利用压缩反馈的低复杂度波束赋形的制作方法
本申请要求2016年12月16日提交的题为“lowcomplexitymethodsandsystemsforbeamformingwithcompressedfeedback”的美国临时专利申请no.62/435,667的权益,其公开内容据此以它的整体通过引用明确地并入本文。
本公开一般地涉及通信网络,并且更特别地,涉及通信网络中的波束赋形。
背景技术:
无线局域网(wlan)在过去十年已经快速演进,并且wlan标准(诸如电气和电子工程师协会(ieee)802.11标准族)的开发已经改进了单用户峰值数据吞吐量。例如,ieee802.11b标准规定11兆比特每秒(mbps)的单用户峰值吞吐量,ieee802.11a标准和802.11g标准规定54mbps的单用户峰值吞吐量,ieee802.11n标准规定600mbps的单用户峰值吞吐量,并且ieee802.11ac标准规定在千兆比特每秒(gbps)范围中的单用户峰值吞吐量。现在正在开发中的ieee802.11ax标准承诺提供甚至更大的吞吐量,诸如在数十gbps范围中的吞吐量。
技术实现要素:
在一种实施例中,一种用于在通信信道中提供波束赋形反馈的方法包括:在第一通信设备处,经由通信信道从第二通信设备接收多个训练信号;在第一通信设备处基于多个训练信号,确定与通信信道相对应的信道矩阵;在第一通信设备处基于信道矩阵,确定将被提供给第二通信设备的压缩反馈,其中确定压缩反馈不包括分解引导矩阵;以及从第一通信设备向第二通信设备传输压缩反馈,以使得第二通信设备能够将至少一个后续传输引导到第一通信设备。
在另一实施例中,一种第一通信设备包括具有一个或多个集成电路的网络接口设备,一个或多个集成电路被配置为:经由通信信道从第二通信设备接收多个训练信号;基于多个训练信号来确定与通信信道相对应的信道矩阵;基于信道矩阵来确定将被提供给第二通信设备的压缩反馈,其中确定压缩反馈不包括分解引导矩阵;以及向第二通信设备传输压缩反馈,以使得第二通信设备能够将至少一个后续传输引导到第一通信设备。
附图说明
图1是根据一种实施例的示例无线局域网(wlan)的框图;
图2是根据一种实施例的技术的流程图,该技术用于联合地确定引导矩阵和表示引导矩阵的压缩反馈;
图3a-图3b是根据一种实施例的技术的流程图,该技术使用qr分解的一次迭代来联合地确定引导矩阵和表示引导矩阵的压缩反馈;
图4是根据一种实施例的流程图,其图示了利用图3a-图3b的技术执行的相位旋转操作;
图5a是根据一种实施例的流程图,其图示了利用图3a-图3b的技术执行的吉文斯旋转操作;
图5b是根据一种实施例的技术的流程图,该技术利用图5a的吉文斯旋转操作执行的去旋转操作;
图6a-图6b是根据一种实施例的技术的流程图,该技术使用qr分解的多次迭代来联合地确定引导矩阵和表示引导矩阵的压缩反馈;
图7a-图7f是图示了根据信道包括四个空间流的实施例的各种操作的示图,这些操作被执行以通过分解4×4矩阵来联合地确定引导矩阵和表示引导矩阵的压缩反馈;以及
图8是根据一种实施例的示例方法的流程图,该示例方法用于在通信信道中提供波束赋形反馈。
具体实施方式
仅出于解释的目的,下文描述的波束赋形反馈技术是在无线局域网(wlan)的上下文中讨论的,这些wlan利用与来自电气和电子工程师学会(ieee)的802.11标准所定义的协议相同或类似的协议。然而,在其他实施例中,波束赋形反馈技术在其他类型的无线通信系统中被利用,诸如个域网(pan)、移动通信网络(诸如蜂窝网络)、城域网(man),等等。
在下文描述的实施例中,无线网络设备(诸如无线局域网(wlan)的接入点(ap))向一个或多个客户站传输数据流。在一些实施例中,wlan支持多输入多输出(mimo)通信,其中ap和/或客户站包括多于一个天线,由此创建多个空间(或空时)流,数据可以在该多个空间流上同时被传输。在ap采用多个天线用于传输的实施例中,ap利用各种天线传输相同的信号,同时在该信号被提供给各种发射天线时对其进行定相(和放大),以实现波束赋形或波束引导。为了实施波束赋形技术,ap一般需要如下的通信信道的某些特性的知识,该通信信道在ap与将为其创建波束赋形图案的一个或多个客户站之间。为了获得信道特性,根据一种实施例,ap向客户站传输探测分组,该探测分组包括允许客户站准确地估计mimo信道的一定数目的训练字段。客户站然后以某种形式将所获得的信道特性传输或反馈给ap,例如通过在传输到ap的管理帧或控制帧中包括信道特性信息。在各种实施例中,一经从客户站中的一个或多个客户站接收到表征对应通信信道的信息,ap生成期望的波束图案以在向一个或多个站的后续传输中使用。
在一种实施例中,客户站基于使用来自ap的训练信号获得的信道特性来确定引导矩阵,并且将压缩反馈传输到ap,压缩反馈包括压缩信息,诸如表示引导矩阵的角度,其然后可以由ap用来重建引导矩阵。为了高效地生成压缩反馈,在一种实施例中,客户站使用不包括分解引导矩阵的技术来生成压缩反馈。例如,在一种实施例中,客户站分解信道矩阵或从信道矩阵得到的中间矩阵,以联合地确定引导矩阵和表示引导矩阵的压缩反馈。在至少一些实施例中,与首先确定引导矩阵并且然后通过分解引导矩阵来获得压缩反馈的系统相比,基于信道矩阵来确定压缩反馈并且不分解引导矩阵的各种技术允许客户站更快地确定准确地表示引导矩阵的压缩反馈,利用较少的硬件,较小的物理面积、较少的功耗、较低的计算复杂度,等等。
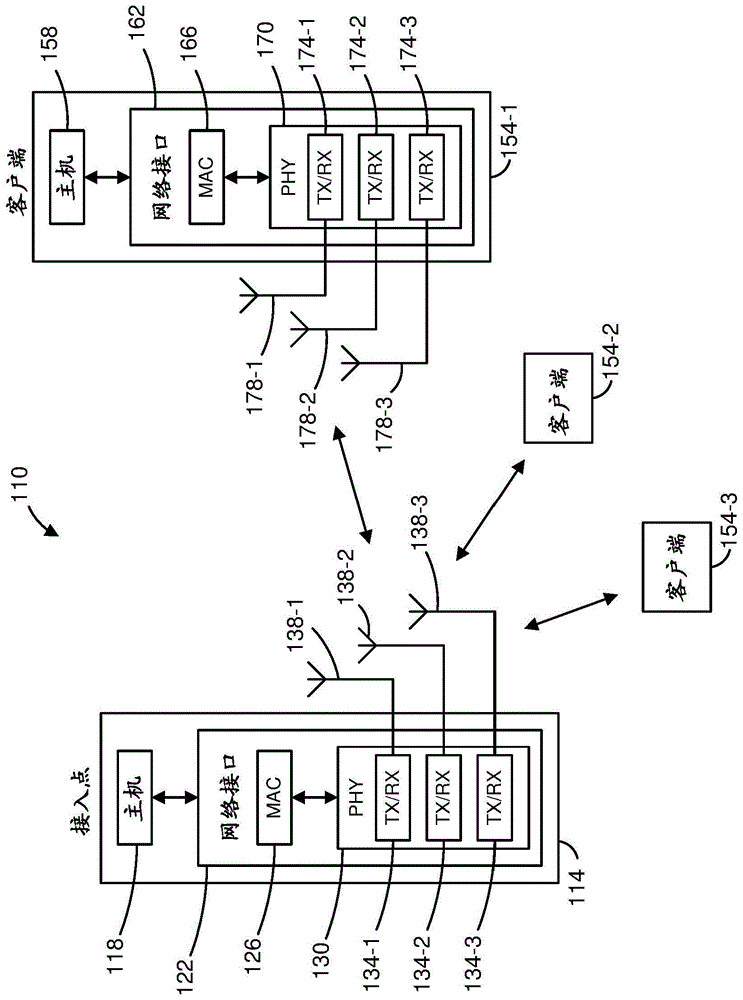
图1是根据一种实施例的示例wlan110的框图。wlan110包括接入点(ap)114,ap114包括耦合到网络接口设备122的主机处理器118。网络接口设备122包括介质访问控制(mac)处理器126和物理层(phy)处理器130。phy处理器130包括多个收发器134,并且收发器134耦合到多个天线138。尽管图1中图示了三个收发器134和三个天线138,但是在其他实施例中,ap114包括其他合适数目(例如,1、2、4、5等)的收发器134和天线138。在一些实施例中,ap114包括比收发器134更多数目的天线138,并且利用天线切换技术。
网络接口设备122使用被配置为如下文所讨论的进行操作的一个或多个集成电路(ic)来实施。例如,mac处理器126可以至少部分地实施在第一ic上,并且phy处理器130可以至少部分地实施在第二ic上。作为另一示例,mac处理器126的至少一部分和phy处理器130的至少一部分可以实施在单个ic上。例如,网络接口设备122可以使用片上系统(soc)来实施,其中soc包括mac处理器126的至少一部分和phy处理器130的至少一部分。
在各种实施例中,ap114的mac处理器126和/或phy处理器130被配置为生成数据单元,并且处理所接收的数据单元,这些数据单元符合wlan通信协议(诸如符合ieee802.11标准的通信协议)或另外的合适无线通信协议。例如,mac处理器126可以被配置为实施mac层功能,包括wlan通信协议的mac层功能,并且phy处理器130可以被配置为实施phy功能,包括wlan通信协议的phy功能。例如,mac处理器126可以被配置为生成mac层数据单元,诸如mac服务数据单元(msdu)、mac协议数据单元(mpdu)等,并且将mac层数据单元提供给phy处理器130。
phy处理器130可以被配置为从mac处理器126接收mac层数据单元,并且封装mac层数据单元以生成phy数据单元,诸如phy协议数据单元(ppdu),用于经由天线138的传输。phy处理器130包括电路装置(例如,在收发器134中),其被配置为将基带信号上变频为射频(rf)信号用于经由天线138的无线传输。
类似地,phy处理器130可以被配置为接收经由天线138接收的phy数据单元,并且提取phy数据单元内封装的mac层数据单元。phy处理器130可以将所提取的mac层数据单元提供给mac处理器126,mac处理器126处理mac层数据单元。phy处理器130包括电路装置(例如,在收发器134中),其被配置为将经由天线138接收的rf信号下变频为基带信号。
wlan110包括多个客户站154。尽管图1中图示了三个客户站154,但是在各种实施例中,wlan110包括其他合适数目(例如,1、2、4、5、6等)的客户站154。客户站154-1包括耦合到网络接口设备162的主机处理器158。网络接口设备162包括mac处理器166和phy处理器170。phy处理器170包括多个收发器174,并且收发器174耦合到多个天线178。尽管图1中图示了三个收发器174和三个天线178,但是在其他实施例中,客户站154-1包括其他合适数目(例如,1、2、4、5等)的收发器174和天线178。在一些实施例中,客户站154-1包括比收发器174更多数目的天线178,并且利用天线切换技术。
网络接口设备162使用被配置为如下文所讨论的进行操作的一个或多个ic来实施。例如,mac处理器166可以实施在至少第一ic上,并且phy处理器170可以实施在至少第二ic上。作为另一示例,mac处理器166的至少一部分和phy处理器170的至少一部分可以实施在单个ic上。例如,网络接口设备162可以使用soc来实施,其中soc包括mac处理器166的至少一部分和phy处理器170的至少一部分。
在各种实施例中,客户端设备154-1的mac处理器166和phy处理器170被配置为生成数据单元,并且处理所接收的数据单元,这些数据单元符合wlan通信协议或另外的合适通信协议。例如,mac处理器166可以被配置为实施mac层功能,包括wlan通信协议的mac层功能,并且phy处理器170可以被配置为实施phy功能,包括wlan通信协议的phy功能。
mac处理器166可以被配置为生成mac层数据单元,诸如msdu、mpdu等,并且将mac层数据单元提供给phy处理器170。phy处理器170可以被配置为从mac处理器166接收mac层数据单元,并且封装mac层数据单元以生成phy数据单元(诸如ppdu)用于经由天线178的传输。phy处理器170包括电路装置(例如,在收发器174中),其被配置为将基带信号上变频为rf信号用于经由天线178的无线传输。
类似地,phy处理器170可以被配置为接收经由天线178接收的phy数据单元,并且提取phy数据单元内封装的mac层数据单元。phy处理器170可以将所提取的mac层数据单元提供给mac处理器166,mac处理器166处理mac层数据单元。phy处理器170包括电路装置(例如,在收发器174中),其被配置为将经由天线178接收的rf信号下变频为基带信号。
在一种实施例中,客户站154-2和154-3中的每个客户站具有与客户站154-1相同或相似的结构。客户站154-2和154-3中的每个客户站具有相同或不同数目的收发器和天线。例如,根据一种实施例,客户站154-2和/或客户站154-3每个仅具有两个收发器和两个天线(未示出)。
在一种实施例中,ap114被配置为使用一个或多个客户站154与ap114之间的通信信道的特性的知识,来实施用于向一个或多个客户站154的传输的波束赋形。在一种实施例中,为了获得ap114与客户站154(例如,客户站154-1)之间的通信信道的特性的知识,ap114将已知的训练信号传输到客户站154-1。例如,在一种实施例中,ap114将探测分组传输到客户站154-1,其中探测分组包括一个或多个训练字段(例如,长训练字段(ltf)),该一个或多个训练字段包括训练信号。在一种实施例中,客户站154-1从ap114接收训练信号,并且基于从ap114接收的训练信号来产生通信信道的信道描述。在数学术语中,客户站154-1经由通信信道从ap114接收的信号可以写为:
其中y是接收的信号矢量,nr是接收天线的数目;nt是发射天线的数目;h是与通信信道相对应的信道矩阵;x是传输的信号矢量;并且w是加性噪声矢量。在一种实施例中,客户站154-1基于接收的信号y及其对传输的训练信号x的知识来确定信道矩阵h。在使用ofdm通信的实施例中,客户站154-1确定多个信道矩阵hi,信道矩阵hi中的相应信道矩阵对应于通信信道中的相应ofdm音调。
基于所确定的一个或多个信道矩阵h,客户站154-1生成要传输到ap114的压缩波束赋形反馈。在一种实施例中,压缩波束赋形反馈包括信息(例如,角度),该信息表示基于一个或多个信道矩阵h确定的一个或多个引导矩阵。在一种实施例中,客户站154-1被配置为基于信道矩阵h来联合地确定引导矩阵和表示引导矩阵的压缩反馈。例如,如下文更详细地解释的,在一种实施例中,客户站154-1被配置为实施一种技术,该技术在确定引导矩阵的过程中确定压缩反馈,而无需首先确定引导矩阵并且然后分解引导矩阵。
根据一种实施例,客户站154-1被配置为通过执行从信道矩阵得到的对称中间矩阵的qr分解来确定压缩反馈。一般地,对称矩阵的qr分解产生正交矩阵q和上三角矩阵r,其中正交矩阵q是对称矩阵的奇异矢量(例如,特征矢量)的足够好的近似。因此,在一种实施例中,从信道矩阵得到的对称中间矩阵的qr分解生成正交矩阵q,其是具有信道矩阵的奇异值的引导矩阵的足够好的近似,诸如,例如,将从信道矩阵的svd分解获得的右奇异矢量矩阵v。在一些实施例中,客户站154-1被配置为执行qr分解的多次迭代以获得q矩阵,其是引导矩阵的更好近似。在一种实施例中,qr分解的每次迭代是对如下的矩阵执行的,该矩阵是从信道矩阵得到的中间矩阵与在qr分解的在前迭代中确定的矩阵q的乘积。在至少一些实施例中,以这种方式执行的qr分解的若干迭代收敛到将会从信道矩阵的svd分解获得的右奇异矢量矩阵v。
在一些实施例中,客户站154-1被配置为执行以下中的一项或两项:i)对在qr分解的每个阶段期间所操作的矩阵的列进行排序,使得主导矢量在qr分解的每个阶段中被确定,以及ii)动态地缩放在qr分解的每个阶段期间所操作的矩阵的元素以防止溢出,并且使用定点算术运算来改进计算的精度。在至少一些实施例中,与首先确定引导矩阵并且然后通过分解引导矩阵来获得压缩反馈的系统相比,这样的各种技术允许客户站更快地确定准确地表示引导矩阵的压缩反馈,利用较少的硬件、较小的物理面积、较少的功耗、较低的计算复杂度,等等,这些技术基于信道矩阵来确定压缩反馈并且不分解引导矩阵,并且采用以下中的一项或两项:i)对在计算的每个阶段期间所操作的矩阵的列进行排序,以及ii)动态地缩放在qr分解的每个阶段期间所操作的矩阵的元素。
图2是根据一种实施例的技术200的流程图,技术200用于联合地确定引导矩阵和表示引导矩阵的压缩反馈。在一种实施例中,客户站(例如,图1的客户站154-1)被配置为实施技术200以确定要反馈给ap114的压缩反馈,并且出于解释的目的,参考图1的客户站154-1来讨论技术200。然而,在其他实施例中,技术200由ap(例如,图1的ap114)来实施,或者由另一合适的通信设备来实施。
在框204处,中间矩阵b从信道矩阵h被得到。在一种实施例中,中间矩阵b是对称方阵。例如,在信道矩阵h具有nr×nt的维度的实施例中,所确定的中间矩阵b具有nt×nt的维度。在一种实施例中,中间矩阵b根据下式,通过将信道矩阵h与信道矩阵h的厄米特转置相乘而被确定:
b=hhh等式2
其中厄米特算子h代表共轭转置。在另一实施例中,中间矩阵b通过以下被确定:执行信道矩阵h的初始qr分解以生成正交矩阵q1和上三角矩阵r1(即,[q1,r1]=qr(h)),并且根据
在框206处,若干初始化被执行。在一种实施例中,框206包括将矩阵q0初始化为等于初始矩阵qinit,其中在一种实施例中,初始矩阵qinit是合适的(例如,随机的)正交矩阵。在一种实施例中,初始矩阵qinit具有与中间矩阵b的维度相对应的维度。例如,在一种实施例中,初始矩阵qinit具有nt×nt的维度。在一种实施例中,框206另外包括将整数计数器k初始化为等于1。
框208-框212执行迭代式qr分解。在框208处,在第一次迭代中,在框204处确定的中间b和在框206处初始化的矩阵q0的矩阵乘积的qr分解被执行。在框210处,检查是否已经达到迭代次数niter。如果确定尚未达到迭代次数niter(k<niter为真),则在框212处整数计数器k被递增,并且该技术返回到框208。在一种实施例中,在第一次迭代之后的每次后续迭代(迭代k)中,框208处的qr分解是对框204处确定的中间矩阵b与在之前迭代(迭代k-1)中确定的矩阵qk-1的相乘所产生的矩阵执行的。
一旦在框210处确定已经达到迭代次数niter(k<niter为假),则技术200终止,并且结果是在末次迭代中确定的矩阵qniter。一般地,在至少一些实施例中,技术200的一次或若干次迭代足以生成如下的矩阵qniter,该矩阵qniter是将会例如由信道矩阵h的svd分解产生的引导矩阵v的良好近似。如下文更详细描述的,在一种实施例中,除了生成引导矩阵qniter之外,执行技术200的一次或若干次迭代还生成表示引导矩阵qniter的压缩反馈。
仍然参考图2,在一种实施例中,执行框208处的qr分解是使用相位旋转和吉文斯(givens)旋转来执行的。一般而言,在一种实施例中,用于分解矩阵mnxn的qr分解是分阶段执行的,其中在每个阶段中执行相位旋转和吉文斯旋转。在qr分解的第k阶段中,对矩阵m(k:n,k:n)的行执行相位旋转,以使得矩阵m(k:n,k:n)的第一列的元素是正实数。在一种实施例中,相位旋转操作可以表示为与具有如下的一般形式的矩阵的左乘:
然后,对所产生的(相位旋转后的)矩阵m(k:n,k:n)执行吉文斯旋转,以使元素m(k+1:n,1)归零。在一种实施例中,吉文斯旋转操作可以表示为与具有如下的一般形式的矩阵的左乘:
相位旋转和吉文斯旋转分别生成角度
图3a-图3b是根据一种实施例的技术300的流程图,技术300使用qr分解的一次迭代联合地确定引导矩阵和表示引导矩阵的压缩反馈。在一种实施例中,客户站(例如,图1的客户站154-1)被配置为实施技术300以确定要反馈给ap114的压缩反馈,并且出于解释的目的,参考图1的客户站154-1来讨论技术300。然而,在其他实施例中,技术300由ap(例如,图1的ap114)来实施,或者由另一合适的通信设备来实施。
在框302处,客户站154-1确定信道矩阵h。在一种实施例中,客户站154-1基于从ap114接收的多个训练信号来确定信道矩阵h。在一种实施例中,训练信号被包括在客户站154-1从ap114接收的数据单元(诸如探测数据单元)中。例如,在一种实施例中,训练信号被包括在客户站154-1从ap114接收的数据单元(诸如探测数据单元)的前导码的训练字段(例如,长训练字段(ltf))中。在其他实施例中,客户站154-1以其他合适的方式确定信道矩阵h。
在框304处,客户站154-1从在框302处确定的信道矩阵h得到中间矩阵b。在一种实施例中,中间矩阵b是对称方阵。在一种实施例中,客户站154-1如上文关于图2的框204描述的那样,从信道矩阵h得到中间矩阵b。例如,在一种实施例中,客户站154-1通过根据b=hhh(等式2)确定信道矩阵h和信道矩阵h的厄米特转置的乘积来得到中间矩阵b,其中厄米特算子h代表共轭转置。在另一实施例中,客户站154-1通过以下来得到中间矩阵b:使用qr分解对信道矩阵h进行分解以生成正交矩阵q1和上三角矩阵r1,其中[q1,r1]=qr(h),并且设置中间矩阵
在框306处,客户站154-1动态地缩放中间矩阵b以生成经缩放的矩阵
j=argmaxbii等式3
其中argmax表示最大值算符的幅角。客户站154-1然后确定用于缩放矩阵b的所标识的元素bjj的缩放因子,使得用于存储元素bjj的一定数目的比特中的前导比特是逻辑一(1)。换言之,在一种实施例中,缩放因子被确定以使得将元素bjj缩放所确定的缩放因子将元素bjj的量值缩放为使得:
在另一实施例中,缩放因子基于具有最高范数值(例如,l2范数或l2范数平方)的列来确定。无论如何,在一种实施例中,一经确定缩放因子,客户站154-1将矩阵b的所有元素缩放所确定的缩放因子,以生成经缩放的矩阵
在框308处,客户站154-1确定经缩放的矩阵
在一种实施例中,客户站154-1将用于矩阵
现在参考图3b,在框310处,在一种实施例中,矩阵
仍参考图3b,在框312处,在各种实施例中,客户站154-1确定新平方范数值,或者更新在框308处确定的平方范数值。在一种实施例中,框312对于qr分解的第一阶段不被执行(即,跳过)。替代地,在一种实施例中,在框308处确定和存储的平方范数值被用于第一阶段。在一种实施例中,对于在第一阶段之后的后续阶段中的每个阶段,新的列平方范数值在框312处被确定以用于在对应阶段中被操作的子矩阵的列。例如,在具有四个空间流(nss=4)的实施例中,在第一阶段中,框312被跳过并且在框308处确定的矩阵
其中
在框314处,经排序的矩阵
并且将矩阵
在框318处,矩阵
在框320处,矩阵
在框418处,整数计数器i被递增。在框420处,确定是否已经到达矩阵
返回参考图3b,在框322处,图3b中的整数计数器i被设置为值l+1。在框324处,针对i为l+1到nr,对矩阵
a=xcos(θ)+ysin(θ)等式8
b=-xsin(θ)+ycos(θ)等式9
在框554处,在一种实施例中,x和y分别被设置为a和b的计算值,并且去旋转操作完成。
返回参考图5a,在框510处,整数计数器k被初始化为等于l+1。在框512处,两个去旋转操作被执行。特别地,在一种实施例中,具有输入re(clk),re(cik),ψil的第一去旋转如上文关于图5b所描述的被执行,其中clk和cik是矩阵
在框514处,整数计数器k被递增。在框512-框518处,矩阵
在框518处,确定是否已经到达矩阵
仍然参考图5a,在框520处,整数计数器i被递增。在框522处,确定是否已经到达矩阵
下文关于图7a-图7f来描述具有四个空间流的示例实施例中的示例吉文斯旋转操作。
返回参考图3b,在框326处,整数计数器l被递增。在框328处,确定是否已经到达最后的空间流。如果在框328处确定尚未到达最后的空间流(即,如果l≤nss为真),则技术300返回到框312,并且qr分解的另一阶段(框312-框328)被执行。另一方面,在一种实施例中,如果在框328处确定已经到达最后的空间流(即,如果l>nss为真),则矩阵
在一种实施例中,分别在框406和框504处保存的角度
其中j≤i<n。另一方面,在一种实施例中,在框504处保存的角度ψ不需要进一步的计算。在一种实施例中,客户站154-1被配置为量化i)基于在框406处保存的角度
图6a-图6b是根据一种实施例的技术600的流程图,技术600使用qr分解的多次迭代来联合地确定引导矩阵和表示引导矩阵的压缩反馈。在一种实施例中,客户站(例如,图1的客户站154-1)被配置为实施技术600以确定要反馈给ap114的压缩反馈,并且出于解释的目的,参考图1的客户站154-1来讨论技术600。然而,在其他实施例中,方法600由ap(例如,图1的ap114)来实施,或者由另一合适的通信设备来实施。
技术600大体上类似于图3a-图3b的技术300,并且包括与图3a-图3b的技术300相同编号的框中的许多框,这些框为了简明未再次描述。然而,与图3a-图3b的技术300不同,技术600包括执行qr分解的多次迭代,以用于联合地确定引导矩阵和表示引导矩阵的压缩反馈。
参考图6a,在一种实施例中,技术600开始于上文关于图3a描述的框302-框308。技术600继续于框608,在框608处,整数计数器n被初始化为等于1。现在参考图6b,在框610处,若干初始化被执行。在一种实施例中,矩阵
继续参考图6b,在框614处,在一种实施例中,矩阵
图7a-图7f是图示了各种操作的示图,这些操作被执行以在通信信道包括四个空间流的示例实施例中,通过分解4×4矩阵来联合地确定引导矩阵q和表示引导矩阵q的反馈角度。在一种实施例中,客户站(例如,图1的客户站154-1)被配置为在针对具有4个空间流的信道来确定要反馈给ap114的压缩反馈时实施图7a-图7f中所图示的操作,并且为了解释的目的,参考图1的客户站154-1来讨论图7a-图7f。然而,在其他实施例中,图7a-图7f中所图示的操作由ap(例如,图1的ap114)来实施,或者由另一合适的通信设备来实施。
图7a是图示了qr操作的示图,这些qr操作被执行以在通信信道包括四个空间流的实施例中分解示例4×4矩阵a,以基于矩阵a联合地确定引导矩阵和表示引导矩阵的压缩反馈。在图7a中,变量c用于表示矩阵的复数,并且变量r用于表示正实数。在一种实施例中,图7a中的上标一般指示在对矩阵a的元素执行qr分解的对应操作之前和之后的该元素。因此,例如,在一种实施例中,元素
如图7a中图示的,4×4矩阵a702的qr分解在三个阶段中执行。在qr分解的第一阶段中,第一相位旋转操作p1旋转矩阵a[1:4,1:4]的第一列中的元素,使得元素变为正实数。然后,吉文斯旋转操作g21、g31和g41依次地被执行,以分别将旋转后的矩阵a的第一列的第二行、第三行和第四行中的元素归零。在所图示的实施例中,qr分解的第一阶段产生矩阵b704。在qr分解的第二阶段中,第二相位旋转操作p2旋转子矩阵b[2:4,2:4]的第一列中的元素,使得元素变为正实数。然后,吉文斯旋转操作g32和g42依次地被执行,以分别将旋转后的子矩阵b[2:4,2:4]的第一列的第二行和第三行中的元素归零。在所图示的实施例中,qr分解的第二阶段产生矩阵c706。在qr分解的第三阶段中,第三相位旋转操作p3旋转子矩阵c[3:4,3:4]的第一列中的元素,使得元素变为正实数。然后,吉文斯旋转操作g43被执行,以将旋转后的子矩阵c[3:4,3:4]的第一列的第二行中的元素归零。在所图示的实施例中,qr分解的第三阶段产生矩阵708。
图7a中应用于矩阵702以获得矩阵708的操作的累积效果可以写为矩阵乘法qh=g43p3g42g32p2g41g31g21p1,其中p1、p2和p3是图7b中所图示的矩阵,并且g21、g31、g41、g32、g42和g43是图7c中所图示的矩阵。如图7b-图7c中所示出的,图7a中的操作使用
图8是根据一种实施例的示例方法800的流程图,示例方法800用于在通信信道中提供波束赋形反馈。在一种实施例中,方法800由第一通信设备来实施。参考图1,在一种实施例中,方法800由网络接口设备162来实施。例如,在一个这样的实施例中,phy处理器170被配置为实施方法800。根据另一实施例,mac处理器166也被配置为实施方法800的至少一部分。继续参考图1,在又另一实施例中,方法800由网络接口设备122(例如,phy处理器130和/或mac处理器126)来实施。在其他实施例中,方法800由其他合适的网络接口设备来实施。
在框802处,多个训练信号从第二通信设备被接收。在一种实施例中,探测分组被接收,其中探测分组包括多个训练信号。在一种实施例中,训练信号在探测分组的一个或多个ltf字段中被接收。在其他实施例中,训练信号以其他合适的方式被接收。
在框804处,与通信信道相对应的信道矩阵被确定。在一种实施例中,信道矩阵基于在框802处接收的训练信号被确定。
在框806处,压缩反馈基于在框804处确定的信道矩阵被确定。在一种实施例中,在框806处确定压缩反馈不包括分解引导矩阵。在一种实施例中,压缩反馈使用图2的技术200被确定。在另一实施例中,压缩反馈使用图3a-图3b的技术300被确定。在又另一实施例中,压缩反馈使用图6a-图6b的技术600被确定。在其他实施例中,压缩反馈使用不包括分解引导矩阵的其他合适技术被确定。
在框808处,在框806处确定的压缩反馈被传输给第二通信设备。在一种实施例中,压缩反馈被传输给第二通信设备,以使得第二通信设备能够基于压缩反馈,将至少一个后续传输引导到第一通信设备。因此,在一种实施例中,第一通信设备被配置为从第二通信设备接收基于压缩反馈被引导的至少一个后续传输。
在一种实施例中,一种用于在通信信道中提供波束赋形反馈的方法包括:在第一通信设备处,经由通信信道从第二通信设备接收多个训练信号;在第一通信设备处基于多个训练信号,确定与通信信道相对应的信道矩阵;在第一通信设备处基于信道矩阵,确定将被提供给第二通信设备的压缩反馈,其中确定压缩反馈不包括分解引导矩阵;以及从第一通信设备向第二通信设备传输压缩反馈,以使得第二通信设备能够将至少一个后续传输引导到第一通信设备。
在其他实施例中,该方法还包括以下特征中的一个特征或者两个或更多特征的任何合适组合。
该方法还包括:在第一通信设备处,从信道矩阵得到中间矩阵,其中确定压缩反馈包括分解中间矩阵。
确定中间矩阵包括:确定信道矩阵和信道矩阵的厄米特转置的乘积。
确定中间矩阵包括:执行信道矩阵的初始qr分解以获得初始q矩阵和初始r矩阵,其中中间矩阵的共轭转置是初始r矩阵。
分解中间矩阵包括:执行中间矩阵的qr分解以确定q矩阵和r矩阵。
该方法还包括:对于qr分解的一个或多个阶段中的每个阶段,确定与在qr分解的该阶段中将被处理的r矩阵的子矩阵的列相对应的范数值。
该方法还包括:对于qr分解的一个或多个阶段中的每个阶段,在执行子矩阵的qr分解之前,对子矩阵的列进行排序,以使得与所确定的范数值之中的最高范数值相对应的列是子矩阵的第一列。
针对qr分解的第二阶段确定范数值包括:更新先前针对qr分解的第一阶段确定的范数值,其中qr分解的第一阶段在qr分解的第二阶段之前被执行。
该方法还包括:对于qr分解的一个或多个阶段中的每个阶段,动态地缩放在qr分解的该阶段中将被处理的r矩阵的子矩阵的元素,包括以下之一:i)基于子矩阵的元素的a)实部和b)虚部中的最大者的绝对值来动态地缩放元素,以使得绝对值的前导比特是逻辑1,以及ii)基于与子矩阵的列相对应的范数值之中的最大范数值来动态地缩放元素,以使得最大范数值的前导比特是逻辑1。
确定压缩反馈包括:执行qr分解的多次迭代,包括对中间矩阵执行多次迭代中的初始迭代。
该方法还包括:对于在qr分解的初始迭代之后的qr分解的一次或多次迭代中的每次迭代,确定中间矩阵和由qr分解的之前迭代产生的q矩阵的乘积,包括通过在qr分解的之前迭代期间将qr分解直接应用到经缩放的中间矩阵来确定乘积。
在另一实施例中,一种第一通信设备包括网络接口设备,网络接口设备具有一个或多个集成电路,一个或多个集成电路被配置为:经由通信信道从第二通信设备接收多个训练信号;基于多个训练信号来确定与通信信道相对应的信道矩阵;基于信道矩阵来确定将被提供给第二通信设备的压缩反馈,其中确定压缩反馈不包括分解引导矩阵;以及向第二通信设备传输压缩反馈,以使得第二通信设备能够将至少一个后续传输引导到第一通信设备。
在其他实施例中,第一通信设备还包括以下特征中的一个特征或者两个或更多特征的任何合适组合。
一个或多个集成电路还被配置为:从信道矩阵得到中间矩阵。
确定压缩反馈包括:分解中间矩阵。
一个或多个集成电路被配置为:至少通过确定信道矩阵和信道矩阵的厄米特转置的乘积来确定中间矩阵。
一个或多个集成电路被配置为:至少通过执行信道矩阵的初始qr分解以获得初始q矩阵和初始r矩阵来确定中间矩阵,其中中间矩阵的共轭转置是初始r矩阵。
一个或多个集成电路被配置为:至少通过执行中间矩阵的qr分解以确定q矩阵和r矩阵来分解中间矩阵。
一个或多个集成电路还被配置为:对于qr分解的一个或多个阶段中的每个阶段,确定与在qr分解的该阶段中将被处理的r矩阵的子矩阵的列相对应的范数值。
一个或多个集成电路还被配置为:对于qr分解的一个或多个阶段中的每个阶段,在执行子矩阵的qr分解之前,对子矩阵的列进行排序,以使得与所确定的范数值之中的最高范数值相对应的列是子矩阵的第一列。
一个或多个集成电路被配置为:至少通过更新先前针对qr分解的第一阶段确定的范数值,来针对qr分解的第二阶段确定范数值,其中qr分解的第一阶段在qr分解的第二阶段之前被执行。
一个或多个集成电路还被配置为,对于qr分解的一个或多个阶段中的每个阶段,动态地缩放在qr分解的该阶段中将被处理的r矩阵的子矩阵的元素,包括以下之一:i)基于子矩阵的元素的a)实部和b)虚部中的最大者的绝对值来动态地缩放元素,以使得绝对值的前导比特是逻辑1,以及ii)基于与子矩阵的列相对应的范数值之中的最大范数值来动态地缩放元素,以使得最大范数值的前导比特是逻辑1。
一个或多个集成电路被配置为:至少通过执行qr分解的多次迭代来确定压缩反馈,包括对中间矩阵执行多次迭代中的初始迭代。
一个或多个集成电路还被配置为:对于在qr分解的初始迭代之后的qr分解的一次或多次迭代中的每次迭代,确定中间矩阵和由qr分解的之前迭代产生的q矩阵的乘积,包括通过在qr分解的之前迭代期间将qr分解直接应用到经缩放的中间矩阵来确定乘积。
上文描述的各种框、操作和技术中的至少一些可以利用硬件、执行固件指令的处理器、执行软件指令的处理器、或它们的任何组合来实施。当利用执行软件指令或固件指令的处理器来实施时,软件指令或固件指令可以存储在任何计算机可读存储器中,诸如在磁盘、光盘或其他存储介质上,在ram或rom或闪存中,在处理器、硬盘驱动器、光盘驱动器、磁带驱动器等中。软件指令或固件指令可以包括机器可读指令,机器可读指令在由一个或多个处理器执行时使得一个或多个处理器执行各种动作。
当实施在硬件中时,硬件可以包括分立组件、集成电路、专用集成电路(asic)、可编程逻辑器件(pld)等中的一个或多个。
尽管已经参考仅旨在为说明性而不是限制本发明的具体示例描述了本发明,但是不偏离本发明的范围,可以对所公开的实施例进行改变、添加和/或删除。
- 还没有人留言评论。精彩留言会获得点赞!