一种基于关键词识别的无线电识别方法与流程
本发明涉及无线电识别领域,具体涉及一种基于关键词识别的无线电识别方法。
背景技术
由于无线电广播技术自身的开放性,所有有发射需求的用户,只需要占据特定的频段,即可通过发射信号进行广播。因此,时常有出于不同目的用户,在批准发射的频率之外,擅自占据频段进行广播发射(俗称“黑广播”,即非法广播)。在这之中,出于经济目的非法广播发射尤为明显,其内容以售卖假冒伪劣产品居多,严重扰乱经济秩序。另外,即便是一些非主观恶意的私占频段发射(如无线电爱好者自行搭建平台),也会扰乱正常电子通讯的运转,在某些情况下甚至会干扰关键性通讯设备(如飞机飞航通讯频段),引发严重的安全隐患。因此,进行有效的无线电识别,进而便于无线电电磁频谱管控是一项意义重大的课题。
传统的无线电识别主要是基于人工收听并识别的方法,具有成本高、效率低、操作人员疲劳易引发失误等缺点。
现有语音识别模型通常针对整句识别、语义判定而设计的,其大部分只提供线上使用功能,无法离线使用,可以移植性差,且整句识别会使得识别成功率大大降低,存在噪声的情况下识别成功率也很低,不适用于无线电识别领域。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种基于关键词识别的无线电识别方法解决了现有无线电识别方法成本高效率低的问题。
为了达到上述发明目的,本发明采用的技术方案为:
提供一种基于关键词识别的无线电识别方法,其包括以下步骤:
s1、建立声学模型,将无线电广播识别为文字;
s2、建立语言模型,提取所识别文字中的关键词;
s3、根据提取的关键词判断该无线电广播是否合法。
进一步地,步骤s1的具体方法为:
采用cmusphinx模型的基础中文模型作为基底,通过逐句分音节标注样本信号,基于最大后验概率对该基底进行参数自适应操作,得到声学模型,其表达式如下:
其中x表示某一个音节;p(x)为输出某一个音节的概率;p(m)为高斯概率密度函数的权值;μm和σm2是高斯分布的参数;p(x|m)为第m个模块下输出某一个音节的概率;m为基础中文模型的高斯子模型总数量;m为第m个基础中文模型的高斯子模型;i为单位矩阵;n(·)为多元高斯分布。
进一步地,步骤s2的具体方法为:
根据cmusphinx词典及语言模型生成器建立语言模型,将样本词作为提取条件,提取与样本词相同的词作为关键词,其具体步骤为:
s2-1、建立文本文件,在文本文件的每一行中加入样本关键词;
s2-2、通过在线语言模型生成工具对文本文件进行语言模型及词典的生成,完成语言模型的建立;
s2-3、通过语言模型提取所识别文字中的关键词。
进一步地,步骤s3的具体方法为:
根据专家系统将样本词进行组合得到判断该无线电广播内容是否合法的判定条件,将关键词不符合判定条件的无线电广播作为非法广播,将关键词符合判定条件的无线电广播作为正常广播。
本发明的有益效果为:本发明基于人工智能发展的成果进行综合改进,使得无线电识别可以实现自动化,极大的节省了成本、提升了效率;本方法针对无线电广播信号的特点,能够最大化的满足不同需求;本方法可以离线使用,特别适合于需要保密的项目中;并且能在存在背景音乐或其他噪声的情况下进行识别,便于应用于更广泛的场景当中。
附图说明
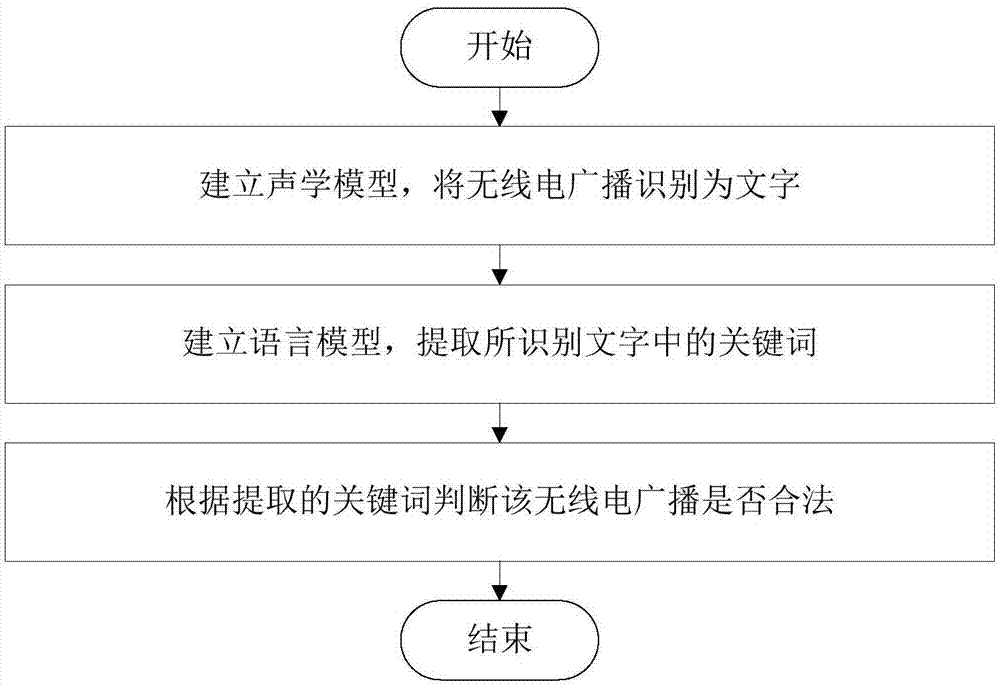
图1为本发明的流程示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,该基于关键词识别的无线电识别方法包括以下步骤:
s1、建立声学模型,将无线电广播识别为文字;
s2、建立语言模型,提取所识别文字中的关键词;
s3、根据提取的关键词判断该无线电广播是否合法。
步骤s1的具体方法为:
采用cmusphinx模型的基础中文模型作为基底,通过逐句分音节标注样本信号,其表达式如下:
其中x表示某一个音节;p(x)为输出某一个音节的概率;p(m)为高斯概率密度函数的权值;μm和σm2是高斯分布的参数;p(x|m)为第m个模块下输出某一个音节的概率;m为基础中文模型的高斯子模型总数量;m为第m个基础中文模型的高斯子模型;i为单位矩阵;n(·)为多元高斯分布。
具体地,我们首先安装cmusphinx的sphinxbase环境,并在下载cmusphinx的基础的中文识别模型zh_broadcastnews_ptm256_8000。值得注意的是,尽管基础模型从操作上来讲可以直接进行关键字识别,但其准确率会非常差。所以,这里我们需要进行模型改进。
声学模型改进需要提取无线电广播的内容,并逐句分音节标注样本。其具体操作为,截取50-100句3-5秒的广播录音,其内容需要较为清晰,存储为.wav格式;然后在与广播录音相同的路径下,建立句子描述文件(.transcript)、录音匹配文件(.field)和改进词典(.dic)。其中,句子描述文件记录了按词组拆分的句子,需要人工加入空格断句(如,现在是北京时间十一点应写为“现在是北京时间十一点”);录音匹配文件记录各句子对应的录音文件名(如radiorecord1);而辞典则记录了录音匹配文件中每个词组的发音,其基本音节发音可以在完整的sphinxbase辞典中寻找匹配。
在完成了上述工作后,可以根据cmusphinx提供的接口(pocketsphinx)将文件转码为相应的格式。首先,将所有的.wav文件转为mfc文件;而后,将原模型中的参数文件转换为文本;最后,统计所有的音频文档的信息,并根据句子描述文件、录音匹配文件和辞典分别进行匹配,从而得到mixw_counts、gauden_counts和tmat_counts三个获取了录音信息的文件。在完成了上述操作后,可以使用最大后验概率的方法对基础模型的参数进行调整。
步骤s2的具体方法为:根据cmusphinx词典及语言模型生成器建立语言模型,将样本词作为提取条件,提取与样本词相同的词作为关键词,其具体步骤为:
s2-1、建立文本文件,在文本文件的每一行中加入样本关键词;
s2-2、通过在线语言模型生成工具对文本文件进行语言模型及词典的生成,完成语言模型的建立;
s2-3、通过语言模型提取所识别文字中的关键词。
步骤s3的具体方法为:
根据专家系统将样本词进行组合得到判断该无线电广播内容是否合法的判定条件,将关键词不符合判定条件的无线电广播作为非法广播,将关键词符合判定条件的无线电广播作为正常广播。
本发明基于人工智能发展的成果进行综合改进,使得无线电识别可以实现自动化,极大的节省了成本、提升了效率;本方法针对无线电广播信号的特点,实现可定制化,能够最大化的满足不同需求;本方法可以离线使用,特别适合于需要保密的项目中;并且能在存在背景音乐或其他噪声的情况下进行识别,便于应用于更广泛的场景当中。
- 还没有人留言评论。精彩留言会获得点赞!