一种基于边缘计算的数据流差分隐私保护方法及系统与流程
本发明涉及边缘计算领域,尤其涉及一种基于边缘计算的数据流差分隐私保护方法及系统。
背景技术:
随着信息化时代的到来,信息技术产业快速发展。internet作为发展最快的信息技术产业之一,能够为用户提供多样化的服务,已成为各领域中不可或缺的一部分。随着互联网终端设备种类的增多和数量的爆炸性增长,以及用户对服务质量(qualityofservice,qos)和多样化需求的显著增长,如今internet也面临着诸多挑战。其中,如何处理internet中大量数据、如何保证服务的实时性以及如何确保用户的安全性,是面临的三个主要挑战。
云计算作为基于internet的一种计算模式,通过集中式计算和存储提供按需可扩展的服务。然而,随着终端设备和数据量的增长以及泛在网网络技术的快速发展,将计算上传到云不仅需要占用大量的网络带宽,而且还增加了服务请求和响应的延时,特别在对延时敏感的应用支持方面,以集中式计算为特征的云计算已经难以满足这些技术和应用的发展需求。由此促使了边缘计算,雾计算等计算模式的兴起。从原理上讲,边缘计算和雾计算具有相似的思想,目的都是使计算更接近用户,即将云计算从集中式的大型数据中心扩展到离用户距离较近的网络边缘,以此来克服以往云计算的网络瓶颈和高延迟等缺点,改善终端用户的服务请求响应速度和用户体验。在技术上,雾计算和边缘计算通过在距离用户较近的网络边缘部署专用服务器或者中小型计算中心来缓解云的计算压力,提高用户服务qos。利用边缘计算,在数据量大、实时性要求高的场景下,可以较好地满足用户的需求。
在以往的云计算中,数据需要先存储到云端再进行处理,这样会增加服务请求响应的时间。如果在边缘计算中也采用先存储再处理的模式,虽然利用“更接近用户的计算”能够缩短响应时间,但是在实时性要求较高的场景下,仍然不是一个很好的解决方案。因此,如果能在数据传输过程中处理数据,那么将会大大缩短服务请求响应时间,这种方式便是基于边缘计算的实时数据流解决方案。kafka作为一个分布式流式处理平台(adistributedstreamingplatform),能够为边缘设备提供实时数据流处理能力。其具备三个关键特性:(1)能够发布和订阅流数据;(2)能够将流数据安全地存储在具有分布式、可复制和容错机制的集群中;(3)能够及时处理到达的流数据。这三个特性是一个流式处理平台所必须具备的。在kafka中,topic是对一组消息的抽象,或者说是对消息的分类。在通常的生产者消费者模型中,producer可以将消息发送到一个topic,这些消息被存储在被称为brokers的kafka服务器中,随后consumer可以订阅该topic并从brokers中消费这些消息。
尽管利用边缘计算和数据流的实时处理能够为数据的分析带来好处,但边缘计算与其它传统计算模式一样也面临着严峻的安全问题。如在移动应用中,许多在线服务依赖于从用户中收集的个人数据,这些数据可以增强移动应用的实用性,为用户提供个性化服务,例如广告推送、购买偏好等,但是这些个人数据同样能够被恶意攻击者用来推断出用户的敏感信息,例如性别推断、位置追踪、说话人身份鉴别等。从用户的角度看,用户希望暴露的隐私信息越少越好,即尽可能少的收集用户个人数据。从服务提供者的角度看,希望收集更多的用户个人数据来提供更好的服务。显然,这两者之间存在着本质性的矛盾。因此,如何权衡收集信息的可用性和用户隐私的安全性是一个需要仔细考量的问题。
现有保护用户隐私的方案中采用的技术主要包括:匿名化处理、数据转换、数据加密和差分隐私等,但即使采用这些技术,目前方案仍然存在如下不足:
1、目前,即使边缘计算使一部分计算从云下放到靠近用户的边缘设备,仍然无法满足高实时性要求的服务。
2、边缘计算面临着安全性的问题,即边缘设备处理的数据涉及数据可用性和隐私安全性的矛盾。
3、目前大多隐私保护方式采用的集中式数据清洗(去隐私化)限制系统吞吐量,无法满足低延时服务的需要。
4、边缘设备计算能力和安全策略之间存在矛盾。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种服务响应延时小,服务质量高,系统吞吐量高,每个边缘设备的计算负载小,用户与边缘设备之间的数据传输量小,隐私保护度高的基于边缘计算的数据流差分隐私保护方法及系统。
为解决上述技术问题,本发明提出的技术方案为:一种基于边缘计算的数据流差分隐私保护方法,包括:
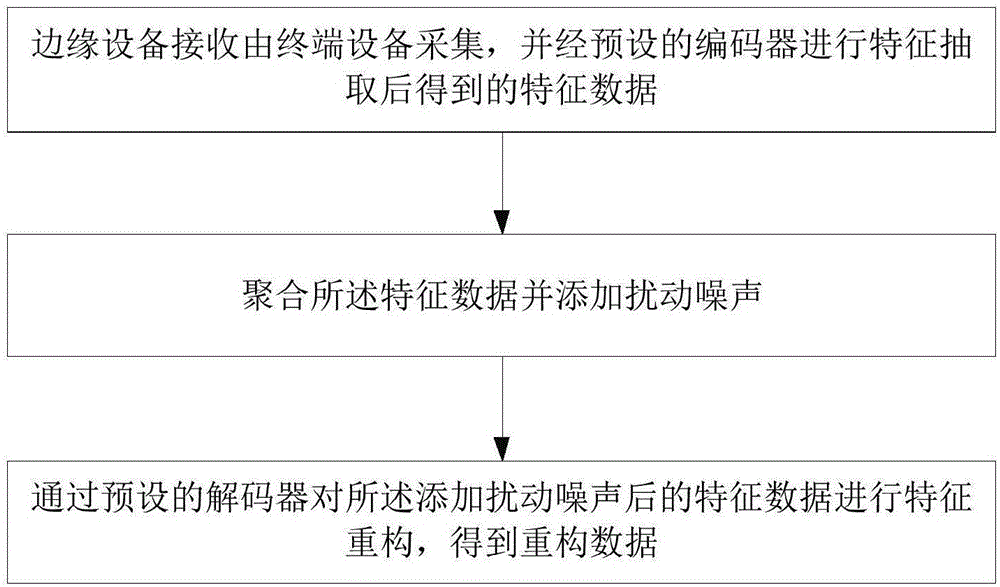
s1.边缘设备接收由终端设备采集,并经预设的编码器进行特征抽取后得到的特征数据;
s2.聚合所述特征数据并添加扰动噪声;
s3.通过预设的解码器对所述添加扰动噪声后的特征数据进行特征重构,得到重构数据;
所述编码器和所述解码器是对同一自编码器进行训练后得到的编码器和解码器。
进一步地,步骤s1中所述特征数据为所述终端设备按照预设的采集时间窗口为单位,所采集到在一个采集时间窗口内,并由预设的编码器进行特征抽取后得到的特征数据。
进一步地,步骤s2具体包括:所述边缘设备中的输入层节点按照预设的第一时间窗口,并将所述第一时间窗口内所接收到的由各所述终端设备采集的特征数据进行聚合,并计算各特征数据的扰动噪声预算,根据所述扰动噪声预算为所述特征数据添加扰动噪声。
进一步地,所述扰动噪声预算根据式(1)计算确定:
式(1)中,ε为预设的总的隐私预算,n为终端设备总数,nk为当前输入层节点所连接的终端设备数,εk为当前输入层节点的隐私预算,βi表示当前第一时间窗口内每个特征在当当前输入层节点的隐私预算中所占的比例,d表示特征的维度,
进一步地,根据式(2)为所述特征数据添加扰动噪声:
fi'=fi+lap(δh0/εi)(2)
式(2)中,fi'为添加扰动噪声后的特征值,fi为添加扰动噪声前的特征值,δh0标识全局敏感度,lap(·)为拉普拉斯分布,εi为当前输入层节点的当前第一时间窗口内第i个输入特征的隐私预算。
进一步地,步骤s3具体包括:所述边缘设备中的输出层节点按照预设的第二时间窗口接收并聚合所述输入层节点提供的添加扰动噪声后的特征数据,并通过预设的解码器对所述第二时间窗口内接收到的所述特征数据进行特征重构,得到重构数据。
一种基于边缘计算的数据流差分隐私保护系统,包括边缘计算设备,用于:接收由终端设备采集,并经预设的编码器进行特征抽取后得到的特征数据;聚合所述特征数据并添加扰动噪声;通过预设的解码器对所述添加扰动噪声后的特征数据进行特征重构,得到重构数据;所述编码器和所述解码器是对同一自编码器进行训练后得到的编码器和解码器。
进一步地,所述边缘设备包括输入层节点,所述输入层节点用于按照预设的第一时间窗口,并将所述第一时间窗口内所接收到的由各所述终端设备采集的特征数据进行聚合,并计算各特征数据的扰动噪声预算,根据所述扰动噪声预算为所述特征数据添加扰动噪声。
进一步地,所述扰动噪声预算根据式(1)计算确定:
式(1)中,ε为预设的总的隐私预算,n为终端设备总数,nk为当前输入层节点所连接的终端设备数,εk为当前输入层节点的隐私预算,βi表示当前第一时间窗口内每个特征在当当前输入层节点的隐私预算中所占的比例,d表示特征的维度,
进一步地,根据式(2)为所述特征数据添加扰动噪声:
fi'=fi+lap(δh0/εi)(2)
式(2)中,fi'为添加扰动噪声后的特征值,fi为添加扰动噪声前的特征值,δh0标识全局敏感度,lap(·)为拉普拉斯分布,εi为当前输入层节点的当前第一时间窗口内第i个输入特征的隐私预算。
进一步地,所述边缘设备包括输出层节点,所述输出层节点用于按照预设的第二时间窗口接收并聚合所述输入层节点提供的添加扰动噪声后的特征数据,并通过预设的解码器对所述第二时间窗口内接收到的所述特征数据进行特征重构,得到重构数据。
进一步地,还包括终端设备,所述终端设备用于按照预设的采集时间窗口为单位采集数据,并将所述采集时间窗口内的数据按照预设的编码器进行特征抽取,得到的特征数据,并提供给所述边缘设备。
与现有技术相比,本发明的优点在于:
1、本发明通过在终端设备上设置采集时间窗口,按照采集时间窗口来采集数据,进行特征抽取,并传送给边缘设备进行后续处理,边缘设备的输入层节点按照第一时间窗口来接收接入该节点的终端设备所发送的特征数据,并通过自适应算法为各特征数据添加扰动噪声,边缘设备的输出层节点按照第二时间窗口接收输入层节点添加扰动噪声后的特征数据,并通过解码器进行重构得到重构数据,将重构数据提供给其它系统使用,重构后的数据将无法得到用户的敏感信息,通过这种方式,可以有效的降低边缘设备的响应延时,提高了服务质量,有效的保护用户的隐私。
2、本发明的边缘设备具有多个输入层节点,每个输入层节点与多个终端设备连接,对所接入的终端设备的特征数据进行处理,通过采用这种分布式的处理方式,提高了边缘设备的系统吞吐量,降低了每个边缘设备的输入层节点的计算负载,也保证了整个边缘计算系统的运行稳定。
3、本发明的终端设备将采集到的数据经哈希对齐,再通过自身的编码器进行特征抽取后,再将特征数据传送给边缘设备的输入层节点,降低了用户的终端设备与边缘设备的输入层节点之间的数据传输量,减少了网络带宽的浪费;并且,编码器和解码器为同一自编码器中的两个部分,预先训练好后再加载至终端设备上,不需要终端设备对编码器进行训练,也降低了对终端设备的处理能力的要求。
附图说明
图1为本发明具体实施例的流程示意图。
图2为本发明具体实施例的系统架构示意图。
图3为本发明具体实施例的自编码器架构示意图。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图1所示,本实施例的基于边缘计算的数据流差分隐私保护方法,包括:s1.边缘设备接收由终端设备采集,并经预设的编码器进行特征抽取后得到的特征数据;s2.聚合所述特征数据并添加扰动噪声;s3.通过预设的解码器对所述添加扰动噪声后的特征数据进行特征重构,得到重构数据;所述编码器和所述解码器是对同一自编码器进行训练后得到的编码器和解码器。
在本实施例中,步骤s1中所述特征数据为所述终端设备按照预设的采集时间窗口为单位,所采集到在一个采集时间窗口内,并由预设的编码器进行特征抽取后得到的特征数据。步骤s2具体包括:所述边缘设备中的输入层节点按照预设的第一时间窗口,并将所述第一时间窗口内所接收到的由各所述终端设备采集的特征数据进行聚合,并计算各特征数据的扰动噪声预算,根据所述扰动噪声预算为所述特征数据添加扰动噪声。
在本实施例中,所述扰动噪声预算根据式(1)计算确定:
式(1)中,ε为预设的总的隐私预算,n为终端设备总数,nk为当前输入层节点所连接的终端设备数,εk为当前输入层节点的隐私预算,βi表示当前第一时间窗口内每个特征在当当前输入层节点的隐私预算中所占的比例,d表示特征的维度,
在本实施例中,根据式(2)为所述特征数据添加扰动噪声:
fi'=fi+lap(δh0/εi)(2)
式(2)中,fi'为添加扰动噪声后的特征值,fi为添加扰动噪声前的特征值,δh0标识全局敏感度,lap(·)为拉普拉斯分布,εi为当前输入层节点的当前第一时间窗口内第i个输入特征的隐私预算。
在本实施例中,步骤s3具体包括:所述边缘设备中的输出层节点按照预设的第二时间窗口接收并聚合所述输入层节点提供的添加扰动噪声后的特征数据,并通过预设的解码器对所述第二时间窗口内接收到的所述特征数据进行特征重构,得到重构数据。
一种基于边缘计算的数据流差分隐私保护系统,包括边缘计算设备,用于:接收由终端设备采集,并经预设的编码器进行特征抽取后得到的特征数据;聚合所述特征数据并添加扰动噪声;通过预设的解码器对所述添加扰动噪声后的特征数据进行特征重构,得到重构数据;所述编码器和所述解码器是对同一自编码器进行训练后得到的编码器和解码器。
在本实施例中,所述边缘设备包括输入层节点,所述输入层节点用于按照预设的第一时间窗口,并将所述第一时间窗口内所接收到的由各所述终端设备采集的特征数据进行聚合,并计算各特征数据的扰动噪声预算,根据所述扰动噪声预算为所述特征数据添加扰动噪声。
进一步地,所述扰动噪声预算根据式(1)计算确定:
式(1)中,ε为预设的总的隐私预算,n为终端设备总数,nk为当前输入层节点所连接的终端设备数,εk为当前输入层节点的隐私预算,βi表示当前第一时间窗口内每个特征在当当前输入层节点的隐私预算中所占的比例,d表示特征的维度,
在本实施例中,根据式(2)为所述特征数据添加扰动噪声:
fi'=fi+lap(δh0/εi)(2)
式(2)中,fi'为添加扰动噪声后的特征值,fi为添加扰动噪声前的特征值,δh0标识全局敏感度,lap(·)为拉普拉斯分布,εi为当前输入层节点的当前第一时间窗口内第i个输入特征的隐私预算。
在本实施例中,所述边缘设备包括输出层节点,所述输出层节点用于按照预设的第二时间窗口接收并聚合所述输入层节点提供的添加扰动噪声后的特征数据,并通过预设的解码器对所述第二时间窗口内接收到的所述特征数据进行特征重构,得到重构数据。
在本实施例中,还包括终端设备,所述终端设备用于按照预设的采集时间窗口为单位采集数据,并将所述采集时间窗口内的数据按照预设的编码器进行特征抽取,得到的特征数据,并提供给所述边缘设备。
在本实施例中,以城市打车应用场景的10000条实际数据作为实验数据为例进行说明,实验数据包含17个字段:medallion(与车辆绑定标识md5值)、hack_license(与的士驾照绑定标识的md5值)、pickup_datetime(乘客上车时间)、dropoff_datetime(乘客下车时间)、trip_time_in_secs(乘车时间)、trip_distance(行车距离)、fare_amount(费用金额)、surcharge(额外费)、mta_tax(税金)、tip_amount(小费)、tolls_amount(通行费)、total_amount(所有费用总额)等,云端的查询目的是统计每个时间窗口内乘车费用总和。由于云端需要查询的是乘车费用总和,因此需要保留跟时间和费用相关的字段:pickup_datetime、dropoff_datetime、fare_amount、surcharge、mta_tax、tip_amount、tolls_amount和total_amount。
在本实施例的应用场景中,系统架构如图2所示,包含有多个终端设备(智能手机)和由多台pc机组成的边缘设备,利用交换机和高速网线实现相互通信。边缘设备包括多个输入层节点和一个输出层节点,每个输入层节点与多个终端设备网络连接,接收终端设备发送的特征数据,并对特征数据进行聚合,并添加扰动噪声(差分扰动,差分隐私扰动)。输出层节点与输入层节点连接,用于接收各输入层连接添加扰动噪声后的数据,并进行聚合及特征重构,并将特征重构后的重构数据输出,以提供给其它设备、系统(如云)使用。终端设备与边缘设备输入层节点是多对一的关系,即一个终端设备对应一个输入层节点,一个输入层节点对应多个终端设备。终端设备与边缘设备的输入层节点之间,以及边缘设备的输入层节点与输出层节点之间均采用数据流的方式进行传输。
在本实施例的应用场景中,终端设备在软件上具有数据采集和特征提取功能,通过调用边缘设备平台的api传输特征数据到边缘设备的输入层节点。边缘设备在软件上由kafka组成分布式计算框架,其中数据存储在kafkabrokers中,边缘设备的逻辑节点对应kafka中的topic,数据流流经topic后便执行相应的任务(task),输入层节点执行数据流聚合并自适应的添加差分隐私扰动,输出层节点执行数据流聚合和特征重构。通过以上的过程,边缘设备输出的数据流满足差分隐私的定义,确保了敏感信息对云端分析的透明性。
在本实施例的应用场景中,自编码器的应用涉及终端设备和边缘设备,关乎数据量的减小和差分隐私扰动的添加,优选采用非完备自编码器。非完备自编码器中的编码器能够达到类似主成分分析(principalcomponentanalysis)的效果,提取数据中的主要特征。在本发明实施例中,优选地使用如图3所示的非完备自编码器架构,其中编码器具有4层神经元(不包含输入层),每层神经元的个数为(6,5,3,3),解码器具有4层神经元(不包含输入层),每层神经元的个数为(3,4,5,8)。自编码器的训练采用离线训练方式,即预先用数据集对自编码器进行训练,得到训练好的非完备自编码器。
在本实施例的应用场景中,训练好的非完备自编码器的编码器神经元(即编码器)运行在终端设备中,解码器神经元(即解码器)运行在如图2的边缘设备的最后一个逻辑节点上(即边缘设备的输出层),用于对特征进行重构。通过将编码器和解码器分开放在终端设备和边缘设备,能够降低传输的数据量。为了保护用户数据的安全,在添加满足差分隐私的扰动噪声时,本发明优选地采用在边缘设备上为特征数据添加扰动噪声。
在本实施例的应用场景中,在确定了保留字段之后,需要训练非完备自编码器,为了使选择的字段数据能够输入自编码器进行训练,需要将每个字段转换成固定长度为k比特的串,即在本实施例中利用哈希算法对每个字段进行对齐以得到k比特的串,数据集中每条消息的字段经过哈希对齐之后组成一行新的记录,每条经过对齐的记录通过矩阵运算组合成一个消息矩阵,每条消息矩阵也通过矩阵运算组合成最终的训练集矩阵,最后将该训练集输入上述非完备自编码器进行训练,损失函数为l(x,g(f(z(x)))),其中l(·)通常采用均方差函数,g(·)为解码器,f(·)为编码器,z(·)为哈希对齐操作。训练完的自编码器中的编码器运行在每个终端设备中,即每个终端设备都具有一个编码器神经网络模型的副本,解码器运行在边缘设备中,即有且仅有一个解码器副本运行在边缘设备上。
在本实施例应用场景中,如图2所示,终端设备为智能手机,数据采集以及特征抽取等步骤均由软件实现。智能手机的整个数据采集以及特征抽取过程均以预设的采集时间窗口为单位,不同手机之间的采集时间窗口为异步执行,即每个手机之间无需通信协调。具体的过程为:对于某个手机,在一个采集时间窗口内,对需要采集的数据以一个较小的时间间隔持续采集并缓存,采集数据时只缓存需要保留的相关字段。考虑到手机的处理性能制约,本实施例中优选地采用批量处理的方式,对缓存的数据按照batch来处理,当缓存的数据量达到一个batch大小时,就立刻对这个batch的数据进行哈希对齐,并且将对齐后的数据输入编码器神经网络抽取特征;当采集时间等于或超过采集时间窗口阈值时,不管剩下采集的数据量是否满足一个batch,都进行哈希对齐操作并进行特征抽取,最后,将当前采集时间窗口内抽取的所有特征数据发送到终端设备。
在本实施例应用场景中,边缘设备由多台pc机组成,边缘设备的作用是接收不同终端设备传输过来的特征数据,并且对特征数据添加扰动噪声(差分扰动,差分隐私扰动)以满足差分隐私,最后将特征数据重构以便云的后续分析。由于边缘设备并非云端的高性能计算机,因此在性能及存储容量上有所限制。为此,在本实施例中,边缘设备采用分布式计算框架,即在多台pc机上部署kafka数据流处理框架,kafka框架基于zookeeper框架,而zookeeper框架是一个集中式的服务,用于维护配置信息、命名、提供分布式同步和提供组服务,kafka利用zookeeper可以实现数据的分布式存储以及冗余备份,通过zookeeper配置文件可以设定数据的冗余份数等,解决了单一设备存储容量限制的问题,而利用kafka实现数据流分布式处理则很好的解决了设备性能限制带来的问题。本实施例中,边缘设备利用kafka数据流框架实现了分布式计算及流数据处理,如图2所示,kafkatopic与边缘设备的逻辑节点一一对应,边缘设备中用于接收终端设备数据流的节点为输入层节点,用于对数据流的聚合和差分隐私扰动的添加,边缘设备输出数据的节点为输出层节点,用于聚合输入层节点输出的数据流,负责数据流的聚合和特征数据的重构,与终端设备类似,输入层节点及输出层节点各具有自己相应的时间窗口,也即输入层节点之间具有异步且相同的时间窗口,即输入层节点的第一时间窗口均相同,但并不同步执行,输出层节点只有一个,并且输出层节点的第二时间窗口和输入层节点无关,也即第一时间窗口和第二时间窗口相互独立。需要说明的是,图2中所示的边缘设备并非物理架构,而是逻辑架构,即物理上为多台pc机共同组成了分布式数据流处理平台,不具有图2所示的分层架构。
在本实施例的应用场景中,多台终端设备(智能手机)通过kafkaproducerapi接口将特征抽取后的数据无线传输到边缘设备的输入层节点对应的topic,输入层的每个逻辑节点在一个第一时间窗口内持续接收从智能手机发送的特征数据流并缓存,利用kafkastreamsapi将不同智能手机的特征数据流抽取聚合并缓存,当此过程花费的时间等于或大于第一时间窗口阈值时,为了增强后续重构出来数据的可用性,根据公式计算出当前逻辑节点接收到的特征值的自适应扰动噪声预算εi并添加扰动噪声到缓存的数据中,将加噪的数据组合成新的数据流,随后将其传输到输出层节点对应的topic;输出层节点同样在自己的第二时间窗口内将输入层不同逻辑节点添加扰动过后的特征数据流聚合,利用kafkaconsumerapi获取数据流中的具体数据并缓存,当此过程花费的时间等于或大于第二时间窗口阈值时,将当前第二时间窗口内缓存的数据转换为矩阵形式输入之前训练模型的解码器神经网络中进行特征重构,最后,输出到远端云服务器中进行数据分析。
在本实施例的应用场景中,如何添加差分隐私扰动噪声影响着特征重构出来数据的安全性与可用性。现有技术中通常的做法是对每个特征值添加相同的扰动,然而现实情况表明,并非每个特征值对解码器输出的贡献都相同,因此,在本实施例中采用自适应算法添加扰动噪声,在保证安全性(固定总隐私预算)的条件下,对特征重构数据影响贡献小的特征添加尽可能多的扰动,而对影响大的特征添加尽可能小的扰动,提高了重构数据的可用性。通过采用上述式(1)和式(2)的公式,对特征数据添加扰动噪声,可以很好的保证数据的安全性。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!