一种字幕内容的纠错方法和装置与流程
本发明实施例涉及多媒体技术,尤其涉及一种字幕内容的纠错方法和装置。
背景技术:
通常在音视频的字幕制作时,一般是一边看视频或者边听音频,一边录入字幕文本,而录好的字幕文本内容是否与视频中的音频内容相符或对应,影响用户观看视频或收听音频的体验。
现有技术中通常是人工去检查,反复核对去发现问题。人工纠错带来的结果是效率地下,投入成本高。
技术实现要素:
本发明实施例提供一种字幕内容的纠错方法和装置,实现了对字幕内容的智能纠错,解决人工纠错效率低下以及投入成本高的问题。
第一方面,本发明实施例提供了一种字幕内容的纠错方法,所述方法包括:
提取视频文件中目标字幕条对应的第一文本信息;
识别所述目标字幕条的音频信息得到对应的第二文本信息;
将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
进一步的,所述提取视频文件中目标字幕条的第一文本信息包括:
判断当前图像帧是否有字幕,若是,则确定所述字幕条的位置以及所述字幕条的起始帧和终止帧;
提取所述字幕条的第一文本信息。
进一步的,所述识别所述目标字幕条的音频信息对应的第二文本信息包括:
根据所述起始帧和所述终止帧确定时间间隔;
根据所述时间间隔解析和切割视频中的音频信息;
将解析和切割后的音频信息与预设文本库进行比对,识别所述音频信息对应的第二文本信息。
进一步的,所述将所述第一文本信息和所述第二文本信息通过文本比对进行纠错,输出纠错结果包括:
将所述第一文本信息和所述第二文本信息以字或词语为单位一一进行比对;
记录所述第二文本中与所述第一文本不同的字或词语;
将所述字或词语作为纠错结果进行输出。
进一步的,所述预设文本库存储在与语音识别模块相连的服务器中。
第二方面,本发明实施例提供了一种字幕内容的纠错装置,所述装置包括:
信息提取模块,用于提取视频文件中目标字幕条对应的第一文本信息;
信息识别模块,识别所述目标字幕条的音频信息得到对应的第二文本信息;
信息比对模块,用于将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
进一步的,所述信息提取模块具体用于:
判断当前图像帧是否有字幕,若是,则确定所述字幕条的位置以及所述字幕条的起始帧和终止帧;
提取所述字幕条的第一文本信息。
进一步的,所述信息识别模块具体用于:
根据所述起始帧和所述终止帧确定时间间隔;
根据所述时间间隔解析和切割视频中的音频信息;
将解析和切割后的音频信息与预设文本库进行比对,识别所述音频信息对应的第二文本信息。
进一步的,所述信息比对模块具体用于:
将所述第一文本信息和所述第二文本信息以字或词语为单位一一进行比对;
记录所述第二文本中与所述第一文本不同的字或词语;
将所述字或词语作为纠错结果进行输出。
进一步的,所述预设文本库存储在与语音识别模块相连的服务器中。
本发明实施例中,提取视频文件中目标字幕条对应的第一文本信息;识别所述目标字幕条的音频信息得到对应的第二文本信息;将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。实现了对字幕内容的智能纠错,解决人工纠错效率低下以及投入成本高的问题。
附图说明
图1是本发明实施例一中的一种字幕内容的纠错方法的流程图;
图2是本发明实施例二中的一种字幕内容的纠错方法的流程图;
图3是本发明实施例三中的一种字幕内容的纠错方法的流程图;
图4是本发明实施例四中的一种字幕内容的纠错装置的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种字幕内容的纠错方法的流程图,本实施例可适用于对字幕内容进行纠错的情况,该方法可以由本发明是实施例提供的一种字幕内容的纠错装置来执行,该装置可采用软件和/或硬件的方式实现。参考图1,该方法具体可以包括如下步骤:
s110、提取视频文件中目标字幕条对应的第一文本信息。
具体的,用户观看视频的过程中,需要结合视频中的字幕信息和用户听到的音频信息来欣赏视频中的画面。通常字幕条位于用户观看画面的整个屏幕的中下部,在视频播放的过程中,会出现多个字幕条,在多个字幕条中根据用户的需求确定至少一个字幕条为目标字幕条,提取视频文件中目标字幕条对应的第一文本信息。其中,第一文本信息与目标字幕条上的字幕一一对应。
可选的,利用纹理去噪方法提取目标字幕条对应的第一文本信息。具体过程如下:求存在同一条字幕的多帧图像帧亮度图像的字幕条区域的平均和图像;将平均和图像进行通过最大类间方差法进行分割,生成只有黑白两种颜色连通域的字幕区域图像;对最大类间方差法分割后的图像确定哪种颜色为文字区域;最后剔除非文字噪声。
s120、识别所述目标字幕条的音频信息得到对应的第二文本信息。
其中,对目标字幕条对应的音频信息进行语音识别,识别结果标记为第二文本信息,其中,第二文本信息与目标字幕条的音频信息相对应。
s130、将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
具体的,将第一文本信息与第二文本信息通过文本比对方法进行纠错,可选的,由于第二文本信息为对音频信息进行语音识别获得,可以将第二文本信息作为目标文本信息,将第一文本信息与目标文本信息进行比对。比对结果中,将两个文本信息中不同的部分定义为错误部分,也即,纠错结果,然后输出纠错结果。
本发明实施例中,提取视频文件中目标字幕条对应的第一文本信息;识别所述目标字幕条的音频信息得到对应的第二文本信息;将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。实现了对字幕内容的智能纠错,解决人工纠错效率低下以及投入成本高的问题。
在上述技术方案的基础上,“将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果”具体可以是:
将所述第一文本信息和所述第二文本信息以字或词语为单位一一进行比对;记录所述第二文本信息中与所述第一文本信息不同的字或词语;将所述字或词语作为纠错结果进行输出。
可选的,在对文本的具体纠错实现方式上,可以将第一文本信息和第二文本信息以字或词语为单位一一进行比对。在一个具体的例子中,词语可以是短词语或者长词语,对具体的词语长度不做具体限定。需要说明的是,词语的长度越短,比对的结果越准确。对比对不同的字或词语进行记录,将记录结果作为进错结果进行输出。
实施例二
图2为本发明实施例二提供的一种字幕内容的纠错方法的流程图,本实施例在上述实施例的基础上,对“提取视频文件中目标字幕条的第一文本信息”进行了优化。参考图2,该方法具体可以包括如下步骤:
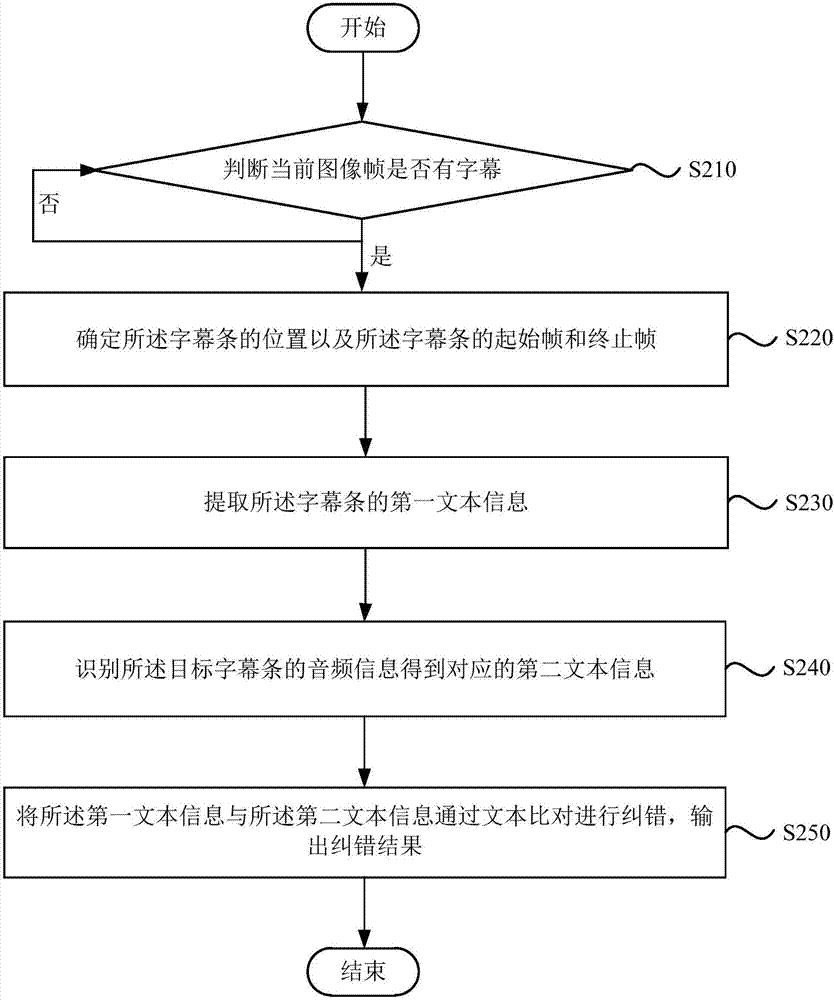
s210、判断当前图像帧是否有字幕,若是,则执行s220,若否,则返回执行s210。
具体的,根据正在播放的视频中确定当前的图像帧,并判断当前的图像帧中行是否有字幕,如果没有字幕,则返回继续判断当前图像帧是否有字幕,直到有字幕出现。
s220、确定所述字幕条的位置以及所述字幕条的起始帧和终止帧。
具体的,确定字幕条的位置时,首先采集图像帧的亮度图像,生成纹理图,通过垂直纹理图水平投影求差分,先确定水平字幕条的上下边框,再确定水平字幕条的左右边框,从而确定字幕条的水平位置;接着确定垂直字幕条的位置,通过水平纹理图垂直投影求查分,先确定垂直字幕条左右边框,再确定垂直字幕条上下边框,最后进行字幕条去噪,确定字幕条的位置。
其中,如果出现字幕条,设当前图像帧为字幕条关键帧,则在前一个关键帧和该字幕条关键帧之间确定字幕条的起始帧,然后该字幕条关键帧的字幕条区域依次匹配后面的关键帧,如果匹配一致,则继续匹配,直到匹配不一致,则在前一个关键帧和当前关键帧确定字幕条的终止帧。
s230、提取所述字幕条的第一文本信息。
s240、识别所述目标字幕条的音频信息得到对应的第二文本信息。
s250、将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
本发明实施例中,通过判断当前图像帧中是否有字幕,若有,则确定字幕条的位置以及该字幕条的起始帧和终止帧,若没有则一直进行判断直到检测到存在字幕为止。通过字幕条的起始帧和终止帧的判断,实现了对字幕条中字幕信息的提取。
实施例三
图3为本发明实施例三提供的一种字幕内容的纠错方法的流程图,本实施例在上述实施例的基础上,对“识别所述目标字幕条的音频信息对应的第二文本信息”进行了优化。参考图3,该方法具体可以包括如下步骤:
s310、判断当前图像帧是否有字幕,若是,则执行s320,若否,则返回执行s310。
s320、确定所述字幕条的位置以及所述字幕条的起始帧和终止帧。
s330、提取所述字幕条的第一文本信息。
s340、根据所述起始帧和所述终止帧确定时间间隔。
具体的,根据起始帧和终止帧确定一个时间间隔,给时间间隔可以即为t,也即,从同一个字幕条的起始帧到终止帧的时间为t。
s350、根据所述时间间隔解析和切割视频中的音频信息。
其中,以确定的时间间隔为基准,对视频中的音频信息进行解析和分割。在一个具体的例子中,将视频以时间间隔t为基准,将视频中的音频进行分割成若干段音频信息,并对分割后的音频信息进行解析。
s360、将解析和切割后的音频信息与预设文本库进行比对,识别所述音频信息对应的第二文本信息。
具体的,将解析和切割后的音频信息与预设文本库进行比对,可选的,预设文本库可以通过语音识别功能获得,在一个具体的例子中,可以通过调用科大讯飞语音识别的开源接口来获得。其中,预设文本库中存储有各音频内容和与其对应的文本信息的对应关系。将解析和切割后的音频信息与预设文本库进行比对,识别音频信息对应的第二文本信息。
可选的,所述预设文本库存储在与语音识别模块相连的服务器中。
其中,语音识别模块与服务器相连,预设文本库存储在该服务器中。服务器中存储有该预设文本,实现了根据用于需求对预设文本库的实时调用。
s370、将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
本发明实施例中,首选图像帧的起始帧和所述终止帧确定时间间隔,并根据所述时间间隔解析和切割视频中的音频信息,将解析和切割后的音频信息与预设文本库进行比对,识别所述音频信息对应的第二文本信息。实现了对音频信息对应的第二文本信息的识别。
实施例四
图4是本发明是实施例四提供的一种字幕内容的纠错装置的结构示意图,该装置适用于执行本发明实施例提供给的一种字幕内容的纠错方法。如图4所示,该装置具体可以包括:
信息提取模块410,用于提取视频文件中目标字幕条对应的第一文本信息;
信息识别模块420,识别所述目标字幕条的音频信息得到对应的第二文本信息;
信息比对模块430,用于将所述第一文本信息与所述第二文本信息通过文本比对进行纠错,输出纠错结果。
进一步的,信息提取模块410具体用于:
判断当前图像帧是否有字幕,若是,则确定所述字幕条的位置以及所述字幕条的起始帧和终止帧;
提取所述字幕条的第一文本信息。
进一步的,信息识别模块420具体用于:
根据所述起始帧和所述终止帧确定时间间隔;
根据所述时间间隔解析和切割视频中的音频信息;
将解析和切割后的音频信息与预设文本库进行比对,识别所述音频信息对应的第二文本信息。
进一步的,信息比对模块430具体用于:
将所述第一文本信息和所述第二文本信息以字或词语为单位一一进行比对;
记录所述第二文本中与所述第一文本不同的字或词语;
将所述字或词语作为纠错结果进行输出。
进一步的,所述预设文本库存储在与语音识别模块相连的服务器中。
本发明实施例提供的字幕内容的纠错装置可执行本发明任意实施例提供的字幕内容的纠错方法,具备执行方法相应的功能模块和有益效果。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!