一种属地网站监管系统的制作方法
本发明涉及网络监管技术领域,尤其涉及一种属地网站监管系统。
背景技术:
伴随着互联网的发展,网站数量急剧增多,截止2015年12月,中国网站总数为423万个,如此多的网站数量,导致网站信息安全管理面临着不容乐观的局面。各类非法信息(淫秽色情、迷信反动、赌博等)以网站为载体传播,监管难度大,传播速度快,危害严重。
目前网站(web网站和wap网站)存在域名采集不全、备案管理不足、不良信息泛滥、安全漏洞普遍存在的现状,导致了网站监管难度较大。结合工信部与公安部在公共信息网络与互联网的安全保护和安全管理打击公共信息网络违法犯罪的监管需求,需要有一种网站监管方法,来实现网站信息采集及违法违规网站识别处理的目的。而现有技术中,存在以下缺陷:
1.各个网站安全监管手段功能相对单一,无法实现网站信息采集、备案查询、违法违规网站识别及处理多功能网站监管的目的;
2.由于现有网站数量较多,数据较大,导致网站信息采集速度较慢,采集到的数据分布散乱,无法进行归类存储;
3.网站识别技术效率不高,不能准确快速地识别是否为违法违规网站。
以上可以看出,现有技术已无法满足网站安全业务需要。针对现有技术的上述缺陷,本发明提出一个集网站域名自动采集、网站自动备案验证、网站不良信息自动监测三大功能于一体的属地网站监管方法,通过建立监管网站库,经过信息采集,针对不同行业领域建立敏感信息规则库进行监管识别,对识别出的违规网站进行电子取证及预警通告,而后进行人工处理,从而实现网站监管的目的。
技术实现要素:
本发明的目的在于,针对上述现有技术存在的缺陷,提供一种属地网站监管方法,以解决上述问题。
为了实现上述目的,本发明给出以下技术方案:
一种属地网站监管方法,包括建立监管网站库、网站信息采集处理、网站监管识别、违法违规内容预警及处理四个步骤;其中:
(1)建立监管网站库:通过ip段域名反查的形式获得,同时通过工信部网站备案库获取需要监管的备案网站;
(2)网站信息采集处理:监管网站确定后,就要对网站内容进行采集,通过网络爬虫技术采集监管网站的信息,将采集到的信息进行索引存储,为后续的网站监管识别做准备;
(3)网站监管识别:对采集到的网站信息进行网站备案地信息验证,查询是否超出了备案经营范围,以及识别是否有违法违规内容;
(4)违法违规内容预警及处理:对识别出的违法违规网站,进行预警通知和人工处理,同时对工作人员处理的违法违规网站进行处罚记录,形成处罚记录表,便于后期跟进。
作为优选,在上述方法中的步骤(3)中,网站监管识别的具体识别步骤如下:
(5)网站备案数据查询,对采集到的网站信息进行网站自动备案验证,识别所查询的网站是否在工信部备案,对未备案网站进行记录和告警;已备案的网站,则可以对网站备案信息进行查询;
(6)网站违规内容查处,对已备案的网站内容先建立敏感信息规则库进行敏感信息检测,然后进行网站违规内容识别,最后对识别出的的政治类有害信息、淫秽色情信息、低俗信息等违法和不良信息以及有害用户账户注册信息进行人工初筛和电子取证,固化相关证据,防止相关网站和用户自行删除逃避追责。
作为进一步的优选,在上述方法中的步骤(6)中,网站违规内容识别包括规则匹配与机器学习两种识别方式;
规则匹配的识别方式是利用构建的敏感信息规则库对监管网站的内容进行匹配,对于识别出的信息根据敏感信息规则库的领域规则进行分类存放和呈现;
机器学习的识别方式则是通过对规则匹配的识别结果进行有监督的学习来建立相关的识别分类器。
本发明的有益效果是:
通过本发明属地网站监管方法,弥补了现有技术的不足,能够对属地网站信息进行有效快速地采集和违法违规网站的监管识别,解决了网站监管难的问题,提升了信息安全管理水平,大大降低了网站执法人员的工作难度,促进了互联网健康平稳发展。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明属地网站监管方法实施例的流程图。
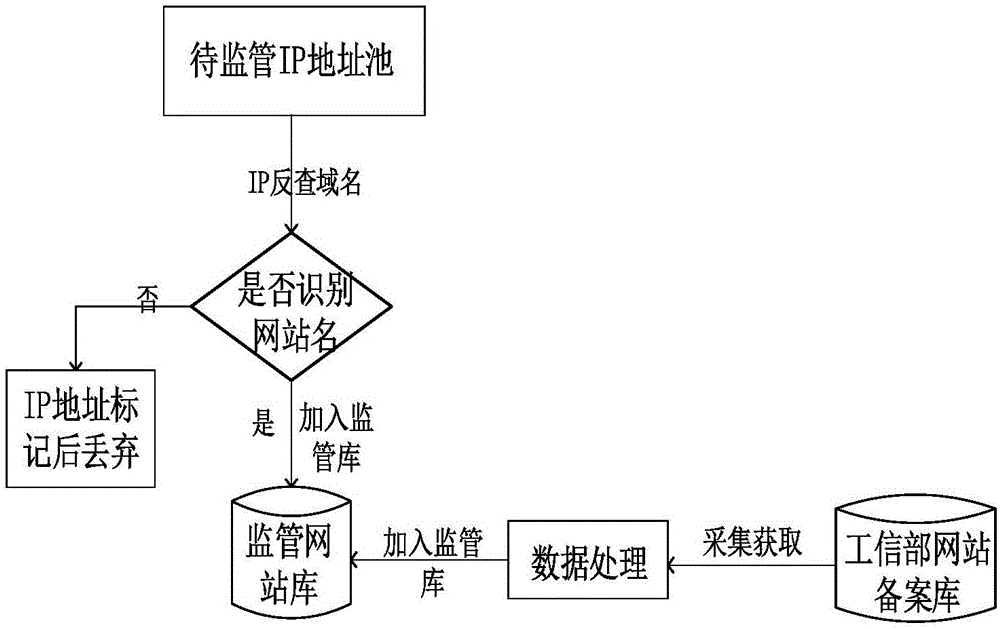
图2是本发明属地网站监管方法实施例的监管网站库建立流程图。
图3是本发明属地网站监管方法实施例的网站信息采集处理流程图。
图4是本发明属地网站监管方法实施例的网站违规内容查处流程图。
图5是本发明属地网站监管方法实施例的违法违规内容预警及处理流程图。
具体实施方式
图1所示,一种属地网站监管方法,主要包括网建立监管网站库、网站信息采集处理、网站监管识别、违法违规内容预警及处理四个步骤:
一、建立监管网站库,主要是通过ip段域名反查的形式获取,同时通过工信部网站备案库获取需要监管的备案网站。具体获取过程是如下几个步骤,如图2所示:
1.从待监管网站ip地址池查看是否识别出网站名,对识别出网站名的网站加入到监管库中,对未识别出网站名的网站对其ip地址标记后丢弃。
2.从工信部网站备案库中采集获取需要监管的备案网站,经数据处理后加入到监管库里。
二、网站信息采集处理,监管网站库建立后,就要对网站内容进行采集处理,整个采集处理过程具体是如下几个步骤,如图3所示:
3.首先通过网络爬虫技术24小时不间断自动、定时地将监管网站库中网站内容进行下载,采用分布式文件系统存储下载的源码信息,为后续的电子取证提供网页源码取证。
4.然后利用数据清洗技术对采集的网站信息进行清洗,获取结构化的文本信息进行收集、整理、归类、保存到数据库中统一管理并进行索引云存储,为后续的网站监管识别做准备。
三、网站监管识别,对采集到的网站信息进行网站自动备案验证,查询是否超出了备案经营范围,以及识别是否有违法违规内容。具体识别过程如下几个步骤:
5.网站备案数据查询,对采集到的网站信息进行网站自动备案验证,识别所查询的网站是否在工信部进行备案,对未备案网站进行记录和告警;已备案的网站,则可以对网站备案信息进行查询,包括网站备案/许可证号、网站名称、网站首页网址、网站域名、网站服务内容、网站负责人姓名、证件号码等。
6.网站违规内容查处,对已备案的网站信息内容进行敏感信息检测、识别是否有违法违规内容,具体过程是如下几个步骤,如图4所示:
(1)建立敏感信息规则库,对索引云存储的文本信息进行违规信息匹配,构建敏感信息规则库,存放有人工处理的分行业领域的相关敏感信息检测规则。
(2)网站违规内容识别,识别方式先是用基于规则匹配的方式进行初步的敏感信息筛选,后续通过机器学习的方式持续动态的对敏感信息库进行调整,同时引入人工定期审核的机制进行修正。
初期通过敏感信息规则库将匹配的信息呈现在用户面前,用户对敏感规则匹配的信息进行筛选分类标记,识别引擎对分类标记的信息进行学习识别后建立相关的违规分类器,形成语料集,中期通过识别引擎学习建立的语料集对新匹配的信息进行违规分类,而后又人工对分类的信息进行二次校对,检验信息的违规分类准确性。对错误的分类进行标注,而后又用识别引擎进行重复学习来修正建立的违规分类器。经过初期、中期的反复学习,进入后期阶段后,就可以完全交由机器进行违规内容的识别,进而输出识别结果。
(3)人工初筛,电子取证,对于识别出的结果在预警前要与本地网站备案数据库信息进行二次比对,比对后要有工作人员对识别结果进行人工初筛,对于不存在违规内容的网站进行标记库识别引擎二次识别;对于存在违法和有害内容的网站,提供网页源码和网页截图两种方式电子取证,固化相关证据。
四、违法违规内容预警及处理,主要是对筛选出的违法违规网站进行预警通知和人工处理。具体处理过程如下几个步骤,如图5所示。
7.预警通知,对筛选出的违规网站要及时预警提醒工作人员,采用的预警方式包括网页弹窗、客户端提醒、邮件等。
8.人工处理,对于存在部分违法和有害内容的网站,将网站标记为灰名单,加入黑白名单库,而后下达整改、处置意见,要求网站进行及时整改,同时程序对标记的网站进行实时跟踪反馈,监测网站管理人员对违法有害内容的整改情况,直到网站整改结束。对于传播违法和有害内容的网站,将网站标记为黑名单,加入黑白名单库,转交相关管理执法部门进行相关处置,同时程序对标记的网站进行实时跟踪反馈,监测网站的处理情况,直到网站处理结束。
9.最后系统对工作人员处理的违规违法网站进行处罚记录,形成处罚记录表,便于后期跟进。
本实施例提供了一个集网站域名自动采集、网站自动备案验证、网站不良信息自动监测三大功能于一体的属地网站监管方法。该方法通过建立监管网站库,经过信息采集,针对不同行业领域建立敏感信息规则库进行监管识别,对识别出的违规网站进行电子取证及预警通告,而后进行人工处理,从而实现网站监管的目的。
以上所述的本发明实施方式,并不构成对本发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!