一种基于序列比对的二进制未知协议报文格式划分方法与流程
本发明属于网络协议分析技术领域,具体涉及一种基于序列比对的二进制未知协议报文格式划分方法。
背景技术:
1967年,英格兰国家物理实验室的r.a.scantleburry和k.a.bartlett在一份备忘录中最早把“protocol”这个英文单词用于描述数据通信的过程,现如今,各种标准化组织、网络通信技术方案提供者、网络运营商等纷纷制定了相应的公开协议。顾名思义,此类协议规格公开,使用的数据格式也属于已知范畴,如手机app与后台交互时最常使用的超文本传输协议,和在家用路由器中配置地址时使用的动态主机配置协议等。与此同时,出于商业利益或者军事政治领域敏感信息保密等目的,或者对于卫星、雷达、无人机等特殊设备而言,有时候设备间进行通信的协议规格不方便公开,于是产生了适用于此环境的私有协议。从网络流量的角度看,私有协议基本上都是以“未知流量”的形式存在,即以无法定义协议种类,也无法从中获取到协议信息的数据流量的形式存在,故也称之为未知协议。
目前国内外已有一些基于网络流量进行私有协议报文格式推断的研究成果。pi项目提出首先使用动态规划的smith-waterman算法找出任意两个样本之间的局部比对,计算出样本之间的相似度,构造样本集的距离矩阵,然后采用非加权成对群算术平均法(upgma)计算子类间距离,逐步将距离最小的样本合并,再使用needleman-wunsch算法用动态规划的方式进行双序列全局比对。discoverer协议格式提取方案则按照文本和二进制两种属性对报文字节流进行标注,得到报文属性序列,通过对报文属性序列进行序列比对得到初始聚类结果,随后依据格式标志字段进行递归聚类获取协议格式。然而,现有的私有协议报文格式推断方案都存在一些缺陷。pi项目使用无监督的upgma聚类方法进行层次聚类,时间复杂度较高。discoverer虽然采用构造报文属性序列的方式降低了时间复杂度,但其采用常见文本类分隔符对报文样本进行划分的处理方法并不适用于二进制协议。
现有的基于序列比对的二进制协议划分方法主要仍以pi项目作为改进基础,考虑对于常规技术手段needleman-wunsch算法和smith-waterman算法本身进行改进,如改进算法中的矩阵构造等步骤,但仍然基本保留经典pi项目中的比对流程,存在时间复杂度较高,且缺少较为明确的格式划分依据和方法的缺点。
技术实现要素:
发明目的:本发明的目的在于解决现有技术中存在的不足,提供一种基于序列比对的二进制未知协议报文格式划分方法,本发明能够根据网络流量对二进制未知协议进行格式划分。
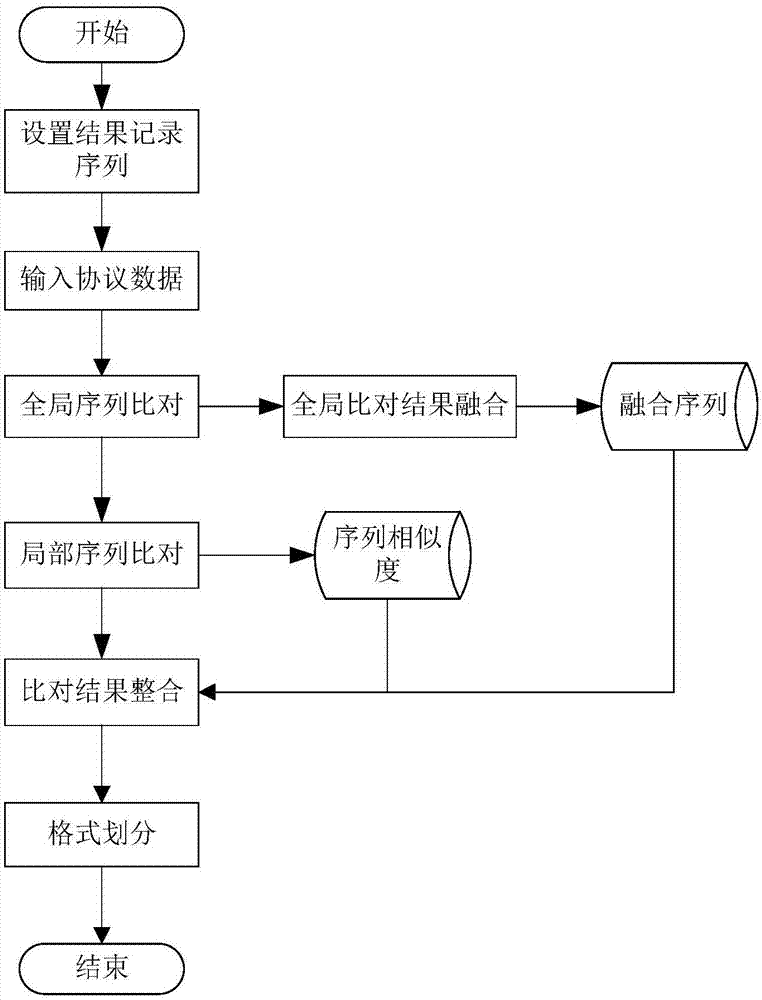
技术方案:本发明的一种基于序列比对的二进制未知协议报文格式划分方法,依次包括以下步骤:
(1)通过对获取的网络流量进行特征提取、特征筛选、聚类等步骤的预处理,得到单一类型的协议序列集合;
(2)初始化一条记录比对结果的序列,将该序列的初始值都设为零;
(3)对协议序列集合中的序列两两进行局部序列比对和全局序列比对,具体过程为:
(3.1)对于每一条协议序列,都需要和集合中与自身不完全相同的所有协议序列进行一次全局序列比对和一次局部序列比对;
(3.2)使用needleman-wunsch序列比对算法进行全局序列比对,并将比对结果按规则融合为一条序列;
(3.3)使用smith-waterman序列比对算法进行局部序列比对得到序列相似度,并设置空位匹配和不匹配两种情况下的基础值;
(4)根据步骤(3.2)和步骤(3.3)中得到的融合序列、序列相似度和基础值修改结果序列;
(5)根据步骤(4)中的结果序列,将结果序列中到达局部峰值后出现较明显下降趋势的点对应的横坐标值推断为协议格式划分位置。
进一步的,所述步骤(3.2)中具体的融合步骤为:
对于在全局匹配过程中产生的空位匹配和不匹配情况,分别在融合序列中使用特殊符号进行标记,即对于匹配成功的字符始终保留,对于序列中出现插空的位置,使用特殊符号gap替代,对于匹配失败但保持对齐的位置,使用特殊符号dif替代。
进一步的,所述步骤(4)中对结果序列进行修改的具体步骤为:根据融合序列中各个位置的符号标记类型确定基础值大小,使用该基础值除以序列相似度,将计算得到的数值添加到结果序列中对应位置的的值上。
有益效果:本发明先设置结果序列,再对协议数据两两进行处理并将结果整合到结果序列中,避免在算法过程中反复多次遍历相似度矩阵寻找局部相似度最高的序列和对矩阵进行修改,降低了时间复杂度。本发明提出在全局序列比对后进行序列融合,改善了现有技术在应用序列比对算法时,由于多次进行比对产生过多插空操作造成边界位置移动的问题,从而能够较为准确和有效地进行格式推断。
附图说明
图1为本发明的流程图。
具体实施方式
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
本发明的一种基于序列比对的二进制未知协议报文格式划分方法,依次包括以下步骤:
(1)通过对获取的网络流量进行特征提取、特征筛选和聚类等步骤,得到单一类型的协议序列集合;
(2)初始化一条记录比对结果的序列,将该序列的初始值都设为零;
(3)对协议序列集合中的序列两两进行局部序列比对和全局序列比对,具体过程为:
(3.1)对于每一条协议序列,都需要和集合中与自身不完全相同的所有协议序列进行一次全局序列比对和一次局部序列比对;
(3.2)使用needleman-wunsch序列比对算法进行全局序列比对,并创新性地将比对结果按一定规则融合为一条序列:对于在全局匹配过程中产生的空位匹配和不匹配情况,分别在融合序列中使用特殊符号进行标记,即对于匹配成功的字符始终保留,对于序列中出现插空的位置,使用特殊符号gap替代,对于匹配失败但保持对齐的位置,使用特殊符号dif替代;
(3.3)使用smith-waterman序列比对算法进行局部序列比对,将比对结果记作序列相似度,并设置空位匹配和不匹配两种情况下的基础值;
(4)根据步骤(3.2)和步骤(3.3)中得到的融合序列、序列相似度和基础值修改结果序列;根据融合序列中各个位置的符号标记类型确定基础值大小,使用该基础值除以序列相似度,将计算得到的数值添加到结果序列中对应位置的的值上。
(5)根据步骤(4)中的结果序列,将结果序列中到达局部峰值后出现较明显下降趋势的点对应的横坐标值推断为协议格式划分位置。
实施例:
如图1所示,本实施例的一种基于序列比对的二进制未知协议报文格式划分方法,对于待进行格式划分的网络流量集合g(集合g为已经经过预处理,仅包含单种协议的协议数据集),g中的元素g为某种未知协议格式的字符序列,最长字符序列的长度为len。
处理步骤如下:
1、初始化比对结果记录序列seq[n],其中n=1,2,…,2*len,表示协议序列的某个位置。
初始化后,seq[n]序列的每个位置初始值都为0。2*len为比对结果记录序列seq的最长值,实际处理中seq的长度可能会小于2*len。在协议格式划分中,需要考虑尽可能挖掘和保留序列数据集合中的多样性特征,也就是说需要尽可能将每一条带有独特信息序列的特征都反映到最终结果中去。
因此本实施例采用基于序列比对的方法对协议格式进行划分,在序列比对的过程中通过修改序列seq[n]的值,完成比对结果整合,并最终通过该序列进行格式划分推测。
2、对输入的单协议序列集合g中的序列两两进行全局序列比对和局部序列比对,并将全局序列比对结果进行融合,将局部序列比对结果记录为序列相似度。在两两比对结束后,得到融合序列集合g'和序列相似度集合s。具体步骤为:
2.1对于序列集合g中任意两条不完全相同的序列g1和g2,首先使用needleman-wunsch全局序列比对算法进行全局序列比对。设定相关得分参数,例如设定匹配得分为1分,不匹配为-1分,空位匹配为-2分,算法会输出总得分最高情况下的两条等长度且各位置对应的序列,当序列g1=“gccctagcg”,序列g2=“gcgcaatg”时,使用needleman-wunsch算法进行序列比对后得到的结果为:序列g1'=“gccctagcg”,序列g2'=“gcgc-aatg”(其中插空操作插入的空格使用“-”表示),比对结果表明在序列的第三、七、八个字符处出现了三次不匹配,在第五个字符处出现了一次空位匹配。
2.2将2.1中得到的全局序列比对结果进行融合,即使用一条新的序列来表示序列比对后得到的结果。对于在序列比对过程中产生的空位匹配和不匹配情况,分别在融合后的新序列中使用特殊符号进行标记。序列融合策略为:对于匹配成功的字符始终保留,对于序列中出现插入空格的位置,在融合序列中使用特殊符号gap替代,对于字符不匹配但依然对齐的位置,使用特殊符号dif替代。对于2.1中的样例序列g1和g2,将其全局序列比对的结果融合后得到的序列为g12=“gc(dif)c(gap)a(dif)(dif)g”(特殊符号使用括号括出)。
2.3此处以步骤2.1中提到的g1和g2两条序列为例,使用smith-waterman局部序列比对算法进行局部序列比对,设定匹配、不匹配和空位匹配等得分参数不变,对于输入的两条序列g1和g2,算法会输出局部序列比对的得分为3分,在本实施例中使用该局部比对的分值表示序列之间的相似度,记为s12=3。
3、使用步骤2中得到的g12和s12对序列seq[n]进行更新。具体步骤为:首先设置gapcoef和difcoef,表示当字符串中某个位置的取值波动表现为空位匹配和不匹配两种情况下,将比对结果整合到序列中时所需要的基础值。然后根据融合序列g12中各个位置的符号标记确定选用的基础值,再除以步骤2中计算得到的序列相似度s12,就可以得到一个具体数值,将该数值添加到序列seq[n]相应n对应的值上,即可实现序列比对结果的整合。例如,使用步骤2.2中得到的g12和其对应的步骤2.3中得到的相似度s12进行结果整合,当n=1时,由于g12的第一位为字母“g”,并非特殊符号,因此直接跳过不作处理。当n继续递增,直到n=3时,由于g12的第三位为dif符号,则需要修改seq[3]=seq[3]+s12/difcoef。由于本实施例在序列比对时,设置的空位匹配为-2分,不匹配为-1分,所以对应的设置基础值difcoef为2,gapcoef为1。
4、根据序列seq[n]推断协议格式。一般来说,协议的不同字段之间变化率一般存在较大差异,且对于协议中较长的字段,从字段的起始处到末尾处,变化率往往是增大的趋势。例如在协议设计时,需要设计一个长为一字节、可以有两种取值的字段,那么在协议设计的时候会选择从低位开始进行取值变化,将这两种取值设计为00和01,意味着对于该字段在后续还可以加入02,03等更多种类的取值情况。而不会选择在高位进行变化,设计成10和00两种取值,这种在高位进行区分的方法无论在可读性还是后期扩展上,都存在较大问题,显然是不合理的。考虑以上协议设计的经验规则,结合之前序列比对和比对结果整合后得到的序列seq[n],可以发现序列seq[n]实际上反映了协议序列各个位置的变化程度,将序列seq[n]画成点图并连线,其图像的局部波峰正是协议序列取值变化最剧烈的位置所在,如果图像到达波峰之后开始出现较明显的下降,意味着该波峰处极有可能对应了协议中的字段边界。筛选出图像中达到局部峰值后出现较明显下降趋势的点对应的n值,就可以得到边界划分的推测结果。
综上所述,本发明在全局序列比对后进行序列融合,改善了现有技术在应用序列比对算法时,由于多次进行比对产生过多插空操作造成边界位置移动的问题,从而能够较为准确和有效地进行格式推断。
- 还没有人留言评论。精彩留言会获得点赞!