基于智能手机的智能啸叫抑制装置和方法与流程
本发明属于语音信号处理技术领域,涉及一种基于智能手机的智能啸叫抑制算法,将神经网络与传统算法相结合,以实现助听器啸叫的高效抑制和消除。该算法将在助听器芯片上实现并通过云端数据共享来实现硬件的软升级。具体涉及基于智能手机的智能啸叫抑制方法。
背景技术:
近年来,随着我国人口老龄化问题的加重,听力障碍逐步成为影响老年人健康的主要因素之一,佩戴助听器已成为听力障碍人士改善自身听力的主要手段。研究表明,佩戴助听器可以有效的缓解听力损伤患者的听力损失,帮助患者改善生活质量。
在助听器的使用过程中,啸叫问题是使用者抱怨频率最高的问题之一。相应的,啸叫抑制算法是数字助听器算法的重要部分。在助听器系统中,当反馈回路与放大器件同时工作,由麦克风采集到的声信号经由放大器件放大后由扬声器输出,通过反馈回路再次被麦克风采集进入系统。这样反复放大造成输出的信号产生高强度的振荡,产生啸叫。这种由反馈引起的系统不稳定造成的啸叫声听起来像是从助听器发出的连续的高频音调或是哨音,即可以将啸叫信号看成是高频的正弦信号。
啸叫效应会严重地影响助听器使用者的体验,因此数字助听器当中的啸叫抑制算法非常关键,是助听器语音算法当中的重要组成部分。传统的助听器回波抵消算法包括lms(leastmeansquare,最小均方误差)算法以及lms算法的一系列改进算法都存在着收敛速度与稳定性矛盾的问题,因此,需要一种能够满足实际使用需要的算法。
技术实现要素:
为克服现有技术的不足,本发明旨在提出一种基于智能手机的智能啸叫抑制算法。本发明把啸叫抑制算法与神经网络相结合,并将算法搭建在智能手机app(application,应用程序)中,通过蓝牙实现智能手机与助听器和数据云端三者之间的通信。
本发明的目的是通过以下技术方案实现的:
基于智能手机的智能啸叫抑制方法,将助听器从外界接收带啸叫语音信号通过基于人工神经网络的智能啸叫抑制算法应用处理后,输出到助听器进行进一步的处理,最后转化为人耳能够识别的语音信号,所述基于人工神经网络的智能啸叫抑制算法包括以下流程步骤:
(1)通过对语音数据库的语音信号以及啸叫信号进行特征参数提取,并对提取到的特征参数进行网络训练,得到成熟的网络作为反向传播bp(backpropagation)神经网络的中间层;
(2)助听器从外界接收语音信号传输到手机端后,通过加权叠加wola(weightedoverlap-add)分析滤波器组进行信号多通道处理并形成有两条路径,同时保存语音信号的相位;
(3)第一条路径首先对语音信号进行特征参数提取,然后通过啸叫检测模块判断是否发生啸叫;第二条路径提取保存的相位;
(4)若检测到啸叫信号,则将提取到的特征参数作为bp神经网络的输入,神经网络的输出为啸叫信号功率,之后将啸叫信号从原始信号中减去,同时将啸叫信号功率上传至数据云端;否则直接将特征参数上传至数据云端;
(5)wola综合滤波器组综合两条路径并重构之后输出得到不含啸叫的语音信号。
步骤(1)中所述语音数据来自由德州仪器、麻省理工学院和sriinternational合作构建的声学-音素连续语音语料库,即timit语音库。提取出的语音信号为时长为3s,采样频率为16khz,单通道16位采样的男女语音信号;步骤(1)中所述的啸叫信号为频率为1.5khz至3khz的正弦信号。
步骤(1)中提取的特征参数包括当前帧信号幅度φ1、子带内所有帧信号幅度之和φ2、相邻帧信号的相位的二阶变化量φ3、相邻帧信号的相位的二阶变化量减去2π,用符号φ4表示以及连续满足啸叫检测幅度和相位条件的帧数n。
bp神经网络训练步骤如下:
1)网络的生成以及初始化
根据网络的初始输入输出状态,确定网络的各个参数,包括输入个数,隐层层数,输出个数,相邻两层之间的权值,隐含层和输出层的阈值,另外还有网络的学习速率以及激励函数;
2)隐含层及输出层的输出计算
隐含层的计算:根据输入向量x,输入层和隐含层之间的连接权值wij以及隐含层阈值a,按照下式得到隐含层输出h,
式中f为隐含层激励函数,l是隐含层的节点数,hj表示第j个隐含层节点的输出,xi表示第i个输入,aj表示第j个隐含层节点的阈值;
输出层的计算:根据隐含层输出h,隐含层和输出层之间的连接权值wjk和输出层阈值b,按照下式计算得到神经网络的预测输出o,
其中m是输出层的层数,ok表示第k个输出层的输出,bk表示第k个输出层的阈值;
3)误差计算
根据神经网络的预测输出o和期望y,计算神经网络预测的误差e,
ek=yk-ok,k=1,2,3,…,m
其中m是输出层的层数,ok表示第k个输出层的输出,yk表示第k个输出层期望得到的输出,ek表示第k个输出层的误差;
4)权值阈值更新
根据神经网络预测的误差更新网络连接的权值wij和wjk,
wjk=wjk+ηhjek,j=1,2,3,…,n;k=1,2,3,…,m
式中η为学习速率,n为输入层层数,l为隐含层层数,m为输出层层数;
5)判断是否结束
达到最大迭代次数或者神经网络已经收敛则停止网络训练。
基于智能手机的智能啸叫抑制装置,由助听器、手机、云端服务器组成,助听器从外界接收带啸叫语音信号并传输到手机,手机通过基于人工神经网络的智能啸叫抑制模块处理后一部分啸叫信号上传到云端服务器,另一部分输出到助听器进行进一步的处理,最后转化为人耳能够识别的语音信号。
基于人工神经网络的智能啸叫抑制模块运行以下流程:
(1)通过对语音数据库的语音信号以及啸叫信号进行特征参数提取,并对提取到的特征参数进行网络训练,得到成熟的网络作为bp神经网络的中间层;
(2)助听器从外界接收语音信号传输到手机端后,通过wola分析滤波器组进行信号多通道处理并形成有两条路径,同时保存语音信号的相位;
(3)第一条路径首先对语音信号进行特征参数提取,然后通过啸叫检测模块判断是否发生啸叫;第二条路径提取保存的相位;
(4)若检测到啸叫信号,则将提取到的特征参数作为bp神经网络的输入,神经网络的输出为啸叫信号功率,之后将啸叫信号从原始信号中减去,同时将啸叫信号功率上传至数据云端;否则直接将特征参数上传至数据云端;
(5)wola综合滤波器组综合两条路径并重构之后输出得到不含啸叫的语音信号。
本发明的特点及有益效果是:
本发明将啸叫抑制算法与神经网络和数据云结合,避免了传统lms算法收敛速度和稳定性矛盾的问题,并且将助听器的一部分功能转移到智能终端上,节省了助听器电池功耗。另外本发明应用在手机端上还能为云端数据库提供新的数据,进一步训练得到更加准确的网络,实现硬件的软升级。
附图说明:
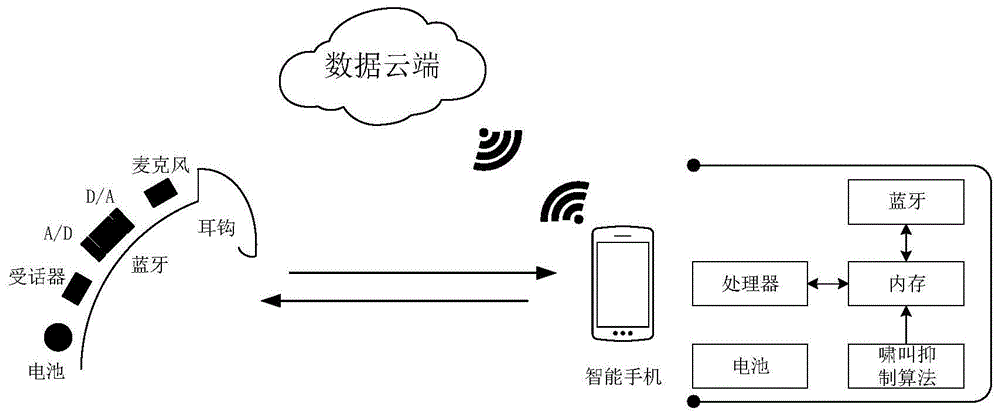
图1是本发明算法应用的系统结构示意图。
图2是本发明算法结构图。
图3是本发明算法的流程示意图。
具体实施方式
本发明,一种基于智能手机的智能啸叫抑制算法,用于助听器、数据云端和智能终端之间的通信,助听器从外界接收带啸叫语音信号并传输到手机端,手机端通过基于人工神经网络的智能啸叫抑制算法应用处理后一部分啸叫信号上传到数据云端,另一部分输出到助听器进行进一步的处理,最后转化为人耳能够识别的语音信号,所述基于人工神经网络的智能啸叫抑制算法包括以下流程步骤:
(1)通过对语音数据库的语音信号以及啸叫信号进行特征参数提取,并对提取到的特征参数进行网络训练,得到成熟的网络作为bp神经网络的中间层;
(2)助听器从外界接收语音信号传输到手机端后,通过wola分析滤波器组进行信号多通道处理并形成有两条路径,同时保存语音信号的相位;
(3)第一条路径首先对语音信号进行特征参数提取,然后通过啸叫检测模块判断是否发生啸叫;第二条路径提取保存的相位;
(4)若检测到啸叫信号,则将提取到的特征参数作为bp神经网络的输入,神经网络的输出为啸叫信号功率,之后将啸叫信号从原始信号中减去,同时将啸叫信号功率上传至数据云端;否则直接将特征参数上传至数据云端;
(5)wola综合滤波器组综合两条路径并重构之后输出得到不含啸叫的语音信号。
步骤(1)中所述语音数据库为timit语音库,提取出的语音信号为时长为3s,采样频率为16khz,单通道16位采样的男女语音信号。
步骤(1)中所述的啸叫信号为频率为1.5khz至3khz的正弦信号。
步骤(1)中提取的特征参数包括当前帧信号幅度φ1、子带内所有帧信号幅度之和φ2、相邻帧信号的相位的二阶变化量φ3、相邻帧信号的相位的二阶变化量减去2π,用符号φ4表示以及连续满足啸叫检测幅度和相位条件的帧数n。
下面结合附图对本发明做进一步的描述:
如图1所示为本发明算法应用的系统结构示意图。
本系统由三个主要部分组成,即助听器、数据云端和智能手机。助听器的受话器从外界接收语音信号,也包括啸叫信号,在助听器中进行数模转换、wola分析变换后通过无线传输到智能终端。在传输之前也可以进行一些语音信号的预处理,此时是不对语音进行任何的改变的。在手机端,首先进行啸叫检测,然后通过神经网络估算啸叫信号功率,并将语音信号特征参数和啸叫信号功率通过网络上传至云端,作为神经网络训练的目标样本。将神经网络估算得到的啸叫信号功率从原始信号减去后通过无线传回到助听器,通过wola综合滤波器重构为不含啸叫的语音信号。经过模数转换后输出为人耳可听见的语音信号。
具体实施过程中,数字化的语音信号传输到手机端之后进行特征参数提取、啸叫检测以及啸叫信号估计等一系列操作。完成之后一部分通过网络上传至云端数据库,方便进一步的网络训练以提高准确性,另一部分通过无线通信返回到助听器,进行wola综合变换、模数转换等。将采集到的听力障碍患者数据上传到云端,然后再把经过中心服务器训练后的网络参数通过升级的方式下载到智能终端上,这样就实现了软件的更新升级,保证了应用的可靠性。
如图2所示为本发明的算法结构图。从结构上,本发明分为训练阶段和应用阶段两个部分。
训练阶段:在本阶段中,我们从已有的timit语音库中挑选出若干时长为3s,采样频率为16khz,单通道16位采样的男女语音信号。而啸叫信号选用频率为1.5k~3khz,时长为0~3s的正弦信号。将这些信号随机排列组合合成不同的啸叫语音信号,经过处理后,提取出特征参数作为神经网络的训练数据,训练结束得到的收敛网络将会被应用在第二个阶段。
应用阶段:从外界接收到的语音信号同样进行特征的提取,使用训练阶段得到的网络可以得到啸叫信号功率,将啸叫信号从语音信号中减去得到不含啸叫的纯净语音信号。
在本发明中提取的特征参数包括当前帧信号幅度φ1、子带内所有帧信号幅度之和φ2、相邻帧信号的相位的二阶变化量φ3、相邻帧信号的相位的二阶变化量减去2π,用符号φ4表示以及连续满足啸叫检测幅度和相位条件的帧数n。
在本发明算法中,bp神经网络的功能是判断和预测,所以在使用之前首先要对神经网络进行联想记忆和预测功能的训练。训练步骤如下:
1.网络的生成以及初始化
根据网络的初始输入输出状态,确定网络的各个参数,例如输入个数,隐层层数,输出个数,相邻两层之间的权值,隐含层和输出层的阈值,另外还有网络的学习速率以及激励函数等等。
2.隐含层及输出层的输出计算
隐含层的计算:根据输入向量x,输入层和隐含层之间的连接权值wij以及隐含层阈值a,按照下式得到隐含层输出h,
式中f为隐含层激励函数,l是隐含层的节点数,hj表示第j个隐含层节点的输出,xi表示第i个输入,aj表示第j个隐含层节点的阈值。
输出层的计算:根据隐含层输出h,隐含层和输出层之间的连接权值wjk和输出层阈值b,按照下式计算得到神经网络的预测输出o,
其中m是输出层的层数,ok表示第k个输出层的输出,bk表示第k个输出层的阈值。
3.误差计算
根据神经网络的预测输出o和期望y,计算神经网络预测的误差e,
ek=yk-ok,k=1,2,3,…,m
其中m是输出层的层数,ok表示第k个输出层的输出,yk表示第k个输出层期望得到的输出,ek表示第k个输出层的误差。
4.权值阈值更新
根据神经网络预测的误差更新网络连接的权值wij和wjk,
wjk=wjk+ηhjek,j=1,2,3,…,n;k=1,2,3,…,m
式中η为学习速率,n为输入层层数,l为隐含层层数,m为输出层层数;
5.判断是否结束
达到最大迭代次数或者神经网络已经收敛则停止网络训练。
如图3所示为本发明的算法流程示意图:助听器从外界接受带啸叫语音信号通过wola分析滤波器组进行信号多通道分析形成多个子带后,将子带信号传输到手机端并形成有两条路径:首先利用人耳对语音信号相位不敏感的特性,将通过wola分析滤波器组分析得到的相位信息保存,以便合成时使用;然后,通过提取特征参数,作为神经网络的输入,输出为神经网络估算的啸叫信号功率;最后,将啸叫信号从原始语音中减去,并wola综合滤波器组重构得到不含啸叫的纯净语音信号并输出。
- 还没有人留言评论。精彩留言会获得点赞!