基于编码矩阵特性的LT码编译码方法与流程
本发明涉及信道编码领域,尤其涉及一种基于编码矩阵特性的lt码编译码方法。
背景技术:
lt(lubytransform)码是一种稀疏线性分组喷泉码。线性分组喷泉码都具有一个明显的特点是:在编码过程中,会生成一个编码矩阵来表示编码包和与其相连接的输入包的连接关系。把这些连接信息传递给译码端的方法有许多,例如,可以将这些信息放到编码包的头部位置,或者将产生度和“邻接”的伪随机数发生器的种子事先告知对方,收发双方可以通过同步来实现成功译码。
传统的lt码编译码算法是一种次优方法,复杂度较低,但一定程度上降低了译码成功率。因此,考虑一种基于编码矩阵特性的lt码的编译码方法,旨在提高译码成功率,降低误码率。
技术实现要素:
本发明的发明目的在于提供一种基于编码矩阵特性的lt码的编译码方法,来实现信息在二进制删除信道(binaryerasurechannel,bec)中的可靠传输。
本发明解决其技术问题所采用的技术方案是:
提供一种基于编码矩阵特性的lt码编码方法,包括以下步骤:
接收原始数据的输入包;
将输入包组成一个k×l的矩阵sk×l,将矩阵sk×l的每一列即存储列依次作为编码矩阵gk×n的附加列,生成新的编码矩阵gk×(n+l),新编码矩阵的行数仍为k,列数增加了l列;
在编码矩阵gk×(n+l)的第k行后增加标志行,对标志行进行标注并存储到标志行中;
经标注和存储后,产生新的编码矩阵g(k+num)×(n+l),其中num为标志行的行数;
将新的编码矩阵g(k+num)×(n+l)生成编码包,并将编码包发送出去。
接上述技术方案,具体采用十进制数字对矩阵sk×l的列顺序进行从低到高标注,然后将十进制转换为二进制;标志行的行数由二进制标志的位数确定,将这些二进制标志分别存储于各个存储列对应的标志行中,而其他列对应的标志行的每个元素设置为0。
接上述技术方案,设置存储列对应的编码包中每bit都为1。
本发明还提供了一种基于上述编码方法的译码方法,包括以下步骤:
接收端接收到n个编码包;
重构编码矩阵g′(k+2)×n;
检测重构后的编码矩阵中的标志行,找到携带存储信息的存储列;
取出每个携带标志信息的存储列中的标志行;
根据取出的标志行判断接收到的存储包是否丢失,存储包为对应于每个存储列的编码包;如果部分存储包丢失,首先,去掉重构后的编码矩阵中的存储列和标志行,构成新的编码矩阵g′k×n,同时去掉存储列对应的编码包;然后,基于重构矩阵g′k×n和对应的编码包,采用置信传播bp算法进行译码;最后,根据存储列恢复输入包中某些未译出的bit。
接上述技术方案,取出标志行后还包括步骤:将二进制的标志行转换为十进制,将所有存储列按照对应的十进制标志进行升序排列,构成矩阵s′k×l′,通过矩阵s′k×l′恢复输入包中某些未译出的bit。
接上述技术方案,如果全部存储包被接收到,则通过矩阵s′k×l′直接得到所有原始数据,无需进行译码过程。
接上述技术方案,如果全部存储包被删除,则采用置信传播bp算法进行译码。
接上述技术方案,检测附加行重构后的编码矩阵中的标志行时,标志行中为“1”的元素对应的列为携带存储信息的存储列。
本发明还提供了一种存储装置,该存储装置内存储有上述技术方案的基于编码矩阵特性的lt码编码方法的程序。
本发明还提供了一种存储装置,该存储装置内存储有上述技术方案的基于编码矩阵特性的lt码译码方法的程序。
本发明产生的有益效果是:本发明根据lt码编码矩阵的生成原理,即输入包的数量与编码矩阵的行数相同,根据此特性,提供一种基于编码矩阵特性的lt码的编译码方法,来实现信息在二进制删除信道中的可靠传输。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1为基于编码矩阵特性的编码方法图;
图2为当存储包全部接收时基于编码矩阵特性的译码方法图;
图3为当存储包部分丢失时基于编码矩阵特性的译码方法图;
图4为基于编码矩阵特性的lt码编码方法;
图5为基于编码矩阵特性的lt码译码方法。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明的编码矩阵生成原理如下:
对k个输入包s={sj|j=1,2,...,k}进行编码,生成编码包c={cn|n=1,2,...},每个编码包长lbit。编码器根据度分布随机产生一个kbit的编码向量
式中,cn是产生的第n个编码包,是与gi,n=1相对应的输入包按位模2和。随机生成的列向量
根据公式(1)可知,编码矩阵gk×n的列数对应产生的编码包的数量n,每一列中的元素“1”可以看作该列对应的编码包与输入包之间存在连接关系;编码矩阵的行数对应输入包的数量k,每一行中的元素“1”可以看作该行对应的输入包与编码包之间存在连接关系。也就是说,编码矩阵中每个为“1”的元素gi,j表示第i个输入包与第j个编码包之间的连接关系。可以看出,输入包的数量与编码矩阵行数相同。基于这一特性,本发明采用如下技术方案改进编译码算法。
(1)基于编码矩阵特性的编码方法
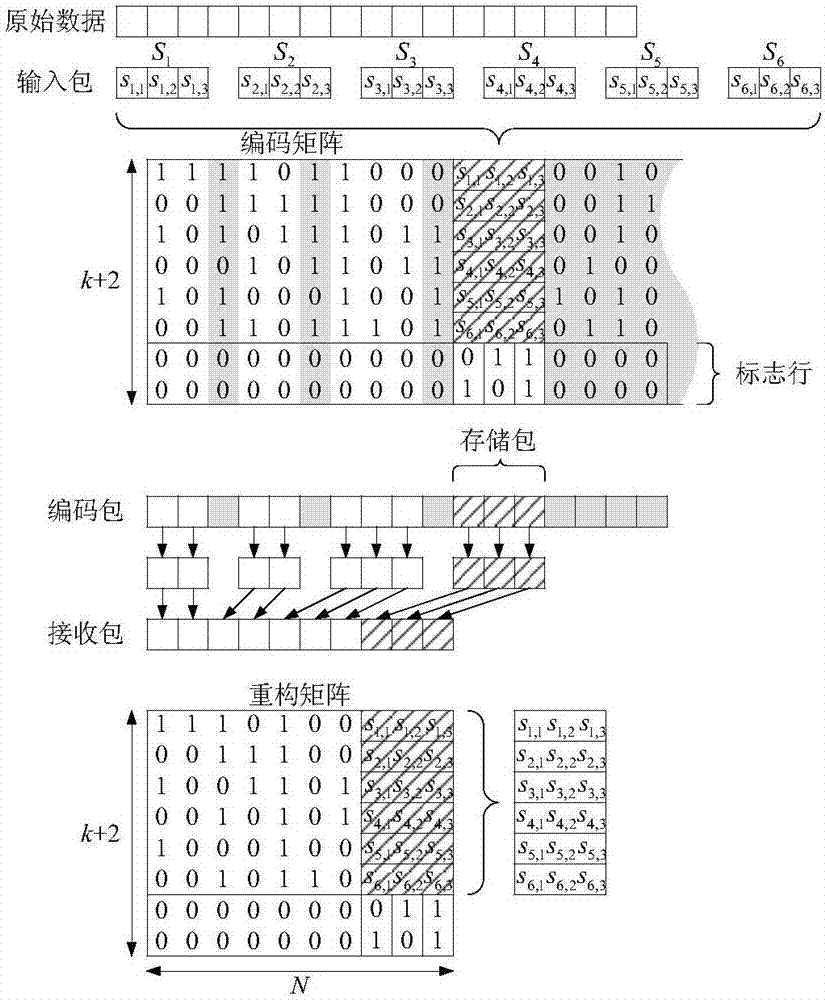
如图4所示,首先,将输入包组成一个k×l的矩阵sk×l,将其每一列依次作为编码矩阵gk×n的附加列,生成新的编码矩阵gk×(n+l)。此时,新编码矩阵的行数仍为k,而列数增加了l列。
随后,为了区分附加列和原编码矩阵列,考虑在编码矩阵gk×(n+l)的第k行后增加几行作为“标志行”。经过bec以后,编码包在传输过程中的顺序被打乱,为了能够将输入包的每bit信息正确恢复到各自原始的位置,采用十进制数字对矩阵sk×l的列顺序进行从低到高标注,然后将十进制转换为二进制。“标志行”的行数由二进制标志的位数确定,将这些二进制标志分别存储于各个“存储列”对应的“标志行”中,而其他列对应的“标志行”的每个元素设置为“0”。
最后,通过上述存储机制,产生新的编码矩阵g(k+num)×(n+l),其中num为二进制标志的位数。“标志行”只起到标注作用,而不参与实际编码,也就是说,原来基于gk×n产生的编码序列保持不变。为了在编码序列中增加“存储列”对应的编码包,我们直接假设“存储列”对应的编码包中每bit都为“1”。
发送端的编码器可采用鲁棒孤子分布(robustsolitondistribution,rsd)产生普通编码包,同时基于编码矩阵特性产生携带存储信息的“存储包”。
(2)基于编码矩阵特性的译码方法
经过bec传输,编码包的顺序被打乱,一些编码包可能不能被接收到。图2和图3中灰色部分表示删除的编码包以及相应的编码矩阵列。“存储包”必然也要面临被删除的可能性,尽管“存储包”不用参与译码,但是“存储包”中的存储信息可以恢复输入包中某些bit。
如图5所示,接收端接收到n个编码包,重构编码矩阵g′(k+2)×n,然后开始译码。首先,通过检测附加行中为“1”的元素对应的列,即携带存储信息的“存储列”,找出所有“存储列”。
随后,取出每个携带标志信息的“存储列”中的“标志行”,并将二进制“标志行”转换为十进制。将所有“存储列”按照对应的十进制标志进行升序排列,构成矩阵s′k×l′。
最后,根据接收到的“存储包”的数量不同,采取不同方式对输入包进行译码:(1)如果全部“存储包”被接收到,则通过矩阵s′k×l′可直接得到所有原始数据,无需进行译码过程;(2)如果部分“存储包”丢失,首先,去掉重构矩阵中的“存储列”和“标志行”,构成新的编码矩阵g′k×n,同时去掉“存储列”对应的编码包;然后,基于重构矩阵g′k×n和对应的编码包,采用bp算法进行译码;最后,通过矩阵s′k×l′恢复输入包中某些未译出的bit。(3)如果全部“存储包”被删除,则采用置信传播(beliefpropagation,bp)算法进行译码。
如图1所示,以输入包长度l=3bit为例,基于编码矩阵特性的编码算法如下:
step1:从度分布中随机选择一个编码包的度d。随机且均匀地选取d个输入包作为该编码包的“邻接”。将这d个“邻接”进行异或生成一个编码包。同时,这个编码包到输入包的连接关系表示为编码矩阵的对应列。
step2:重复step1产生n(n=1,2,...)个编码包和编码矩阵gk×n。
step3:将原输入包组成一个k×3的矩阵
其中,
step4:将“1”、“2”、“3”作为标志对存储列进行排序,其他列标志为“0”。首先,将十进制“0”、“1”、“2”、“3”转换为二进制“00”、“01”、“10”、“11”。然后,将这些二进制标志存储于编码矩阵的附加行,生成新的编码矩阵:
式中,第k+1行和第k+2行为“标志行”。[g(k+1),m,g(k+2),m]=[0,1],[g(k+1),(m+1),g(k+2),(m+1)]=[1,0],[g(k+1),(m+2),g(k+2),(m+2)]=[1,1],而“标志行”的其他元素设置为“0”。
step5:对应于“存储列”的每个编码包中的3bit都设置为“1”,称为“存储包”。
如图2和图3所示,基于编码矩阵特性的译码算法如下:
step1:检测g′(k+2)×n的附加行中是否存在标志。
step2:如果所有的标志“01”、“10”、“11”都被检测出,则表示“存储包”全部被接收,所有输入包都能通过“存储列”的1到k行直接获得。首先,二进制“01”、“10”、“11”转换为十进制“1”、“2”、“3”。然后,所有“存储列”按照十进制标志的升序进行排列,并删除附加行,构成
step3:如果只有一些标志被检测出,则表示一些“存储包”丢失,通过结合“存储包”和bp译码算法对输入包进行译码。例如,只有标志“01”和“11”被检测到。首先,通过step2的方法得到
step4:如果所有标志未被检测出,则表示所有“存储包”丢失,采用bp算法进行译码。
上述实施例的基于编码特性的lt码的编译码方法,可以通过多种程序语言实现,并通过存储装置存储。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!