可从用户简档导出且随用户的当前位置、变换事件和/或日时而变化。还注意,可能存在给定周期内用户留在位置ln处的时变概率pn-n,例如用户(在到达食品杂货店后)留在食品杂货店的可能性可具有以20分钟为中心的具有10分钟方差的高斯分布。图42是概述用于基于nfc事务来更新用户简档的示范性操作的过程流的图。所述过程在步骤4202中开始,其中可对移动客户端进行编程以根据预定或自适应取样频率和周期使用可用gps(或其它适宜的位置寻找装置)和/或局域无线蜂窝式网络、局域可用lan等等中的任一者对位置信息进行取样。接下来,在步骤4204中,可处理/合成所捕获的信息以识别感兴趣点、感兴趣区域、所采取的路径或任何其它位置和/或路径数据。接着,在步骤4206中,可进一步处理/合成所述信息以确定针对特定时间周期的可能的位置和/或可能的路径,以及针对给定位置或路径的可能时间周期的补充信息。控制继续到步骤4208。在步骤4208中,可使用驻存在移动客户端中的特殊软件来更新驻存在移动客户端中的用户简档。在各种实施例中,例如包含从对用户的过去观察导出的信息的用户简档信息可用于创建针对给定日时和当前位置的用户的可能行为的某一形式的概率模型。接下来,在步骤4210中,移动客户端可导出(直接或使用次级资源,例如汽车的gps)上文所论述的任何和所有最近/当前观察数据,例如位置、时间、变换/移动、传感器(例如,速度计)数据,以及与用户的当前和/或最近行为有关的信息,例如移动客户端观察用户发送文本消息。接下来,在步骤4512中,移动客户端可使用上文所论述的技术中的任一者来处理步骤4210的信息和用户简档内的信息,以基于用户的当前位置和时间来识别用户将可能采取的可能目的地、变换时间和/或路径(或对先前确定的概率的改变)。接着,在步骤4214中,移动客户端可基于用户简档、先前步骤中收集到的数据和所导出的任何概率数据来选择和/或显示信息,例如广告、优惠券等。控制接着跳回到步骤4210,其中可在发现必要或合乎需要时重复步骤4210到4214中的任何或所有步骤。本文描述的技术和模块可通过各种手段来实施。举例来说,这些技术可以硬件、软件或其组合来实施。对于硬件实施方案,接入点或接入终端内的处理单元可实施在一个或一个以上专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理w-at(dspd)、可编程逻辑w-at(pld)、现场可编程门阵列(fpga)、处理器、控制器、微控制器、微处理器、经设计以执行本文所描述的功能的其它电子单元或其组合内。对于软件实施方案,本文所描述的技术可用执行本文描述的功能的模块(例如,过程、函数等)来实施。软件代码可存储在存储器单元中并由处理器或解调器执行。存储器单元可实施在处理器内或处理器外部,在后一种情况下存储器单元可经由各种手段通信地耦合到处理器。在一个或一个以上示范性实施例中,所描述的功能可以硬件、软件、固件或其任何组合来实施。如果以软件实施,那么所述功能可作为一个或一个以上指令或代码存储在计算机可读媒体上或经由计算机可读媒体传输。计算机可读媒体包含计算机存储媒体和通信媒体两者,包含促进将计算机程序从一个位置传送到另一位置的任何媒体。存储媒体可为可由计算机存取的任何可用媒体。作为实例而非限制,此类计算机可读媒体可包括ram、rom、eeprom、cd-rom或其它光盘存储装置、磁盘存储装置或其它磁性存储装置,或任何其它可用于携载或存储呈指令或数据结构形式的所要程序代码且可由计算机存取的媒体。并且,严格地说,任何连接均被称作计算机可读媒体。举例来说,如果软件使用同轴电缆、光纤电缆、双绞线、数字订户线(“dsl”)或例如红外线、无线电和微波等无线技术从网站、服务器或其它远程源发射,那么同轴电缆、光纤电缆、双绞线、dsl或例如红外线、无线电和微波等无线技术包含在媒体的定义内。如本文所使用的磁盘与光盘包含压缩光盘(“cd”)、激光光盘、光学盘、数字多功能光盘(“dvd”)、软性磁盘、高清晰度dvd(“hd-dvd”)和蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。上述各项的组合也应包含在计算机可读媒体的范围内。提供所揭示的实施例的先前描述是为了使所属领域的技术人员能够制作或使用本文所揭示的特征、功能、操作和实施例。所属领域的技术人员将易于了解对这些实施例的各种修改,且本文所定义的一般原理可在不脱离本发明的精神或范围的情况下应用于其它实施例。因此,本发明无意限于本文所展示的实施例,而是本发明应被赋予与本文所揭示的原理和新颖特征一致的最宽范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1