一种软件定义网络中交换机迁移算法的制作方法
本发明属于通信网络技术领域,涉及一种软件定义网络中交换机迁移算法。
背景技术:
随着网络规模的扩大、用户数目的增多,单一控制器所控制的网络规模将无法适应越来越大的用户群体,并且在单控制器控制的sdn中,一旦控制器发生了故障,将对网络造成无法挽回的损失。多域sdn的提出,使得由sdn的单点故障问题得到了一定程度的改善,但多控制器域架构的“命运共享”是控制平面脆弱的主要原因。命运共享主要是指:将片区域a内的网络信息,备份到片区域b中,同理区域b的信息也将保存到包括a域在内的其他域中。在某一网络域发生故障之后,其他域能够对故障域进行管理,从而达到故障恢复的目的。在多域sdn的环境中各个控制器各自管理自身的域,控制器之间不断的进行状态备份。
针对该问题的解决方法有两种:其一,在部署控制器时通过合理放置控制的位置,从而增强控制平面的可靠性。这种方式主要缺点是:网络节点之间的映射都是静态的,因此无法适应网络的动态变化。其次是在部署完成之后,再发生故障问题时进行交换机之间的迁移。这类方法虽然能动态的调整网络。但考虑的因素单一造成了时延增大,负载不均等问题。
针对于故障之后的交换机迁移的问题许多方案大多都是以负载、时延这两个衡量指标进行目标控制器的选择;在选择交换机的目的控制器时,负载小的控制器可以使得流请求的排队时间短(packet-in消息能够快速的进行处理),时延较小的控制器可使得交换机能够尽快的获得流表从而缩短故障时间。
近年来,在sdn中交换机迁移算法的研究正受到越来越多的关注。对现有文献检索发现相关文献如下:
文献[l.f.müller,r.r.oliveira,m.c.luizelli,l.p.gasparyandm.p.barcellos.survivor:anenhancedcontrollerplacementstrategyforimprovingsdnsurvivability[c]//2014ieeeglobalcommunicationsconference,austin,tx,2014:1909-1915]提出按当前控制平面中控制器的负载最小值作为交换机的迁移目标。文献[kurokik,matsumoton,hayashim.scalableopenflowcontrollerredundancytacklinglocalandglobalrecoveries[j].2013:61-66]中提出在考虑当前控制平面中负载的同时,还考虑了控制器当前的cpu利用率,并按最小值作为交换机迁移的目标;而文献[guozhencheng,hongchangchen,zhimingwangandshuqiaochen.dha:distributeddecisionsontheswitchmigrationtowardascalablesdncontrolplane[c]//2015ifipnetworkingconference(ifipnetworking),toulouse,2015:1-9]考虑的是交换机迁移之后整个控制平面的负载均衡问题,通过映射每个待分配交换机与控制器的关系构建整个网络的效益函数,使用log-sum-exp函数逼近效益函数,按使得迁移后的网络效益达到最大值的交换机与控制器映射作为迁移的方式。与以上不同的是文献[m.obadia,m.bouet,j.leguay,k.phemiusandl.iannone.failovermechanismsfordistributedsdncontrollers//2014internationalconferenceandworkshoponthenetworkofthefuture(nof),paris,2014:1-6]与[dixita,haof,mukherjees,etal.towardsanelasticdistributedsdncontroller[j].acmsigcommcomputercommunicationreview,2014,43(4):17-27]均考虑的是交换机到控制器之间的最短距离作为迁移时的衡量目标;除此之外,文献[tootoonchiana,ganjaliy.hyperflow:adistributedcontrolplaneforopenflow[c]//internetnetworkmanagementconferenceonresearchonenterprisenetworking.usenixassociation,2010:3-3]通过提前定义控制优先级的方式来决定故障后交换机迁移的目的控制器,一旦控制平面中某个节点发生了故障,节点下的交换机将由预先定义优先级最高的控制器进行接管,文献[tootoonchiana,ganjaliy.hyperflow:adistributedcontrolplaneforopenflow[c]//internetnetworkmanagementconferenceonresearchonenterprisenetworking.usenixassociation,2010:3-3]则是采用随机定义的方式进行交换机迁移,即故障后由hyperflow随机决定该由哪个控制器去接管孤立的交换机。当前的研究仅通过负载或时延单一的目标进行交换机迁移,因此会导致负载分配不均或流表下发时延增大等问题,采用本方法可以解决负载不均或时延增大的问题。
由相关研究可知,为了能够减少迁移后流表下发时间及减小控制器与交换机之间的故障概率,本发明将交换机到控制器间的时延及控制器负载进行结合考虑的同时,还考虑了交换机到控制器之间的链路故障概率。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种使得在迁移后交换机获得了较短的流表下发时间的同时,降低了交换机到控制器之间的链路故障概率的方法。本发明的技术方案如下:
一种软件定义网络中交换机迁移算法,其包括以下步骤:
101、当控制器发生故障后,对故障域中的边界交换机,计算待迁移的边界交换机迁移优先级,并选择优先级最大的边界交换机优先进行迁移
102、以交换机与控制器之间的映射构建模型,以通过控制器的负载、控制器的剩余资源量、待迁移交换机与控制器之间的距离作为迁移的衡量指标,计算待迁移交换机与控制器之间的失信度;
103、通过失信度与任一控制器的负载构建映射关系并建立映射评估函数;
104、判断选择出的控制器是否使得评估函数达到最小值,若是则选择此控制器作为交换机迁移目的地并记录映射关系,跳转至步骤105,否则返回步骤103重新选择控制器;
105、若故障域中的交换机全部分配完毕,结束并输出映射矩阵,否则返回步骤101。
进一步的,所述迁移优先级定义具体包括:边界交换机vj的优先级权重pj*定义为:
进一步的,所述步骤102控制器的负载、待迁移交换机与控制器之间的距离作为迁移的衡量指标具体包括:
s1:控制器负载表示为:
s2:控制器的剩余资源量/资源利用率:csurplusi为控制器的容量ci减去控制器的资源使用量cui,即csurplusi=ci-cui,则剩余资源利用率usurplusi为剩余资源量csurplusi与容量ci的比值,即usurplusi=1-cui/ci;
s3:交换机到控制器的距离:通过交换机到控制器的最小时延进行衡量,即通过迪杰斯特拉算法计算出表示待分配交换机集合v-={vi,vi+1,…,vi+n}到各个备选控制器集合c-之间的最小时延d(i,j),其中i∈v-,j∈c-。
进一步的,还包括交换机在迁移过程中的失信度计算:在迁移过程中交换机按最短时延未能成功分配到目的节点的度量值,假设交换机节点vi到备选控制器节点ci的最短路径由
进一步的,所述步骤103通过失信度与任一控制器的负载构建映射关系并建立映射评估函数包括:对交换机vi到控制器cj的任意映射构建评估函数可表示为:
进一步的,所述建立映射评估函数前还包括度量变换的步骤,为了消除由于度量不同而引起数值上的差距而影响结果,对目标函数的两个度量目标f1,f2进行数值度量变换为f1,f2,使得每个函数都满足于0<fi<1,其中i=1,2,表示当前映射与理想映射之间的接近程度,其度量变换方式可表示为:fi=fi-fmin/fmax-fmin,其中f1表示在备选控制器集合中选择使用量最小的控制器,而f2表示在待分配交换机vi到备选控制器的失信度集合中选择最小值。
本发明的优点及有益效果如下:
本发明通过控制器的负载、待迁移交换机与控制器之间的距离作为迁移的衡量指标之外,还建立了每个交换机在迁移过程中的失信度矩阵,使得在迁移后交换机获得了较短的流表下发时间的同时,降低了交换机到控制器之间的链路故障概率。
附图说明
图1是本发明提供优选实施例所使用的分域之后的网络拓扑图;
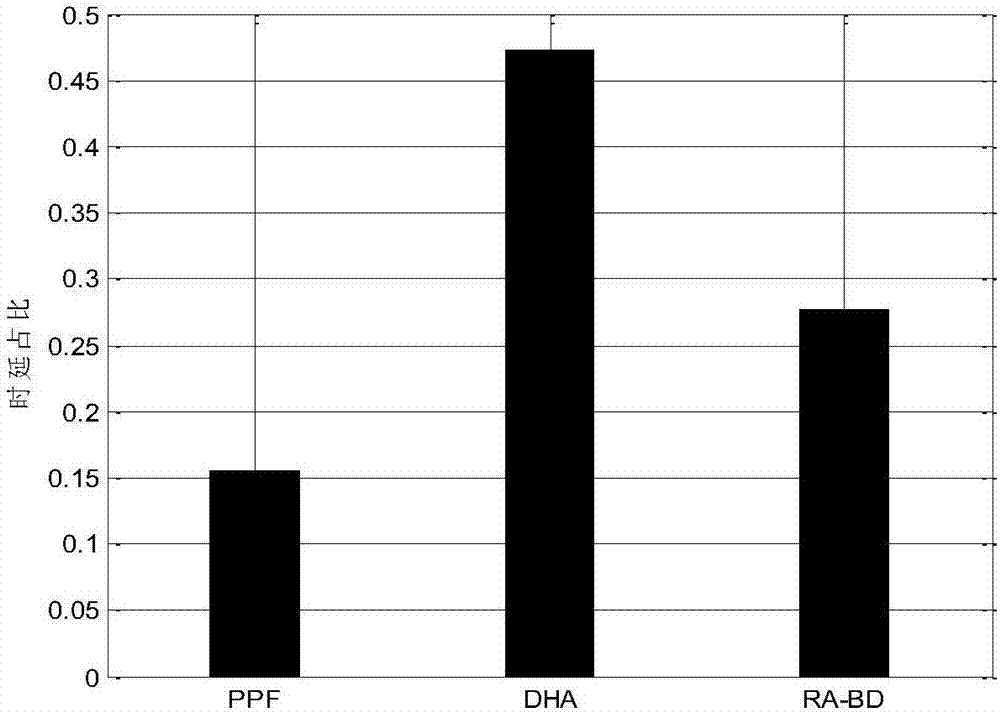
图2为本发明迁移后时延占比结果图;
图3为本发明迁移后失信度结果图;
图4为本发明迁移后各个控制器的资源利用率结果图;
图5为本发明优选实施例的软件定义网络中交换机迁移算法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
一种软件定义网络中交换机迁移算法,该算法将:控制器发生故障之后,底层的交换机进行重新分配。首先以交换机与控制器之间的映射做出模型构建,通过控制器的负载、待迁移交换机与控制器之间的距离作为迁移的衡量指标建立相应模型,除此之外,还考虑了每个交换机在迁移过程中的失信度;其次,通过对模型的目标函数按不同的映射方式进行计算选出其中最优结果;最后得出交换机与控制器迁移的映射矩阵。
为达到上述目的,本发明图5提供如下技术方案:
101、对于控制器发生故障之后,对故障域中的边界交换机,进行迁移优先级定义;
102、以交换机与控制器之间的映射构建模型,以通过控制器的负载、待迁移交换机与控制器之间的距离作为迁移的衡量指标;
103、除以第二步中控制器的负载与交换机到控制器之间的距离作为交换机迁移的衡量指标之外,定义了交换机在迁移过程中的失信度;
104、通过度量变换将控制器的负载、交换机到控制器之间的失信度进行变化后,构建映射评估函数,通过使得评估函数达到最优值的交换机到控制器的映射关系来进行迁移时目的控制器的选取;
105、如果故障域中的交换机全部分配完毕,结束算法,否则返回第二步;
具体包括:
s1:控制器负载的定义:在sdn中,控制器的容量ci作为控制器的最大负载值,主要由packet-in消息数目组成,即控制器最多能处理的流请求个数。则控制器i的负载使用量为域内交换机提供的负载,可表示为:
s2:控制器的剩余资源量/资源利用率:csurplusi为控制器的容量ci减去控制器的资源使用量cui,即
s3:交换机到控制器的距离:通过交换机到控制器的最小时延进行衡量,即通过d算法计算出表示待分配交换机集合v-={vi,vi+1,…,vi+n}到各个备选控制器集合c-之间的最小时延d(i,j),其中i∈v-,j∈c-。
s4:度量变换:为了消除由于度量不同而引起数值上的差距而影响结果,对目标函数的两个度量目标f1,f2进行数值度量变换为f1,f2,使得每个函数都满足于0<fi<1,其中i=1,2。表示当前映射与理想映射之间的接近程度,其度量变换方式可表示为:fi=fi-fmin/fmax-fmin,其中f1表示在备选控制器集合中选择使用量最小的控制器,而f2表示在待分配交换机vi到备选控制器的失信度集合中选择最小值。
s5:评估函数:当控制器想要接收一个待迁移的交换机时会先衡量这个交换机此刻产生的流请求数是多少,自身的剩余资源利用率能不能接收这个数量的流请求,因为控制器的使用量越小,流请求的时间越短,引起排队的几率越小。控制器还会衡量自己的当前位置与待迁移交换机的失信度,其中时延指的是带内模式下,与控制器相连的交换机到待迁移交换机之间的最小传输时延。相比于其他控制器而言,如果控制器与待分配交换机的失信度越高,那么这个交换机分配给其他失信度低控制器的可能性越大。因此在评估交换机vi到控制器cj的映射时,从控制器的使用量与失信度两方面进行评估,因此对交换机vi到控制器cj的任意映射构建评估函数可表示为:
图1为本发明所使用的分域之后的网络拓扑图;本文的网络拓扑来源于topologyzoo。topologyzoo:由澳大利亚政府和阿德雷得大学共同推进,针对于全球超过250个公共拓扑进行网络抽象,深得学术界认可。本文选择topologyzoo中由26个节点组成的renater拓扑。如图1所示:图中将网络拓扑划分为4个域,通过不同的颜色代表不同的域,每个域携带的交换机个数分别为5,6,7,8。现假设红色的域发生了故障。
在控制器的放置上均采用平均通信开销最小的方法,设置每条链路的故障概率区间为[0,0.2],也就是说网络中每条链路的概率为0到0.2之间的随机数。
本文中对交换机负载及控制器容量的设置,即网络中平均每个交换机产生的流请求速率为400k。在实际网络中,由于控制器的容量不同,因此对控制器的容量做出差异化设置,即控制器的容量设定为8m~11m。
图2为本发明迁移后时延占比结果图,为了能够更加直观的表示迁移之后故障域中交换机到控制器的流表下发时间,通过图2表示的时延占比来进行衡量,即迁移后故障域中交换机到控制器的时延占总体时延的比值,图中可看出迁移后本文算法ra-bd中交换机到控制器之间的时延与ppf与dha之间。对于ppf而言,通过就近分配的思想对交换机进行迁移,总是将交换机分配给距离最近的控制器,因此时延要低于ra-bd算法。对于dha算法而言,通过找寻交换机与控制器的映射关系,使得评估函数达到最优值,在迁移的过程中不考虑时延所带来的影响,因此在迁移后流表下发时间很长;而ra-bd与其衡量的方式不一样,在考虑负载与时延的同时,将时延与链路正常的概率倒数乘积作为衡量目标扩大了时延所占的权重,因此ra-bd在时延方面要优于dha算法。
图3为本发明迁移后失信度结果图:用平均链路的故障概率来表示,即迁移后交换机到控制器最短链路的故障概率。由于算法dha与ppf没有考虑到交换机到控制器之间的故障概率,所以在迁移之后交换机与控制器之间的链路更容易发生故障。而本文考虑到了此因素,因此在迁移之后交换机到控制器之间的平均链路故障概率为0.2左右。
图4为本发明迁移后各个控制器的资源利用率结果图:在相同条件下迁移结束后各个控制的资源利用率。通过图可以看出使用ppf算法进行迁移之后的控制平面的负载相差很大,是因为算法中不考虑负载对迁移交换机过程的影响,因此导致控制平面不均衡,甚至会出现级联故障。而dha中衡量负载的方式是找寻交换机与控制器之间的映射,使得评估值达到最优,即每次的迭代都使得控制平面内的负载方差达到最小,并且评估函数仅与负载相关,因此负载效果优于ra-bd算法。然而对于ra-bd的优化目标而言,是在考虑负载的同时获得更小的流表下发时延,因此ra-bd算法所产生的控制平面资源利用率稍逊于dha,仍然能够达到负载的大致均衡,均衡效果仍优于ppf算法。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!