一种用于无人摄影的视觉感知方法和系统与流程
本发明属于无人拍摄领域,具体地说是一种用于无人摄影的视觉感知方法和系统。
背景技术:
现有的摄像工作都需要有人的参与。用户直接拿着拍摄终端进行拍摄,或者借用拍摄云台等进行控制。或者如无人机、水下摄像机等所谓的无人摄像工具,其实质也是由人进行操控,由人来决定拍摄的内容、时间起止、拍摄范围、拍摄角度等等摄像要素。即各种拍摄方式,实质上都是需要人的直接或者间接参与。而且,设定好的无人拍摄,只能简单的进行拍摄,无法进行感知拍摄。
技术实现要素:
本发明要解决的技术问题是提供一种用于无人摄影的视觉感知方法和系统,不需要人参与的情况下,完成拍摄,减少人力成本,节省时间,拍摄效果佳。
为了解决上述技术问题,本发明采取以下技术方案:
一种用于无人摄影的视觉感知方法,包括以下步骤:
s1,将摄像终端架设在支撑终端上,启动摄像终端对目标开始拍摄视频,提取目标的基础特征;
s2,根据基础特征,分析目标当前的行为、姿态和位置,输出下一步拍摄画面的指导信息,为摄像终端的行为提供指导信息,调整拍摄终端,依此反复,直至视频拍摄结束。
所述步骤s2具体包括前端视觉感知,该前端视觉感知具体包括以下步骤:
s201,目标检测,确定目标在当前拍摄画面中的具体位置;
s202,姿态估计,获取目标的姿态特点,推测目标下一步的趋向;
s203,目标跟踪,根据目标的历史位置以及姿态分布信息,确定目标在后续帧中的位置以及姿态信息。
所述步骤s201中,目标检测时,每隔设定帧对当前拍摄画面中的图像帧进行检测,找到拍摄画面中的目标位置,为姿态估计和目标跟踪提供辅助信息。
所述步骤s2具体包括后端场景理解,该后端场景理解具体包括以下步骤:
s211,行为检测,对目标的动作进行检测,获取目标的动作信息;
s212,人脸识别,对拍摄画面中的人脸进行识别,为识别目标和对象选取提供参考信息;
s213,手势识别,检测是否有代表操作指令的手势,若有,根据手势执行相应操作;
s214,热点感知,根据行为检测中获取的动作信息和姿态估计中获取的姿态特点,对当前拍摄视频的热点进行估计,自动确定拍摄范围、拍摄角度和拍摄路径,输出拍摄策略,调整拍摄终端至相应位置进行拍摄。
所述步骤s212的人脸识别得到的信息和步骤s213的手势识别得到的信息,还提供给步骤s203的目标跟踪,对该信息进行分析处理。
所述步骤s201的目标检测得到的信息和步骤s202姿态估计得到的信息,还提供给步骤s211的行为检测,对该信息进行分析处理。
一种用于无人摄影的视觉感知系统,所述系统包括基础特征提取模块,用于获取拍摄画面中目标的基础特征;
前端视觉感知模块,用于接收基础特征并进行分析处理,输出下一步拍摄画面的指导信息;
后端场景理解模块,用于接收基础特征并进行分析处理,输出下一步拍摄画面的指导信息。
所述前端视觉感知模块包括:
目标检测模块,用于确定目标在当前拍摄画面中的具体位置;
姿态估计模块,获取目标的姿态特点,推测目标下一步的趋向;
目标跟踪模块,根据目标的历史位置以及姿态分布信息,确定目标在后续帧中的位置以及姿态信息;
后端场景理解模块包括:行为检测模块,对目标的动作进行检测,获取目标的动作信息;
人脸识别模块,对拍摄画面中的人脸进行识别,为识别目标和对象选取提供参考信息;
手势识别模块,检测是否有代表操作指令的手势,若有,根据手势执行相应操作;
热点感知模块,根据行为检测中获取的动作信息和姿态估计中获取的姿态特点,对当前拍摄视频的热点进行估计,自动确定拍摄范围、拍摄角度和拍摄路径,输出拍摄策略,调整拍摄终端至相应位置进行拍摄。
本发明不需要人参与的情况下,完成拍摄,减少人力成本,通过基础特征提取,有效减少拍摄的计算量和耗费的时间,拍摄效果佳。
附图说明
附图1为本发明中系统的连接原理示意图;
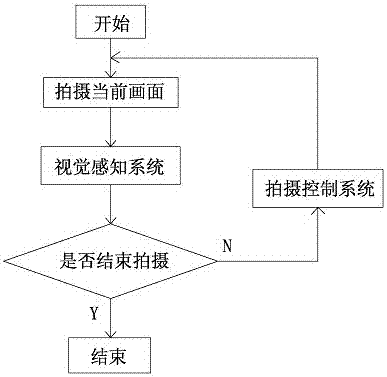
附图2为本发明结合拍摄终端进行拍摄的整体流程示意图。
具体实施方式
为能进一步了解本发明的特征、技术手段以及所达到的具体目的、功能,下面结合附图与具体实施方式对本发明作进一步详细描述。
一种用于无人摄影的视觉感知方法,包括以下步骤:
s1,将摄像终端架设在支撑终端上,启动摄像终端对目标开始拍摄视频,提取目标的基础特征。支撑终端可为云台或者是其他可运动的支撑装置,摄像终端如为相机、手机等具有摄影功能的电子设备。得到目标的多种基础特征,该基础特征如为目标和周边环境的相对关系、动作、姿态等等。
s2,根据基础特征,分析目标当前的行为、姿态和位置,输出下一步拍摄画面的指导信息,为摄像终端的行为提供指导信息,调整拍摄终端,依此反复,直至视频拍摄结束。
所述步骤s2具体包括前端视觉感知,该前端视觉感知具体包括以下步骤:
s201,目标检测,确定目标在当前拍摄画面中的具体位置。每隔设定帧对当前拍摄画面中的图像帧进行检测,找到拍摄画面中的目标位置,从而获取得到较为精确的目标位置。
s202,姿态估计,获取目标的姿态特点,依据姿态与行为之间的内在联系,推测目标下一步的趋向,得到一个推测的目标趋向。
s203,目标跟踪,根据目标的历史位置以及姿态分布信息,确定目标在后续帧中的位置以及姿态信息,输出后续帧中的目标位置和姿态信息。主要对目标的动作进行跟踪,可以较为平滑快速的进行跟踪,根据目标的位置和姿态信息,可以有效的提高跟踪效果。而且,即使在复杂的场景当中,通过目标检测和姿态估计得到的信息,也能够找到视频中的人体位置,从而辅助人体跟踪的工作,或帮助目标跟踪从失败中恢复,从而继续跟踪。
所述步骤s2具体包括后端场景理解,该后端场景理解具体包括以下步骤:
s211,行为检测,对目标的动作进行检测,获取目标的动作信息,同时可以用于估计当前对象的行为热点。
s212,人脸识别,对拍摄画面中的人脸进行识别,为识别目标和对象选取提供参考信息;
s213,手势识别,检测是否有代表操作指令的手势,若有,根据手势执行相应操作。比如目标是人,则人可以在摄像头前通过手势对摄像机发出开始摄像、停止摄像等指令。通过识别这些手势,可以实现相应的操作。
s214,热点感知,根据行为检测中获取的动作信息和姿态估计中获取的姿态特点,对当前拍摄视频的热点进行估计,自动确定拍摄范围、拍摄角度和拍摄路径,输出拍摄策略,调整拍摄终端至相应位置进行拍摄。从而根据得到的拍摄策略,调整拍摄终端,或者通过调整支撑终端来达到调整拍摄终端的目的,实现更佳的下一下拍摄。跟控制摄像终端或者支撑终端的控制系统进行指令数据的通讯,实现具体控制。
为了更好的进行拍摄和感知,人脸识别得到的信息和手势识别得到的信息还提供给目标跟踪,输送给目标跟踪步骤,有利于更好的进行跟踪。
另外,所述步骤s201的目标检测得到的信息和步骤s202姿态估计得到的信息,还提供给步骤s211的行为检测,对该信息进行分析处理。从而前端视觉感知为后端场景理解提供大量的基础信息,如姿态特点、位置等。而同时后端场景理解也会反馈信息给前端视觉感知,通过前端视觉感知和后端场景理解双输出的下一步拍摄指导信息,综合得到一个较挂的拍摄策略。
本发明还揭示了一种用于无人摄影的视觉感知系统,如附图1所示,所述系统包括基础特征提取模块,用于获取拍摄画面中目标的基础特征,通过基础特征提取模块,作为单独的提取模块,节省后续对目标的特征提取,形成一个统一的特征提取模块,从而节省数倍的时间和计算机存储空间。基础特征提取模块的深度神经网络参数,首先来自训练好的imagenet的分类模型,然后利用迁移学习,通过不同的模块依次训练,得到共用的基础特征提取网络。
前端视觉感知模块,用于接收基础特征并进行分析处理,输出下一步拍摄画面的指导信息;后端场景理解模块,用于接收基础特征并进行分析处理,输出下一步拍摄画面的指导信息。
所述前端视觉感知模块包括:目标检测模块,用于确定目标在当前拍摄画面中的具体位置;姿态估计模块,获取目标的姿态特点,推测目标下一步的趋向;目标跟踪模块,根据目标的历史位置以及姿态分布信息,确定目标在后续帧中的位置以及姿态信息,输出后续帧中的目标位置和姿态信息。
后端场景理解模块包括:行为检测模块,对目标的动作进行检测,获取目标的动作信息;人脸识别模块,对拍摄画面中的人脸进行识别,为识别目标和对象选取提供参考信息;手势识别模块,检测是否有代表操作指令的手势,若有,根据手势执行相应操作;热点感知模块,根据行为检测中获取的动作信息和姿态估计中获取的姿态特点,对当前拍摄视频的热点进行估计,自动确定拍摄范围、拍摄角度和拍摄路径,输出拍摄策略,调整拍摄终端至相应位置进行拍摄。
目标检测可以找到目标位置,为姿态估计确定骨架所在范围,提供辅助信息。目标检测模块为行为检测模块提供辅助信息。
姿态估计模块为目标跟踪模块提供辅助信息:姿态估计模块可以得到目标各个部位所在的位置,为目标跟踪的复位提供更多辅助信息。姿态估计模块为行为检测模块提供辅助信息。姿态估计模块可以得到目标的姿态特点,姿态与行为之间存在联系,故可以通过姿态特点,推测可能的目标行为。
姿态估计模块为热点感知模块提供辅助信息:热点的定义一定程度上取决于目标的姿态。
人脸识别模块为目标跟踪模块提供辅助信息:与目标检测模块为目标跟踪模块提供辅助信息类似。
行为检测模块为热点感知模块提供辅助信息:热点的定义一定程度上取决于目标的行为。
最后,综合前端视觉感知模块和后端场景分析模块的输出信息,为支撑终端及摄像终端的行为提供指导信息,从而完成拍摄。
如附图2所示,目标设定为人,支撑终端采用云台。拍摄当前画面,然后进入到本方法中的视觉感知系统中,对人的位置、姿态等信息进行获取,推测人的下一个姿态趋向,并且进行跟踪。另外还对人的动作进行检测,通过各种热点感知,得到一个较佳的拍摄策略,然后通过云台的控制系统控制云台的具体转向和角度,实现摄像终端的转向和角度调节。依此反复,直至拍摄结束。可通过人手势识别或者按下按钮或者其他信号进行控制。
需要说明的是,以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,但是凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!