一种3D音效系统的制作方法
本发明涉及3d音效领域,更具体地说,涉及一种3d音效系统。
背景技术:
主体位姿预判方法3d技术与传统做法最大的不同之处,在于它可以只利用一组喇叭或者是耳机,就可以发出逼真的立体声效,定位出环绕使用者身边不同位置的音源。这种音源追踪的能力,就叫做定位音效,它使用当时的hrtf的功能来达到这种神奇的效果。
所谓hrtf的全名是he主体位姿预判方法d—rel主体位姿预判方法tedtr主体位姿预判方法nsferfunction(头部相关位置转换),就是在三度立体空间中,人耳是如何监测和分辨出声音来源的方法。简单的说一下,就是声波会以几百万分之一秒的差距先后传到你的耳朵里面,而我们的大脑可以分辨出那些细微的差别,利用这些差别来分辨声波的形态,然后在换算成声音在空间里的位置来源。
在目前多数的3d音效的声卡上,都是使用hrtf的换方法来转换游戏里的声音效果,误导你的大脑听到声音是来自不同地方的。支援声源定位的游戏将声音与游戏的物件、人物或是其他的声音的来源结合在一起,当这些声音与你在游戏中的位置改变时,声卡就将依据相对位置来调整声波讯号的发送。
而目前随着3d眼镜技术的普及和应用,而可以实现对主体头部的位姿进行采样,而原有的3d音效方法由于首先需要确定声源,然后根据声源的位置以及声源的内容根据主体的位置进行换算,然后根据主体的位姿换算得到不同的功放单元的输出的声音数据,而这样由于计算量较大,所以非常容易出现时延,影响用户体验,而目前是通过预处理进行对声音数据的提前获取以保证数据的连续性,原理是通过提前计算主体可能的位姿,然后实际主体位姿,如果实际主体位姿与预判的位姿相同,就可以直接输出计算结果,减小处理时间,保证声音的连续性,但是对预判的准确性是一个较大问题,如果连续预判失误,会造成较大的时延,影响音效。
技术实现要素:
有鉴于此,本发明目的是提供一种3d音效系统,以解决上述问题。
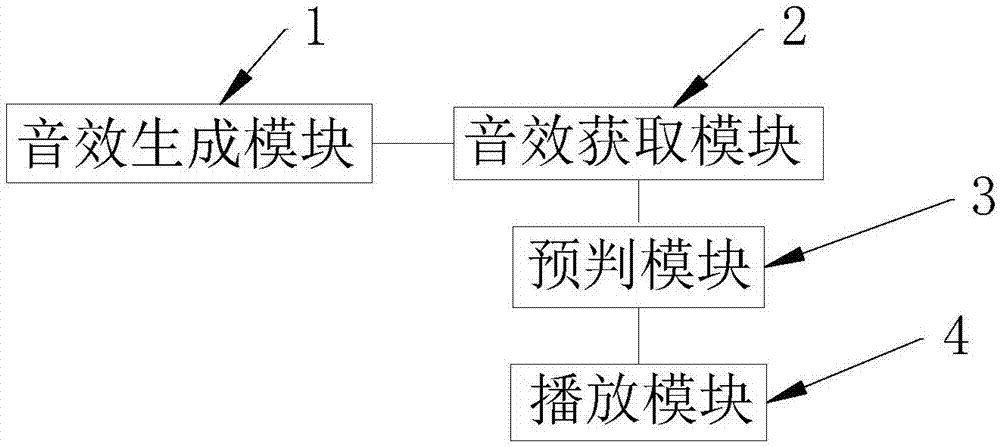
为了解决上述技术问题,本发明的技术方案是:一种3d音效系统,包括主体位姿捕获设备、对应主体左耳的左功放、对应主体右耳的右功放,所述主体位姿捕获设备用于捕获主体的位姿信息,包括音效生成模块、音效获取模块、预判模块以及播放模块;
所述音效生成模块用于根据音源在主体所对应的功放输出声音信息,每一音源对应有音源位置以及第一音源内容,所述第一音源内容包括每一对应时刻下的音源数据,所述主体具有若干个预设位姿,每一预设位姿具有与主体左耳对应的第一位姿点以及与主体右耳对应的第二位姿点;
所述音效生成模块包括构坐标步骤、内容关联步骤、相位关联步骤以及位姿关联步骤;
构坐标步骤包括建立一环境坐标系,根据音源位置在所述环境坐标系中确定每一音源的位置;
内容关联步骤包括在所述环境坐标系中确定主体的活动区域,并根据每一音源以及主体的活动区域中每一位置生成对应的第二音源信息,每一所述第二音源信息包括若干第二音源内容,每一所述第二音源内容和每一所述第一音源内容对应,所述第二音源内容包括每一对应时刻下的音源数据,以环境坐标系的位置为参量根据第二音源信息构建位置内容关联模型;
相位关联步骤包括根据每一音源位置以及主体的活动区域中每一位置生成对应的第三音源信息,每一第三音源信息包括若干声音相位参数,每一所述声音相位参数与每一音源位置对应,以环境坐标系的位置为参量根据第三音源信息构建位置相位关联模型;
位姿关联步骤包括根据每一主体的活动区域中每一位置以及每一预设位姿生成定位信息,所述定位信息包括每一预设位姿下,第一位姿点在环境坐标系的位置以及第二位姿点在环境坐标系的位置,以环境坐标系的位置为参量根据定位信息构建位姿位置关联模型;
所述音效获取模块包括定位获取步骤、相位获取步骤、内容获取步骤以及声音生成步骤;
定位获取步骤包括主体位姿捕获设备捕获主体位姿信息,将主体位姿信息以及主体位置信息输入到位姿位置关联模型中以得到定位信息;
相位获取步骤包括解析定位信息以得到第一定位子信息以及第二定位子信息,所述第一定位子信息反映主体作为在所述环境坐标系中的位置,所述第二定位子信息反映主体右耳在环境坐标系的位置,将第一定位子信息和第二定位子信息分别输入到位置相位关联模型以得到第一声音相位信息以及第二声音相位信息,所述第一声音相位信息为主体左耳在环境坐标系下的位置对应的第三音源信息,所述第二声音相位信息为主体右耳在环境坐标系下的位置对应的第三音源信息;
内容获取步骤包括将所述第一定位子信息和所述第二定位子信息分别输入到位置内容关联模型以得到第一声音内容信息以及第二声音内容信息,所述第一声音内容信息为主体左耳在环境坐标系下的位置对应的第二音源信息,所述第二声音内容信息为主体右耳在环境坐标系下的位置对应的第二音源信息;
声音生成步骤,根据第一声音相位信息和第一声音内容信息、第二声音相位信息和第二声音内容信息生成此时的声音播放信息;
所述预判模块包括第一获取步骤、位姿预判步骤、预判计算步骤、第二获取步骤以及位姿判断步骤;
第一获取步骤包括获取此时的主体的位姿信息;
位姿预判步骤包括根据此时的主体的位姿信息以及当前时刻以一随机权重分配算法生成方向预判信息,每一方向预判信息包括一个方向预判角度范围,所述方向预判角度范围反映所述主体的转动的角度,根据所述方向预判信息生成下一时刻的主体的预判位姿信息,所述随机权重分配算法根据此时的每一方向预判信息分配有对应的权重值,对应的权重值越大,则该方向预判信息更容易被所述随机权重分配算法选中;
预判计算步骤包括将所述预判位姿信息输入到所述音效获取模块中以获得预判的声音播放信息;
第二获取步骤包括获取下一时刻的主体的位姿信息;
位姿判断步骤包括根据下一时刻的位姿信息计算所述主体的转动方向,若所述主体的转动方向在所述方向预判角度范围内,则将预判得到的声音播放信息输入到播放模块,并增加该方向预判信息的权重值;若所述主体的转动方向在所述方向预判角度范围之外,则将下一时刻的主体位姿信息输入到音效获取模块中,将得到的声音播放信息输入到播放模块,且减小该方向预判信息的权重值;
所述播放模块用于播放所述声音播放信息。
进一步地,通过第一换算策略根据每一音源以及主体的活动区域中每一位置生成对应的第二音源信息,通过第二换算策略根据每一音源位置以及主体的活动区域中每一位置生成对应的第三音源信息;通过第三换算策略根据每一主体的活动区域中每一位置以及每一预设位姿生成定位信息。
进一步地,所述内容关联步骤还包括获取环境参数,所述第一换算策略还根据所述环境参数生成第二音源信息。
进一步地,所述环境参数包括温度参数、湿度参数以及反射面参数。
进一步地,在每一时刻下,所述主体的转动角度为主体在环境模型中的三维空间中的转动角度,对应的方向预判信息设置为16个,每一方向预判信息对应的方向预判角度范围设置为90度。
进一步地,所述主体的转动角度为主体在环境模型中的预设平面的等效转动角度。
进一步地,在每一时刻下,对应的方向预判信息设置为12个,每一方向预判信息对应的方向预判角度范围设置为30度。
进一步地,所述位姿判断步骤配置有划分子步骤,所述划分子步骤配置有划分权重阈值,当一方向预判信息对应的权重值超过权重阈值时,将所述方向预判信息分成至少两个新的方向预判信息,每一新的方向预判信息均分原所述方向预判信息的权重值以及方向预判角度范围。
本发明技术效果主要体现在以下方面:相比原来需要实时进行复杂计算,本发明采用检索法实现对3d音效进行获取,更加的简单便利,大大提高了响应效率。以自学习的算法方式通过判断主体在预设场景和时刻下的转向习惯进行优化得到预判断主体的下一时刻的转动方向,提前获取对应的声音信息,提高精度。
附图说明
图1:本发明的一种3d音效系统的架构原理图;
图2:本发明的一种3d音效系统的环境坐标系原理图。
附图标记:1、音效生成模块;2、音效获取模块;3、预判模块;4、播放模块。
具体实施方式
以下结合附图,对本发明的具体实施方式作进一步详述,以使本发明技术方案更易于理解和掌握。
一种3d音效系统,包括主体位姿捕获设备、对应主体左耳的左功放、对应主体右耳的右功放,所述主体位姿捕获设备用于捕获主体的位姿信息,包括音效生成模块1、音效获取模块2、预判模块3以及播放模块4;
所述音效生成模块1用于根据音源在主体所对应的功放输出声音信息,每一音源对应有音源位置以及第一音源内容,所述第一音源内容包括每一对应时刻下的音源数据,所述主体具有若干个预设位姿,每一预设位姿具有与主体左耳对应的第一位姿点以及与主体右耳对应的第二位姿点;
所述音效生成模块1包括构坐标步骤、内容关联步骤、相位关联步骤以及位姿关联步骤;以下以4个声源为例,a,b,c,d,做出详述。
构坐标步骤,建立一环境坐标系,根据音源位置在所述环境坐标系中确定每一音源的位置;如图所示,四个声源的位置的坐标依次为(x1,y1,z1),(x2,y2,z2),(x3,y3,z3),(x4,y4,z4),这样就可以建立声源关系。
内容关联步骤,在所述环境坐标系中确定主体的活动区域,并根据每一音源以及主体的活动区域中每一位置生成对应的第二音源信息,每一所述第二音源信息包括若干第二音源内容,每一所述第二音源内容和每一所述第一音源内容对应,所述第二音源内容包括每一对应时刻下的音源数据,以环境坐标系的位置为参量根据第二音源信息构建位置内容关联模型;而活动区域在虚线区域,是主体的活动方范围,而需要说明的是,此时需要确定每一个声源的内容,而主体听到的是四个声源叠加的结果,而此时记录的声源是不具有方向性的,仅仅记录如果主体的耳朵在一个位置,则这个位置得到的叠加的声源信息,就是第二音源信息,而第二音源信息只有在每个第二音源内容都具有时间参数之后,才能生成具体的声音,而需要说明的是,需要在活动区域中确定需要的位置点,优选8毫米-20毫米为一个单位,在活动区域内每隔一个点的位置生成对应的第二音源信息。
相位关联步骤,根据每一音源位置以及主体的活动区域中每一位置生成对应的第三音源信息,每一第三音源信息包括若干声音相位参数,每一所述声音相位参数与每一音源位置对应,以环境坐标系的位置为参量根据第三音源信息构建位置相位关联模型;此时是为了确定每个位置和每个音源的距离产生的播放相位的误差,此时仅仅需要建立一个时间基准,所有音源从时间0开始播放,那么每一位置接收到实际声音会根据声音的传播速度存在差别,所以也就是每个位置信息对应的播放的实际时间会不同,也就是例如位置x,对应abcd四个声源的距离不同产生了接收到四个声源的时间不同,所以根据这个值,就可以知道四个实际播放时间。
位姿关联步骤,根据每一主体的活动区域中每一位置以及每一预设位姿生成定位信息,所述定位信息包括每一预设位姿下,第一位姿点在环境坐标系的位置以及第二位姿点在环境坐标系的位置,以环境坐标系的位置为参量根据定位信息构建位姿位置关联模型。而这个模型的目的是根据人体的位姿就可以得到实际的左耳和右耳对应的位置的坐标。通过第一换算策略根据每一音源以及主体的活动区域中每一位置生成对应的第二音源信息,通过第二换算策略根据每一音源位置以及主体的活动区域中每一位置生成对应的第三音源信息;通过第三换算策略根据每一主体的活动区域中每一位置以及每一预设位姿生成定位信息。所述内容关联步骤还包括获取环境参数,所述第一换算策略还根据所述环境参数生成第二音源信息。所述环境参数包括温度参数、湿度参数以及反射面参数。还包括冗余法分别简化位姿位置关联模型、位置相位关联模型以及位置内容关联模型。
所述音效获取模块2包括定位获取步骤、相位获取步骤、内容获取步骤以及声音生成步骤;
定位获取步骤,主体位姿捕获设备捕获主体位姿信息,将主体位姿信息以及主体位置信息输入到位姿位置关联模型中以得到定位信息;而根据主体的位置信息以及主体的位姿信息就可以得到左耳和右耳的位置。
相位获取步骤,解析定位信息以得到第一定位子信息以及第二定位子信息,所述第一定位子信息反映主体作为在所述环境坐标系中的位置,所述第二定位子信息反映主体右耳在环境坐标系的位置,将第一定位子信息和第二定位子信息分别输入到位置相位关联模型以得到第一声音相位信息以及第二声音相位信息,所述第一声音相位信息为主体左耳在环境坐标系下的位置对应的第三音源信息,所述第二声音相位信息为主体右耳在环境坐标系下的位置对应的第三音源信息;而这里就可以得到左耳对应每个声源的播放时间,和右耳对应每个声源的播放时间。
内容获取步骤,将所述第一定位子信息和所述第二定位子信息分别输入到位置内容关联模型以得到第一声音内容信息以及第二声音内容信息,所述第一声音内容信息为主体左耳在环境坐标系下的位置对应的第二音源信息,所述第二声音内容信息为主体右耳在环境坐标系下的位置对应的第二音源信息;这里就可以得到左耳实际听到的四个声源的叠加得到的声音内容,而同时可以听到右耳根据四个声源叠加得到的声音内容。
声音生成步骤,根据第一声音相位信息和第一声音内容信息、第二声音相位信息和第二声音内容信息生成此时的声音播放信息;
根据原有的面对信息构建习惯也就是在特定场景下,用户的位姿习惯势必会具有一定的规律,而这样一来,提前计算得到的声音信息更可能符合用户实际转动方向,这样就可以起到一个预判的效果。
具体包括以下步骤:
第一获取步骤,获取此时的主体的位姿信息;
位姿预判步骤,根据此时的主体的位姿信息以及当前时刻以一随机权重分配算法生成方向预判信息,每一方向预判信息包括一个方向预判角度范围,所述方向预判角度范围反映所述主体的转动的角度,根据所述方向预判信息生成下一时刻的主体的预判位姿信息,所述随机权重分配算法根据此时的每一方向预判信息分配有对应的权重值,对应的权重值越大,则该方向预判信息更容易被所述随机权重分配算法选中;在一个实施例中,在每一时刻下,所述主体的转动角度为主体在环境模型中的三维空间中的转动角度,对应的方向预判信息设置为16个,每一方向预判信息对应的方向预判角度范围设置为90度。首先在理论上主体的位姿信息是三维的位姿信息,而相对的转动方向也是在三维空间中实现的,所以通过16个方向预判信息实现方向的获取。
在另一个实施例中,所述主体的转动角度为主体在环境模型中的预设平面的等效转动角度。在每一时刻下,对应的方向预判信息设置为12个,每一方向预判信息对应的方向预判角度范围设置为30度。需要说明的是人耳对上、下的位置分别能力较差,所以本发明优选通过将上、下的转动方向等效到平面,也就是说,只判断主体周向的转动,这样可以优化数据处理效率,同时提高精度。
预判计算步骤,将所述预判位姿信息输入到所述音效获取模块2中以获得预判的声音播放信息;
第二获取步骤,获取下一时刻的主体的位姿信息;通过第二获取步骤就可以获得主体的下一时刻的位姿信息。
位姿判断步骤,根据下一时刻的位姿信息计算所述主体的转动方向,若所述主体的转动方向在所述方向预判角度范围内,则播放预判得到的声音播放信息,并增加该方向预判信息的权重值;若所述主体的转动方向在所述方向预判角度范围之外,则将下一时刻的主体位姿信息输入到音效获取模块2中,播放音效获取模块2输出的声音播放信息,且减小该方向预判信息的权重值。如果判断正确,则输出以及计算好的音频信息,而如果判断错误,则不输出,同时根据正确或错误的结果增加或减小对应的权重值。这样在多次样本训练下,判断会趋于准确,而需要说明的是,可以在时间允许的情况下执行多次步骤,不只有一个方向预判信息。
所述位姿判断步骤配置有划分子步骤,所述划分子步骤配置有划分权重阈值,当一方向预判信息对应的权重值超过权重阈值时,将所述方向预判信息分成至少两个新的方向预判信息,每一新的方向预判信息均分原所述方向预判信息的权重值以及方向预判角度范围。通过这种方式可以起到一个较为可靠的效果,这样可以在转动方向上,在训练下更加精确。
所述播放模块4用于播放所述声音播放信息。
当然,以上只是本发明的典型实例,除此之外,本发明还可以有其它多种具体实施方式,凡采用等同替换或等效变换形成的技术方案,均落在本发明要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!