高可用性系统中的故障处理方法和故障处理集群与流程
本发明涉及通信技术领域,尤指一种高可用性系统中的故障处理方法和故障处理集群。
背景技术:
高可用性集群(highavailable,ha)是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。通常把正在执行业务的称为活动节点,而作为活动节点的一个备份的则称为备用节点。当活动节点出现问题,导致正在运行的业务(任务)不能正常运行时,备用节点此时就会侦测到,并立即接续活动节点来执行业务。从而实现业务的不中断或短暂中断。
但在高可用(ha)系统中,当联系2个节点之间的联系断开时,原本为一整体、动作协调的ha系统,就分裂成为2个独立的个体。由于相互失去了联系,都会认为是对方出了故障。两个节点上的ha软件像“裂脑人”一样,争抢共享资源、争起应用服务,就会发生严重后果,比如,共享资源被瓜分、2边服务都起不来了;或者2个节点服务都起来了,但同时读写共享存储,导致数据损坏,比如hdfs文件系统元数据出错等。
因此,在高可用(ha)系统中,当联系2个节点之间的联系断开时,如何对集群中节点进行管理以保证业务正常运行是亟待解决的问题。
技术实现要素:
为了解决上述技术问题,本发明提供了一种高可用性系统中的故障处理方法和故障处理集群,能够防止高可用集群脑裂现象的产生。
为了达到本发明目的,本发明提供了一种高可用性系统中的故障处理集群,所述故障处理集群中每个节点包括:
获取模块,用于获取高可用性系统中工作集群中的管理对象,其中所述管理对象为工作集群的节点;
监测模块,用于根据预先设置的监测策略,对所述管理对象的运行状态进行监测;
节点管理模块,用于当管理对象中有节点不能因出现故障不能处理业务时,通知出现故障的节点下线。
其中,所述故障处理集群有2n+1个节点,其中一个节点为主节点,其余节点为从节点,n为正整数;其中:
发送模块,用于通知从节点从工作集群中选择代替所述出现故障的节点继续工作的节点;
确定模块,用于根据从节点和主节点的选择结果,确定代替故障节点继续工作的节点;
其中,所述每个节点包括:
选举模块,用于从工作集群中选择代替所述出现故障的节点继续工作的节点,并将选择结果发送给所述主节点。
其中,所述节点管理模块包括:
获取单元,用于获取出现故障节点的节点上基板管理控制器bmc的ip地址信息;
发送单元,用于根据出现故障节点的节点上bmc的ip地址信息,向出现故障的节点的bmc发送关闭电源的指令。
其中,所述每个节点还包括:
告警模块,用于输出出现故障的节点的故障描述信息。
其中,所述每个节点还包括:
策略管理模块,用于在接收到监测策略的更新请求后,根据所述更新请求,对监测策略进行更新,并将更新后的监测策略发送给所述监测模块。
一种高可用性系统中故障处理方法,包括:
故障处理集群获取每个节点在高可用性系统中工作集群对应的管理对象,其中所述管理对象为工作集群的节点;
根据预先设置的监测策略,对所述管理对象的运行状态进行监测;
当管理对象中有节点不能因出现故障不能处理业务时,通知出现故障的节点下线。
其中,所述通知出现故障的节点下线之后,所述方法还包括:
通知各节点从工作集群中选择代替所述出现故障的节点继续工作的节点;
接收各节点发送的选择结果;
根据所述选择结果,确定代替故障节点继续工作的节点,其中所述故障处理集群有2n+1个节点,其中一个节点为主节点,其余节点为从节点,n为正整数。
其中,所述通知出现故障的节点下线包括:
获取出现故障节点的节点上基板管理控制器bmc的ip地址信息;
根据出现故障节点的节点上bmc的ip地址信息,向出现故障的节点的bmc发送关闭电源的指令。
其中,所述通知出现故障的节点下线之后,所述方法还包括:
输出出现故障的节点的故障描述信息。
其中,所述方法还包括:
在接收到监测策略的更新请求后,根据所述更新请求,对监测策略进行更新,并将更新后的监测策略发送给所述监测模块。
本发明提供的实施例,通过对集群节点进行故障诊断,当集群中某节点心跳断开,对故障节点进行关机操作,确保故障节点完全关闭,防止高可用集群脑裂现象的产生。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。
图1为本发明提供的高可用性系统中的故障处理集群中节点的结构图;
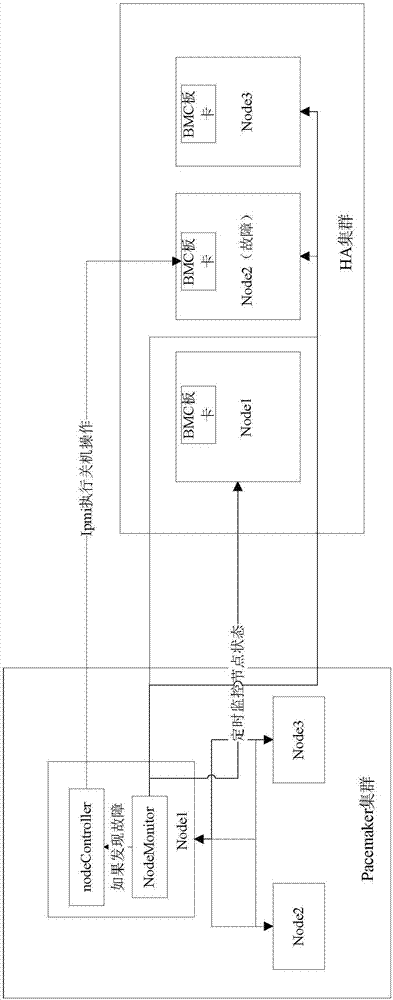
图2为本发明应用实例提供的基于ipmi的高可用集群系统的结构示意图;
图3为在图2系统下故障处理的方法流程图;
图4为本发明提供的高可用性系统中故障处理方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
图1为本发明提供的高可用性系统中的故障处理集群中节点的结构图。图1所示故障处理集群中每个节点包括:
获取模块101,用于获取高可用性系统中工作集群中的管理对象,其中所述管理对象为工作集群的节点;
监测模块102,用于根据预先设置的监测策略,对所述管理对象的运行状态进行监测;
节点管理模块103,用于当管理对象中有节点不能因出现故障不能处理业务时,通知出现故障的节点下线。
本发明提供的故障处理集群,通过对集群节点进行故障诊断,当集群中某节点心跳断开,对故障节点进行关机操作,确保故障节点完全关闭,防止高可用集群脑裂现象的产生。
下面对本发明提供的故障处理集群进行说明:
在检测出工作集群中有出现故障节点后,该故障节点处理的业务需要进行执行,则需要故障处理集群为该故障节点从工作集群中选择一个节点,代替出现故障的节点进行工作。
为保证故障处理集群能够尽快选择出合适的节点,故障处理集群中节点的数量为2n+1个,其中一个节点为主节点,其余节点为从节点,n为正整数;
所述主节点通知从节点从工作集群中选择代替所述出现故障的节点继续工作的节点;
其余的从节点在接收到通知后,从工作集群中选择代替所述出现故障的节点继续工作的节点,并将结果发送给主节点;
主节点根据从节点和主节点的选择结果,选择代替故障节点继续工作的节点。
其中主节点可以将工作集群中节点选择次数最多的节点,作为代替故障节点继续工作的节点。
工作集群中各节点自带的基板管理控制器(baseboardmanagementcontroller,bmc)芯片和管理网,通过智能平台管理接口(intelligentplatformmanagementinterface,ipmi)协议实现具体的虚拟机关机操作。当前绝大部分服务器主板都带有bmc芯片和bmc网口,bmc芯片不依赖于服务器的处理器、bios或操作系统来工作,可谓非常地独立,是一个单独在服务器内运行的无代理管理子系统,只要服务器上电便可开始工作。bmc良好的自治特性便克服了以往基于操作系统的管理方式所受的限制,例如操作系统不响应或未加载的情况下其仍然可以进行开关机、信息提取等操作,并且由于管理网独立组网,在网络稳定性和可达性上一般都要强于业务网,因此对远程服务器的ipmi操作在非极端情况下都是可靠的,这样在故障发生时可以确保节点完全关闭,防止出现脑裂现象。
具体的,所述节点管理模块包括:
获取单元,用于获取出现故障节点的节点上bmc的ip地址信息;
发送单元,用于根据出现故障节点的节点上bmc的ip地址信息,向出现故障的节点的bmc发送关闭电源的指令。
可选的,所述每个节点还包括:
告警模块,用于输出出现故障的节点的故障描述信息。
例如,发出告警提示音,或者,在显示屏幕上输出告警提示信息,其中故障描述信息可以描述节点的标识信息以及节点出现的异常。
当然,监测策略是可以动态更新的,用户可以自定义,也可以根据业务的需要进行动态修改,因此所述每个节点还包括:
策略管理模块,用于在接收到监测策略的更新请求后,根据所述更新请求,对监测策略进行更新,并将更新后的监测策略发送给所述监测模块。
在实际应用中,可以通过节点状态监控脚本和合理的逻辑严密的节点控制脚本,使得ha集群的节点发生故障后,可以自动进行故障节点的关机隔离,弥补了原生ha软件不能确保故障节点隔离、容易产生脑裂现象的问题,并且通过不断的累积监控方式,可以达到多种条件的故障综合判断,比如cpu利用率、内存利用率等性能信息,java进程是否正常、节点上应用进程是否正常等条件,都可以加入监控列表中,并且通过ipmi协议对故障节点执行强制的关机操作,避免了ha方案中经常出现的脑裂现象,达到ha方案可灵活定制、高可靠运行的效果。
下面结合具体应用实例进行说明:
本发明采用pacemaker作为故障探测和恢复的控制器。pacemaker可以自行管理一个集群,在集群上创建pacemaker的ocf资源,并保证这个ocf资源本身的集群间选举、飘移和高可用。因此我们使用ocf脚本来做openstack的监控器,其本身也是高可用的;
pacemaker的资源主要有两类,分别为lsb(linuxstandardsbase,linux标准服务)和ocf(openclusterframework,开放集群框架)。其中lsb资源通常就是/etc/init.d目录下的脚本,pacemaker可以用这些脚本来启停服务。ocf资源是对lsb服务的扩展,增加了一些高可用集群理的功能如故障监控等和更多的元信息,作为具体故障探测的实现方式。pacemaker通过实现一个ocf资源,可以很好的对服务进行高可用保障。
本发明提供的基于ipmi的高可用集群防脑裂实现方案:
图2为本发明应用实例提供的基于ipmi的高可用集群系统的结构示意图。该系统的部署如下:
选择至少高可用系统中3个节点,安装pacemaker集群软件以及安装ipmitool,其中ipmitool用于远程管理节点;其中之所以选择3个节点是为了保证pacemaker资源选举主节点时的投票能产生多数;
将安装了pacemaker软件的节点互相认证,配置成一个整体,完成pacemaker集群的创建;
创建自动监控节点状态的ocf脚本nodemonitor,并上传至pacemaker集群中每个节点的/usr/lib/ocf/resource.d/openstack/目录下,其中该ocf脚本能够实现对节点进行开机、关机、查看状态、监控资源的操作等;通过使用符合ocf脚本规范的格式编写节点状态监控脚本,可以灵活利用pacemaker本身的资源高可用、定时调度和管理资源、以及大量已有的linuxocf脚本,实现监控程序本身的灵活与高可用;
当然,在ocf脚本内部可以自定义monitor方法,实现多种监测条件,可根据业务灵活定制,达到条件限制后即可触发虚拟机的疏散。方法包括但不限于:检查节点上业务网卡的状态;检查节点上指定应用进程的状态;检查该节点的性能数据,如cpu利用率、内存利用率等;检查该节点上的存储空间状态等。
创建具体执行节点关机操作的脚本nodecontroller,并上传至pacemaker用户有权限操作的目录下,如/usr/lib/myscript/;该脚本需要输入节点bmcip地址、账号、密码;
使用该ocf脚本创建一个pacemaker资源;pacemaker资源相当于一个由pacemaker集群来保证执行和监控状态的服务实例,每个资源本身可能在pacemaker集群的各个节点上经选举而启动,并按照资源内部定义的逻辑,由pacemaker框架执行相应的动作,例如,在ocf的meta标签中定义操作的执行间隔和超时时间。
图3为在图2系统下故障处理的方法流程图。图2所示方法包括:
系统启动后,pacemaker按设定的时间间隔定时执行脚本的monitor方法,该方法可以由业务人员自行定义,用于判断节点是否故障,例如pingip、访问某业务接口、ssh连接、访问数据库连接等;
当nodemonitor脚本判断某节点故障,则调用ipmitool,利用现有的bmc管理网远程控制节点电源,对远程故障节点进行关机操作,不需要额外增加设备;同时使用pacemaker的attrd_updater接口将故障节点置为无效,以触发pacemaker的主节点选举流程。
由上可以看出,本发明应用实例提供一种基于ipmi的高可用集群防脑裂方案,通过使用开源的pacemaker作为ha集群的故障探测中心,使用ocf脚本作为监控方法,利用多种手段探测节点的故障信息,利用服务器板卡自身提供的bmc管理接口隔离故障节点,可以快速而可靠的将故障节点从ha集群中分离,完善的保证分布式业务运行过程中的数据完整性,防止脑裂现象的产生,弥补当前ha整体解决方案中对故障节点隔离不彻底的问题,更完善的监控业务运行过程中的问题,大大保护业务数据的完整性性。
图4为本发明提供的高可用性系统中故障处理方法的流程图。图4所示方法包括:
步骤401、获取每个节点在高可用性系统中工作集群对应的管理对象,其中所述管理对象为工作集群的节点;
步骤402、根据预先设置的监测策略,对所述管理对象的运行状态进行监测;
步骤403、当管理对象中有节点不能因出现故障不能处理业务时,通知出现故障的节点下线。
其中,所述通知出现故障的节点下线之后,所述方法还包括:
通知各节点从工作集群中选择代替所述出现故障的节点继续工作的节点;
接收各节点发送的选择结果;
根据所述选择结果,确定代替故障节点继续工作的节点,其中所述故障处理集群有2n+1个节点,其中一个节点为主节点,其余节点为从节点,n为正整数。
其中,所述通知出现故障的节点下线包括:
获取出现故障节点的节点上基板管理控制器bmc的ip地址信息;
根据出现故障节点的节点上bmc的ip地址信息,向出现故障的节点的bmc发送关闭电源的指令。
其中,所述通知出现故障的节点下线之后,所述方法还包括:
输出出现故障的节点的故障描述信息。
可选的,所述方法还包括:
在接收到监测策略的更新请求后,根据所述更新请求,对监测策略进行更新,并将更新后的监测策略发送给所述监测模块。
本发明提供的故障处理方法,通过对集群节点进行故障诊断,当集群中某节点心跳断开,对故障节点进行关机操作,确保故障节点完全关闭,防止高可用集群脑裂现象的产生。
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!