一种用于语音位置显示的监控摄像机及其控制方法与流程
本发明属于电子电路技术领域,尤其涉及一种用于语音位置显示的监控摄像机及其控制方法。
背景技术:
传统的安防监控摄像机采用的是全向型采音模式,针对处于摄像机周围的任何角度,只要在摄像机采声口音量达到采音音量条件,声音即被录取;但是,该声音很大一部分是摄像机镜头拍摄的角度范围以外区域的音源产生,属于无效的干扰音源,会影响到录像回放时对声音来源的判断。例如:一公交车的录像回放中,出现异常尖叫声,则此时无法判断尖叫声源是摄像机拍摄区域内还是拍摄区域外。
并且,在传统的安防监控摄像机的录像音视频回放过程中,可通过图像直观分辨人、物在拍摄区内的位置,以及其移动的方向,但无法利用声音信息判定声音来源方位及声音位移方向,更无法将录像中声音的发音源与视频图像中的人、物对应起来。例如:录像回放中,视频中有分布的多个人物(无法看到嘴型变化),音频中有一个人说话的语音,但无法判定声音是哪个人发出来的。
因此,现有的安防监控摄像机存在着无法确定声音源与图像中发出声音的生物体进行一一对应的问题。
技术实现要素:
本发明的目的在于提供一种用于语音位置显示的监控摄像机及其控制方法,旨在解决现有的安防监控摄像机存在着无法确定声音源与图像中发出声音的生物体进行一一对应的问题。
本发明第一方面提供了一种用于语音位置显示的监控摄像机,包括主体和摄像头,所述摄像头设于主体的一侧面上,所述摄像头用于采集图像信号,所述监控摄像机还包括:
均设于所述侧面上,用于采集预设区域内的声音,并输出不同通道的模拟音频信号的至少两个拾音器;
与至少两个所述拾音器连接,用于分别对所述模拟音频信号进行滤波及放大处理的带通放大模块;
与所述带通放大模块连接,用于对滤波及放大处理后的所述模拟音频信号进行模数转换后,输出数字音频信号的模数转换模块;
与所述模数转换模块连接,用于根据所述数字音频信号,以形成坐标矩阵的处理模块;以及
与所述处理模块及所述摄像头连接,用于根据所述坐标矩阵及结合所述图像信号,确定所述声音的发出者的视频叠加模块。
本发明第二方面提供了一种用于语音位置显示的监控摄像机的控制方法,所述监控摄像机包括主体和摄像头,所述摄像头设于主体的一侧面上,所述摄像头用于采集图像信号,所述控制方法包括:
采用至少两个拾音器采集预设区域内的声音,并输出不同通道的模拟音频信号;
采用带通放大模块分别对所述模拟音频信号进行滤波及放大处理;
采用模数转换模块对滤波及放大处理后的所述模拟音频信号进行模数转换后,输出数字音频信号;
采用处理模块根据所述数字音频信号,以形成坐标矩阵;
采用视频叠加模块根据所述坐标矩阵及结合所述图像信号,确定所述声音的发出者。
本发明提供的一种用于语音位置显示的监控摄像机及其控制方法,监控摄像机包括主体和摄像头,摄像头设于主体的一侧面上,摄像头用于采集图像信号,通过至少两个拾音器采集预设区域内的声音,并输出不同通道的模拟音频信号;接着带通放大模块分别对模拟音频信号进行滤波及放大处理;并采用模数转换模块对滤波及放大处理后的模拟音频信号进行模数转换后,输出数字音频信号;处理模块根据数字音频信号,以形成坐标矩阵;最终视频叠加模块根据坐标矩阵及结合图像信号,确定所述声音的发出者。由此实现了将声音的发音源与图像信号中的人、物对应起来,起到了智能匹配的效果,有利于警察侦破案件,解决了现有的安防监控摄像机存在着无法确定声音源与图像中发出声音的生物体进行一一对应的问题。
附图说明
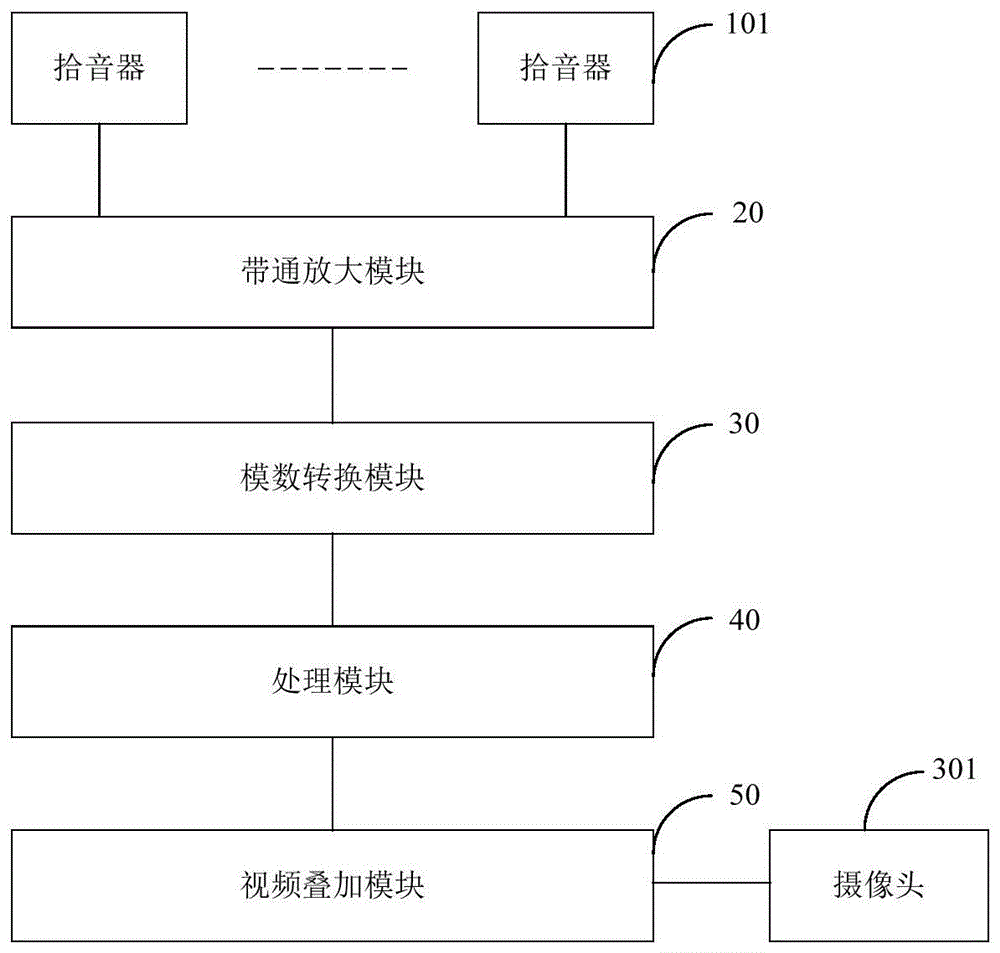
图1是本发明一实施例提供的一种用于语音位置显示的监控摄像机的模块结构示意图。
图2是本发明一实施例提供的一种用于语音位置显示的监控摄像机的具体模块结构示意图。
图3是本发明一实施例提供的一种用于语音位置显示的监控摄像机的结构示意图。
图4是本发明一实施例提供的一种用于语音位置显示的监控摄像机中的拾音器的结构示意图。
图5是本发明一实施例提供的一种用于语音位置显示的监控摄像机的示例电路图。
图6是本发明一实施例提供的一种用于语音位置显示的监控摄像机中确定坐标矩阵的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
上述的一种用于语音位置显示的监控摄像机及其控制方法,监控摄像机包括主体和摄像头,摄像头设于主体的一侧面上,摄像头用于采集图像信号,通过至少两个拾音器采集预设区域内的声音,并输出不同通道的模拟音频信号;接着带通放大模块分别对模拟音频信号进行滤波及放大处理;并采用模数转换模块对滤波及放大处理后的模拟音频信号进行模数转换后,输出数字音频信号;处理模块根据数字音频信号,以形成坐标矩阵;最终视频叠加模块根据坐标矩阵及结合图像信号,确定所述声音的发出者。由此实现了将声音的发音源与图像信号中的人、物对应起来,起到了智能匹配的效果,有利于警察侦破案件。
图1和图2示出了本发明一实施例提供的一种用于语音位置显示的监控摄像机的模块结构,为了便于说明,仅示出了与本实施例相关的部分,详述如下:
上述一种用于语音位置显示的监控摄像机,包括主体302和摄像头301,摄像头301设于主体302的一侧面上,摄像头301用于采集图像信号,该监控摄像机还包括至少两个拾音器(图1采用101表示)、带通放大模块20、模数转换模块30、处理模块40以及视频叠加模块50。
至少两个拾音器101均设于所述侧面上,用于采集预设区域内的声音,并输出不同通道的模拟音频信号。
带通放大模块20与至少两个所述拾音器101连接,用于分别对模拟音频信号进行滤波及放大处理。
模数转换模块30与带通放大模块20连接,用于对滤波及放大处理后的模拟音频信号进行模数转换后,输出数字音频信号。
处理模块40与模数转换模块30连接,用于根据数字音频信号,以形成坐标矩阵。
视频叠加模块50与处理模块40及摄像头301连接,用于根据坐标矩阵及结合图像信号,确定所述声音的发出者。
在一实施例中,至少两个拾音器包括第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104。
因此,由于设置了四个拾音器,使得经处理模块40处理后形成的坐标矩阵具体为:x轴比较器通过对上下通道音频电平幅度计算,得出两组可比对的x轴声源,经均值处理判定发音位置的上下方位;y轴比较器通过对左右通道音频电平幅度计算,得出两组可比对的y值声源,经均值处理判定发音位置的左右方位,音源坐标还原算法根据x、y轴的位置,并处理转换成音源的坐标信息(可以与叠加到视频图像的位置区域中,也可以是坐标字附串信息的输出)。
并且,带通放大模块包括第一带通放大单元201、第二带通放大单元202、第三带通放大单元203以及第四带通放大单元204;
第一带通放大单元201、第二带通放大单元202、第三带通放大单元203以及第四带通放大单元204分别与第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104一一对应连接。由此实现了第一带通放大单元201对第一拾音器101输出的模拟音频信号进行滤波及放大处理,第二带通放大单元202对第二拾音器102输出的模拟音频信号进行滤波及放大处理,第三带通放大单元203对第三拾音器103输出的模拟音频信号进行滤波及放大处理,第四带通放大单元204对第四拾音器104输出的模拟音频信号进行滤波及放大处理。由于人类语音的频谱特征主要为300hz~3khz,因此每个拾音器对应有一路带通滤波电路,带通频段为300hz~3khz,以过滤掉音频外的干扰音源。
由图3可得,上述第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104分别设于所述侧面上的四个角边沿位置。
同时,上述第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104两两之间的距离不小于预设值,预设值的范围为5厘米~10厘米。因此,使得每个拾音器不会受到相互干扰。同时,上述第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104通过物理的隔音,过滤掉声音源的直线传播,即过滤掉喇叭夹角以外的音源的直线传播,形成第一级(物理性)声场方向过滤,从而衰减掉喇叭口型方向以外的音源。上述第一拾音器101、第二拾音器102、第三拾音器103以及第四拾音器104均选用具备有指向型拾音器。
由图4可得,上述第一拾音器101、第二拾音器、第三拾音器以及第四拾音器均包括:
采音腔1011和麦克风1012;
麦克风1012设于采音腔1011的腔体中央位置,采音腔1011的形状为喇叭状,并且采音腔1011的朝向与摄像头301的朝向一致,也即是采音腔1011的采音夹角=麦克风1012的指向夹角=摄像头301的视场角,因此这样可以保证采音腔1011采集到的声音信号与摄像头301采集到的图像信号的匹配更为精确。
图5示出了本发明一实施例提供的一种用于语音位置显示的监控摄像机的示例电路,为了便于说明,仅示出了与本实施例相关的部分,详述如下:
作为本发明一实施例,上述第一带通放大单元201、第二带通放大单元202、第三带通放大单元203以及第四带通放大单元204的具体电路结果一致,以第一带通放大单元201为例进行说明,第一带通放大单元201包括:
第一电阻r1、第二电阻r2、第三电阻r9、第四电阻r10、第五电阻r11、可调电阻rw1、第一电容c1、第二电容c2以及放大芯片u1;
第一电阻r1的第一端接第一拾音器101,第一电阻r1的第二端与第一电容c1的第一端接放大芯片u1的第一正相输入端,第二电阻r2的第一端与第三电阻r9的第一端接放大芯片u1的第一反相输入端,第三电阻r9的第二端与第二电容c2的第一端接放大芯片u1的第一输出端,第二电容c2的第二端与第五电阻r11的第一端接放大芯片u1的第二正相输入端,可调电阻rw1的第一端与第四电阻r10的第一端接放大芯片u1的第二反相输入端,第四电阻r10的第二端接放大芯片u1的第二输出端,第一电容c1的第二端、第二电阻r2的第二端、第五电阻r11的第二端以及可调电阻rw1的第二端接地。
作为本发明一实施例,上述模数转换模块30采用模数转换芯片u5实现。
作为本发明一实施例,上述处理模块40采用微处理器实现。
作为本发明一实施例,上述视频叠加模块50采用视频叠加芯片u6-c实现。
图6示出了本发明一实施例提供的一种用于语音位置显示的监控摄像机中确定坐标矩阵的示意图,以下结合图1-图6对上述一种用于语音位置显示的监控摄像机的工作原理进行描述如下:
将四个拾声器简称为a1、a2、b1、b2,每路拾音器接入一路带通波段电路,带通波段电路由一组低通滤波电路(lpf)与一组高通滤波电路(hpf)组成,组合成带通频段为300hz~3khz,lpf的截止频率fl=3khz,hpf的截止频率fh=300hz,经滤掉无效干扰频段的音源后再接入前置音频放大电路。
以mic1通道为参考,低通滤波电路由第一电阻r1和第一电容c1组成,高通滤波电路由第二电容c2和第五电阻r11组成。
各路音频放大电路的放大倍数因器件的精度偏差或物理结构采音效果偏差,所以各电路设计可调电阻rw1对每路放大进行的微调(在专用测试环境中进行),使四组音频电路的放大输出的电平幅度偏差降到可接受的范围(如:小于1%)。
接着,四路音频经a/d转换,将四路模拟音频电平转化成数字音频并输出到处理模块40。
a1与a2进行比较得出横向一电平强弱偏差量,即x1轴;
b1与b2进行比较得出横向二电平强弱偏差量,即x2轴;
a1与b1进行比较得出纵向一电平强弱偏差量,即y1轴;
a2与b2进行比较得出纵向二电平强弱偏差量,即y2轴;
x1轴与x2轴经平均处理,得中间值,定义为x轴;
y1轴与y2轴经平均处理,得中间值,定义为y轴;
音源坐标标识生成器以图像传感器的水平、垂直像素比为基准,根据x轴与y轴坐标比,等分换算得出对应于图像中的具体位置,并生成虚拟有x、y的属性,并以x与y轴交汇点为中心生成音源位置坐标的图标。坐标不仅可以生成示意图形式,也可直接输出坐标文本信息。最终视频叠加模块60根据坐标矩阵及结合图像信号,确定所述声音的发出者。由此实现了将声音的发音源与图像信号中的人、物对应起来,起到了智能匹配的效果,有利于警察侦破案件。
本发明另一实施例还提供了用于语音位置显示的监控摄像机的控制方法,监控摄像机包括主体和摄像头,摄像头设于主体的一侧面上,摄像头用于采集图像信号,该控制方法包括:
采用至少两个拾音器采集预设区域内的声音,并输出不同通道的模拟音频信号;
采用带通放大模块分别对模拟音频信号进行滤波及放大处理;
采用模数转换模块对滤波及放大处理后的模拟音频信号进行模数转换后,输出数字音频信号;
采用处理模块根据数字音频信号,以形成坐标矩阵;
采用视频叠加模块根据坐标矩阵及结合图像信号,确定声音的发出者。
综上,本发明实施例提供的一种用于语音位置显示的监控摄像机及其控制方法,监控摄像机包括主体和摄像头,摄像头设于主体的一侧面上,摄像头用于采集图像信号,通过至少两个拾音器采集预设区域内的声音,并输出不同通道的模拟音频信号;接着带通放大模块分别对模拟音频信号进行滤波及放大处理;并采用模数转换模块对滤波及放大处理后的模拟音频信号进行模数转换后,输出数字音频信号;处理模块根据数字音频信号,以形成坐标矩阵;最终视频叠加模块根据坐标矩阵及结合图像信号,确定所述声音的发出者。由此实现了将声音的发音源与图像信号中的人、物对应起来,起到了智能匹配的效果,有利于警察侦破案件,解决了现有的安防监控摄像机存在着无法确定声音源与图像中发出声音的生物体进行一一对应的问题。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!