一种智能家居系统中的个性化服务定制方法与流程
本发明属于智能家居领域,尤其涉及一种智能家居系统中的个性化服务定制方法。
背景技术:
随着智能家居技术的发展和应用的普及,用户越来越依赖于智能家居系统,同时智能家居系统收集到的用户数据越来越多。改善智能家居用户体验的途径逐渐由传统的功能性增加转向个性化的服务定制,即根据用户的生活习惯提供个性化的智能家居服务,而忽略用户不感兴趣的服务,从而优化用户对智能家居系统的使用体验。
现有的智能家居系统逐渐由专用型向通用型发展,将电器控制、环境监测、数据分析等各项功能整合到一个系统中,提供大量通用的智能家居服务,这些服务的种类越来越多,控制越来越精细,操作越来越复杂。然而对于很多用户而言,通常只对其中的部分服务感兴趣,而对于有些服务不感兴趣甚至可能完全不使用。现有的智能家居系统提供给每个用户的服务均是所有可用的服务,用户需要花大量的时间去摸索哪些服务是自己感兴趣的,并且每次使用这些服务时均需要从系统提供的大量服务中慢慢搜索寻找这些服务,降低了智能家居系统的用户体验。
在智能家居系统中个性化的服务定制需要根据用户信息预测其对智能家居系统提供的各种服务的兴趣度,对用户兴趣度较高的应用重点推荐,方便用户的使用,而对于用户兴趣度较低的应用进行隐藏,只有用户主动提出使用需求时再显式提供该服务。个性化的服务定制可以加快用户和智能家居系统之间的交互,提高智能家居系统的用户体验。现有的智能家居系统中提高用户体验的方式主要有三种:一是对各种专用的智能家居服务的整合,用一个系统实现多种智能控制,如将空调、冰箱、电饭煲、窗帘和电灯等设备的控制整合到一个智能家居系统中;二是预定义场景模式实现对家居环境的一键式控制,如用户可以预先设置会客模式、娱乐模式等不同的场景,以及每个场景中需要控制的各类设备状态,使用时只需选择场景即可实现对多种设备的控制;三是优化各类服务的效率和质量,主要优化控制策略、数据处理算法、用户界面等,如设计更高效的算法实现对空调制冷效果、时间和耗电量之间的均衡。
现有的各类提高智能家居系统用户体验的方法尽管提供了更全面的系统功能和更高效的服务质量,但也会导致智能家居系统中的各类服务越来越多,用户很难在短时间内发现哪些服务是自己感兴趣的,而且也很难在每次使用时能够快速找到自己感兴趣的服务。
智能家居系统中现有的提高用户体验的方法主要包括功能整合、控制整合和服务优化三类。功能整合类方法将各种各样的智能家居服务整合到同一个系统中,便于系统管理和用户使用,但是由于智能家居系统服务太多而导致用户很难快速确定哪些服务是自己感兴趣的,需要多次尝试才能找到用户兴趣度较高的服务。而且,在每次使用智能家居系统时,即便用户确定了感兴趣的服务,也很难快速地在大量服务中找到自己需要的服务。控制整合类和服务优化类方法主要用用于提高服务的执行效率,与用户的个性化的服务定制没有直接关系。
在实现智能家居系统中个性化的服务定制过程中最重要的步骤是预测用户对每个服务的兴趣度。用户兴趣度的预测在智能家居系统中研究较多,通常采用机器学习中各类经典的预测方法,通过对大量历史数据的训练得到预测模型,再根据预测模型进行特定用户的兴趣度预测。但是智能家居系统中现有的用户兴趣度预测方法在训练数据集增量更新的情况下需要对更新后的训练数据集进行重新训练得到新的预测模型。但是在智能家居系统中训练数据集持续更新且数据集的规模越来越大,现有的预测方法在每次重新计算预测模型时需要耗费大量的空间和时间代价,尤其当训练数据集规模很大时,现有的预测方法无法快速得到新的预测模型。
技术实现要素:
本发明主要解决在智能家居系统中如何进行个性化的服务定制,减少用户与智能家居系统的交互时间,提高用户体验。具体而言,本发明要解决的问题包括如下三个方面:一是如何通过预测用户对智能家居服务的兴趣度而提高智能家居系统的用户体验;二是如何从智能家居服务使用的历史数据中快速获得精度较高的用户兴趣度预测模型;三是当训练集发生增量更新时,如何只分析增量数据以及原始的预测模型而快速获取新的用户兴趣度预测模型,而无需对所有训练数据集进行重新计算。
本发明的目的是通过以下技术方案来实现的:本发明所述的智能家居系统中个性化服务定制方法主要通过预测每个用户对智能家居系统中的诸多服务的兴趣度来实现个性化的服务定制,即重点推荐用户感兴趣的服务,隐藏用户不感兴趣的服务,避免用户每次使用智能家居系统时均需要从大量的服务中选择感兴趣的服务,减少用户与智能家居系统的交互时间,从而提高用户体验。
本发明所述的智能家居系统中个性化服务定制方法的总体流程主要分为三个步骤:首先根据各项服务的历史使用数据计算出每个服务的用户兴趣度预测模型,再根据当前用户信息计算出该用户对所有服务的兴趣度;然后将这些服务按该用户的兴趣度降序排列;最后对系统进行优化,对兴趣度较高的服务向用户重点推荐,保证用户每次使用智能家居系统时均能够快速找到其感兴趣的服务,而对于兴趣度较低的服务则进行隐藏处理,当用户需要使用时再打开隐藏选项寻找需要使用的服务。
本发明所述的智能家居系统中个性化服务定制方法中的用户偏好预测,需要预测用户对智能家居系统中每一项服务的兴趣度。预测用户对某项服务的兴趣度包含如下步骤:
步骤1:预测模型的建立。假设该服务的使用情况数据集d包含n条记录,每条数据表示一个用户useri对该服务的使用情况,具体格式为(yi,xi),其中xi=(xi1,xi2,...,xit)表示与是否使用该服务有关系的用户属性,如年龄、收入等,yi为0-1变量,1表示用户useri使用该项服务,0表示用户useri不使用该项服务。采用逻辑回归的方法对数据集d进行分析,回归系数θ=(θ0,θ1,…,θt)。对于给定的数据集d而言,采用数值分析的牛顿迭代法(newton-raphsonmethod)求解方程组
步骤2:根据当前用户user的个人信息xu=(xu1,xu2,...,xut),以及最优的回归系数
步骤3:求解数据集d的预测模型的参数
步骤4:数据集d增量更新后计算新的预测模型。
本发明所述的对数据集d的增量更新包括两类:一是增量类更新,即d′=d∪δd,其中数据集d的预测模型已知,而增量数据集δd和更新后的数据集d'的预测模型均未知,如周一到周六的用户数据集d已分析得到预测模型,而周日的数据δd刚刚更新,如何对本周(周一到周日)的数据d'建立预测模型;二是聚集类更新,即d′=d1∪d2∪…∪dk,其中数据集d1、d2、dk等的预测模型均已知,而更新后d'的预测模型未知,智能家居系统中的聚集类更新包括时间维度和空间维度的数据聚集,如过去一周内k个城市的数据集均已建立预测模型,如何得到过去一周内整个地域(包括k个城市)的数据的预测模型。
对于聚集类更新d′=d1∪d2∪…∪dk,若数据集d1、d2、...、dk的预测模型分别为{r1,r2,...,rk},而聚集后的数据集d'的预测模型为ra。其中r1、r2、...、rk已知,而ra未知。求解ra的步骤如下:
4.1:对于已知数据集dk的预测模型rk而言,在步骤1和步骤3中已经得到回归系数和参数
4.2:求解聚集后的数据集d'的预测模型为ra的参数
在第一增量类更新d′=d∪δd中,可以根据步骤1和步骤3先求解更新量的回归系数
本发明的有益效果是:
1.本发明所述方法通过对智能家居系统中服务使用的历史数据进行分析,预测用户对每个服务的兴趣度,从而提供个性化服务定制以减少智能家居系统与用户的交互时间,不会影响现有的智能家居系统中各项服务的功能和性能。
2.本发明所述方法中采用增量式的回归分析方法实现对用户兴趣度的预测,可以保证在数据量增加或者数据聚集时能够根据现有的预测模型计算出新的用户兴趣度预测模型,既减少了预测模型计算的时间和空间代价,也可以保证新的预测模型的有效性。
3.本发明所述方法的使用范围广泛,既可以应用于智能家居系统中的个性化服务定制,也可以应用于智能家居系统中特定服务的个性化功能定制。
附图说明
图1为智能家居系统中个性化服务定制方法的总体流程图;
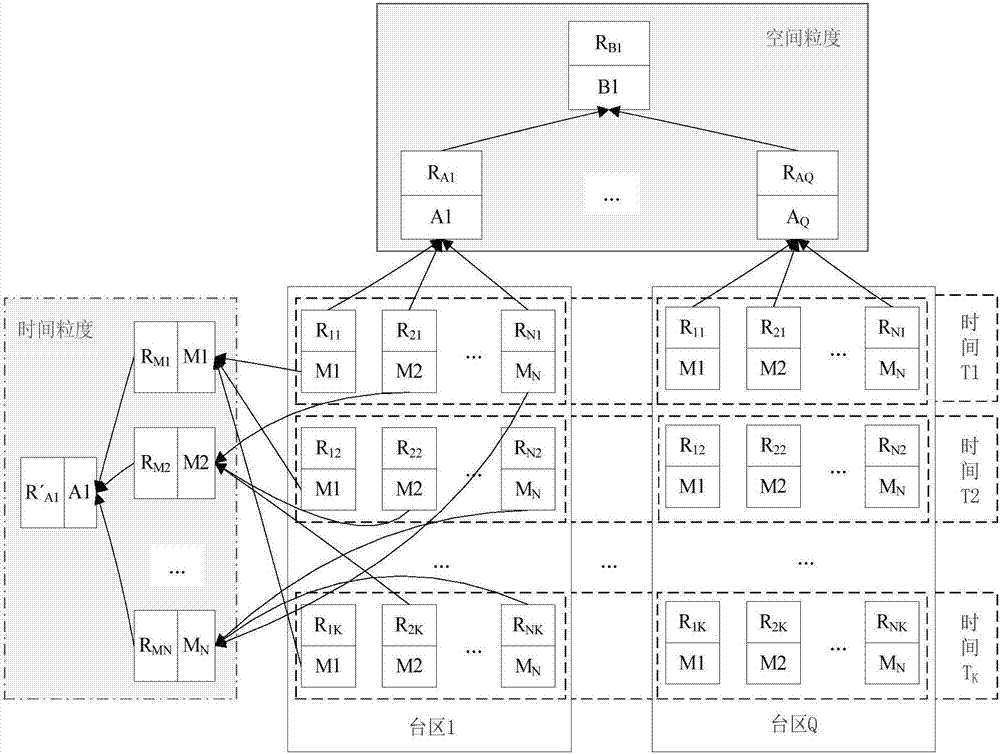
图2为智能家居系统中在时间维度和空间维度上进行数据聚集时用户兴趣度预测模型的增量更新示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
图1为智能家居系统中个性化服务定制方法的总体流程,对智能家居系统中每个服务的用户使用数据集采用逻辑回归的方法建立用户对每个服务的兴趣度的预测模型,当用户使用数据集增量更新或者进行数据聚集时再进行预测模型的更新。对于当前的智能家居系统用户而言,根据用户信息和当前的每个服务的用户兴趣度预测模型,预测用户对每个用户的兴趣度,再将这些应用按照预测出的兴趣度的降序排序,最后进行智能家居系统的个性化服务定制,即重点推荐兴趣度较高的服务。预测用户对某项服务的兴趣度具体包含如下步骤:
步骤1:预测模型的建立。假设该服务的使用情况数据集d包含n条记录,每条数据表示一个用户useri对该服务的使用情况,具体格式为(yi,xi),其中xi=(xi1,xi2,...,xit)表示与是否使用该服务有关系的用户属性,如年龄、收入等,yi为0-1变量,1表示用户useri使用该项服务,0表示用户useri不使用该项服务。采用逻辑回归的方法对数据集d进行分析,回归系数θ=(θ0,θ1,…,θt)。对于给定的数据集d而言,采用数值分析的牛顿迭代法(newton-raphsonmethod)求解方程组
步骤2:根据当前用户user的个人信息xu=(xu1,xu2,...,xut),以及最优的回归系数
步骤3:求解数据集d的预测模型的参数
步骤4:数据集d增量更新后计算新的预测模型。
本发明所述的对数据集d的增量更新包括两类:一是增量类更新,即d′=d∪δd,其中数据集d的预测模型已知,而增量数据集δd和更新后的数据集d'的预测模型均未知,如周一到周六的用户数据集d已分析得到预测模型,而周日的数据δd刚刚更新,如何对本周(周一到周日)的数据d'建立预测模型;二是聚集类更新,即d′=d1∪d2∪…∪dk,其中数据集d1、d2、dk等的预测模型均已知,而更新后d'的预测模型未知,智能家居系统中的聚集类更新包括时间维度和空间维度的数据聚集,如过去一周内k个城市的数据集均已建立预测模型,如何得到过去一周内整个地域(包括k个城市)的数据的预测模型。
对于聚集类更新d′=d1∪d2∪…∪dk,若数据集d1、d2、...、dk的预测模型分别为{r1,r2,...,rk},而聚集后的数据集d'的预测模型为ra。其中r1、r2、...、rk已知,而ra未知。求解ra的步骤如下:
4.1:对于已知数据集dk的预测模型rk而言,在步骤1和步骤3中已经得到回归系数和参数
4.2:求解聚集后的数据集d'的预测模型为ra的参数
在第一增量类更新d′=d∪δd中,可以根据步骤1和步骤3先求解更新量的回归系数
图2为智能家居系统中在时间维度和空间维度上进行数据聚集时用户兴趣度预测模型的增量更新。在时间维度上的兴趣度预测模型的增量更新如图2左侧阴影框所示,对于某个区域而言,如地区1的区域m1,若时间t1...tk分别代表每一天,根据该区域每天产生的智能家居服务使用情况计算得到的预测模型分别为{r11,r12,...,r1k}。若要对该区域一周内的智能家居服务使用情况进行分析,即k=7,则需要根据已知的预测模型{r11,r12,...,r1k},计算得到更新后的预测模型rm1。若要对整个地区1一周内的智能家居服务使用情况进行分析,则需要根据预测模型{rm1,rm2,...,rmn}进一步计算得到新的预测模型r′a1。
在空间维度上的用电行为分析如图2上方阴影框所示,对时间t1内的地区1而言,对每个区域在时间t1的智能家居服务使用情况进行分析得到n个区域的兴趣度预测模型{r11,r21,...,rn1},对其进行预测模型的增量更新计算后,可以得到进行空间聚集后的整个地区1在时间t1内的智能家居系统服务使用数据的用户兴趣度预测模型ra1。若要对所有地区的智能家居系统服务使用情况进行分析,则需要再根据q个地区在t1时刻的用户兴趣度预测模型{ra1,ra2,...,raq}进行计算,得到所有地区在t1时刻的预测模型rb1。
本发明方法可以用户信息自主进行个性化的服务定制,加快用户与智能家居系统的交互速度,提高智能家居系统的用户体验。用户兴趣度预测模型在训练集增量更新时可以直接进行预测模型的增量式更新,而无需在每次增量更新时对整个数据集进行预测模型的重新计算,既保证了预测模型的有效性也提高了预测模型的更新效率。本发明方法在训练集数据在空间维度和时间维度进行数据聚集后可以直接进行预测模型的更新,无需进行训练集的数据聚集后再进行预测模型的重新计算。本发明方法不仅适用于对智能家居系统中各项服务的个性化选择,也可以用于单个智能家居服务中各项服务功能的个性化选择。
- 还没有人留言评论。精彩留言会获得点赞!