一种宏观区域实时流动量检测算法的制作方法
本发明属于移动智能互联网技术,尤其涉及景区等人流检测和评估算法。
背景技术:
区域流量数据是当前智慧校园、智慧景区、智慧城市的重要信息来源,可为区域人流密度评估、区域人流变化、流量诱导等提供决策辅助。
随着我国经济和科技迅猛发展,为更好的管理校园、景区、城镇等人们日常生活旅行的区域,提升人民生活旅行的便捷性、幸福感,建设智慧校园、智慧景区、智慧城市成为未来发展的新趋势。
在智慧校园、智慧城市等的建设过程中,人流的动态监测、估计,动向检测、预测、引导为不可或缺的重要组成部分。
以景区为例,目前建立了大量数字监控用以监控景区人流量,如通过进出口门闸记录景区内人流总量;通过在重点区域布设视屏监控,对当前区域内人流进行识别;通过数字显示屏,向游客展示景区内相关信息等。
然而尽管现在部署了各种各样的设备,但在人流的检测、预测上仍有无法满足管理需求,如进出口门闸只能记录景区内的总保留量,而无法记录分散在各个景点的人流量,而视频等,虽然能够清晰可视化,甚至通过图像识别的方式识别人数,但无法做到全覆盖,自然也就无法全局统计,更做不到流量的预估。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种宏观区域实时流动量检测算法。
为解决上述技术问题,本发明采用了以下技术方案:一种宏观区域实时流动量检测算法,包括按照物理空间部署在宏观区域范围内的多个检测子网络和远端的后台服务器,所述检测子网络包括若干个分机,以及与所述分机数据连接的的一个主机;所述分机通过无线被动感知的模式,采集分机覆盖范围内移动终端设备基于wifi协议随机向四周环境发送的广播式数据包,并筛选其中带有移动终端设备id信息的数据包进行检索,打上分机标签后上传至主机,主机将手机到的数据进行统一存储和打上时间标签,并上传至远端的后台服务器中存储,并对数据按照以下步骤进行分析:
步骤1:通过分机分别采集完整时间段(t1-δt)和(t2-δt)的数据
其中,dij表示第j个子网第i号分机数据;n表示子网的个数,m表示第j个子网中的分机个数;
步骤2:对数据进行切片并提取待分析局部区域s及完整时间段(tk-δt)的数据ds',
步骤3:物理空间位置映射,对应所部署的子网络,将其与实际区域s进行空间匹配,每个子网络主机带有对应区域相应编号信息及分机部署情况列表;
步骤4:对各分机采集的数据根据移动终端设备id号进行排序,建立数据矩阵{tower(i,s),tk};
步骤5:将建立的id数据列表按出现在不同数据矩阵的次数c进行分类:将仅在一个数据矩阵tower中出现的id记为idc=1并单独提取进行分析,将在两个以上数据矩阵tower中出现的id数据归为idc>1;
步骤6:对于在时间段δt内仅出现在一个数据矩阵tower中出现的id数据进行分析,若在δt时间段内,未发现该id数据在该数据矩阵tower中重复出现的,则遍历该局部区域s周围相邻的子网查找是否出现相同的id数据,如果未出现,则将该id数据归为idc=1,若果在其他子网中出现,则将该id数据打上标识归为idc>1;
步骤7:重复步骤4~6直到数据处理完毕;
步骤8:将步骤5和6处理得到的数据进行归纳合并,形成两类数据idc=1和idc>1;
步骤9:在tk时刻的δt时间段内,通过以下方法计算和检测局部区域的区域流出量wout和区域流入量win:
(1)首先,将idc>1中数据经过数据唯一化处理后计入有效数据;
(2)然后,将idc=1中数据通过f(g)近似拟合函数近似拟合处理,拟合过程中设置偏置参考系
(3)接着,对idc>1和idc=1的有效数据,通过下式求取区域人流保有量数据
式中,x和y分别是idc>1和idc=1中有效数据总数;
(4)最后,通过式(2)计算t1-t2时间范围内,该局部区域内的人员流出量wout和流入量win:
式中,δ1和δ2分别为为t1和t2的极小量。
作为优选,所述偏置参考系
作为优选,步骤9中,δ1和δ2的取值通过以下方法确定:首先令y=f(g),n为符合系统误差范围内的y的次数,则,
有益效果:本发明提供了一种基于便携移动终端唯一id、采集数据时间戳和检测设备位置信息的宏观区域流量信息检测算法,实现对移动终端采集数据的数据挖掘和分析,可应用于对宏观区域实时流动量的精确高效检测,为宏观区域人流控制策略提供了指导。
附图说明
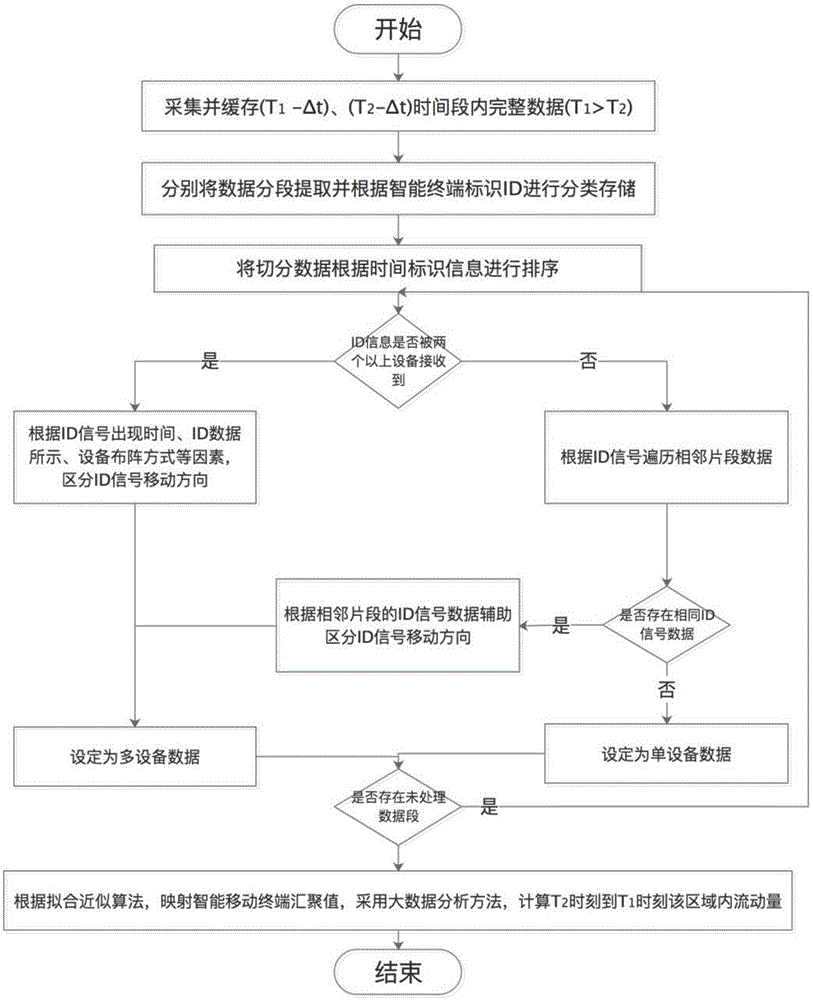
图1为本发明所述宏观区域实时流动量检测算法的逻辑流程示意图;
图2为本发明所述宏观区域实时流动量检测算法中的机器学习与自反馈原理示意图。
图3为本发明实施例宏观区域实时流动量检测与参照系的数据对比图。
具体实施方式
下面结合附图并以具体实施例,进一步阐明本发明。应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,如上图所示为包括按照物理空间部署在宏观区域范围内的多个检测子网络和远端的后台服务器,所述检测子网络包括若干个分机,以及与所述分机数据连接的的一个主机;所述分机通过无线被动感知的模式,采集分机覆盖范围内移动终端设备基于wifi协议随机向四周环境发送的广播式数据包,并筛选其中带有移动终端设备id信息的数据包进行检索,打上分机标签后上传至主机,主机将手机到的数据进行统一存储和打上时间标签,并上传至远端的后台服务器中存储,并对数据按照以下步骤进行分析:
步骤1:通过分机分别采集完整时间段(t1-δt)和(t2-δt)的数据
步骤2:对数据进行切片并提取待分析局部区域s及完整时间段(tk-δt)的数据ds',
步骤3:物理空间位置映射,对应所部署的子网络,将其与实际区域s进行空间匹配,每个子网络主机带有对应区域相应编号信息及分机部署情况列表;
步骤4:对各分机采集的数据根据移动终端设备id号进行排序,建立数据矩阵{tower(i,s),tk};
步骤5:将建立的id数据列表按出现在不同数据矩阵的次数c进行分类:将仅在一个数据矩阵tower中出现的id记为idc=1并单独提取进行分析,将在两个以上数据矩阵tower中出现的id数据归为idc>1;
步骤6:对于在时间段δt内仅出现在一个数据矩阵tower中出现的id数据进行分析,若在δt时间段内,未发现该id数据在该数据矩阵tower中重复出现的,则遍历该局部区域s周围相邻的子网查找是否出现相同的id数据,如果未出现,则将该id数据归为idc=1,若果在其他子网中出现,则将该id数据打上标识归为idc>1;
步骤7:重复步骤4~6直到数据处理完毕;
步骤8:将步骤5和6处理得到的数据进行归纳合并,形成两类数据idc=1和idc>1;
步骤9:在tk时刻的δt时间段内,通过以下方法计算和检测局部区域的区域流出量wout和区域流入量win:
(1)首先,将idc>1中数据经过数据唯一化处理后计入有效数据;
(2)然后,将idc=1中数据通过f(g)近似拟合函数近似拟合处理,拟合过程中设置偏置参考系
(3)接着,对idc>1和idc=1的有效数据,通过下式求取区域人流保有量数据
(4)最后,通过式(2)计算t1-t2时间范围内,该局部区域内的人员流出量wout和流入量win:
式中,δ1和δ2分别为为t1和t2的极小量,与拟合函数f(g)有关。
- 还没有人留言评论。精彩留言会获得点赞!