一种自适应的半监督网络流量分类方法、系统及设备与流程
本发明属于网络流量管理领域,尤其涉及一种自适应的半监督网络流量分类方法、系统及设备。
背景技术:
传统的基于网络流的方法大多采用监督的或无监督的机器学习算法来实现网络流量分类。在有监督的流量分类中,学习引擎接受一组已标记的流样本,根据预定义的协议类别进行训练,然后返回一个训练好的分类模型,该分类模型可以预测未来网络流的协议类型。然而,随着网络的迅速扩展,互联网上部署了许多新的应用程序,这些应用对应的未知流是基于监督学习的分类方法无法处理的。在这种情况下,未知流将被错误地划分到某个预定义的流量类别中去,并影响分类器的整体精度。基于无监督学习的分类方法可以自动聚类未标记的训练样本,应用聚类结果构建流量分类器。但是聚类簇的数目必须被设置得足够大,以得到高纯度的流量簇,而且很难在没有监督信息的情况下将大量的流量簇映射到少量的流量类别中。
因此,传统的流量分类方法在标记信息不足,且网络中存在未知流量的现实情况下表现不佳。为了解决这个问题,erman等人首先提出了将半监督学习方法应用到流量分类中,利用有标记流和未标记流的混合输入,训练出一个可以将已知协议分类的同时提取出未知协议的分类器。张等人扩展了erman的工作,提出了一种改进的半监督流量分类方法,该方法在复杂的网络环境下表现良好。但是这样依然存在一些问题,比如:在训练阶段不能自动确定最佳参数,需要人工手动调参,不能实现系统的参数自适应。
技术实现要素:
本发明所要解决的技术问题是:现有的在训练阶段不能自动确定最佳参数,需要人工手动调参,不能实现系统的参数自适应。
为解决上面的技术问题,本发明提供了一种基于半监督学习的自适应网络流量分类方法,其特征在于,该自适应网络流量分类方法包括:
s1,获取已标记类型和未标记类型的网络流,提取每条网络流中预设固定量的流特征,得到网络流特征向量;
s2,根据已标记的网络流特征向量,计算出每个类型中的网络流特征向量集合的质心,得到向量集m;
s3,以所述向量集m为k-means聚类的初始中心点,对混合的已标记类型和未标记类型的网络流特征向量集x进行自适应的半监督k-means聚类,并输出k-means的聚簇;
s4,根据输出的聚簇中每个簇的已标记网络流特征向量的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到已知类型的流量簇;
s5,将所述已知类型的流量簇作为训练数据,训练出线上的流量分类器。
本发明的有益效果:通过上述的方法,利用参数自适应的半监督k-means,将网络流进行了合理的聚类,保证了每一簇类中网络流类别的统一性,同时实现了对未知类别网络流的提取,利用得到的聚类结果训练出的分类器,可以在提高多协议分类准确率的同时,实现对未知协议的提取,保证了系统的可靠性和准确性。
进一步地,所述步骤s1中获取已标记类型和未标记类型的网络流,其中每种类型中的已标记网络流的数量相同。
进一步地,所述步骤s3中具体包括:
s31,利用输入的初始中心点m对混合的网络流进行k-means聚类,得到k个簇和k个簇中心点;
s32,根据所述k个簇和所述k个簇中心点计算评价函数,得到评价函数的值,同时更新所述向量集m,得到新的向量集m;
s33,计算出所述网络流特征向量集x中离所述新的向量集m的中心点最远的k个向量点;
s34,根据密度计算公式,确定在所述最远的k个向量点中密度最大的向量点,并将所述密度最大的向量点添加到所述新的向量集m中;
s35,设置新的k值,根据所述新的中心点集m和所述新的k值,重复执行步骤s31-s34,直到k值大于预设最大阈值;
s36,统计所有所述评价函数的值,从所有所述评价函数的值中选取最小评价函数的值,以及与所述最小评价函数的值对应的k值,并输出在所述对应的k值时k-means的聚簇。
上述进一步地有益效果:通过上述的方法,实现对半监督k-means的改进,利用迭代半监督k-means,并动态添加中心点的方法,实现了k值的自适应选取,即聚类数目的自适应选取,同时保证了聚簇内部的高纯净性。
进一步地,所述s32中更新所述向量集m,得到新的向量集m,其具体包括:将向量集m替换为所述k个簇中心点组成的集合。
进一步地,所述s32中根据所述k个簇和所述k个簇中心点计算评价函数,得到评价函数的值,其公式具体为:
其中,d(mi,xj)表示簇i的中心点mi与簇i中的向量点xj之间的欧式距离,
进一步地,所述s34中根据点的密度计算公式,计算出所述最远的k个点中密度最大的点,其具体计算公式为:
其中d(xi,xj)表示向量点xi和向量点xj之间的欧式距离,
进一步地,所述s35中包括:
设置新的k值,当所述新的k值小于所述预设最大阈值时,根据所述新的中心点集m和所述新的k值,重复执行步骤s31-s34,其中所述新的k值为原k值加1,所述预设最大阈值为
本发明还涉及一种自适应的半监督网络流量分类系统,该自适应网络流量分类系统包括:
获取模块、向量集处理模块、聚类模块、分类模块、输出模块;
所述获取模块,用于获取已标记类型和未标记类型的网络流,提取每条网络流中预设固定量的流特征,得到网络流特征向量;
所述向量集处理模块,用于根据已标记的网络流特征向量,计算出每个类型中的网络流特征向量集合的质心,得到向量集m;
所述聚类模块,用于以所述向量集m为k-means聚类的初始中心点,对混合的已标记类型和未标记类型的网络流特征向量集x进行自适应的半监督k-means聚类,并输出k-means的聚簇;
所述分类模块,用于根据输出的聚簇中每个簇中已标记网络流特征向量的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到已知类型的流量簇;
所述输出模块,用于将所述已知类型的流量簇作为训练数据,训练出线上的流量分类器。
本发明的有益效果:通过上述的系统,利用参数自适应的半监督k-means,将网络流进行了合理的聚类,保证了每一簇类中网络流类别的统一性,同时实现了对未知类别网络流的提取的改进,利用得到的聚类结果训练出的分类器,可以在提高多协议分类准确率的同时,实现对未知协议的提取,保证了系统的可靠性和准确性。。
进一步地,所述获取模块,用于获取已标记类型和未标记类型的网络流,其中每种类型中的已标记网络流的数量相同。
本发明还涉及一种计算机设备,该计算机设备包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一项所述方法的步骤。
本发明的有益效果:通过上述的计算机设备,改进了半监督k-means聚类算法,利用迭代半监督k-means,并动态添加中心点的方法,实现k值的自适应,利用得到的聚类结果训练出的分类器,可以在提高多协议分类准确率的同时,实现对未知协议的提取,保证了系统的可靠性和准确性。。
附图说明
图1为本发明实施例1的一种自适应的半监督网络流量分类方法的流程图;
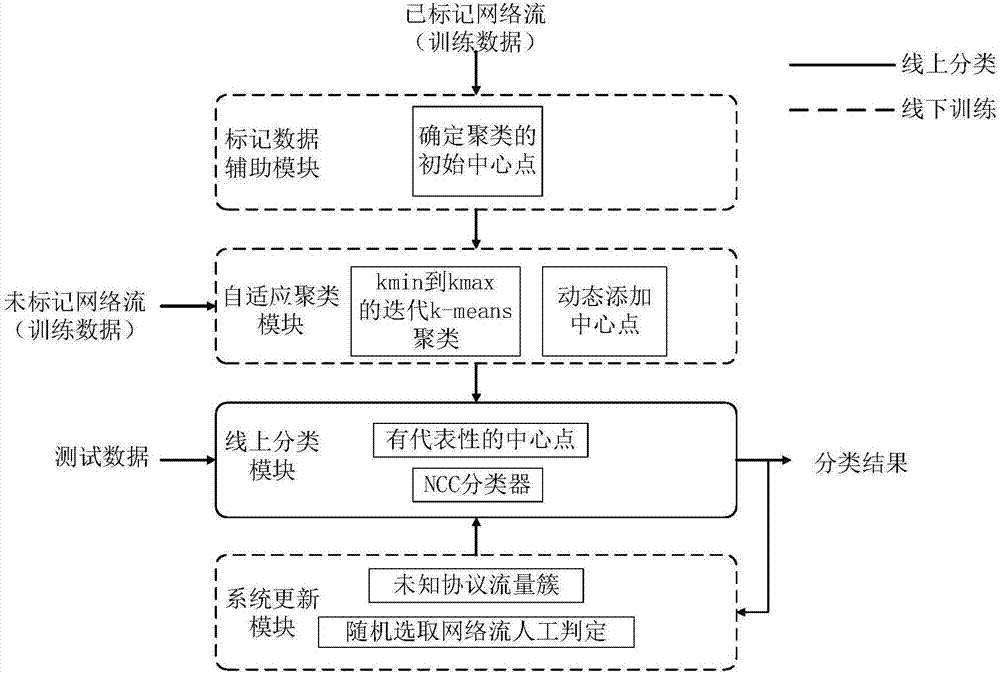
图2为本发明的自适应的半监督网络流量分类系统的框架的结构示意图;
图3为本发明实施例8一种自适应的半监督网络流量分类系统的结构示意图;
图4为本发明实施例10的一种计算机设备的结构示意图;
图5是分类器的整体准确率对比的示意图;
图6是针对每种协议的分类的准确率对比的示意图;
图7是更进一步分析已标记网络流的比例对分类器准确率的影响的示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,本发明实施例1提供的是一种自适应的半监督网络流量分类方法,该自适应网络流量分类方法包括:
s1,获取已标记类型和未标记类型的网络流,提取每条网络流中预设固定量的流特征,得到网络流特征向量;
s2,根据已标记的网络流特征向量,计算出每个类型中的网络流特征向量集合的质心,得到向量集m;
s3,以所述向量集m为k-means聚类的初始中心点,对混合的已标记类型和未标记类型的网络流特征向量集x进行自适应的半监督k-means聚类,并输出k-means的聚簇;
s4,根据输出的聚簇中每个簇中已标记网络流特征向量的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到已知类型的流量簇;
s5,将所述已知类型的流量簇作为训练数据,训练出线上的流量分类器。
需要说明的是,如图2所示,在本实施例1中是采用的是自适应的半监督网络流量分类系统的框架,该系统训练出的分类器能够实现实时的流量分类,在提高常见类型流量的分类准确度的同时,还具有检测和提取出未知应用程序产生的未知流的能力。该系统由两阶段组成:离线学习和在线识别。少量的标记流量和大量未标记的网络流作为系统的线下训练数据输入。在本实施例1中主要是利用参数自适应的半监督k-means,将网络流进行了合理的聚类,保证了每一簇类中网络流类别的统一性,同时实现了对未知类别网络流的提取,根据每簇中已标记网络流特征向量的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到已知类型的流量簇;将所述已知类型的流量簇作为训练数据,训练出线上的流量分类器聚簇结果作为训练数据,可用于训练线上的实时网络流量分类器,如ncc分类器。在线上分类时,该分类器可将网络流量划分为若干已知流量类型的同时,检测并提取出未知流量。为了实现更细粒度分类,我们还加入了系统更新模块,进一步分析了未知流量的类型,可用于构建新的流量类别,更新系统的知识量。
通过本实施例1的方法,改进了半监督k-means算法,利用迭代半监督k-means,并动态添加中心点的方法,实现k值的自适应,这样大大提高了后续分类的精度。
可选地,在另一实施例2中所述步骤s1中获取已标记类型和未标记类型的网络流,其中每种类型中的已标记网络流的数量相同。
需要说明的是,本实施例2是在上述实施例1的基础上进行的进一步说明。
可选地,在另一实施例3中所述步骤s3中具体包括:
s31,利用输入的初始中心点m对混合的网络流进行k-means聚类,得到k个簇和k个簇中心点;
s32,根据所述k个簇和所述k个簇中心点计算评价函数,得到评价函数的值,同时更新所述向量集m,得到新的向量集m;
s33,计算出所述网络流特征向量集x中离所述新的向量集m的中心点最远的k个向量点;
s34,根据密度计算公式,确定在所述最远的k个向量点中密度最大的向量点,并将所述密度最大的向量点添加到所述新的向量集m中;
s35,设置新的k值,根据所述新的中心点集m和所述新的k值,重复执行步骤s31-s34,直到k值大于预设最大阈值;
s36,统计所有所述评价函数的值,从所有所述评价函数的值中选取最小评价函数的值,以及与所述最小评价函数的值对应的k值,并输出在所述对应的k值时k-means的聚簇。
需要说明的是,本实施例3是在上述实施例1或者实施例2的基础上进行的进一步说明。
可选地,在另一实施例4中所述s32中更新所述向量集m,得到新的向量集m,其具体包括:将向量集m替换为所述k个簇中心点组成的集合。
需要说明的是,本实施例4是在上述实施例3的基础上进行的进一步说明。
可选地,在另一实施例5中所述s32中根据所述k个簇和所述k个簇中心点计算评价函数,得到评价函数的值,其公式具体为:
需要说明的是,本实施例5是在上述实施例3或者实施例4的基础上进行的进一步说明。
可选地,在另一实施例6中所述s6中包括:
所述s34中根据点的密度计算公式,计算出所述最远的k个点中密度最大的点,其具体计算公式为:
其中d(xi,xj)表示向量点xi和向量点xj之间的欧式距离,
需要说明的是,本实施例6是在上述实施例3或者实施例4的基础上进行的进一步说明。
可选地,在另一实施例7中所述s35中包括:
设置新的k值,当所述新的k值小于所述预设最大阈值时,根据所述新的中心点集m和所述新的k值,重复执行步骤s31-s34,其中所述新的k值为原k值加1,所述预设最大阈值为
需要说明的是,本实施例7是在上述实施例3或者实施例4的基础上进行的进一步说明。
实施例8
如图3所示,本发明还提供一种自适应的半监督网络流量分类系统,该自适应网络流量分类系统包括:
获取模块、向量集处理模块、聚类模块、分类模块、输出模块;
所述获取模块,用于获取已标记类型和未标记类型的网络流,提取每条网络流中预设固定量的流特征,得到网络流特征向量;
所述向量集处理模块,用于根据已标记的网络流特征向量,计算出每个类型中的网络流特征向量集合的质心,得到向量集m;
所述聚类模块,用于以所述向量集m为k-means聚类的初始中心点,对混合的已标记类型和未标记类型的网络流特征向量集x进行自适应的半监督k-means聚类,并输出k-means的聚簇;
所述分类模块,用于根据输出的聚簇中每个簇中已标记网络流特征向量的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到已知类型的流量簇;
所述输出模块,用于将所述已知类型的流量簇作为训练数据,训练出线上的流量分类器。
需要说明的是,如图2所示,本实施例8是对应于上述实施例1-实施例7的方法的系统,本实施例8的系统与实施例1-实施例7的技术特征是一一对应的,在本实施例8中是采用的是自适应的半监督网络流量分类系统的框架,该系统能够实现实时的流量分类,在提高常见类型流量的分类准确度的同时,还具有检测和提取出未知应用程序产生的未知流的能力。该系统由两阶段组成:离线学习和在线识别。少量的标记流量和大量未标记的网络流作为系统的线下训练数据输入。在本实施例8中主要是对半监督k-means的改进,利用迭代半监督k-means,并动态添加中心点的方法,实现k值的自适应,根据每簇中已标记网络流的最大后验概率,将得到的每类簇中的网络流映射到所属的流量类型中,得到新的已知类型的流量簇;将所述新的已知类型的流量簇作为训练数据,训练出线上的实时网络流量分类器,如ncc分类器。在线上分类时,该分类器可将网络流量划分为若干已知流量类型的同时,检测并提取出未知流量。为了实现更细粒度分类,我们还加入了系统更新模块,进一步分析了未知流量的类型,可用于构建新的流量类别,更新系统的知识量。
通过本实施例8的系统,改进了半监督k-means算法,利用迭代半监督k-means,并动态添加中心点的方法,实现k值的自适应,这样大大提高了后续分类提炼的精度。
可选地,在另一实施例9中所述获取模块,用于获取已标记类型和未标记类型的网络流,其中每种类型中的已标记网络流的数量相同。
需要说明的是,本实施例9是在上述实施例8的基础上进行的进一步说明。
实施例10
如图4所示,本发明实施例还提供一种计算机设备,该计算机设备包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现上述实施例1-实施例7任一实施例所述方法的步骤。
需要说明的是,在本实施例10中通过本发明的计算机设备,获取已标记类型和未标记类型的网络流,提取每条网络流中预设固定量的流特征,得到网络流特征向量,根据已标记的所述网络流特征向量,计算出已标记的每个类型网络流的中心点,并以所述中心点作为k-means算法的初始聚类中心m,对混合的已标记类型和未标记类型的网络流点集x进行半监督k-means聚类,得到k个簇和k个中心点,更新m为k个新的中心点;再计算jk值,并根据更新后的m点集,计算出点集x中离所述m中新的中心点最远的k个点;接着根据点的密度计算公式,确定在所述最远的k个点中密度最大的点,并将所述密度最大的点添加到更新后的中心点集m中;当k值小于
对于上述实施例1到实施例10,使用到的改进的k值自适应的半监督k-means算法,其计算方法如下步骤:
输入:未标记的网络流特征向量x={x1,...,xn}
p个初始中心点m={m1,...,mp},k的初始取值为p
输出:k个网络流特征向量簇
step1:利用m作为k-means的初始聚类中心,对向量点集x进行k-means聚类,得到k个簇ck={c1,...,ck}和k个中心点;
step2:计算对应评价函数
step3:将m重置为k-means聚类得到的k个簇的中心点;
step4:计算点集x中距离step3中得到的中心点距离最远的k个点;
step5:根据点的密度计算公式计算出step4得到的k个中心点中密度最大的点,加入到更新后的中心点集m中,其中计算密度的公式为:
step6:k值重置为k+1,当k值小于
step7:统计得到最小的jk的值,以及其对应的k值和k取该值时对应的聚簇结果,并输出。
下面是具体的一些解析,首先输入是一个由已标记和未标记流组成的训练集,其中每个网络流可以认为是统计特征空间中的一个向量点。向量之间的欧氏距离是
在改进的算法中k值从kmin=p变化到
此外,我们需要在迭代过程中在每次动态地添加一个中心点。我们考虑从距当前的中心点距离最远的k个中心点中选择密度最大的一个进行添加,距离最大可以有效地避免陷入局部最优,而密度最大可以保证该点的代表性。其中密度的计算公式为
接下来是聚类识别算法。我们采用概率分配机制将k-means得到的k个聚簇映射到属于不同应用程序的流量类型中。我们可以利用后验概率来决定映射的类别,p(l=lj|ci)=nij/ni,其中nij表示类型j的已标记数据被聚类到簇i中的数目,ni表示簇i中已标记流的总数量。
如图5、图6和图7所示,下面的对上述实施例1-实施例10进行的一些实验数据说明;
图5中的表格中的数据分别对应着柱状图从左到右的四个图形,依次为本发明得到的分类器,本发明去掉已标记数据充分利用部分得到的分类器,以及其他两种半监督分类器,分类器整体的准确率分别为95.80%,92.67%,91.13%,86.67%。
图6列举了几种不同协议通过上述分类器进行分类后的f值对比,f值一般用于评价多协议分类器对每种协议的不同分类性能,它是正确率和召回率的加权调和平均。针对http,smtp,ftp,dns和一类未知协议,通过本发明的方法训练出的分类器均得到了很好的效果。
图7更进一步分析已标记网络流的比例对各种分类器准确率的影响,随着已标记网络流比例的增加,本发明训练出的分类器的准确率不断提高,但是其他方法得到的分类器不仅没有明显提高,甚至有所下降,说明了本发明在簇的类别映射方面的改进方法的先进性。
在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!