一种数据处理方法及电子设备与流程
本申请涉及智能汽车技术领域,尤其涉及一种数据处理方法及电子设备。
背景技术:
随着技术的发展,无人驾驶汽车的研究与应用也越来越多。无人驾驶汽车中能够在没有驾驶员控制的情况下携带乘客安全到达目标位置。
但目前的自动驾驶领域中并不会过多的关注乘客在汽车内的乘坐体验。
技术实现要素:
有鉴于此,本申请提供了一种数据处理方法,包括:
获得触发指令,所述触发指令用于指示自动驾驶的交通工具启动音效增强模式;
响应于所述触发指令,启动所述音效增强模式;
其中,在所述音效增强模式下,将声音输出至所述自动驾驶的交通工具的内部空间,以增强位于所述内部空间的乘客的乘坐体验。
上述方法,优选的:
在所述音效增强模式下,将当前采集的声音输出至所述自动驾驶的交通工具的内部空间。
上述方法,优选的,将当前采集的声音输出至所述自动驾驶的交通工具的内部空间,包括:
确定目标声音源;
将所述目标声音源的声音输出至所述自动驾驶的交通工具的内部空间;
其中,所述目标声音源的声音输出至所述内部空间的音量大小与所述自动驾驶的交通工具的行驶的运行参数相关;
或/和
所述目标声音源的声音在所述内部空间输出的位置与所述目标声音源相对于所述自动驾驶的交通工具的位置相一致。
上述方法,优选的,获得触发指令,包括:
获得感应信息,所述感应信息用于表征位于所述自动驾驶的交通工具的内部空间的乘客关注所述自动驾驶的交通工具以外的目标物体;
基于所述感应信息,生成触发指令;
其中,所述感应信息还用于确定所述目标物体以及所述目标声音源,所述目标声音源与所述目标物体相关。
上述方法,优选的,将所述目标声音源的声音输出至所述自动驾驶的交通工具的内部空间,包括:
对所述目标声音源的声音进行第一处理,并将经过所述第一处理的目标声音源的声音输出至所述自动驾驶的交通工具的内部空间。
上述方法,优选的,所述第一处理包括:
对所述声音进行声强增强或减弱处理。
上述方法,优选的,将声音输出至所述自动驾驶的交通工具的内部空间,包括:
在所述音效增强模式下,获得所述自动驾驶的交通工具的行驶的运行参数;
基于所述行驶的运行参数,匹配出音效参数;
在所述自动驾驶的交通工具的行驶过程中,以与所述运行参数相匹配的所述音效参数输出声音至所述自动驾驶的交通工具的内部空间。
上述方法,优选的,不同的所述音效参数对应于不同种类的声音源。
上述方法,优选的,基于所述运行参数,匹配出音效参数,包括:
基于所述运行参数,匹配与所述运行参数相对应的音乐节奏。
本申请还提供了一种电子设备,包括:
控制器,用于获得触发指令,所述触发指令用于指示自动驾驶的交通工具启动音效增强模式;响应于所述触发指令,启动所述音效增强模式;
输出装置,用于在所述音效增强模式下,将声音输出至所述自动驾驶的交通工具的内部空间,以增强位于所述内部空间的乘客的乘坐体验。
本申请还提供了一种交通工具,包括:
本体,具有内部空间,所述内部空间用于承载乘客;
处理器,用于获得触发指令,所述触发指令用于指示自动驾驶的交通工具启动音效增强模式;响应于所述触发指令,启动所述音效增强模式;在所述音效增强模式下,将声音输出至所述内部空间,以增强位于所述内部空间的乘客的乘坐体验。
从上述技术方案可以看出,本申请公开的一种数据处理方法及电子设备,通过对触发指令进行获取,进而对该指令进行响应,从而指示自动驾驶的交通工具启动音效增强模式,由此在音效增强模式下,自动驾驶的交通工具将声音输出至内部空间,从而增强位于该内部空间的乘客的乘车体验。可见,本申请中通过在触发指令下启动自动驾驶的交通工具的音效增强模式进而将声音输出到乘客乘坐的内部空间,从而增强乘客的乘坐体验。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例一提供的一种数据处理方法的流程图;
图2-图8分别为本申请实施例的示例图;
图9为本申请实施例一的部分流程图;
图10为本申请实施例二提供的一种电子设备的结构示意图;
图11为本申请实施例的另一示例图;
图12为本申请实施例二的另一结构示意图;
图13为本申请实施例的另一示例图;
图14为本申请实施例三提供的一种交通工具的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
如图1所示,为本申请实施例一提供的一种数据处理方法的流程图,本实施例中的方法适用于自动驾驶的交通工具,如无人驾驶的汽车或飞机等等,用以增强交通工具中乘客的乘坐体验。
具体的,本实施例中的方法可以包括以下步骤:
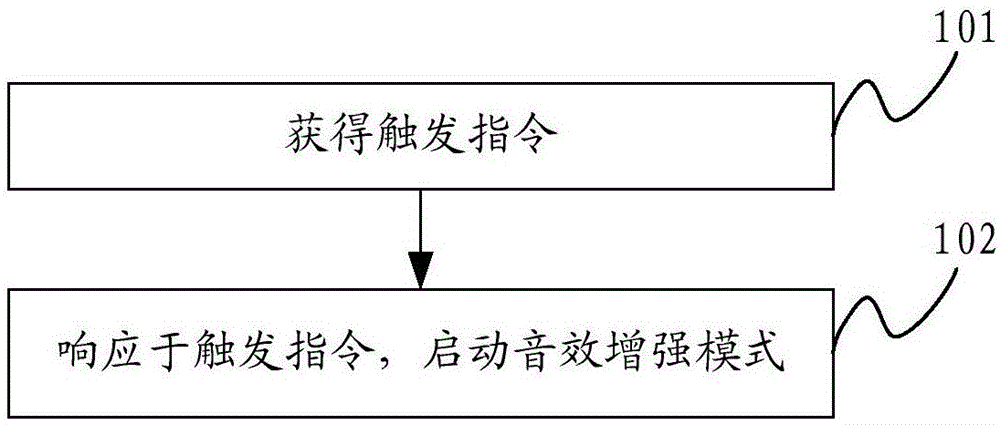
步骤101:获得触发指令。
其中,触发指令用于指示自动驾驶的交通工具启动音效增强模式。触发指令可以根据用户的需求操作所生成,也可以基于自动驾驶的交通工具的驾驶情况生成,进而在该触发指令下指示自动驾驶的交通工具启动音效增强模式。
步骤102:响应于触发指令,启动音效增强模式。
其中,在音效增强模式下,自动驾驶的交通工具将声音输出至自动驾驶的交通工具的内部空间,如图2中所示,以增强位于该内部空间的乘客的乘坐体验。
需要说明的是,本实施例中可以通过自动驾驶的交通工具本身来启动音效增强模式,例如,利用车辆内自带的音箱输出声音到内部空间,也可以通过与自动驾驶的交通工具相连接的输出设备启动音效增强模式,例如,利用独立设置在车辆上的播放器输出声音到内部空间。
其中,本实施例中输出至自动驾驶的交通工具内部空间的声音可以是交通工具以外的至少部分环境声音,如外界车辆鸣笛声音或行人说话声音等,也可以是交通工具内部的声音,如车辆内的鸣笛声音、车辆内的音乐声音或车辆内用户演讲声音等等。
从上述技术方案可以看出,本申请实施例一提供的一种数据处理方法,通过对触发指令进行获取,进而对该指令进行响应,从而指示自动驾驶的交通工具启动音效增强模式,由此在音效增强模式下,自动驾驶的交通工具将声音输出至内部空间,从而增强位于该内部空间的乘客的乘车体验。可见,本实施例中通过在触发指令下启动自动驾驶的交通工具的音效增强模式进而将声音输出到乘客乘坐的内部空间,从而增强乘客的乘坐体验。
在一种实现方式中,在音效增强模式下,自动驾驶的交通工具具体可以将预先设置的声音输出至自动驾驶的交通工具中,如叮叮、滴滴或音乐等声音,为乘客改善乘坐体验;或者,自动驾驶的交通工具将当前采集的声音输出至自动驾驶的交通工具中,如图3中所示,自动驾驶汽车实时采集车辆外的环境声音,将环境声音中至少部分声音如某辆车的鸣笛或某个行人的讲话声音等输出实时输出到车辆内,以提供给车辆内乘客听到车辆外的声音。
基于以上实现,本实施例中在音效增强模式下将当前采集的声音输出至自动驾驶的交通工具的内部空间时,具体可以通过以下方式实现:
首先,确定目标声音源,如发出声音的音源,如车辆或行人等,之后,将目标声音源的声音输出至自动驾驶的交通工具的内部空间。如图4中所示,本实施例中在确定需要收听的声音的声音源之后,对该目标声音源如行人a的声音进行实时采集,此时也可能采集到其他声音源的声音,但后续只会将行人a的声音输出至自动驾驶的交通工具的内部空间,以使得位于内部空间的乘客可以清晰的收听到行人a的声音,而不会受其他外界声音的干扰。
在具体实现中,本实施例在将目标声音源的声音输出至自动驾驶的交通工具的内部空间时,可以对目标声音源输出至内部空间的音量大小、输出位置和输出方向等输出参数中的一种或多种进行控制。
例如,本实施例中将目标声音源的声音输出至自动驾驶的交通工具的内部空间时,可以基于自动驾驶的交通工具的行驶的运行参数来确定目标声音源的声音音量大小。例如,根据自动驾驶车辆的行驶速度及距离目标声音源之间的距离,来确定目标声音源传输到自动驾驶车辆的声音音量,并对声音音量进行提高或减弱处理,再输出至自动驾驶车辆的内部空间,例如,随着自动驾驶车辆驾驶距离目标声音源越来越近或者越来越远的运行参数,调整目标声音源的声音音量逐渐增大或逐渐减小,从而模拟乘客位于车辆外接收目标声音源的声音的真实体验,由此改善乘客的乘坐体验。
当然,本实施例中也包含另一种实现:本实施例中在自动驾驶车辆上实时采集目标声音源的声音,并将目标声音源的声音不进行音量调整而以实时采集到的当前声音音量输出至自动驾驶车辆的内部空间。而进一步的,为了增强内部空间中乘客的乘坐体验,可以适当对实时采集到的目标声音源的声音音量进行调整,如增加或减小等,以模拟出乘客位于目标声音源的位置上接收声音的真实体验,由此改善乘客的乘坐体验。
再如,本实施例中将目标声音源的声音输出至自动驾驶的交通工具的内部空间时,可以基于自动驾驶的交通工具的行驶位置来确定目标声音源的声音在交通工具的内部空间的输出位置或输出方向。例如,根据自动驾驶车辆相对于目标声音源的行驶位置,来确定目标声音源相对于自动驾驶车辆的相对位置,进而在自动驾驶车辆的内部空间中确定与该相对于位置对应的输出位置,进而在采集到目标声音源的声音之后,将目标声音源的声音在该输出位置上进行输出。如图5中所示,随着自动驾驶车辆的行驶,行人b相对于自动驾驶车辆的位置可能是不断变化的,本实施例中将行人b的声音采集之后基于不断变化的行人b相对于自动驾驶车辆的位置,将行人b的声音在自动驾驶车辆的内部空间相对应的位置上进行输出,从而模拟乘客位于车辆外接收行人b声音的真实体验,由此改善乘客的乘坐体验。
进一步的,本实施例中为了增强内部空间中乘客的乘坐体验,在调整目标声音源的声音在自动驾驶的交通工具的内部空间的输出位置的基础上,还可以适当对实时采集到的目标声音源的声音进行第一处理,如对声强进行增强或减弱处理,也可以理解为对音量进行调整,如增加或减小等,以模拟出乘客位于车辆外接收声音的真实体验,如车辆距离行人b越远,声音音量越来越小,车辆距离行人b越近,声音音量越大,如图6中所示,声音的输出位置也随之变动等,由此改善乘客的乘坐体验。
基于以上实现,本实施例中在获得触发指令时,具体可以采用以下方式实现;
首先,获得感应信息,该感应信息用以表征位于自动驾驶的交通工具的内部空间的乘客关注所述自动驾驶的交通工具以外的目标物体。其中,感应信息可以利用图像采集设备如摄像头获得,例如,利用摄像头采集乘客图像,以识别出乘客的朝向,再利用摄像头采集乘客朝向的正前方所关注区域的图像,进而识别出表征乘客关注的目标物体的感应信息;或者,感应信息可以利用眼球追踪设备获得,例如,利用增强现实ar(augmentedreality)眼镜中的眼球追踪设备获得乘客眼球的运动信息,进而解析出乘客眼球朝向的目标物体的感应信息,等等。
需要说明的是,本实施例中的感应信息可以是乘客发现目标声音源之后有目的的关注目标物体所获得到的信息,例如,乘客乘坐在自动驾驶的车辆中,乘客发现右侧车道上有电动汽车与行人c发生剐蹭,出现争吵的声音,乘客关注电动汽车和行人c,如图7中所示,本实施例中通过眼球追踪设备获得乘客关注于电动汽车和行人c的感应信息。
之后,基于所获得的感应信息,生成触发指令。
其中,本实施例中在获得到乘客关注目标物体的感应信息之后,生成触发指令,进而在该触发指令下,为乘客启动自动驾驶的交通工具的音效增强模式,从而将目标物体所对应的目标声音源的声音进行实时采集,并以一定的输出方式(如音量调整和/或位置调整后的输出方式)输出到自动驾驶的交通工具的内部空间中,以增强乘客的乘坐体验。
例如,乘客乘坐在自动驾驶的车辆中,乘客关注右侧车道上电动汽车和行人c,本实施例中通过眼球追踪设备获得乘客关注于电动汽车和行人c的感应信息,之后,生成触发指令,在该触发指令之后,为乘客启动自动驾驶车辆的音效增强模式,在该音效增强模式下将行人c和/或电动汽车的驾驶员的声音进行实时采集,对采集到的声音进行音量增强后输出到自动驾驶车辆的内部空间中,且在内部空间中的输出位置为乘客与行人c之间的相对位置上,如图8中所示,由此为乘客增强模拟位于行人c最近位置上的声音接收体验,进而增强乘客的乘坐体验。
另外,本实施例中除了采集自动驾驶的交通工具之外的声音输出至自动驾驶的交通工具的内部空间,还可以将自动驾驶的交通工具内的声音在内部空间中以增强音效模式进行输出。例如,在自动驾驶车辆中,乘客在收听钢琴曲等音乐时,本实施例中可以对钢琴曲的播放器所输出的钢琴曲声音进行音量调整、声道调整及输出位置调整等处理,以环绕立体声的模式输出至车辆内部空间,由此,为乘客模拟音乐会中的声音收听场景,从而增强乘客的乘坐体验。
进一步的,本实施例中在采集自动驾驶的交通工具之外的声音输出至自动驾驶的交通工具的内部空间,可以同时自动驾驶的交通工具内的声音在内部空间中以增强音效模式进行输出。例如,在自动驾驶车辆中,乘客在聚精会神的观看电影时,本实施例中可以对电影播放器所输出的角色对话声音进行音量调整出来,以输出至车辆内部空间,此时,本实施例还可以对自动驾驶车辆外的某个目标物体如街头歌唱家的声音进行采集并进行音量调整及输出位置的调整之后输出到车辆内部空间,同时对电影播放器所输出的角色对话声音进行音量降低,以提醒乘客有街头歌唱家在演绎某个曲目,由此避免乘客错过街头精彩景色,进一步增强乘客的乘坐体验。
在一种实现方式中,本实施例在将声音输出至自动驾驶的交通工具的内部空间时,具体可以通过以下步骤实现,如图9中所示:
步骤901:在音效增强模式下,获得自动驾驶的交通工具的行驶的运行参数。
其中,自动驾驶的交通工具的行驶的运行参数可以为:自动驾驶的交通工具在行驶中的行驶状态、行驶速度、行驶加速度、行驶车道等等。其中行驶状态可以包括有:起步状态、刹车状态、加油状态、熄火状态、鸣笛状态、音频播放状态中的一种或多种等等,行驶车道可以为:高速公路行驶、山路行驶、城市道路行驶等等。
步骤902:基于行驶的运行参数,匹配出音效参数。
其中,本实施例中可以根据乘客需求,基于运行参数匹配出满足乘客乘坐需求的音效参数,例如,乘客对自动行驶的交通工具进行输入操作,如触控或声音输入等,以表达乘客所需要体验的乘坐体验所对应的音效参数需求,如飙车乘坐体验、飞机或火车等乘坐体验对应的音效参数;或者,本实施例中可以基于预设的匹配规则,基于运行参数匹配出相应音效参数,例如匹配规则可以为:男行人的声音对应于某个动画人物的发音音效、女行人的声音对应与另一个动画人物的发音音效,等等。
步骤903:在自动驾驶的交通工具的形式过程中,以与运行参数相匹配的音效参数输出声音至自动驾驶的交通工具的内部空间。
其中,不同种类声音源的声音可以对应于不同的音效参数,例如,电动汽车的声音以音量小且高频段的音效参数进行输出;大卡车的声音以音量大且低频的低沉音效参数进行输出,等等。
例如,本实施例中在自动驾驶车辆在踩油门加速时时,以高速运行下的音效参数输出所采集到的行人声音,如只输出行人声音的前半截,后半截消音;
或者,本实施例中在自动驾驶车辆中,输出火车哐当声音到车内,在车辆鸣笛并将车辆鸣笛的声音采集输出到车内时,以火车拉笛的声音输出效果进行输出,带给乘客乘坐火车的真实体验。
另外,本实施例中步骤902在基于行驶的运行参数匹配音效参数时,具体还可以基于运行参数匹配与该运行参数相对应的音乐节奏。
这里的音乐节奏可以理解为经典影片或歌曲的音乐节奏或片段等,由此,在乘客乘坐自动驾驶车辆时,可以自在体验经典的音乐节奏带来的快感,如经典飙车的音乐节奏或经典谍战影片的背景音乐等等。
例如,本实施例中在自动驾驶车辆中,输出大马力引擎运行的声音到到车内,模拟出超跑的乘车体验,并在车辆加速、转弯或急刹车时,使用经典的引擎高速运转的音乐节奏及谍战影片背景音乐输出到车内,进一步带给乘客乘坐超跑飙车追逐的乘车体验。
参考图10,为本申请实施例二提供的一种电子设备的结构示意图,该电子设备可以为设置在自动驾驶的交通工具如自动驾驶车辆中,用以增强交通工具中乘客的乘坐体验。
在本实施例中,该电子设备中可以包括以下结构:
控制器1001,用于获得触发指令,所述触发指令用于指示自动驾驶的交通工具启动音效增强模式;响应于所述触发指令,启动所述音效增强模式。
其中,触发指令用于指示自动驾驶的交通工具启动音效增强模式。触发指令可以根据用户的需求操作所生成,也可以基于自动驾驶的交通工具的驾驶情况生成,进而在该触发指令下指示自动驾驶的交通工具启动音效增强模式。
输出装置1002,用于在所述音效增强模式下,将声音输出至所述自动驾驶的交通工具的内部空间,以增强位于所述内部空间的乘客的乘坐体验。
其中,输出装置1002中可以包括至少一个播放器如喇叭等,用以将声音输出至交通工具的内部空间。
本实施例中,在音效增强模式下,输出装置1002在自动驾驶的交通工具中将声音输出至自动驾驶的交通工具的内部空间,如图11中所示,以增强位于该内部空间的乘客的乘坐体验。
其中,输出装置1002可以通过自动驾驶的交通工具如车辆内自带的音箱设备实现,以输出声音到内部空间,也可以通过与自动驾驶的交通工具相连接的输出设备启动音效增强模式,例如,利用独立设置在车辆上的播放器输出声音到内部空间。
其中,本实施例中输出至自动驾驶的交通工具内部空间的声音可以是交通工具以外的至少部分环境声音,如外界车辆鸣笛声音或行人说话声音等,也可以是交通工具内部的声音,如车辆内的鸣笛声音、车辆内的音乐声音或车辆内用户演讲声音等等。
从上述技术方案可以看出,本申请实施例二提供的一种电子设备,通过对触发指令进行获取,进而对该指令进行响应,从而指示自动驾驶的交通工具启动音效增强模式,由此在音效增强模式下,自动驾驶的交通工具将声音输出至内部空间,从而增强位于该内部空间的乘客的乘车体验。可见,本实施例中通过在触发指令下启动自动驾驶的交通工具的音效增强模式进而将声音输出到乘客乘坐的内部空间,从而增强乘客的乘坐体验。
其中,如图12中所示,本实施例中的电子设备中还可以包括有,声音采集装置1003,如麦克风等,用以实时采集声音,相应的,在所述音效增强模式下,输出装置1002将声音采集装置1003当前采集的声音输出至所述自动驾驶的交通工具的内部空间。
具体的,输出装置1002在将当前采集的声音输出至所述自动驾驶的交通工具的内部空间,具体可以通过以下方式实现:
确定目标声音源;将所述目标声音源的声音输出至所述自动驾驶的交通工具的内部空间;其中,所述目标声音源的声音输出至所述内部空间的音量大小与所述自动驾驶的交通工具的行驶的运行参数相关;
或/和,所述目标声音源的声音在所述内部空间输出的位置与所述目标声音源相对于所述自动驾驶的交通工具的位置相一致。
相应的,控制器1001获得触发指令具体可以为:
获得感应信息,所述感应信息用于表征位于所述自动驾驶的交通工具的内部空间的乘客关注所述自动驾驶的交通工具以外的目标物体;基于所述感应信息,生成触发指令;其中,所述感应信息还用于确定所述目标物体以及所述目标声音源,所述目标声音源与所述目标物体相关。
在另一种实现中,输出装置1002在将所述目标声音源的声音输出至所述自动驾驶的交通工具的内部空间,还可以包括以下实现:
对所述目标声音源的声音进行第一处理,并将经过所述第一处理的目标声音源的声音输出至所述自动驾驶的交通工具的内部空间。
其中,第一处理可以为:对所述声音进行声强增强或减弱处理。
另外,输出装置1002将声音输出至所述自动驾驶的交通工具的内部空间,还可以通过以下方式实现:
在所述音效增强模式下,获得所述自动驾驶的交通工具的行驶的运行参数;基于所述行驶的运行参数,匹配出音效参数;在所述自动驾驶的交通工具的行驶过程中,以与所述运行参数相匹配的所述音效参数输出声音至所述自动驾驶的交通工具的内部空间。
其中,不同的所述音效参数对应于不同种类的声音源。
另一种实现中,输出装置1002在基于所述运行参数,匹配出音效参数时,具体可以为:基于所述运行参数,匹配与所述运行参数相对应的音乐节奏。
需要说明的是,输出装置1002中的播放器在交通工具内部空间的设置位置可以不同,如图13中所示,由此实现将声音以不同的位置或方向输出至交通工具的内部空间。
参考图14,为本申请实施例三提供的一种交通工具的结构示意图,该交通工具可以为自动驾驶的交通工具,具体如自动驾驶车辆、轮船或飞机等,本实施例中的技术方案用以增强交通工具中乘客的乘坐体验。
在本实施例中,自动驾驶的交通工具中可以包括以下结构:
本体1401,具有内部空间,该内部空间中可以承载乘客,或者携带其他物体,如行李等。
具体的,本体1401中可以包括有壳体(汽车、轮船、飞机、火车等的壳体)、动力结构(如发动机)及行驶结构(汽车车轮、船螺旋桨)等,其中,动力结构用以驱动行驶结构带动壳体及壳体所形成的内部空间中的乘客移动。
处理器1402,设置在本体1401上,用于获得触发指令,触发指令用于指示自动驾驶的交通工具启动音效增强模式;响应于触发指令,启动所述音效增强模式,并在音效增强模式下,将声音输出至本体1401的内部空间,以增强位于内部空间的乘客的乘坐体验。
其中,触发指令用于指示自动驾驶的交通工具启动音效增强模式。触发指令可以根据用户的需求操作所生成,也可以基于自动驾驶的交通工具的驾驶情况生成,进而在该触发指令下指示自动驾驶的交通工具启动音效增强模式。
具体的,处理器1402在将声音输出至本体1401的内部空间时,可以通过设置在本体1401上的输出装置实现,其中,输出装置可以包括至少一个播放器,如车辆内自带的音箱设备等,用以将声音输出至本体1401的内部空间。
其中,本实施例中输出装置输出至本体1401内部空间的声音可以是交通工具以外的至少部分环境声音,如外界车辆鸣笛声音或行人说话声音等,也可以是交通工具内部的声音,如车辆内的鸣笛声音、车辆内的音乐声音或车辆内用户演讲声音等等。
从上述技术方案可以看出,本申请实施例三提供的一种自动驾驶的交通工具,通过处理器对触发指令进行获取,进而对该指令进行响应,从而指示自动驾驶的交通工具启动音效增强模式,由此在音效增强模式下,自动驾驶的交通工具将声音输出至本体的内部空间中,从而增强位于该内部空间的乘客的乘车体验。可见,本实施例中通过在触发指令下启动自动驾驶的交通工具的音效增强模式进而将声音输出到乘客乘坐的内部空间,从而增强乘客的乘坐体验。
其中,本实施例中,可以通过在自动驾驶的交通工具中设置麦克风等声音采集装置,用以实时采集声音,相应的,在所述音效增强模式下,处理器1402将声音采集装置当前采集的声音输出至所述自动驾驶的交通工具的内部空间。
具体的,处理器1402在将当前采集的声音输出至本体1401的内部空间,具体可以通过以下方式实现:
确定目标声音源;将目标声音源的声音输出至本体1401的内部空间;其中,目标声音源的声音输出至内部空间的音量大小与自动驾驶的交通工具的行驶的运行参数相关;
或/和,所述目标声音源的声音在所述内部空间输出的位置与所述目标声音源相对于所述自动驾驶的交通工具的位置相一致。
需要说明的是,输出装置中的播放器在交通工具内部空间的设置位置可以不同,由此实现将声音以不同的位置或方向输出至交通工具的内部空间。
相应的,处理器1402获得触发指令具体可以为:
获得感应信息,所述感应信息用于表征位于所述自动驾驶的交通工具的内部空间的乘客关注所述自动驾驶的交通工具以外的目标物体;基于所述感应信息,生成触发指令;其中,所述感应信息还用于确定所述目标物体以及所述目标声音源,所述目标声音源与所述目标物体相关。
在另一种实现中,处理器1402在将所述目标声音源的声音输出至所述自动驾驶的交通工具的内部空间,还可以包括以下实现:
对所述目标声音源的声音进行第一处理,并将经过所述第一处理的目标声音源的声音输出至所述自动驾驶的交通工具的内部空间。
其中,第一处理可以为:对所述声音进行声强增强或减弱处理。
另外,处理器1402将声音输出至所述自动驾驶的交通工具的内部空间,还可以通过以下方式实现:
在所述音效增强模式下,获得所述自动驾驶的交通工具的行驶的运行参数;基于所述行驶的运行参数,匹配出音效参数;在所述自动驾驶的交通工具的行驶过程中,以与所述运行参数相匹配的所述音效参数输出声音至所述自动驾驶的交通工具的内部空间。
其中,不同的所述音效参数对应于不同种类的声音源。
另一种实现中,处理器1402在基于所述运行参数,匹配出音效参数时,具体可以为:基于所述运行参数,匹配与所述运行参数相对应的音乐节奏。
另外,以下以驾驶汽车为例,对本实施例中的技术方案进行举例说明:
对于汽车驾驶员或乘客来说,在车辆行驶中,除了看,听也是个很重要的信息,比如有经验的司机可以听出来左右盲区有没有车辆,作为变道时的辅助。但是由于行人,电动自行车,电动汽车的噪声本身就比较小,所以听不完全管用。尤其电动汽车越来越多,行驶在路上,都是悄悄的,无法及时进行车辆控制,为此,提出以下方案:
首先,乘坐汽车可以通过外置传感器感知到周围的车辆。然后,通过车厢内的喇叭,主动制造并播放一定的声音,声音的类型和方位于外面的车辆向符合。对于驾驶员的主观感受就是,听到了外面的车。
除了模拟车辆本身噪声,更进一步的,驾驶员可以选择自己喜欢的声音替代外部噪声,比如摩托车声音替代电动自行车,叮叮叮的声音替代公交车。。拖拉机的声音替代大货车噪声等等,由此改善驾驶员或乘客的乘坐体验。
可见,本实施例中的技术方案应用到有人驾驶或者无人驾驶的汽车中,具有三个模式,屏蔽外界的的环境音,如乘客需要休息的模式,普通模式,增强模式,即将外界的环境音或者某一个具体位置的环境音采采集回来输出至车内,从而让用户能够更好的了解车外某一个具体事件的情况。
本申请的实施例所提供的无人驾驶的车辆针对内部的乘客提供音效增强体验。可以是针对ar的声音增强,也可以是用户选择不同的声音效果输出,上述的声音效果与该无人驾驶的车辆的行驶参数匹配。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!