一种基于多智能体强化学习的分布式缓存策略的制作方法
本发明涉及无线通信技术领域,特别是涉及一种基于多智能体强化学习的分布式缓存策略。
背景技术:
近年来,强化学习得到了越来越多的关注,其理论基础研究不断取得进展,已大量运用于人工智能、工业控制、机器人等诸多领域。同时由于强化学习本身对环境知识要求较少,能够较好地适应动态变化的环境,这些特点都使得强化学习在越来越复杂的无线通信网络中具有广阔的应用前景。
无线通信越来越复杂的主要原因之一,在于无线数据流量的快速增长给当前的无线通信系统带来了巨大的负担。特别是在通信高峰期的时候,无线通信系统面临着巨大的通信压力。考虑到传统的无线通信系统没有利用文件的重要特征--内容复用性,即最流行文件会在一段时间内给大量用户重复请求。随着计算能力、存储能力的日益提高,研究者们基于文件特性(内容复用性)以及硬盘存储的现实,提出了一种新的解决方案,其基本思想就是在无线节点处配置大容量的存储器,利用非高峰期(如夜间时段)将最流行的文件提前缓存到接入点处的存储器中。在缓存的辅助下,当用户进行业务请求时,如果无线节点有请求文件,无线节点可以直接将文件传输给用户,使流量本地化。通过缓存技术,不仅能够大大降低了数据在回程链路及核心网络的延迟,同时也能降低了高峰时期回程链路及核心网络的负载,进而能够为用户带来更好的服务体验。对于无线缓存技术而言,最为重要的是对一个无线缓存网络进行建模,并在该模型的基础上设计最优缓存策略。
目前无线缓存网络中的最优缓存策略一般都需要一个全局中心控制服务器集中化求解。这类系统过于集中式,给中心服务器带来巨大的负载,没有充分利用无线节点的自主性进行负载均衡。
技术实现要素:
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于多智能体强化学习的分布式缓存略,使得无线节点之间不需要进行任何信息交换,每个无线节点仅仅通过自主学习,就能得到对应的分布式最优缓存策略,进而提高无线通信系统性能。
为达上述目的,本发明提出一种基于多智能体强化学习的分布式缓存策略,应用于一包括若干无线节点的无线缓存网络,所述分布式缓存策略包括:
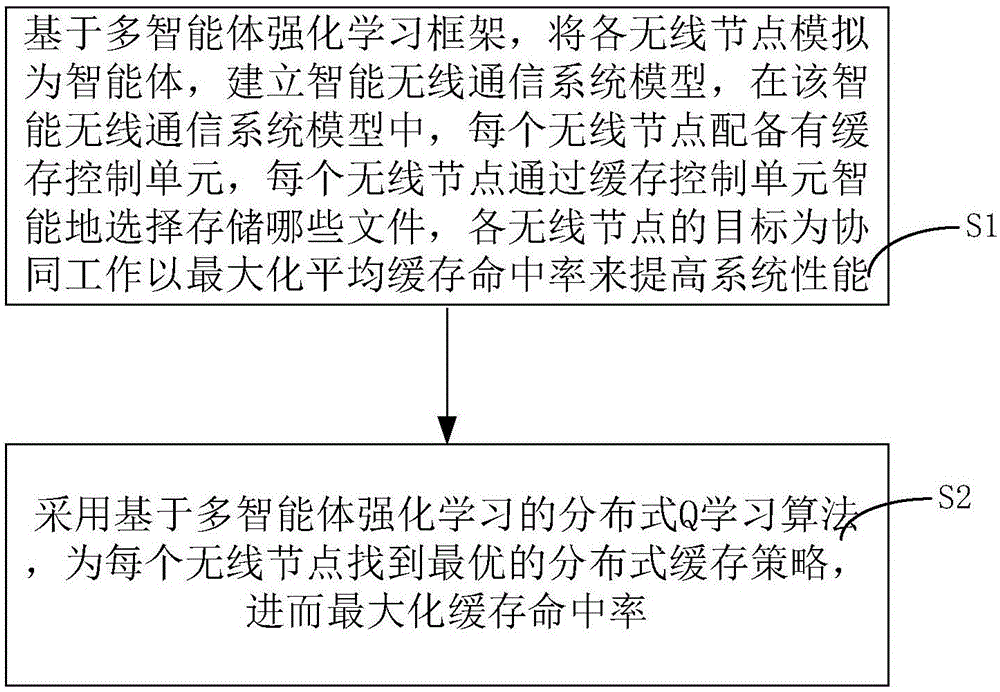
步骤s1,基于多智能体强化学习框架,将各无线节点模拟为智能体,建立智能无线通信系统模型,在该智能无线通信系统模型中,每个无线节点配备有缓存控制单元,每个无线节点通过缓存控制单元智能地选择存储哪些文件,各无线节点的目标为协同工作以最大化平均缓存命中率来提高系统性能;
步骤s2,采用基于多智能体强化学习的分布式q学习算法,为每个无线节点找到最优的分布式缓存策略,进而最大化缓存命中率。
优选地,于该智能无线通信系统模型中,环境状态代表无线节点能观察到的当前环境状态,即当前自身存储了哪些文件;动作空间代表无线节点的动作,即选择存储哪些文件;回报代表无线节点的立即回报函数,即平均缓存命中率。
优选地,于该智能无线通信系统模型中,每个无线节点不需进行任何信息交换,仅仅通过独立学习,就能协同工作以最大化平均缓存命中率来提高系统性能
优选地,于步骤s2中,引入贪婪探索策略ε,以1-ε的概率贪婪选择当
*前最好的动作,并使用ε概率随机选择所有动作,无线节点找到最优的动作am,即找到了最优的缓存策略。
优选地,于步骤s2中,根据无线节点一次可以选择存储的文件数,如果一次可以存储的文件数等于自身的存储容量,则采取单状态下的分布式q学习算法;否则,采取多状态下的分布式q学习算法。
优选地,所述单状态下的分布式q学习更新策略为:
qm(am)=max{qm(am),phit(a)}
其中,qm(am)为第m个无线节点选择动作am时,其q表qm的值;phit(a)为第m个无线节点选择动作am时,其联合动作a所对应的平均缓存命中率。
优选地,所述多状态下的分布式q学习更新策略为:
其中,qm(sm,am)为无线节点m在当前状态sm,选择动作am时,其q表qm的价值;qm(s′m,a′m)为无线节点m在下一状态s′m,选择下一个动作a′m时,其q表qm的价值,phit(s,a)为无线节点m在当前状态sm选择动作am,得到联合状态s下,选择联合动作a时,所对应的平均缓存命中率。
优选地,于步骤s2中,对于存在多个最优联合动作的情况,通过引入附加的协商机制,即无线节点记录第一次获得最高平均缓存命中率的动作,进而保证所有无线节点找到最优的分布式缓存策略。
与现有技术相比,本发明一种基于多智能体强化学习的分布式缓存策略通过将无线节点模拟为智能体,在多智能体强化学习的框架中考虑如何最大化平均缓存命中概率,并基于分布式q学习的缓存策略以优化分布式缓存方案,进而最大化平均缓存命中率,本发明在缓存辅助下无线网络中,结合多智能体强化学习技术,找到最优缓存策略进行数据传输,大幅提高系统性能,以推动该分布式缓存方案在无线通信上的应用。
附图说明
图1为本发明一种基于多智能体强化学习的分布式缓存策略的流程示意图;
图2为在matlab仿真环境的相同系数下,本发明所提基于分布式q学习缓存策略与基于频率最大q值缓存策略、基于q学习缓存策略、概率缓存策略和最流行缓存策略五种方案的平均缓存命中率的仿真曲线对比图;
图3为在matlab仿真环境下,系数相同,本发明所提方法在无线节点一次可以存储的文件数n变化下的平均缓存命中率的仿真曲线图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种基于多智能体强化学习的分布式缓存策略的流程示意图。如图1所示,本发明一种基于多智能体强化学习的分布式缓存策略,应用于一无线缓存网络,该无线缓存网络包括多个无线节点,所有无线节点具有有限的存储容量并且服务于特定覆盖区域,所述分布式缓存策略包括:
步骤s1,基于多智能体强化学习框架,将各无线节点模拟为智能体,建立智能无线通信系统模型。在该智能无线通信系统模型中,每个无线节点不需要进行任何信息交换,仅仅通过独立学习,就能协同工作以最大化平均缓存命中率来提高系统性能
在该多智能体强化学习框架中,环境状态代表无线节点能观察到的当前环境状态,即当前自身存储了哪些文件;动作空间代表无线节点的动作,即选择存储哪些文件;回报代表无线节点的立即回报函数,即平均缓存命中率,无线节点的目标是协同工作以最大化平均缓存命中率来提高系统性能。
强化学习是一种通过试错方法,在不断与环境进行交互过程中获得环境的反馈信号不断调整自身行为的学习方法。具体地,考虑到强化学习是智能体与环境的交互中,通过试错法获得有效行为的方法,是智能体学习环境状态到动作空间的映射行为,目标是使得智能体从环境中得到的奖励信号最大。因此基于智能体强化学习的特性,建立了智能无线通信系统模型,假设每个无线节点配备有缓存控制单元(cachingcontrolunit),可以通过缓存控制单元智能地选择存储哪些文件,无线节点通过试错法并得到回报,即使工作在没有全局中心控制服务器的情况下,也可以通过这样的交互独立学习到自身的最优缓存策略。
具体地,考虑区域内有m个无线节点,每个无线节点的存储容量设置为c。定义无线节点的集合
其中l代表当前系统的文件总数;f代表齐普夫公式;
无线节点的目标是协同工作以最大化平均缓存命中率来提高系统性能,如下所示:
步骤s2,基于多智能体强化学习的分布式q学习算法,为每个无线节点找到最优的分布式缓存策略,进而最大化缓存命中率。
为了提高收敛速度,本发明引入ε-贪婪探索策略,以1-ε的概率贪婪选择当前最好的动作,并使用ε概率随机选择所有动作。无线节点找到最优的动作
在本发明具体实施例中,如果无线节点一次可以存储的文件数等于自身的存储容量,即n等于c时,则采取以下单状态下的分布式q学习更新策略:
qm(am)=max{qm(am),phit(a)},
其中qm(am)为第m个无线节点选择动作am时,其q表qm的值;phit(a)为第m个无线节点选择动作am时,其联合动作a所对应的平均缓存命中率。
其具体实现过程如下:
如果无线节点一次可以存储的文件数小于自身的存储容量,即n小于c时,则采取以下多状态下的分布式q学习更新策略:
其中qm(sm,am)为无线节点m在当前状态sm,选择动作am时,其q表qm的价值;qm(s′m,a′m)为无线节点m在下一状态s′m,选择下一个动作a′m时,其q表qm的价值;phit(s,a)为无线节点m在当前状态sm选择动作am,得到联合状态s下,选择联合动作a时,所对应的平均缓存命中率。
其具体实现过程如下:
对于上述两种情况,只要探索的次数足够多,那么无线节点自然有机会选择到最好的动作
优选地,对于存在多个最优联合动作的情况,例如,考虑当前系统有两个无线节点a、b,假设当无线节点a选择存储第1个文件这个动作,而无线节点b选择存储第2个文件这个动作时,是最优的联合动作;如果此时当无线节点a选择存储第2个文件这个动作,而无线节点b选择存储第1个文件这个动作时也是最优的联合动作,那么此时相当于存在两个最优联合动作,为了保证每个节点能正确选择到最优的动作
实施例
图2为在matlab仿真环境的相同系数下,本发明所提基于分布式q学习缓存策略与基于频率最大q值缓存策略、基于q学习缓存策略、概率缓存策略和最流行缓存策略五种方案的平均缓存命中率的仿真曲线对比图。图3为在matlab仿真环境下,系数相同,本发明所提方法在无线节点一次可以存储的文件数n变化下的平均缓存命中率的仿真曲线图。
在matlab仿真环境下,考虑有三个无线节点位于区域内,相当于m设置为3。分别设置三个无线节点的位置为(0.5,0.55),(0.45,0.6),(0.55,0.5),并将无线节点的覆盖半径r统一设置为0.5。此外,考虑文件流行度服从齐普夫定律,并将文件数l设置为4,流行度系数γ设置为0.3,每个无线节点的存储容量c设置为2。为了更好的对比本发明之缓存策略,本实施例同时给出了通过遍历得到的最优缓存策略,考虑到强化学习算法具有随机数,本实施例取1000次试验结果做平均,得到平均缓存命中率。
给定相同系数下不同缓存策略的平均缓存命中率的对比仿真曲线。图2表征的是在n=2的条件下,本发明之缓存策略、基于fmq(frequencymaximumq-value)缓存策略、基于q学习缓存策略、概率缓存策略和最流行内容缓存策略五种方案的平均缓存命中率仿真曲线。对比可以看出,本发明之缓存策略均明显优于其它缓存策略,并且最后收敛到最优缓存策略,充分验证了本发明的有效性。
给定相同系数下平均缓存命中率随无线节点一次可以存储的文件数n变化关系。图3表征的是相同系数下,无线节点一次可以存储的文件数n=1和n=2时,本发明所提方法的平均缓存命中率仿真曲线。对比可以看出,n=2的计算复杂度比n=1小。这是因为当n=2时,无线节点一次可以存储的文件数等于无线节点的存储容量c,在这种情况下,可以采用单状态下的分布式q学习算法进行求解最优缓存策略,而对于n=1的情况,只能采用多状态下的分布式q学习算法来求解最优缓存策略。此外,观察到当n=1和n=2时,本发明之缓存策略都能收敛到最优缓存策略,进一步验证了本发明的有效性。
综上所述,本发明一种基于多智能体强化学习的分布式缓存策略通过将无线节点模拟为智能体,在多智能体强化学习的框架中考虑如何最大化平均缓存命中概率,并基于分布式q学习的缓存策略以优化分布式缓存方案,进而最大化平均缓存命中率,本发明在缓存辅助下无线网络中,结合多智能体强化学习技术,找到最优缓存策略进行数据传输,大幅提高系统性能,以推动该分布式缓存方案在无线通信上的应用。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 还没有人留言评论。精彩留言会获得点赞!