反爬虫方法、装置、电子设备及计算机可读存储介质与流程
本发明涉及互联网监测领域,特别涉及一种反爬虫方法、装置、电子设备及计算机可读存储介质。
背景技术:
互联网(英语:internet),是网络与网络之间所串连成的庞大网络,这些网络以一组标准的网络tcp/ip协议族相连,连接全世界几十亿个设备,形成逻辑上的单一巨大国际网络。它是由从地方到全球范围内几百万个私人的、学术界的、企业的和政府的网络所构成,通过电子,无线和光纤网络技术等等一系列广泛的技术联系在一起。这种将计算机网络互相联接在一起的方法可称作“网络互联”,在这基础上发展出覆盖全世界的全球性互联网络称互联网,即是互相连接一起的网络。互联网并不等同万维网(www),万维网只是一个基于超文本相互链接而成的全球性系统,且是互联网所能提供的服务其中之一。互联网带有范围广泛的信息资源和服务,例如相互关系的超文本文件,还有万维网的应用,支持电子邮件的基础设施,点对点网络,文件共享,以及ip电话服务。
爬虫相比于人,可以有更快的检索速度和更深的层次,所以,他们可能使一个站点瘫痪。不需要说一个单独的爬虫一秒钟要执行多条请求,下载大的文件,一个服务器也会很难响应多线程爬虫的请求。就像koster所注意的那样,爬虫的使用对很多任务都是很有用的,但是对一般的社区,也需要付出代价。使用爬虫的代价包括:
网络资源:在很长一段时间,爬虫使用相当大的带宽高度并行地工作。
服务器超载:尤其是对给定服务器的访问过高时。
质量糟糕的爬虫,可能导致服务器或者路由器瘫痪,或者会尝试下载自己无法处理的页面。
个人爬虫,如果过多的人使用,可能导致网络或者服务器阻塞。
如此多问题,急待开发出反爬虫的技术,以避免云端网站资源被网路爬虫过度消耗。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供一种反爬虫方法、装置、电子设备及计算机可读存储介质,其通过收集用户端的行为日志,进行数据分析、训练并构建出用户端访问网站的行为模型后以过滤非正常的访问。
本发明解决其技术问题所采用的技术方案是:一种基于用户端行为的反爬虫方法,其包括以下步骤:
系统响应于用户端的访问行为,通过服务器和/或所述用户端采集待测访问信息;
系统判断所述待测访问信息是否与预先建立的用户行为模型相符,如不相符,则将所述用户端的访问行为作为异常访问行为,并进行预警;
所述用户行为模型具体为,系统响应于用户端的合法访问行为,通过服务器和/或所述用户端采集合法访问信息;根据所述合法访问信息构建所述用户行为模型。
进一步,所述待测访问信息包括以下至少一种:mac地址、ip地址、访问时间、停留时间、点击位置、点击事件、用户端地理位置及用户端喜好。
进一步,所述合法访问信息包括以下至少一种:mac地址、ip地址、访问时间、停留时间、点击位置、点击事件、用户端地理位置及用户端喜好。。
进一步,所述当对应比对任一不同时,是所述mac地址为不同mac地址。
进一步,所述当对应比对任一不同时,是所述ip地址为不同ip地址。
进一步,所述当对应比对任一不同时,是所述访问时间为不同访问时间的差值大于一门坎值。
进一步,所述当对应比对任一不同时,是所述停留时间为不同停留时间的差值大于一门坎值。
进一步,所述当对应比对任一不同时,是所述点击位置为不同点击位置。
进一步,所述当对应比对任一不同时,是所述用户端地理位置为不同用户端地理位置。
进一步,所述当对应比对任一不同时,是所述用户端喜好为不同用户端喜好。
进一步,当对应比对访问数据信息和访问数据信息有任一不同时,所述服务器发出一预警讯息,还包括:进一步降低用户端允许访问频次。
本发明解决其技术问题所采用的技术方案是:一种基于用户端行为的反爬虫装置,包括:
采集模块,用于响应用户端的访问行为,通过服务器和/或所述用户端采集待测访问信息;
判断模块,用于判断所述待测访问信息是否与预先建立的用户行为模型相符,当所述待测访问信息是否与预先建立的用户行为模型不相符时,将所述用户端的访问行为作为异常访问行为,并进行预警;
所述用户行为模型具体为,响应于用户端的合法访问行为,通过服务器和/或所述用户端采集合法访问信息;根据所述合法访问信息构建所述用户行为模型。
本发明解决其技术问题所采用的技术方案是:一种电子装置,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
所述存储器,用于存放计算机程序;
所述处理器,用于执行存储器上所存放的程序时,实现所述的反爬虫方法的任一实施例。
本发明解决其技术问题所采用的技术方案是:一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现所述的反爬虫方法的任一实施例。
本发明一种反爬虫方法、装置、电子设备及计算机可读存储介质,具有以下有益效果:
透过记录所述用户端的所述待测访问信息;当所述用户端再次进入所述网站时,所述服务器内进行侦测所述用户端的所述待测访问信息;借此比对对应的记录,当任一不同时,由服务器发出预警信息,从而通知服务器的管理人员使其得知目前登入服务器的用户端的用户端行为是爬虫行为,甚至进一步降低用户端的允许访问频次,以减少或避免网站被爬虫的频次。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
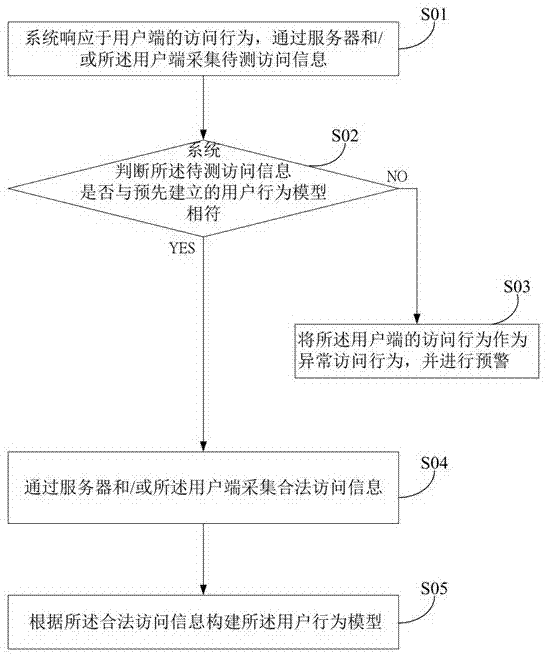
图1为本发明基于用户端行为的反爬虫方法一个实施例中方法的流程图;
图2为本发明基于用户端行为的反爬虫方法另一个实施例中方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明基于用户端行为的反爬虫方法实施例中,其基于用户端行为的反爬虫方法的流程图如图1所示。图1中,该基于用户端行为的反爬虫方法包括如下步骤:
步骤s01:系统响应于用户端的访问行为,通过服务器和/或所述用户端采集待测访问信息;
步骤s02:系统判断所述待测访问信息是否与预先建立的用户行为模型相符;
步骤s03:将所述用户端的访问行为作为异常访问行为,并进行预警;
步骤s04:通过服务器和/或所述用户端采集合法访问信息;
步骤s05:根据所述合法访问信息构建所述用户行为模型。
本实施例中,步骤s01为在用户端或服务器依据插件程序的执行进行埋点,以在服务器或用户端中进行采集待测访问信息,用以判断用户端的访问行为。
其中系统为采集访问数据信息,包括以下至少一种:mac地址、ip地址、访问时间、停留时间、点击位置、点击事件、用户端地理位置及用户端喜好并记录,例如:记录所述用户端的首次访问数据信息,包括以下至少一种:一第一mac位置、一第一ip位置、一第一访问时间、一第一停留时间、一第一点击位置、一第一点击事项、一第一用户端地理位置及一第一用户端喜好,以及采集所述用户端的首次访问之后访问数据信息,任一次访问可视为二次访问行为,而为采集二次访问数据信息,包括以下至少一种:一第二mac位置、一第二ip位置、一第二访问时间、一第二停留时间、一第二点击位置、一第二点击事项、一第二用户端地理位置及一第二用户端喜好。
其中,步骤s02中,系统将对以上所采集到访问数据信息进行处理,即针对收集到的数据信息存在的各种异常情况,如数据缺失、数据值异常等进行清除处理,以避免后续处理失败或无法继续运行。
在判断过程中,系统判断所述待测访问信息与预先建立的用户行为模型不相符时,执行步骤s03,倘若所述用户行为模型具体为,系统响应于用户端的合法访问行为,则执行步骤s04。
在步骤s04中,系统为通过服务器和/或所述用户端采集合法访问信息,也就是采集mac地址、ip地址、访问时间、停留时间、点击位置、点击事件、用户端地理位置及用户端喜好的其中至少一者。
在步骤s05中,利用kmean、svm算法训练样本获得用户端特征数据并且建立标签体系,且根据不同的标签对应不同的行为进行数据采集。
例如用户端a拥有以下访问行为特征并记录为访问数据信息。
1)最常登陆地点北京、南京;
2)最常范围时间段(10:00-12:00);
3)每页平均停留时间1分钟;
4)验证码平均输入时间10秒;
5)平均最多翻10页;以及
6)最常浏览艺术类主题。
借此,将用户端每次登入到网站或服务器的过程与结果一一采集并在步骤s04中,依据最初采集到的记录与后续采集到的数据一一比对,或者是依据第一笔有效的记录进行比对。
复参阅步骤s02中,服务器取得后续用户a的用户行为,例如用户a突然出现以下行为:
1)在凌晨频繁范问
2)每个页面停留1秒
3)最多翻页达到1000页
4)浏览主题增加20大类
服务器通过侦测用户行为的登入时间以及翻页页数、停留时间与主题数目,也就是第一登入时间与第二登入时间的差值过大,且第一用户喜好不同于第二用户喜好时,系统判断系统判断所述待测访问信息与预先建立的用户行为模型不相符,因此系统判断出执行步骤s03,由用户端异常并发出预警信息,此时并不阻拦用户访问。
除此之外,在所述mac地址不同于所述第二mac位置,也就是是所述mac地址为不同mac地址时,或在所述第一ip位置不同于所述第二ip位置,也就是所述ip地址为不同ip地址时,或在所述第一停留时间与所述第二停留时间的差值大于一门坎值(例如:停留时间超过1分钟),或在所述第一点击位置不同于所述第二点击位置时,在所述第一用户端地理位置不同于所述第二用户端地理位置时,也就是任一不同时,接续执行步骤s03,服务器的插件程序皆判断用户异常,服务器皆会后续发出预警信息。在步骤s04中,当系统判断所述用户行为模型具体为系统响应于用户端的合法访问行为时,通过服务器和/或所述用户端采集合法访问信息,也就是采集采集合法访问信息,也就是采集mac地址、ip地址、访问时间、停留时间、点击位置、点击事件、用户端地理位置及用户端喜好的其中至少一者。
本发明不仅在于发出预警信息,更可进一步透过服务器的设定,而将客户端的允许访问频次降低,即当对应比对首次访问数据信息和二次访问数据信息有任一不同时,所述服务器发出一预警讯息,还包括:进一步降低用户端允许访问频次,以下图2的实施例,为降低用户端允许访问频次。
在本发明基于用户端行为的反爬虫方法实施例中,其基于用户端行为的反爬虫方法的流程图如图2所示。图2中,该基于用户端行为的反爬虫方法包括如下步骤:
步骤s11:系统响应于用户端的访问行为,通过服务器和/或所述用户端采集待测访问信息;
步骤s12:系统判断所述待测访问信息是否与预先建立的用户行为模型相符;
步骤s13:将所述用户端的访问行为作为异常访问行为,并进行预警;
步骤s14:当对应比对首次访问数据信息和二次访问数据信息有任一不同时,所述服务器发出一预警讯息。
步骤s15:通过服务器和/或所述用户端采集合法访问信息;
步骤s16:根据所述合法访问信息构建所述用户行为模型。
本实施例中,步骤s11至步骤s13及步骤s15至步骤s16相同于上述步骤s01至步骤s05,因此不再赘述,以下将重点描述步骤s14:
其中,本发明的反爬虫方法,除了先行发出预警信息,供服务器的管理人员得知,有用户端进行爬虫行为,进一步而言,本发明更是降低用户端的允许访问频次,其中,服务器与用户端皆内嵌有插件程序,进行埋点,在执行插件程序的过程中,得知比对所述mac地址、所述ip地址、所述访问时间、所述停留时间、所述点击位置、所述点击事件、所述用户端地理位置及所述用户端喜好的比对结果有任一不同时,除了发出预警信息,服务器更是针对所述比对结果有任一不同的用户端降低允许访问频次。
借此,从而避免或减少网站或服务器被爬取的次数。
以上实施例为应用于一反爬虫装置,所述反爬虫装置包括采集模块与判断模块,其中采集模块,用于响应用户端的访问行为,通过服务器和/或所述用户端采集待测访问信息;而,判断模块,用于判断所述待测访问信息是否与预先建立的用户行为模型相符,当所述待测访问信息是否与预先建立的用户行为模型不相符时,将所述用户端的访问行为作为异常访问行为,并进行预警;且所述用户行为模型具体为,响应于用户端的合法访问行为,通过服务器和/或所述用户端采集合法访问信息;根据所述合法访问信息构建所述用户行为模型。
抑或,以上实施莉可应用于一种电子装置,所述电子装置包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;所述存储器,用于存放计算机程序;所述处理器,用于执行存储器上所存放的程序时,实现所述的反爬虫方法的任一实施例。
进一步,本发明更可为一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现所述的反爬虫方法的任一实施例,以应于采集访问数据信息,并在异常情况下,提出预警,甚至是降低访问次数,或者是在访问数据信息为合法的情况下,建立信息模型。
总之,上述插件程序是内嵌到网站或其服务器中,及内嵌到用户端中进行埋点,以采集到用户端每次登入后的过程与结果,并一一呈现于服务器并保存,供后续比对分析,以及在确认用户端的爬虫行为后,发出预警信息以警告进行爬虫行为的用户端,且当多次比对判断后结果仍为异常时则降低用户端的允许访问频次。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!