一种基于人机语音交互的网络入侵告警系统及方法与流程
本发明涉及网络安全技术,特别涉及一种基于人机语音交互的网络入侵告警系统及方法。
背景技术:
重大活动网络安保应急指挥中心场景下存在人员精力、体力有限、值守效率不高的问题。熬夜太久人的注意力、精力和体力都会下降,对安全威胁的判断难免会出现纰漏。语音告警可有针对性提高值守人员注意力。通过语音控制可以大大提高安全事件或威胁的处置效率。
语音识别及身份验证技术、人脸识别及身份验证技术已经非常成熟,近几年基于语音的人机互动技术也飞速发展,为提高网络安全值守活动中工作效率和发现网络威胁的精度和速度,利用大数据分析方法协助分析判断网络攻击行为和网络安全事件,并用语音进行网络威胁告警,通过语音控制,可快速执行预设命令或任务,及时对网络威胁或事件进行应急处置。
现有网络安全告警技术大多是基于短信和邮件,基于语音告警的系统多为机房消防系统或网管系统,且不能与人语音互动。已有的基于b/s架构的语音告警实现方法及系统,虽能实现语音告警或人机互动,但是大多适用于简单的应用场景,无法满足瞬息万变的网络安全态势监控环境,存在人机交互不够深入、对复杂指令执行效果不佳的技术缺陷。
技术实现要素:
本发明要解决的技术问题是,克服现有技术中的不足,提供一种基于人机语音交互的网络入侵告警系统及方法。
为解决上述技术问题,本发明采用的解决方案是:
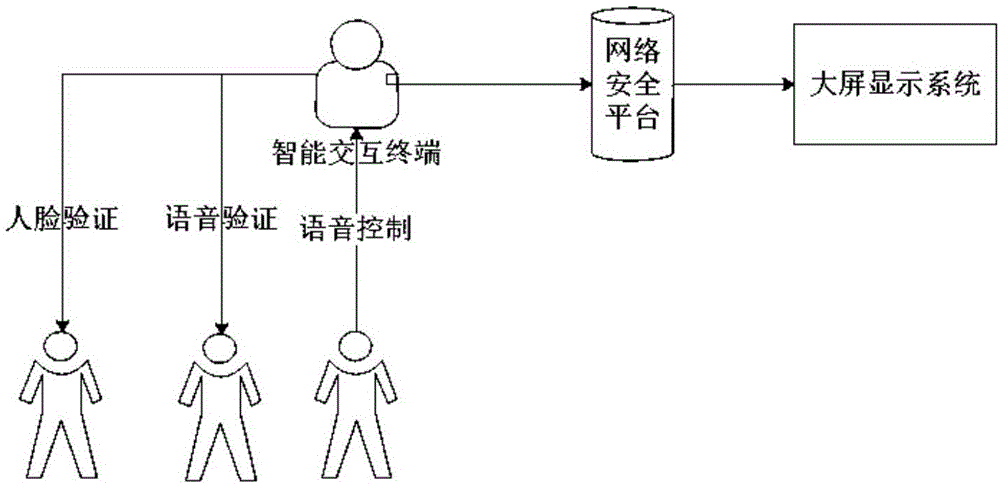
提供一种基于人机语音交互的网络入侵告警系统,包括网络安全防护平台;还包括由音视频采集系统、语音控制系统和声光告警系统组成的智能交互终端,智能交互终端通过有线或无线方式连接至网络安全防护平台;
所述音视频采集系统包括摄像头、拾音器和音视频数据处理模块,音视频数据处理模块与安装在网络安全防护平台中的身份认证数据库连接并实现数据交换;
所述语音控制系统包括拾音器和音频采集与识别模块,音视识别与判断模块与安装在网络安全防护平台中的语音控制指令数据库连接并实现数据交换;
所述声光告警系统包括声音报警器和灯光报警器,分别通过信号线连接至智能交互终端,并通过有线网络或无线网络与网络安全防护平台进行数据交互。
本发明中,所述网络安全防护平台是安装于本地服务器的网络安全防护平台,或者是基于云端的网络安全防护平台。
本发明中,所述网络安全防护平台还接有大屏显示系统,用于显示与安全业务相关的文本信息和操作人员人机对话界面。
本发明中进一步提供了利用前述系统的基于人机语音交互的网络入侵告警方法,包括:
(1)操作人员通过音视频采集系统采集身份验证信息,在与网络安全防护平台中的身份认证数据库进行身份验证后,获得网络安全防护平台的语音操控权限;
(2)操作人员通过语音控制系统对网络安全防护平台进行语音控制,下达语音指令;音频采集与识别模块对操作人员的声音进行识别后,进行语义的识别,判断该指令的内容与语音控制指令数据库之间的匹配关系及权限适配与否;如果找到相匹配的指令且权限相符,则执行;如无法找到内容相匹配的指令,或者虽有匹配指令但权限不符,则拒绝执行;
(3)当网络安全防护平台遭受攻击或监测发现安全隐患或安全事件时,网络安全防护平台通过声光告警系统发出声音或灯光告警信号。
本发明中,在进行身份验证、下达语音指令和进行语音告警的同时,通过大屏显示系统实时显示身份验证进度与结果、语音指令内容和执行内容、告警内容和处置建议。
本发明中,通过声光告警系统发出告警信号的同时,还同时通过网络社交软件或短信方式向预定联系人发送包含告警内容的信息。
发明原理描述:
本发明的原理是利用人脸识别与语音识别等身份验证技术对系统管理员和用户进行身份验证,通过身份验证后,管理员和用户可通过语音对网络安全监控防护平台进行操控,如下达监测或漏扫任务、查看某一业务系统的安全态势、分析安全风险等等,并可实时对重大网络攻击行为和重大安全事件进行智能识别和声光告警,通过语音提示系统管理员或用户采取应对措施,并提供处置建议。该发明的关键点是可进行人机语音交互,实现用语音对网络安全系统或设备进行控制,并将系统反馈在大屏显示终端进行展示。
涉及到的术语释义:
人机语音交互:人通过语音实现对网络安全系统或设备的控制,实现安全系统或设备的某种功能。
mfcc:基于mel频率的倒谱系数(mei-frequencycepslralcoefficients),它是在1980年由davis和mermelstein提出来的一种在自动语音和说话人识别中广泛使用的特征。
与现有技术相比,本发明的技术效果是:
1、本发明可以很好的弥补人员值守精力有限的问题,可大大提高工作效率和对安全事件判断的准确率。
2、在7×24小时重大活动安保和值守情况下,可提高应急响应速度和处置效率,提高对网络威胁和安全事件判断的准确性。
附图说明
图1为人机交互实现原理图。
图2为语音控制实现原理图。
具体实施方式
下面结合附图,对本发明的具体实施方式进行详细描述。
首先需要说明的是,本发明涉及数据库及网络安全防护技术,是计算机技术在信息安全技术领域的一种应用。在本发明的实现过程中,会涉及到多个软件功能模块或集成软硬件的功能模块的应用。申请人认为,如在仔细阅读申请文件、准确理解本发明的实现原理和发明目的以后,在结合现有公知技术的情况下,本领域技术人员完全可以运用其掌握的软件编程技能实现本发明。前述功能模块包括但不限于:音视频采集系统、语音控制系统、声光告警系统、音视频数据处理模块、身份认证数据库、音频采集与识别模块,音视识别与判断模块、语音控制指令数据库等,凡本发明申请文件提及的均属此范畴,申请人不再一一列举。
本发明中,基于人机语音交互的网络入侵告警系统,包括网络安全防护平台;还包括由音视频采集系统、语音控制系统和声光告警系统组成的智能交互终端,智能交互终端通过有线或无线方式连接至网络安全防护平台。网络安全防护平台可以是安装于本地服务器的网络安全防护平台,例如杭州安恒信息技术股份有限公司的ailpha大数据智能安全平台系统;也可以是基于云端的网络安全防护平台,例如杭州安恒信息技术股份有限公司的玄武盾云防护平台系统。
音视频采集系统包括摄像头、拾音器和音视频数据处理模块,音视频数据处理模块与安装在网络安全防护平台中的身份认证数据库连接并实现数据交换;语音控制系统包括拾音器和音频采集与识别模块,音视识别与判断模块与安装在网络安全防护平台中的语音控制指令数据库连接并实现数据交换;分别通过信号线连接至智能交互终端,并通过有线网络或无线网络与网络安全防护平台进行数据交互。网络安全防护平台还接有大屏显示系统,用于显示与安全业务相关的文本信息和操作人员人机对话界面。
利用前述系统的基于人机语音交互的网络入侵告警方法,包括:
(1)操作人员通过音视频采集系统采集身份验证信息,在与网络安全防护平台中的身份认证数据库进行身份验证后,获得网络安全防护平台的语音操控权限;
(2)操作人员通过语音控制系统对网络安全防护平台进行语音控制,下达语音指令;音频采集与识别模块对操作人员的声音进行识别后,进行语义的识别,判断该指令的内容与语音控制指令数据库之间的匹配关系及权限适配与否;如果找到相匹配的指令且权限相符,则执行;如无法找到内容相匹配的指令,或者虽有匹配指令但权限不符,则拒绝执行;
(3)当网络安全防护平台遭受攻击或监测发现安全隐患或安全事件时,网络安全防护平台通过声光告警系统发出声音或灯光告警信号。
在进行身份验证、下达语音指令和进行语音告警的同时,通过大屏显示系统实时显示身份验证进度与结果、语音指令内容和执行内容、告警内容和处置建议。通过声光告警系统发出告警信号的同时,还同时通过网络社交软件或短信方式向预定联系人发送包含告警内容的信息。
本发明的告警系统由音视频采集系统、语音控制系统、声光告警系统、大屏显示系统四部分组成,场景主要适用于网络安全监控值守中心或应急指挥中心,通过该系统可大大提高安全威胁和安全事件的处置效率,降低值守人员的工作量。
本系统利用人脸识别与语音识别等身份验证技术对系统管理员和用户进行身份验证,通过身份验证后,管理员和用户可通过语音对网络安全监控防护平台进行操控,如下达监测或漏扫任务、查看某一业务系统的安全态势、分析安全风险等等,并可实时对重大网络攻击行为和重大安全事件进行智能识别和声光告警,通过语音提示系统管理员或用户采取应对措施,并提供处置建议。
系统工作流程示例:
多因子身份验证(人脸识别+声纹识别,也可结合系统用户名+密码验证)---得到相应的云安全平台管理和控制权限---通过音视频采集系统跟云平台进行互动---互动结果通过大屏显示系统进行展示---系统通过智能交互终端可实现语音告警。
人脸验证实现原理:
(1)首先通过音视频采集系统建立人脸的面像档案。即用摄像机采集安全防护平台管理人员的人脸的面像文件,并将这些面像文件生成面纹编码(faceprintcode)贮存起来。这种面纹编码可以抵抗光线、皮肤色调、面部毛发、发型、眼镜、表情和姿态的变化,具有很高的可靠性。
(2)验证时,通过视频采集系统获取当前人员的人脸面像,并将当前的面像文件生成面纹编码,然后用当前的面纹编码与档案库存的面纹编码进行检索比对。根据比对结果可判断识别人员身份,并赋予相对应的安全平台的管理权限。
声音验证实现原理:
声音验证系统主要是由预处理、特征提取、建模、模式匹配及系统判别等构成。首先对云安全平台的管理人员的语音进行采集,通过提取声纹信息建立个人语音模型。
验证时提取说话人语音的mfcc特征,根据后验概率算法把说话人模型与说话人的语音进行模型比对。如果有与说话人语音相匹配的的模型,则把相匹配模型的语者来作为识别结果输出,并赋予相对应的安全防护平台的管理权限,反之,则拒绝。
语音控制实现原理:
云安全防护平台的管理员通过人脸和声纹等多因子身份认证技术后,可对云安全防护平台进行语音控制,通过下达语音指令,云平台可完成相应功能的任务。首先通过音频采集系统对人员声音进行识别,然后进行语义的识别,判断该指令是否与人员的权限相符,如果相符则执行,并通过视频监控大屏进行结果反馈,反之拒绝执行。
声光告警实现原理:
云安全防护平台遭受到重大攻击如大流量ddos或apt攻击,或者监测发现重大安全隐患或安全事件时,云平台会将会通过扩声系统进行语音告警,并可配合红色警报灯加强告警力度,提醒值守人员注意,并采取相应措施。对于常态性告警,系统可自动提供处置建议,并将告警信息通过短信发送相关联系人。
- 还没有人留言评论。精彩留言会获得点赞!